引言
在日常开发中,分页查询接口往往需要执行两条SQL:一条获取数据,另一条使用count(*)统计总数。其中,count(*)在数据量较大时常常成为性能瓶颈。本文基于实际优化经验,深入剖析count(*)性能问题根源,并提供五种实用优化方案,协助开发者提升查询效率。
一、为什么 count(*) 性能差?
存储引擎差异是关键
- MyISAM:将表的总行数直接存储在磁盘上,count(*)直接返回该值,无需计算,效率极高。
- InnoDB:支持事务和MVCC(多版本并发控制),同一时间点不同事务中,行数可能不一致。count(*)需逐行扫描并统计,导致性能低下,尤其在大数据量表上表现明显。
二、五大优化方案详解
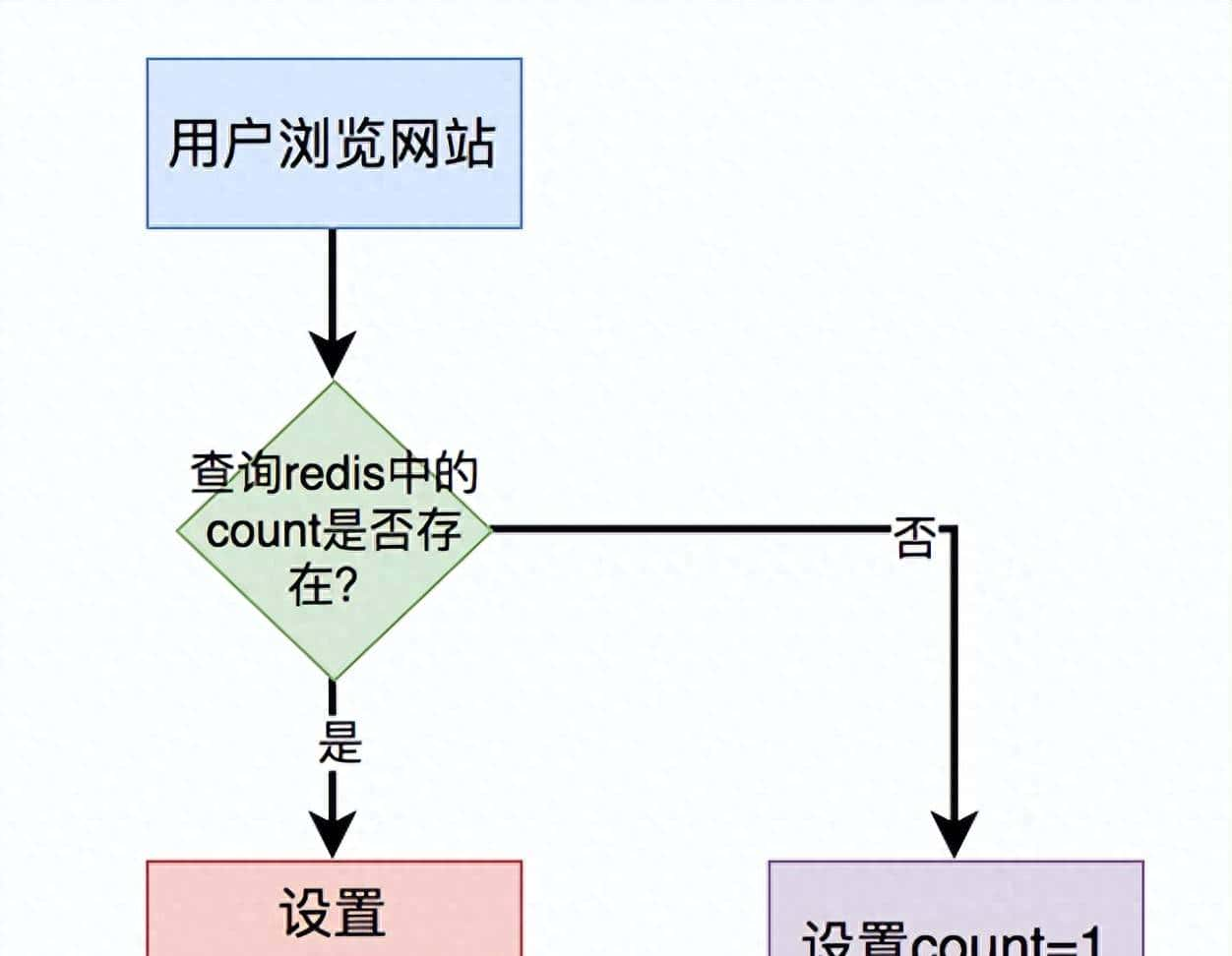
1. Redis 缓存:简单计数的首选
适用场景:浏览次数、访问人数等对准确性要求不高的统计。
实现方式:
- 用户访问时,通过Redis的原子操作(如INCR)递增计数。
- 首次访问初始化计数,后续直接操作缓存,避免数据库查询。
优点:性能提升显著,减少数据库压力。
缺点:可能存在数据不一致,但可容忍。
2. 二级缓存:复杂查询条件的利器
适用场景:查询条件多样(如多字段组合筛选),数据更新频率低。
工具推荐:SpringBoot集成Caffeine或Guava。
实现示例:
@Cacheable(value = "brand", keyGenerator = "cacheKeyGenerator")
public BrandModel getBrand(Condition condition) {
return getBrandByCondition(condition); // 实际查询数据库
}关键点:
- 自定义KeyGenerator,根据查询条件生成缓存键。
- 设置合理过期时间(如5分钟),平衡实时性与性能。
注意:分布式环境可能导致缓存不一致,需根据业务需求评估。
3. 多线程执行:并行统计多维数据
适用场景:需同时统计多个状态或类别(如订单有效/无效数)。
传统问题:同步执行多条count(*)SQL效率低。
优化方案:
- 使用CompletableFuture异步执行多条统计SQL。
- 示例代码:
CompletableFuture<Long> validOrderFuture = CompletableFuture.supplyAsync(() -> countValidOrders(), executor);
CompletableFuture<Long> invalidOrderFuture = CompletableFuture.supplyAsync(() -> countInvalidOrders(), executor);
