最近在AI圈子里混,常常听到有人问:”我到底该用LoRA还是RAG?”说实话,这个问题就像在问”我该吃米饭还是面条”一样,听起来简单,但背后的选择逻辑实则挺复杂的。
今天咱们就来聊聊这两个技术路线的真实差异,不搞那些官方文档式的废话,直接上干货。
先搞清楚它们到底是什么
- LoRA:给大模型”开小灶”
LoRA(Low-Rank Adaptation)说白了就是给现成的大模型”补课”。想象一下,你有个很机智的学生(预训练模型),但在某个特定领域表现不太行。你不需要让他从头学起,只要针对性地训练这个领域就行。
LoRA的核心思路是:我不动原模型的参数,而是在旁边加个”小本本”,记录针对特定任务的调整。这样既保持了原模型的通用能力,又能在特定任务上表现更好。
- RAG:给模型配个”百度一下”
RAG(Retrieval-Augmented Generation)的思路完全不同。它相当于给模型装了个实时搜索引擎。当你问问题时,模型先去知识库里搜相关信息,然后基于搜到的内容来回答。
就像你考试时可以查资料一样,RAG让模型能”临时抱佛脚”,实时获取最新、最准确的信息。
两者的本质区别在哪?
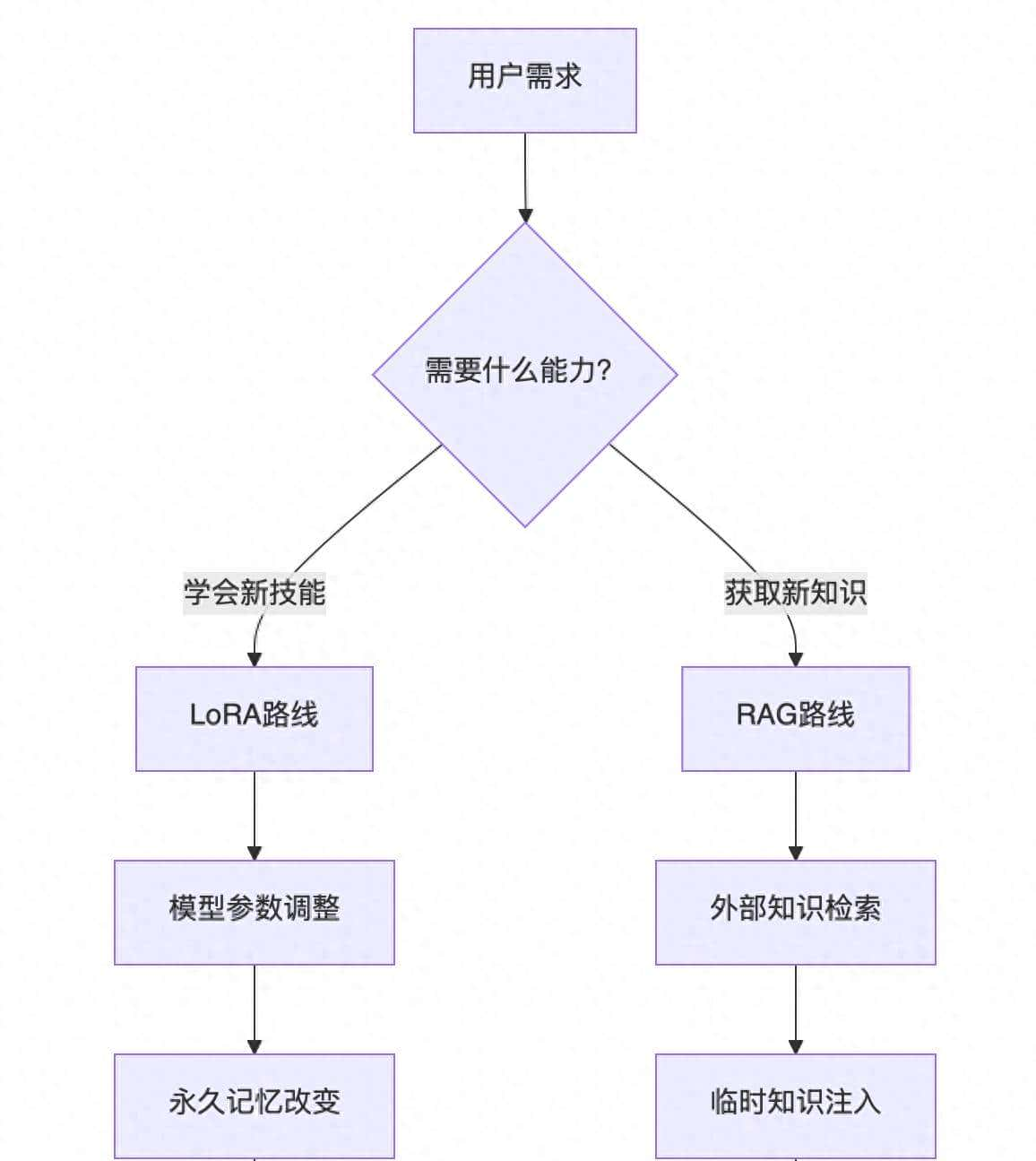
- 记忆方式不同
LoRA:就像学骑自行车,一旦学会就刻在脑子里了。模型的”肌肉记忆”被永久改变,即使不给额外信息也能表现出新的行为模式。
RAG:更像是带着手机查资料。每次回答问题都要先”搜一搜”,没有外部知识库就回到原始状态。
- 知识更新机制不同
LoRA:知识是”固化”的。训练完成后,除非重新训练,否则学到的东西不会变。就像你大学学的专业知识,毕业后基本定型。
RAG:知识是”流动”的。只要更新知识库,模型立马就能获取最新信息。今天更新数据库,今天就能回答最新问题。
什么时候该选LoRA?
