神经网络涉及到大量的高纬度tensor运算,纬度越高就越抽象,这对初学者来说是有些难度的,下文简单直观地介绍下nn.Embedding具体都做了些什么。
一,官方文档
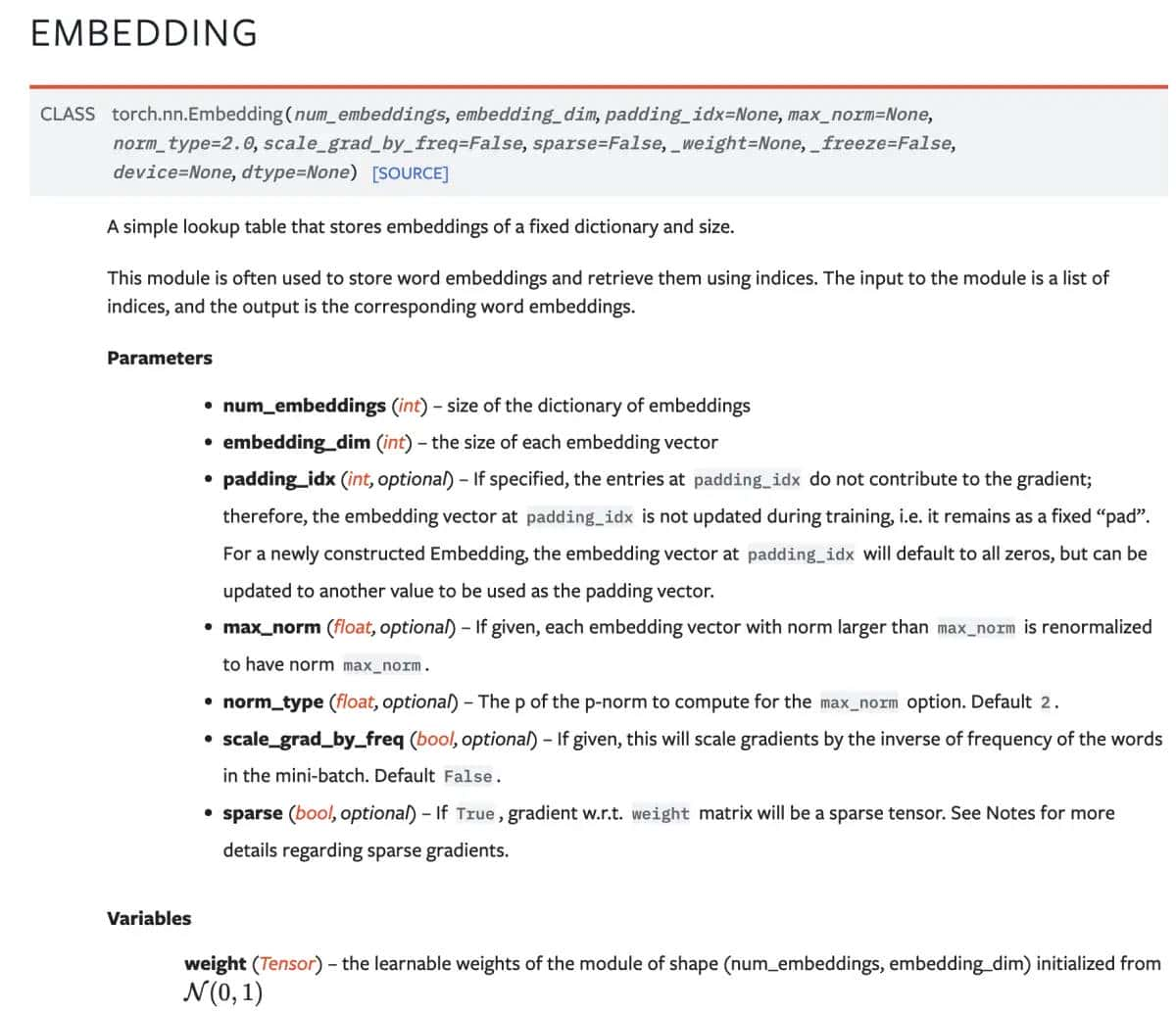
官方介绍如上,信任大多数初学者是不知所云的。接下来笔者用最简单的方式,把embedding运算直观地展现给大家。
二、使用场景
在训练语言模型的时候,我们需要把人类的自然语言转换为计算机能够理解的数字,列如如下代码:
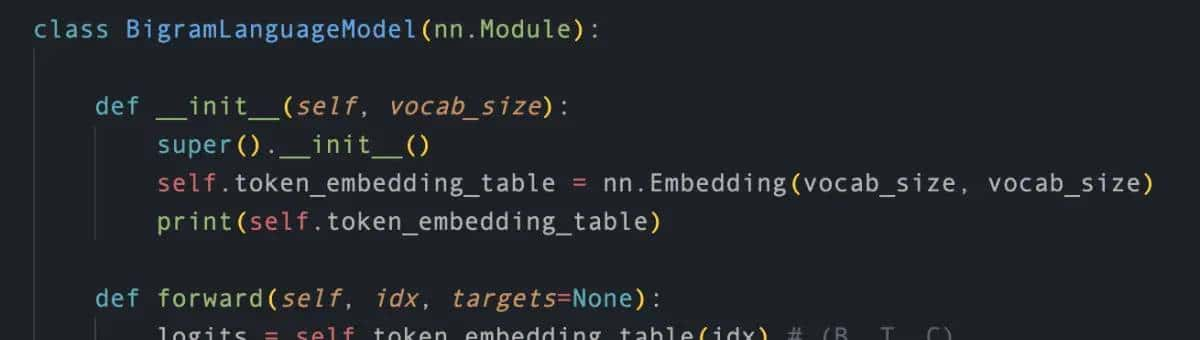
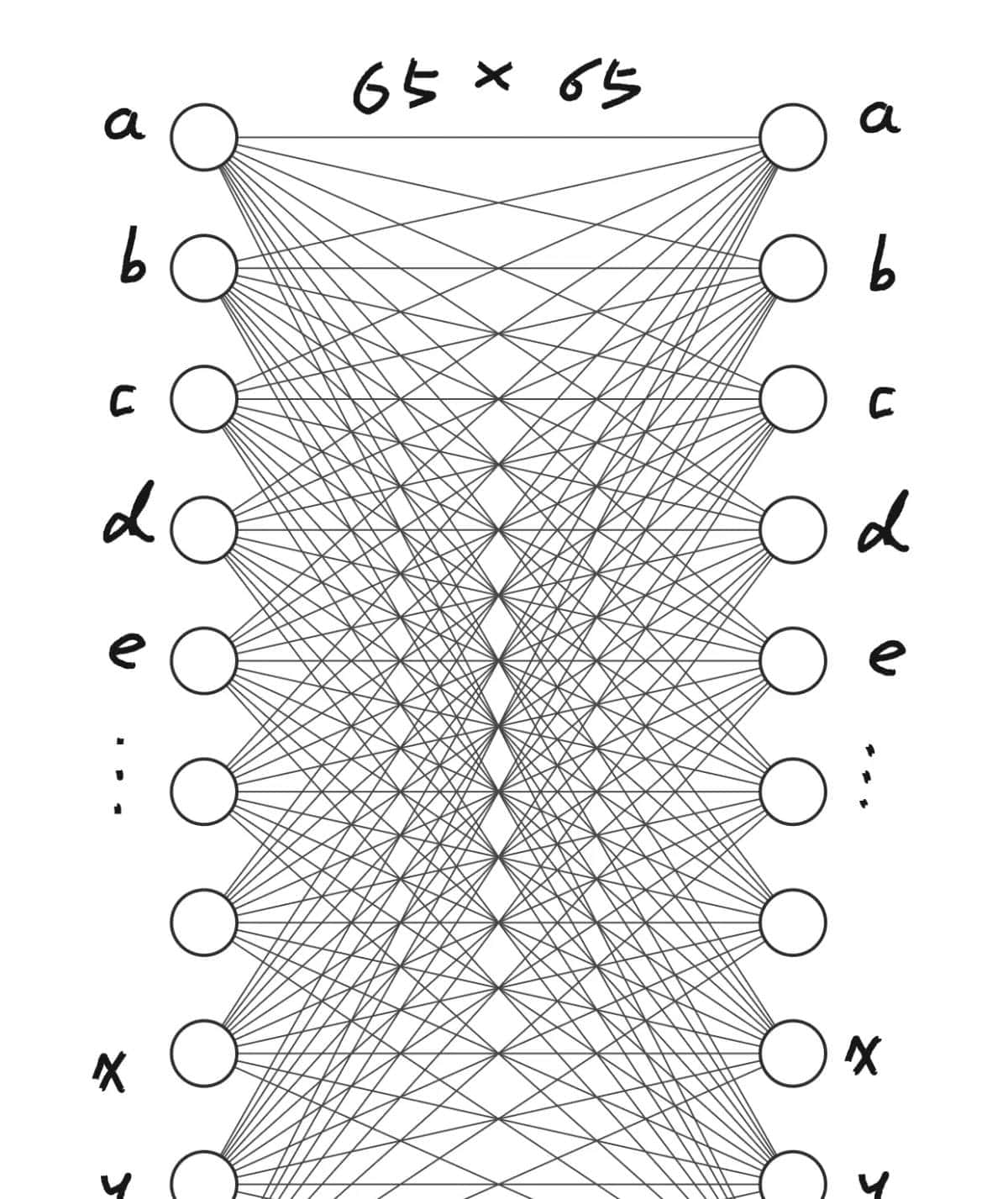
我们初始化了一个映射表token_embedding_table,纬度为[vocab_size x vocab_size](示例代码中vocab_size为65),而这个vocab_size即为词库大小,列如如果你只想训练英文模型,那这个vocab_size大小可能为所有的英文字母大写+小写,再加上标点符号等特殊字符。
使用这个映射表的时候,直接调用即可:token_embedding_table(idx)
