1. 引言:InternLM2——更强的模型
InternLM2系列的发布,其核心亮点不能z有四点:
卓越的开源性能:发布了1.8B, 7B, 20B的全系列模型,在各类客观与主观评测中均表现出色。200K超长上下文窗口:通过创新的预训练和微调策略,实现了在200K“大海捞针”测试中近乎完美的表现。全面的数据准备指导:详细阐述了预训练、SFT、RLHF各阶段的数据处理细节,为社区提供了宝贵的实践经验。创新的RLHF训练技术:提出了COOL RLHF,有效解决了多偏好冲突和奖励滥用(reward hacking)问题。
2. 模型Infrastructure: InternEvo训练框架
强大的模型离不开强大的训练框架。InternLM2的训练依托于团队自研的InternEvo框架,这是一个专为大规模LLM训练设计的、高效且轻量级的解决方案。
核心特性:
混合并行策略: 深度融合了数据并行、张量并行、序列并行和流水线并行,能够将模型训练扩展至数千块GPU。极致的内存优化: 集成了多种ZeRO(Zero Redundancy Optimizer)策略,显著降低了训练所需的显存。高硬件利用率 (MFU): 通过FlashAttention、混合精度训练(BF16)等技术,实现了极高的模型浮点运算利用率(MFU)。论文中提到,在1024块GPU上训练7B模型时,MFU高达53%,远超DeepSpeed等框架。强大的长序列扩展能力: 能够支持高达256K token的序列长度进行训练,MFU仍能达到近88%。高容错性: 针对GPU数据中心常见的硬件故障问题,设计了高效的故障诊断和自动恢复机制。
InternEvo为InternLM2的成功奠定了坚实的工程基础。
3. Model Structure: LLaMA based
为了保证与现有开源生态的无缝衔接,InternLM2在模型结构上选择遵循LLaMA的设计原则。
基础架构: 采用标准的Transformer架构。关键组件:
归一化层: 使用RMSNorm替代LayerNorm。激活函数: 使用SwiGLU。注意力机制: 采用Grouped-Query Attention (GQA),这是一种在多头注意力(MHA)和多查询注意力(MQA)之间的折中方案,能够在保证性能的同时,显著减少长序列推理时的KV Cache显存占用。
结构优化:
权重矩阵合并: 将注意力机制中的
W_k
W_q
W_o
4. 第一阶段:预训练 (Pre-training) —— 2.6T数据
预训练是奠定LLM基础知识和能力的核心环节。InternLM2在**超过2.6万亿(Trillion)**个token的高质量数据上进行了预训练。
4.1 数据处理管线:从原始数据到高质量语料
团队详细介绍了他们针对通用文本和代码数据的多阶段处理管线。
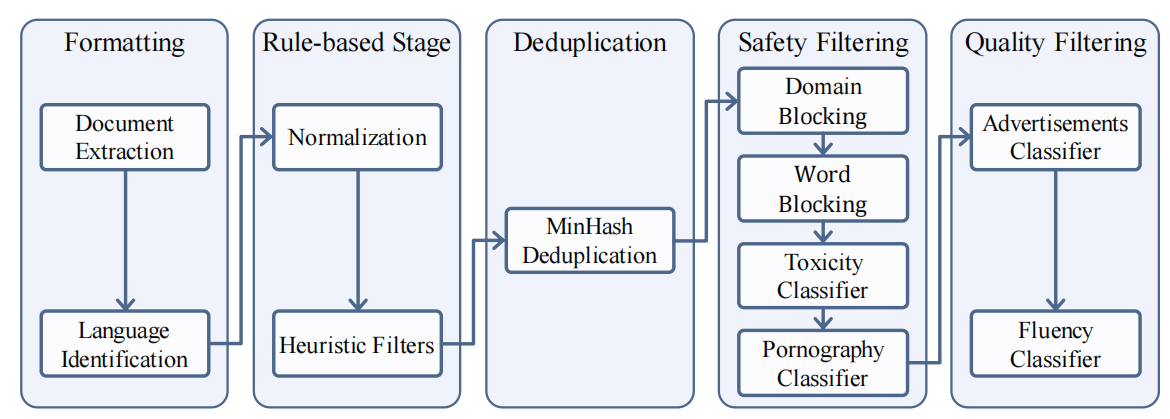
(InternLM2的文本数据处理管线,从格式化、规则清洗、去重、安全过滤到最终的质量过滤,层层递进。)
数据格式化 (Data Formatting): 将网页、论文、书籍等不同来源的数据统一转换为JSON Lines (jsonl) 格式。基于规则的清洗 (Rule-based Stage): 使用一系列启发式规则,过滤掉解析错误、格式混乱、非自然语言等低质量文本。去重 (Deduplication): 使用基于MinHash的**局部敏感哈希(LSH)**进行模糊去重,保留最新的数据。安全过滤 (Safety Filtering): 结合域名/关键词黑名单和基于BERT的毒性/色情内容分类器,进行多层次的安全过滤。质量过滤 (Quality Filtering):
通过人工标注,训练了一个广告分类器和一个流畅度分类器。使用这两个模型对数据进行二次过滤,筛选出逻辑连贯、信息量高的高质量内容。
4.2 长上下文数据专项处理
为了提升模型的长上下文能力,团队专门设计了一套针对长文本的过滤管线。
数据来源: 所有用于长上下文训练的数据,均来自标准预训练语料库的子集。过滤管线:
长度筛选: 筛选出字节数超过32K的样本。统计特征过滤: 基于词汇和语言学特征(如连词使用频率),过滤掉结构异常的长文本。困惑度(Perplexity)过滤: 创新性地使用困惑度差异来评估文本段落间的连贯性。如果一个段落S1的出现,反而使得后续段落S2的预测变得更困难(即
P(S2|S1) < P(S2)
4.3 长上下文:从4K到32K的“课程学习”
InternLM2的预训练并非一步到位,而是遵循了一个“由短到长”的课程学习策略。
第一阶段 (4k Context): 在约90%的训练步数中,使用长度不超过4096 token的语料进行训练。第二阶段 (32k Context): 在后续约9%的训练步数中,将训练语料切换为包含50%长度不超过32K token的高质量长文本。
在进入此阶段时,将RoPE(旋转位置编码)的base从50,000调整到1,000,000,以增强对长位置的编码能力。
第三阶段 (Capability Enhancement): 见下文。
这种策略使得模型首先在海量短文本上高效地学习基础知识,然后再逐步适应和学习长距离依赖。
