图谱增强检索实则就是在传统RAG向量私有知识库的基础上提升了向量库功能,原来的向量的库只能通过近似值查询,升级成为这个之后,可以将文档中的实体对象、以及对象之间的关系进行抽离,并且进一步将关系进行分类、对象进一步分类,在我的理解当中,这里的分类就是它文档里提的社区算法和社区摘要。
测试环境
4090的显卡一张,ollama 跑的Gemma2,xinference 跑的bge-large-zh-v1.5
安装步骤
pip install graphrag
注意,安装的时候确保自己的python的版本是其要求的python版本,另外国内镜像可能存在同步延迟,我安装的时候第一遍使用的清华镜像就安装了个老版本。
我安装过程中报错了,由于我的cmd窗口是utf8编码的,但是这个库需要用的到windows的gcc编译等。我将编码改为gbk后,报错消失
所以 没事不要随意改windows的cmd这种命令行编码基础设置。
第一
mkdir ./myTest/input
curl https://www.xxx.com/太白金星有点烦.txt > ./myTest/input/book.txt // 这里是示例代码,大家在测试时根据实际情况放入自己要测试的txt文本即可。
cd ./myTest
进行库初始化
python -m graphrag.index –init
这里随意找篇中文文档就好,我一开始怕中文看不来效果用了个英文文档,但是我又用中文试了下没啥区别
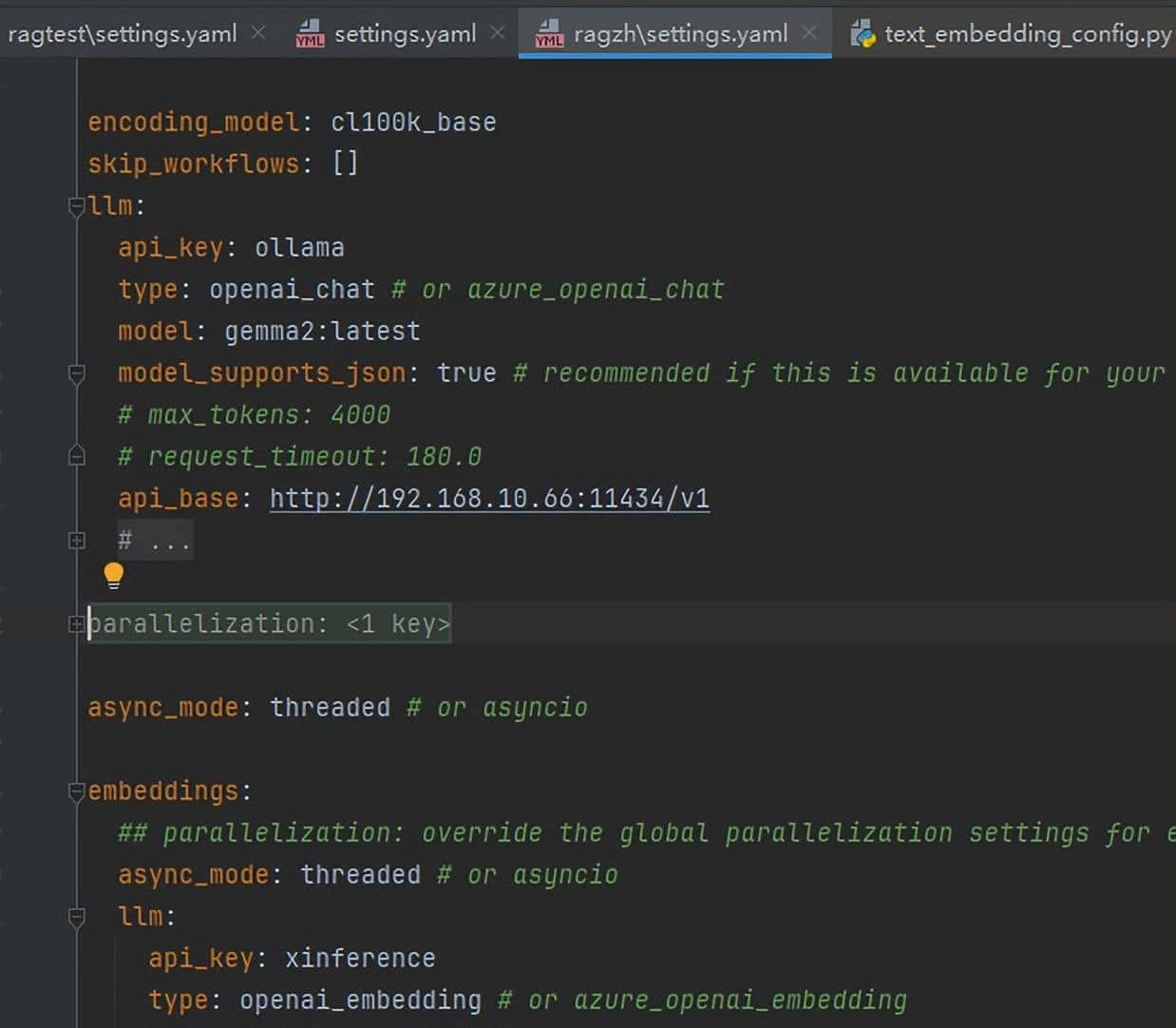
下面修改初始化配置文件,配置大模型接口地址和词向量接口地址
这里使用的ollama 部署的google的gemma2 9B模型