1. 你想改变模型的”性格”
列如你想让一个通用模型变得更像客服、更像老师,或者说话风格更幽默。这种深层的行为模式改变,LoRA最拿手。
我之前做过一个项目,需要让模型用特定的专业术语和表达方式回答法律问题。用RAG的话,虽然能提供准确的法条信息,但说话方式还是很”AI”。用LoRA训练后,整个表达风格都变了,真的像个专业律师在说话。
2. 你的任务场景相对固定
如果你的应用场景比较单一,列如专门做医疗咨询、专门做代码生成,那LoRA就很合适。一次训练,长期受益。
3. 你不希望依赖外部系统
LoRA训练完后,模型就是个独立的个体,不需要连接数据库、不需要搜索引擎,部署起来特别简单。
LoRA的坑在哪?
- 灾难性遗忘:这是LoRA最大的痛点。训练新任务时,模型可能会”忘记”之前学的东西。就像学了新技能,把老技能给忘了。
- 数据需求大:想要好效果,你需要大量高质量的训练数据。而且数据质量直接决定最终效果,垃圾进垃圾出。
- 成本不透明:表面上看LoRA便宜,但算上数据准备、训练时间、试错成本,实则不必定省钱。
什么时候该选RAG?
1. 你需要最新、最准确的信息
做新闻资讯、股票分析、实时数据查询这类应用,RAG是不二选择。模型可能不知道昨天发生了什么,但RAG可以让它瞬间变成”消息灵通人士”。
2. 你的知识领域很广泛
如果你要做一个什么都能聊的助手,涉及历史、科学、娱乐、时事等各个领域,RAG比LoRA更practical。你不可能为每个领域都训练一个LoRA模型。
3. 你需要可解释性
RAG有个天然优势:你能看到模型参考了哪些资料。当用户质疑答案时,你可以说”这是根据XXX文档得出的结论”。这种透明度在许多场景下很重大。
RAG的坑在哪?
- 检索质量决定一切:RAG的效果上限就是你的知识库质量。垃圾知识库+完美检索算法=垃圾答案。
- 延迟问题:每次回答都要先搜索,必然带来延迟。虽然目前检索速度很快,但对于实时性要求极高的场景还是个问题。
- 成本隐性增长:看起来RAG不需要训练成本,但维护知识库、优化检索系统的成本可能比你想象的高。
实际选择策略
场景导向的决策树
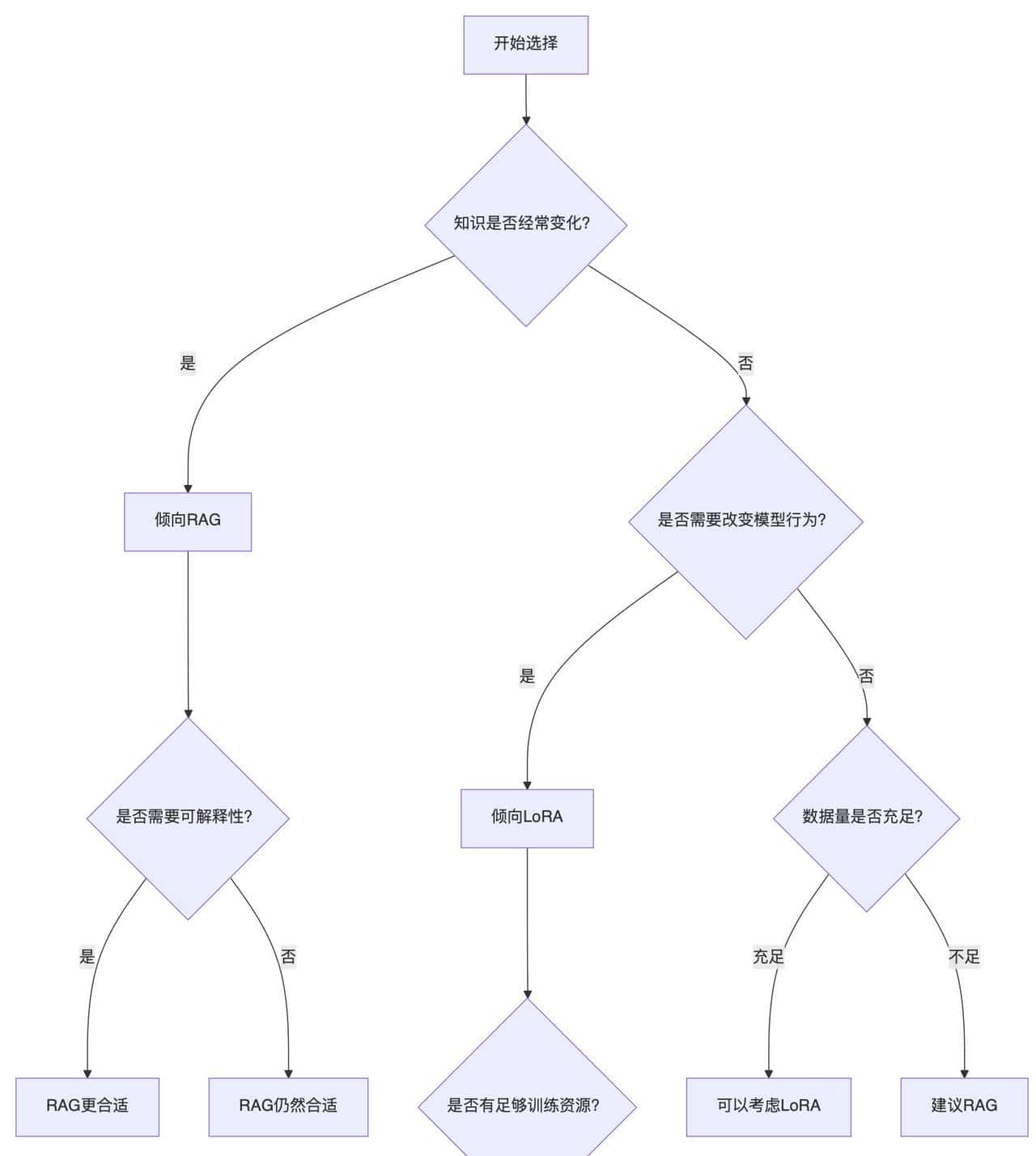
我的提议框架
优先思考RAG的情况:
- 创业公司,资源有限,需要快速验证想法
- 知识密集型应用,需要准确的实际信息