4.4 增强训练 (Capability Specific Enhancement)
在预训练的最后阶段(约24B tokens),团队引入了一个精心策划的、包含高质量指令或专业数据的增强数据集,旨在“拔高”模型在编码、推理、问答、考试等关键能力上的表现。这批数据包括:
Retrieved Stem Data: 检索到的STEM领域数据。Retrieved Special Domain Data: 检索到的特定领域数据。Selected High Quality Data: 从Hugging Face等平台精选的高质量开源数据。
这个阶段使用了更小的学习率和批次大小,以确保模型能充分“吸收”这些高价值数据。
5. 第二阶段:对齐 (Alignment)
对齐的目标是让预训练好的基础模型(Base Model)能够理解并遵循人类的指令,同时符合人类的价值观(如有用、诚实、无害)。
5.1 监督微调 (SFT)
使用了一个包含1000万条指令样本的数据集,覆盖通用对话、NLP任务、数学、代码、安全等多个领域。将所有数据转换为ChatML格式。在7B和20B模型上训练一个epoch。
5.2 核心创新:COOL RLHF (Conditional Online RLHF)
标准的RLHF面临两大挑战:偏好冲突(如“有用”和“无害”有时会矛盾)和奖励滥用(模型学会“钻空子”以获得高分,而非真正提升能力)。InternLM2为此提出了COOL RLHF。
条件奖励模型 (Conditional Reward Model):
解决偏好冲突: 摒弃了为每种偏好(如helpful, harmless, math-correct)训练一个独立奖励模型的做法(如LLaMA2),而是使用一个单一的奖励模型。核心思想: 在计算奖励时,向奖励模型**提供一个条件系统提示(conditional system prompt)**来动态地引导其关注特定的偏好维度。例如,当评估“有用性”时,提供
"You should score the helpfulness."

(COOL RLHF的条件奖励模型架构,通过不同的系统提示,让单个奖励模型能够输出针对不同偏好维度的分数。)
在线RLHF (Online RLHF):
解决奖励滥用: 采用多轮在线的模式,在PPO训练过程中,不断地发现奖励模型的漏洞(即奖励滥用案例),并快速地将这些“补丁”数据加入到奖励模型的训练中,进行迭代更新。快慢路径 (Fast and Slow Paths):
快路径: 快速收集少量(20-100个)新发现的奖励滥用案例,用于“打补丁”,修复奖励模型的明显缺陷。慢路径: 通过持续的人工标注,全面地、系统性地提升奖励模型的整体能力上限。
5.3 长上下文微调与工具增强
长上下文对齐: 在SFT和RLHF阶段,都持续混入长上下文的预训练数据,以保持模型在对齐后依然具备强大的长上下文处理能力。工具调用: 采用了修改版的ChatML格式,引入了
environment
<|interpreter|>
<|plugin|>
6. 性能评估:在6大维度、30+基准上的卓越表现
InternLM2在多个公开基准测试上均展现了SOTA级别的性能。
综合与学科能力 (MMLU, C-Eval, AGIEval等): InternLM2-7B和20B在其各自的参数量级中,均名列前茅,显著优于LLaMA2, Mistral, Qwen等同期模型。语言、知识、推理与数学: 在语言知识、常识推理(WinoGrande, HellaSwag)和数学(GSM8K, MATH)等任务上均表现出色。长上下文:“大海捞针”测试近乎完美:
在200K长度的“大海捞针”测试中,InternLM2几乎能够100%地召回插入在文本中任意位置的“针”,证明了其强大的长上下文信息提取能力。在L-Eval和LongBench等长文本评测基准上,也取得了顶尖的成绩。
对齐与主观评估 (AlpacaEval, MTBench, CompassArena):
经过COOL RLHF对齐后,InternLM2-Chat模型在多个主观评估平台上(由GPT-4等更强模型作为裁判)取得了SOTA或接近SOTA的成绩,其胜率(Win Rate)显著高于SFT版本,证明了COOL RLHF的有效性。
7. 小结一下
InternLM2的发布及其技术报告的公开,对开源LLM社区具有里程碑式的意义:
性能标杆: 它在多个维度上为同量级的开源模型设立了新的性能标杆。技术透明度: 报告极为详尽地公开了从数据到模型、从预训练到对齐的全链路技术细节,为其他研究者和开发者提供了宝贵的、可复现的实践经验。创新范式: 其长上下文训练策略和COOL RLHF对齐方法,为解决行业共同面临的技术难题提供了创新的、有效的解决方案。生态贡献: 团队不仅开源了模型权重,还开源了训练过程中的多个检查点,这对于社区研究模型能力是如何在训练中逐步演化而来的,具有极高的价值。
InternLM2雄辩地证明了,通过精心的系统设计、海量的高质量数据工程以及创新的对齐策略,开源模型完全有能力追赶甚至在某些方面超越顶尖的闭源模型。它为我们描绘了一个更加开放、协同、繁荣的AI未来。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...