

大数据文摘出品最近,DeepSeek 推出了一种全新的 OCR 系统,能让 AI 在不超出内存限制的情况下,处理更长的文档。

地址:
https://github.com/deepseek-ai/DeepSeek-OCR?tab=readme-ov-file
这套系统的关键,是把文字当作图像来压缩。DeepSeek 发现,处理图片反而比处理纯文本更节省算力。
据其技术论文,系统在保留 97% 信息量的前提下,可将文档压缩至原来的十分之一。
换句话说,一本上百页的 PDF,经 DeepSeek 处理后,只需原来十分之一的 token 数量,就能被 AI 完整阅读。
DeepSeek OCR 的核心由两部分组成:一是图像处理模块,DeepEncoder,二是基于Deepseek-3B-MoE的文本生成器。.
DeepEncoder 拥有 3.8 亿参数,负责将文档图片分析为压缩后的视觉 token;文本生成器在此基础上恢复文字与结构。

在技术上,它融合了 Meta 的 SAM(Segment Anything Model)与 OpenAI 的CLIP 模型。
SAM 担任局部视觉分析,CLIP 则提供全局语义关联。两者之间,嵌入了一个 16 倍压缩器,大幅减少图像 token 数量。
一张 1024×1024 像素的图片,起初被分为 4096 个 token;经压缩后,只剩 256 个。这一过程的算力节省是数量级的:CLIP 的计算负担因此显著下降。
在低分辨率下,DeepSeek OCR 每张图仅需 64 个视觉 token;高分辨率时也不超过 400。
相比之下,传统 OCR 系统往往需要数千 token 才能完成同样的任务。
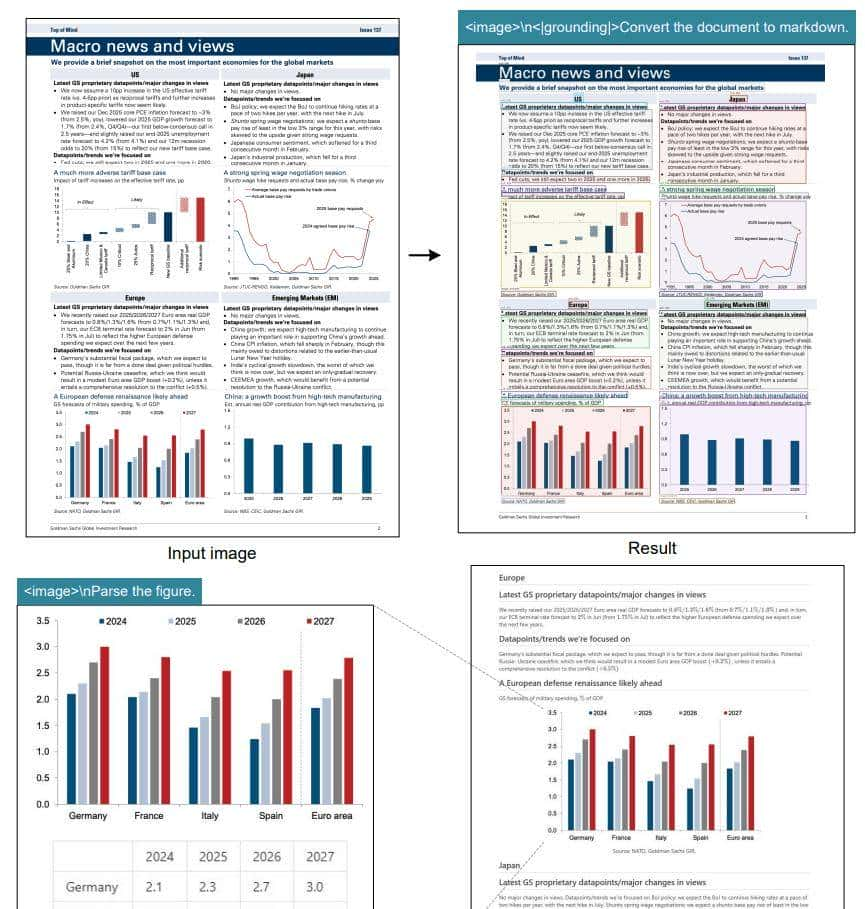
DeepSeek 并不仅仅识别文字。它能识别图表、化学式、几何图形等多种复杂结构。
研究团队称,系统可直接从财报图表中提取结构化数据,并自动生成 Markdown 表格。
在“深度解析模式”下,它能将金融图表、几何图形重新绘制成矢量图,并同时保留说明文字。