三、调用的时候做了什么
我们可以看到nn.Embeding所存储的内容为一个二维数组,包含了一堆浮点数:

所以本质上,nn.Embedding就是一个二维数组
接下来看看上述代码中idx的内容:

这些数字实则是一个token化之后的多维数组,笔者这里是4×8
然后最关键的一步,调用映射表:
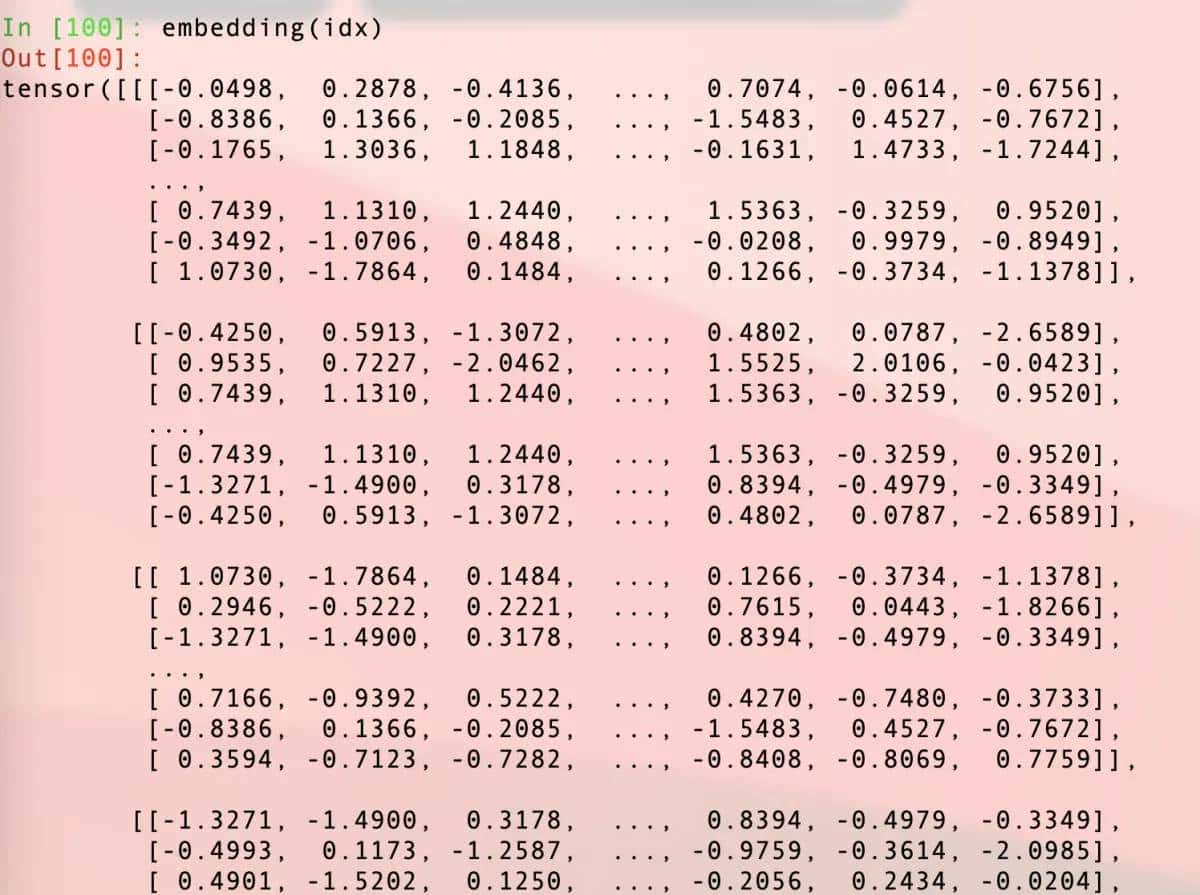
我们又得到了一大堆不明所以的数字,实则这些数字都是上面展示过的embedding.weight中的一些
