
模型即服务,尤其高并发低延迟场景下不能每次都调用LLM。响应时间长占用资源多,最后肯定需要LLM-Cache。Langchain也支持集成Cache,而且品类超级多。
1.InMemoryCache
内存性质,大数据缓存内存资源比较高
最简单的memory:就是”硬“缓存更新删除

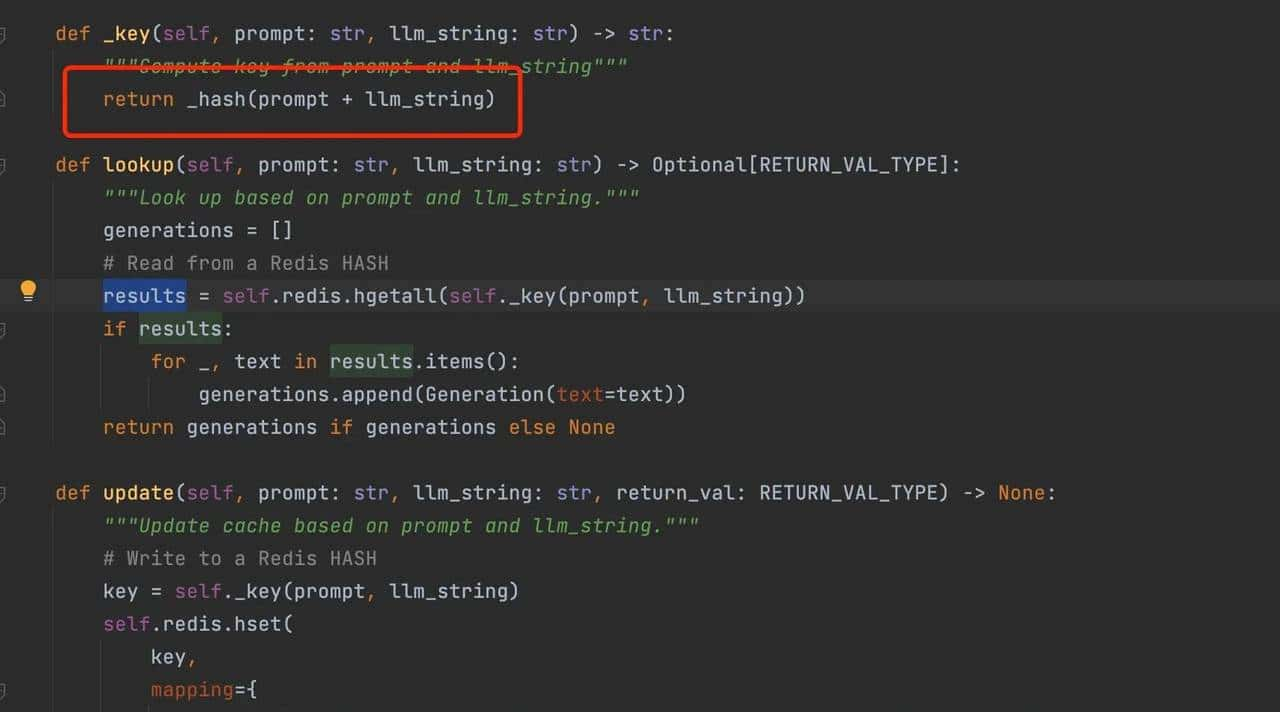
2.RedisCache
redis的memory:对prompt+llmstring做hash-md5
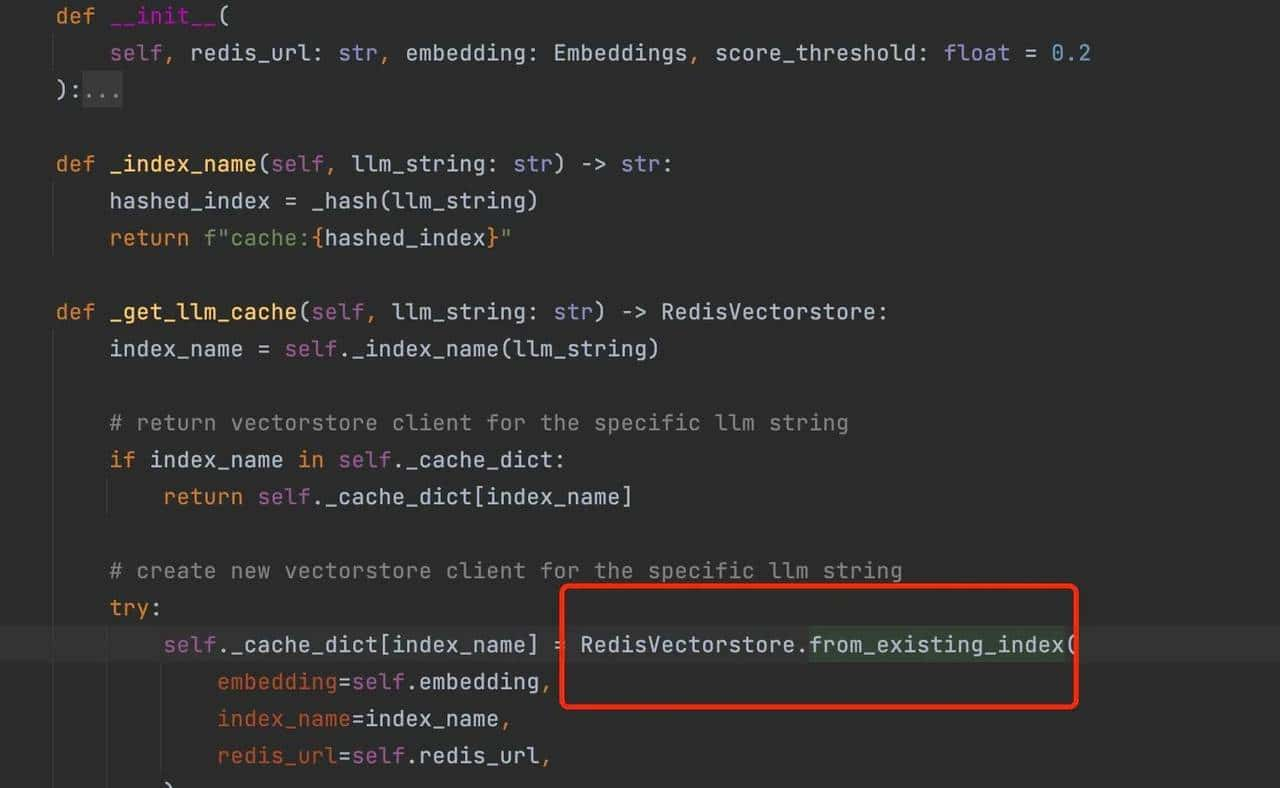
3.RedisSemanticCache
Redis的STS插件例如RedisSemantic语义检索
4.SQLAlchemyCache
利用数据库做Cache,SQLAlchemy支持的数据库都可以思考
5.SQLiteCache
测试实验性质科研,你懂的
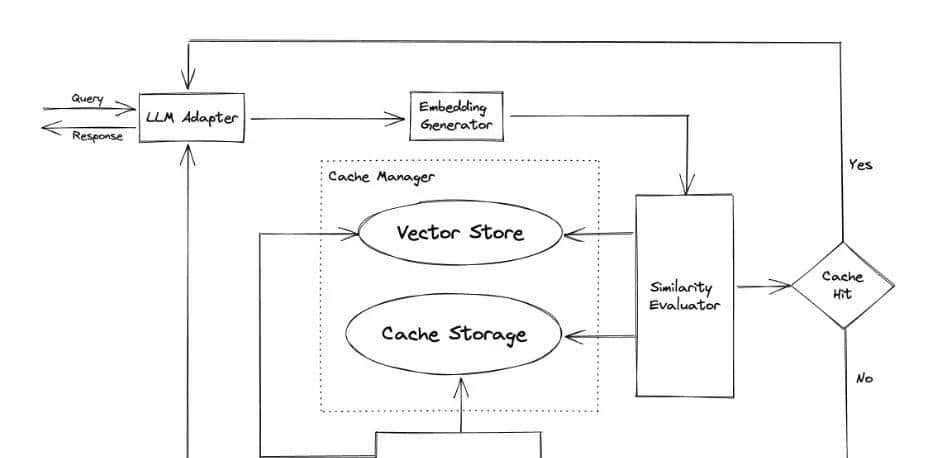
6.GPTCache