测试结果显示,DeepSeek OCR 在 OmniDocBench 基准上超过了 GOT-OCR 2.0。
在仅使用 100 个视觉 token 的情况下,它的表现优于 GOT-OCR 2.0 使用 256 token 的结果。
即使在 800 token 以下,DeepSeek 也击败了 MinerU 2.0,后者每页需超过 6000 token。
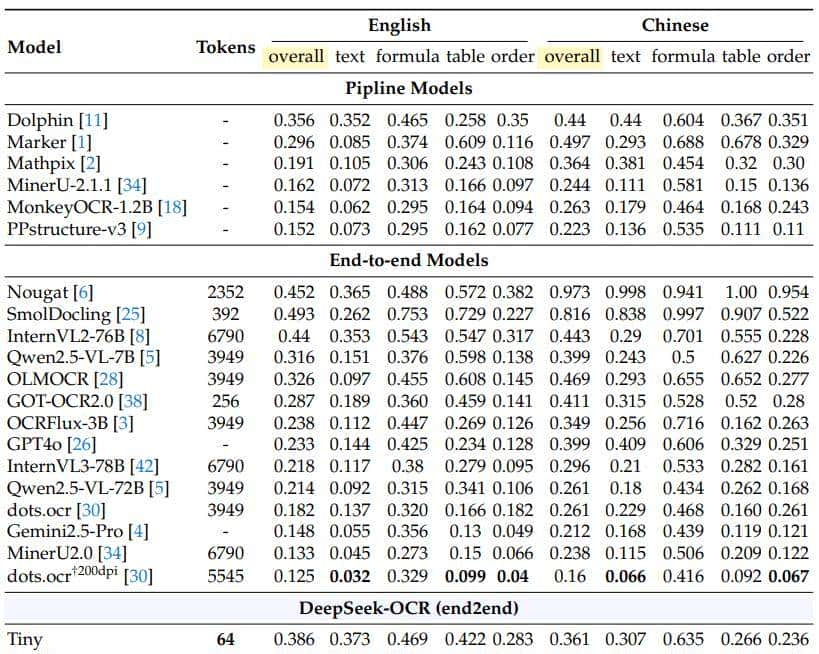
根据对比数据,DeepSeek OCR 的 Gundam-M 模式在中英文混合识别上取得了最佳编辑距离分数。
系统根据文档复杂度自动选择模式:简单演示文档用 64 token;普通报告约 100;复杂报纸需启用“Gundam 模式”,上限 800 token。
此外,它还提供 Resize、Padding、Multi-page、Sliding 四种策略,在多页文档中平衡压缩率与准确性。

DeepSeek OCR 的训练规模同样罕见。研究团队使用了 三千万页 PDF 语料,覆盖约一百种语言。
其中包括 2500 万页中英文文档,以及一千万张合成图表、五百万化学公式、一百万几何图形。
这些数据让模型具备了跨领域、跨语言的泛化能力。
它不仅能保持原始排版,还能在输出中附带文字描述和图像内容说明。
在多模态大模型中,文本上下文的限制一直是瓶颈。DeepSeek 的方法绕开了传统 token 计数逻辑,用视觉 token 替代文本 token。
这使得语言模型能在“看图”的同时完成“读文”。
对研究者而言,这是一种近似“外接硬盘”的解决方案:通过视觉压缩,AI 的上下文长度几乎无上限。
这种方式也预示着未来的模型架构可能不再区分“文本理解”和“图像理解”。
注:头图AI生成
作者长期关注 AI 产业与学术,欢迎对这些方向感兴趣的朋友添加微信 Q1yezi,共同交流行业动态与技术趋势!

GPU 训练特惠!
H100/H200 GPU算力按秒计费,平均节省开支30%以上!

点「赞」的人都变好看了哦!
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...










