
JVM 调优不求人:手把手教你看懂 Grafana GC 大盘
“程序员有三怕:掉电、掉盘、掉 GC。”
—— 一位在凌晨三点看 GC 日志的开发者
Grafana 大盘解读
JVM 大盘

常见指标解读:
- G1 Eden Space:新对象分配的游乐场,满了就触发 Young GC。
- G1 Survivor Space:幸存者收容所,Eden GC 后没死掉的对象会住这里。
- G1 Old Gen:养老院,多次 GC 还活着的对象晋升过来。
- Metaspace:存放类元数据,和堆无关,涨得快要警惕类加载泄漏。
- Code Cache:JIT 编译后的机器码缓存,满了性能会打折。
GC 排查流程图
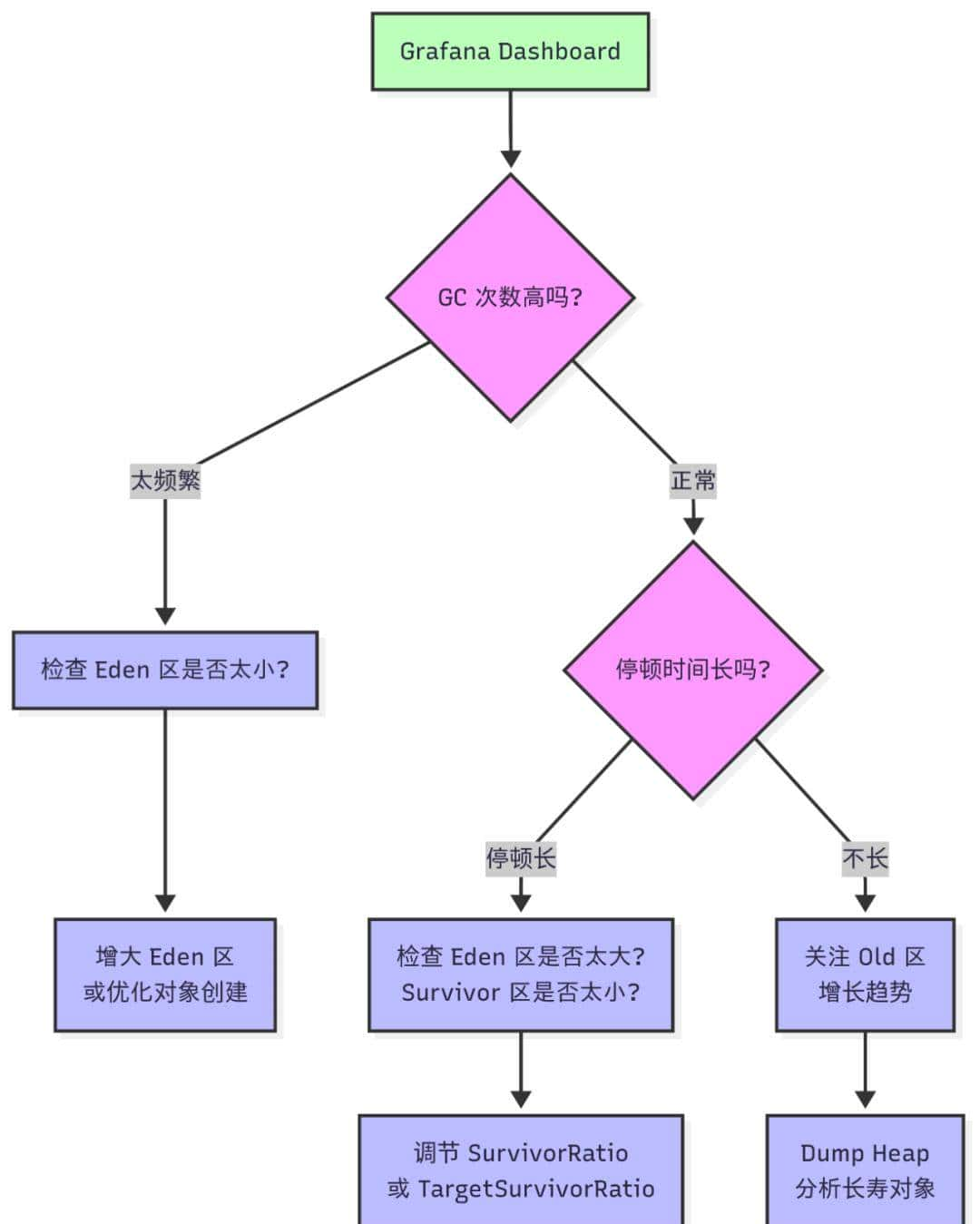
GC 正常范围参考
看到这些指标时,心里要有一杆秤:
|
指标 |
正常范围(经验值) |
异常表现 |
|
Young GC 次数 |
每分钟 < 5 次 |
频繁触发,应用抖动 |
|
Young GC 停顿时间 |
单次 < 50ms |
单次 > 200ms 且频繁 |
|
Old GC 次数 |
小时级别才 1 次 |
短时间多次,说明 Old 区膨胀 |
|
Full GC |
几乎不该出现 |
出现就要排查 OOM/堆不足 |
|
GC 占用 CPU |
< 5% |
长期 > 20%,性能堪忧 |
口诀:频率看 Young,停顿看 Old,出现 Full 就要慌。
JVM GC 速查对照表
一表在手,GC 不愁:
|
现象 |
表现 |
可能缘由 |
调优手段 |
|
Young GC 频繁 |
Eden 快速被填满 |
Eden 太小 |
增大 Eden (-Xmx / -XX:NewRatio) |
|
Young GC 停顿长 |
单次 GC 清理对象太多 |
Eden 太大 |
调小 Eden,调 -XX:MaxGCPauseMillis |
|
Survivor 区打满 |
晋升太快 |
Survivor 太小,对象存活率高 |
调 -XX:SurvivorRatio,优化缓存 |