使用的xinference 部署的embedding模型,选用了它内置的bge-large-zh-v1.5
为什么选择这两个框架呢,由于graphRAG默认支持的openai和azure_openai_chat接口都是用openai的接口规范调用的,这两个框架都是支持openai接口规范的
也就是接口前缀
http://192.168.xxx.xxx:11434/v1 这种接口格式。
但是由于ollama的embedding接口并不支持的openai的接口格式,所以无奈我又部署了个xinference框架。
ollama 安装后使用
ollama run gemma2:latest
启动模型,超级简单
xinference安装
pip install “xinference[all]”
xinference由于启动后是有web页面的,所以我们直接使用
http://192.168.xxx.xxx:9997/ui/
选择内置模型
bge-large-zh-v1.5
启动
修改配置文件
执行初始化数据
python -m graphrag.index –root ./ragzh
使用本地搜索
python -m graphrag.query –root ./ragzh –method local “故事的主要讲了什么”
python -m graphrag.query –root ./ragzh –method global “故事的主要讲了什么”
本地搜索和全局搜索的区别,我的理解就是 全局搜索是基于社区报告进行搜索
本地搜索更应该叫局部搜索,是基于某个局部片段的搜
目前项目存在的问题:
- 项目整体的prompt全部都是英文的,处理中文文本并不成熟,使用英文prompt处理中文数据会出现 中英混合问题,得到的数据不必定是中文还是英文。