完整级别解决方案(涵盖Embedding Model,Cache Storage,Vector Store,Cache Manager[LRU,LFU,FIFO],Similarity Evaluator等),就是那个向量数据库Milvus运营商Zilliz推出解决方案
简单使用样例:
初始化实现
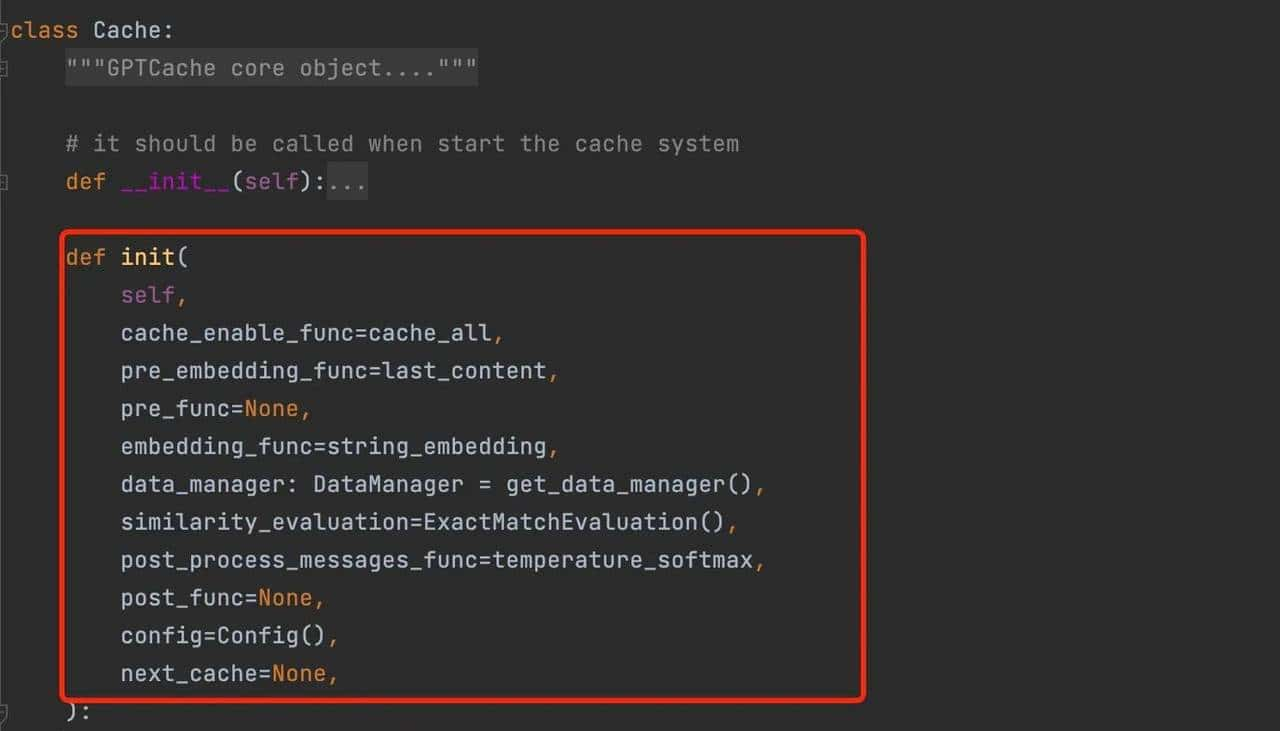
简单举例:
#cache选择mysql
cache_base = CacheBase('mysql',sql_url='mysql+pymysql://root:123456@127.0.0.1:3306/mysql')
#使用milvus作为vectordb
vector_base = VectorBase('milvus', host='127.0.0.1', port='19530', dimension=hf.dimension)
#data管理器
data_manager = get_data_manager(cache_base, vector_base)
cache.init(
pre_embedding_func=None,#没有自定义函数可以为空
embedding_func=hf.to_embeddings,
data_manager=data_manager,
similarity_evaluation=SearchDistanceEvaluation(), ##类似性算法评估
)
7.MomentoCache:三方服务key收费,要钱的始终不能干
介绍这么多Cache,最后思考成本开源安全高效可靠:提议还是采用Redis/RedisSemantic或者VectorDB做缓存,然后类似性匹配检索。也可以思考GPTCache复杂度高且对竟对vectordb产品支持度有限主推自己产品。上述Cache方式继承BaseCache实现lookup,update,clear抽象方法。
© 版权声明
文章版权归作者所有,未经允许请勿转载。

![一些好用的开源监控工具汇总[转]](https://img.dunling.com/blogimg/20251213/3d611d781c4a4852884de55bde23f274.jpg)










收藏了,感谢分享