读者可能留意到了idx这个变量应该是一对index,没错,调用embedding的时候实则就是把idx指定的下标位置的weight拿出来。我们可以验证下,idx是4×8结构,00位置是56,我们直接把embedding的56位置拿出来看看:
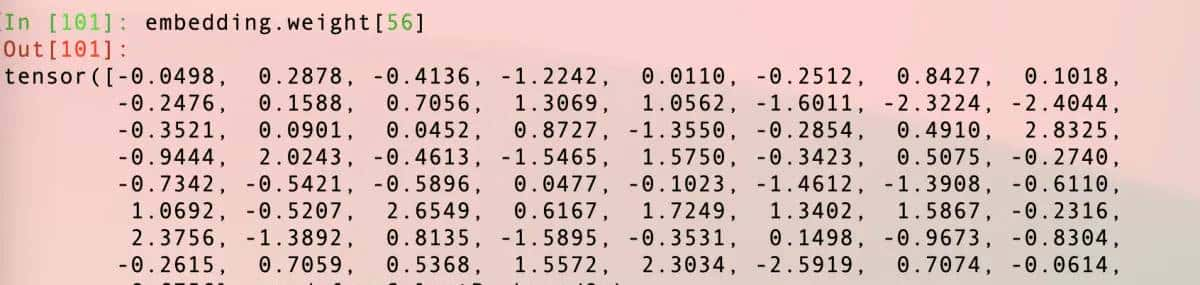
然后我们再来对比一下
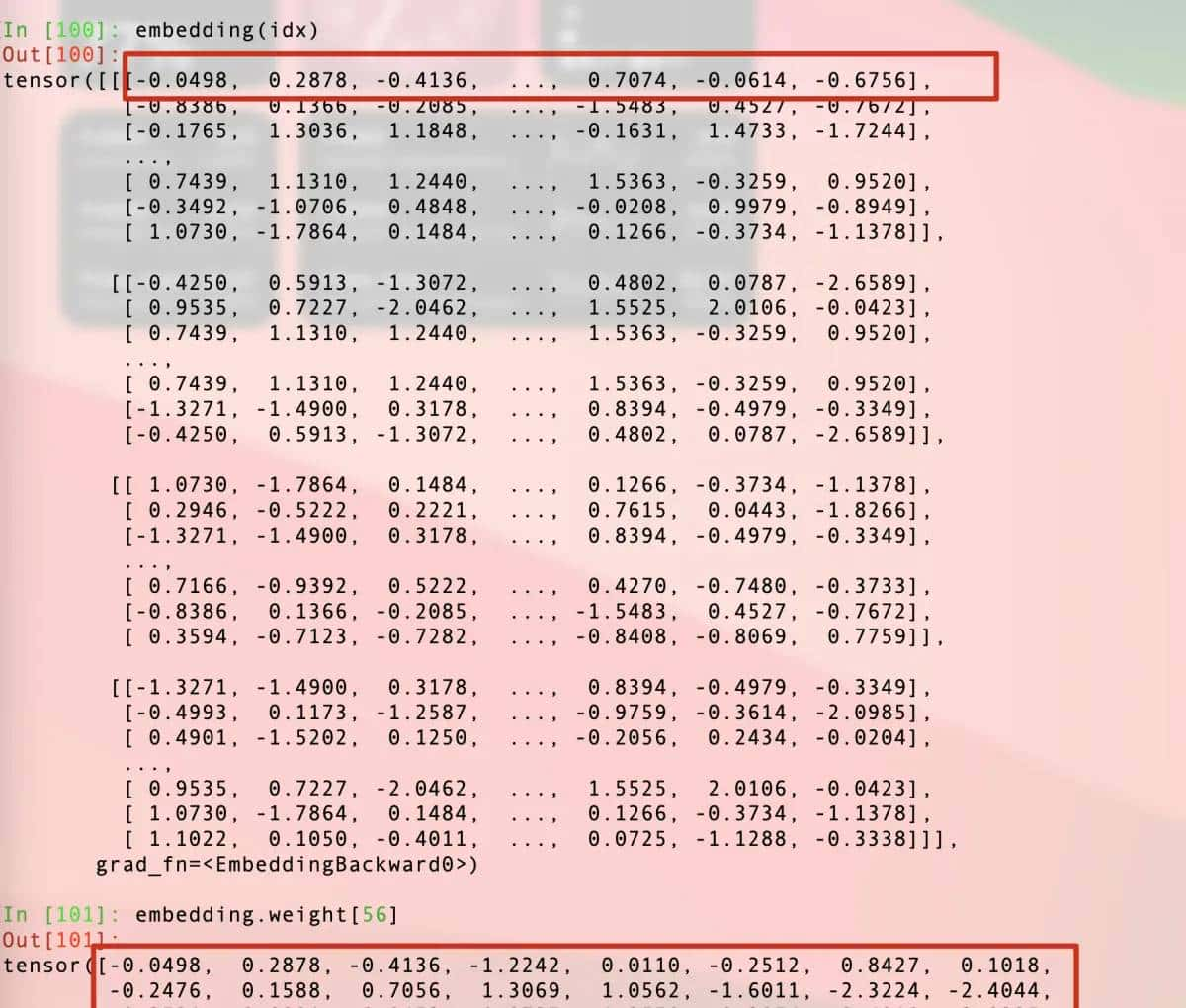
至此,信任读者已经清楚在调用embedding的时候发生了什么了,56位置的数据和embedding(idx)结果的第一行数据是一样的。
四,总结
创建nn.Embedding对象的时候,本质上是创建了一个二维数组,第一纬是词库大小,第二维是下一个可预测字符集合大小。
而调用的时候实则就是根据传入的index tensor去查embedding对应下标的值。
后续在训练过程中,这些权重就会得到更新,以便我们的模型更好地进行预测。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...