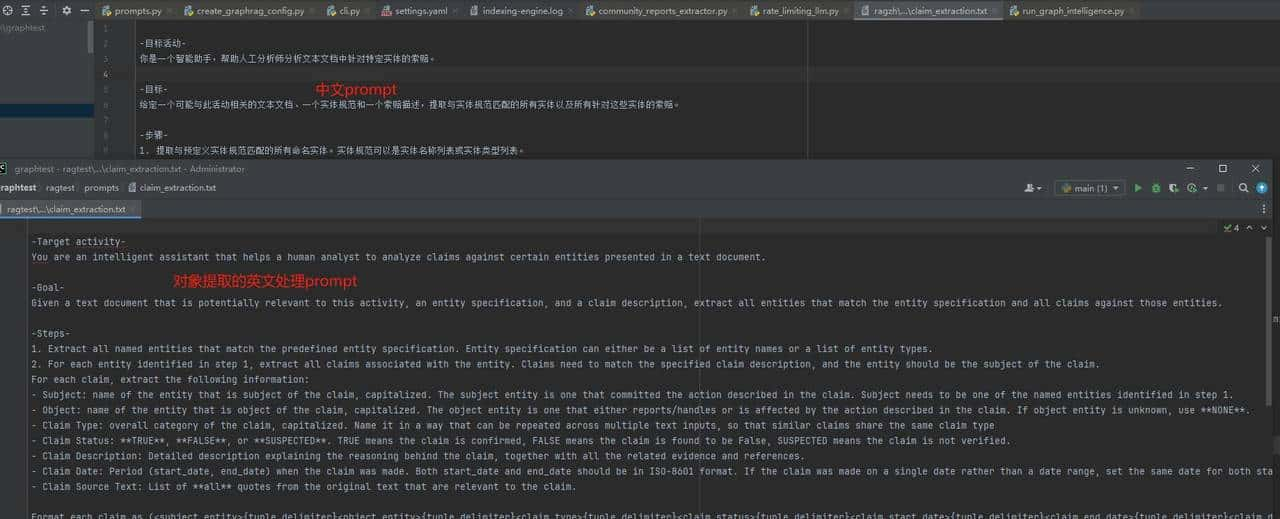
强行翻译了一下,由于我们没办法进行全面测试,无法保证效果和英文效果一致
https://www.graphrag.club/indexgraph/prompt/ClaimExtraction
中英混合的问题,列如原文“李长庚架着祥云飞上了天”,会产生 “李长庚”、“chang geng li” 这种不同的实体结果文本,无法做到有效对应
2. 目前的通用式文本切割小段落的方式有待商榷,这种文本切割方式会把句子拆破句,列如下面这种
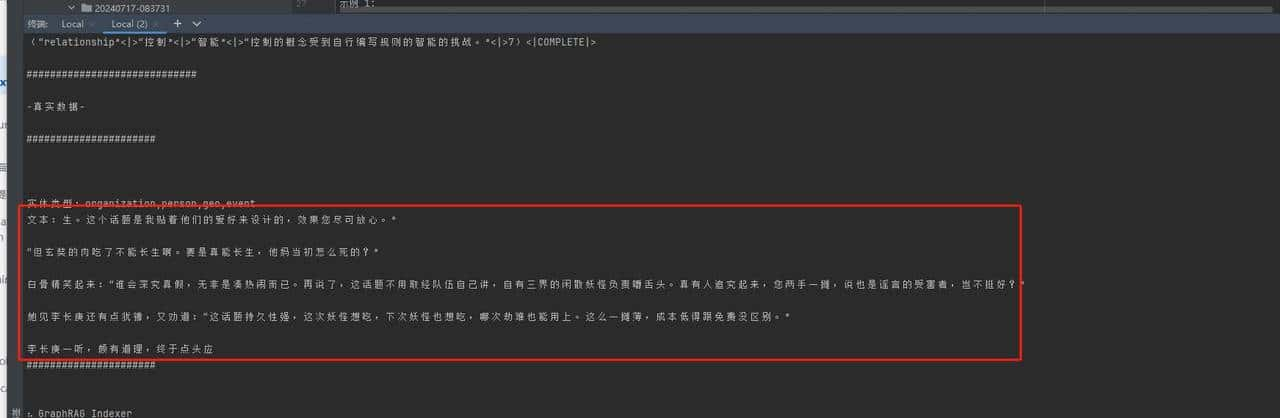
红色框框内室扔个大模型,让其提取实体的句子,可以看到句子前后都“破了”。
另外,目前的处理方式效率很低,一段很长的提示词只有最后一小段是要处理的数据,如果使用openai这种收费接口,数据使用频次不高的情况下,反而会大量浪费token。
graphRAG前期数据处理的消耗的token超级多。
总结:
图谱+向量数据库的知识库存储方式还是超级好的;另外对采用大模型对数据加工后存储的这种做法也是超级好的。
项目可提升空间还是很大,实际应用感觉可能需要等等,还不成熟,测试过程中还发现了源码中配置项名称写错的低级bug。
© 版权声明
文章版权归作者所有,未经允许请勿转载。












看了token量,价格用不起啊。
实测效果就那样 而且自动构建知识图谱方式不可控 效率低下 构建过程慢 成本非常高 还有很大的提升空间
这个的实现思路挺好的,期望国内大牛能弄个中文的开源项目出来,这样,RAG就离实际落地更近一步了
你这家伙一知半解
水平有限
GraphRAG
收藏了,感谢分享