- 多领域通用助手
- 对可解释性有要求
- 团队缺乏深度学习经验
优先思考LoRA的情况:
- 有明确的垂直领域focus
- 需要特定的交互风格或personality
- 有充足的高质量训练数据
- 团队有ML训练经验
- 对响应速度要求极高
组合拳:为什么不两个都要?
实则许多时候,LoRA和RAG不是非此即彼的关系。你完全可以:
- 用LoRA调整基础能力:让模型在特定领域更professional
- 用RAG补充实时信息:确保信息的时效性和准确性
列如做一个金融分析助手:
- LoRA让模型学会专业的金融术语和分析框架
- RAG提供最新的市场数据和新闻信息
这样搭配,效果往往比单独使用任何一种都要好。
成本这笔账怎么算?
- LoRA的真实成本
别只看GPU训练费用,还要算:
- 数据收集和清洗:这可能是最贵的部分
- 实验和调优:很少有人一次就成功
- 版本管理和部署:每个版本都要单独维护
- 机会成本:训练期间不能快速响应需求变化
- RAG的隐性成本
表面上看RAG不需要训练,但要思考:
- 知识库建设和维护:这是个持续性工作
- 检索系统优化:embedding、索引、查询优化都需要专业技能
- 数据更新流程:自动化更新系统的开发和维护
- 服务器和存储:实时检索对基础设施要求不低
- 我的成本提议
- 初期: 先用RAG验证idea,快速迭代
- 中期: 如果效果不错,思考用LoRA优化core功能
- 长期: 混合使用,LoRA负责基础能力,RAG负责信息更新
写在最后
选LoRA还是RAG,本质上是在选择不同的技术哲学:
LoRA信任专精: 深度定制,一招制胜
RAG信任广博: 灵活应对,博采众长
没有标准答案,只有最适合你当前情况的答案。
我的提议是:如果你还在纠结,那就先从RAG开始。它的试错成本更低,见效更快,更容易让你的产品活下来。等有了用户反馈和足够的数据积累,再思考用LoRA做深度优化。
毕竟,活着比完美更重大。
P.S. 技术选型没有完美的,只有合适的。重大的是快速行动,在实践中调整。理论再完美,不如用户的一个真实反馈来得有价值。
#ai# #头条创作挑战赛# #智能体# #rag# #lora# #头条首发大赛#
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...