// 合并结果
Long validCount = validOrderFuture.get();
Long invalidCount = invalidOrderFuture.get();优势:利用多核CPU并行处理,缩短总响应时间。
4. 减少 JOIN 表:简化查询逻辑
适用场景:多表关联查询时,优先检查是否可简化为单表查询。
案例对比:
-- 优化前:多表JOIN
SELECT COUNT(*) FROM product p
INNER JOIN unit u ON p.unit_id = u.id
INNER JOIN brand b ON p.brand_id = b.id
INNER JOIN category c ON p.category_id = c.id
WHERE p.name = '测试商品';
-- 优化后:单表查询
SELECT COUNT(*) FROM product
WHERE name = '测试商品'
AND unit_id = 123
AND brand_id = 124
AND category_id = 125;效果:避免JOIN操作带来的性能开销,提升查询效率。
5. 改用 ClickHouse:大数据量的终极方案
适用场景:数据量极大、查询条件复杂且无法减少JOIN。
实现步骤:
- 通过Canal监听MySQL Binlog,实时同步数据到ClickHouse。
- 在ClickHouse中预聚合数据,直接查询结果。
优点:ClickHouse列式存储和向量化查询带来秒级响应。
注意: - 适合批量写入,避免频繁单条插入。
- 替代方案:Elasticsearch(但存在深分页问题)。
三、count 家族性能对比
性能排序从高到低:
- count(*) ≈ count(1):直接统计行数,无需解析字段,效率最高。
- count(id):需解析主键字段(非NULL),稍慢。
- count(普通索引列):需判断字段是否为NULL,索引协助有限。
- count(未加索引列):全表扫描并判断NULL,性能最差。
结论:优先使用count(*)或count(1),避免使用未索引字段计数。
四、总结
- 根因分析:InnoDB的MVCC机制导致count(*)需实时统计,性能低下。
- 方案选择:简单计数 → Redis缓存复杂查询 → 二级缓存多维度统计 → 多线程并行多表关联 → 减少JOIN或改用ClickHouse
- 最佳实践:结合业务场景灵活选用,兼顾性能与数据一致性。
通过以上优化,可显著提升count(*)性能,实现从慢查询到高效统计的转变。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...