|
Old 区膨胀快 |
Old used 持续增长 |
Survivor 太小,大对象晋升 |
增 Survivor,排查大对象 |
|
Full GC 出现 |
应用卡死,日志 OOM |
堆太小/内存泄漏 |
增堆、HeapDump 分析、修复泄漏 |
|
Metaspace 涨不停 |
used 一直上升 |
类加载泄漏 |
限制 -XX:MaxMetaspaceSize,修复动态类 |
⚙️ JVM 调优推荐配置
实用稳定组合(G1):
-Xms4g
-Xmx4g
-XX:+UseG1GC
-XX:MaxGCPauseMillis=200
-XX:InitiatingHeapOccupancyPercent=45
-XX:ParallelGCThreads=4
-XX:ConcGCThreads=2
-XX:SurvivorRatio=8
-XX:+PrintGCDetails
-XX:+PrintGCDateStamps
-Xlog:gc*,gc+heap=info:file=gc.log:time,uptime,level,tags调优原则:
- 先定好堆大小(-Xmx),再让 G1 动态调节。
- 不要死磕低延迟,MaxGCPauseMillis=200ms 是常用平衡点。
- GC 问题先看日志和大盘,不要盲目改参数。
结尾彩蛋:GC ≈ 感情问题
GC 和感情一样:
- 偶尔来一下 → 正常
- 太频繁 → 有问题
- 一来就很久 → 要重点关注
- Full GC → 基本等于大吵一架
所以,别等到 Full GC 才想起排查。懂得看 Grafana + GC 日志,再配合这份 流程图、对照表、调优参数,你就能轻松 hold 住 JVM 的小情绪。
往期回顾
打造企业级全栈监控系统:Prometheus + Thanos + Exporter + Alertmanager 实战指南「链接」
© 版权声明
文章版权归作者所有,未经允许请勿转载。













好文章
无人扶驴凌云志,驴自拉磨至山巅,若是命中无此运,亦可孤驴登昆仑,核动力驴申请出战。
收藏了,感谢分享