目录
一、背景1.1、为什么 ChatGPT 能成为增长最快的应用1.2、LLM
二、用户视角的大模型2.1、知识丰富2.2、知人晓事2.3、知错就改2.4、知法守法
本文来源:极客时间vip课程笔记
一、背景
1.1、为什么 ChatGPT 能成为增长最快的应用
我们都知道,这一波的 AI 浪潮始于 2022 年底的 ChatGPT 发布,有一幅图,很多人都见过,它说明 ChatGPT 是人类有始以来最快突破一亿用户的应用,用时仅仅 2 个月。
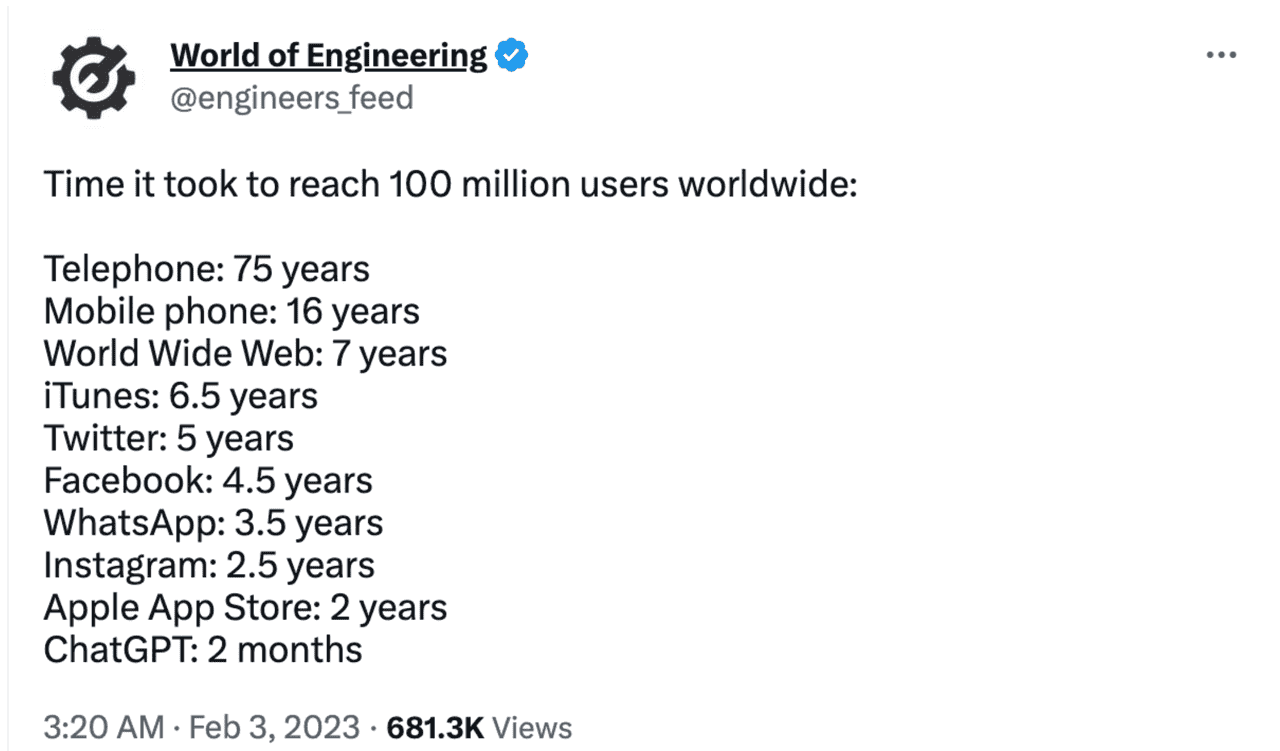 一个重要的因素是 ChatGPT 是以聊天的形式呈现。拜诸如微信、WhatsApp 之类即时聊天工具所赐,人们已经非常习惯在文本框里输入文字的交流方式,这是普通人能够理解 ChatGPT 的基础,也是 ChatGPT 得以破圈的关键原因。如果说最初吸引用户的原因是聊天模式的熟悉感,那么留住用户的就是 ChatGPT 的优异表现,这背后的支撑是 GPT 模型,它是大语言模型里最有代表性的一个。AI 应用开发主要用的就是大语言模型(Large Language Model,LLM)
一个重要的因素是 ChatGPT 是以聊天的形式呈现。拜诸如微信、WhatsApp 之类即时聊天工具所赐,人们已经非常习惯在文本框里输入文字的交流方式,这是普通人能够理解 ChatGPT 的基础,也是 ChatGPT 得以破圈的关键原因。如果说最初吸引用户的原因是聊天模式的熟悉感,那么留住用户的就是 ChatGPT 的优异表现,这背后的支撑是 GPT 模型,它是大语言模型里最有代表性的一个。AI 应用开发主要用的就是大语言模型(Large Language Model,LLM)
1.2、LLM
它是模型,是 AI 能力的核心。它是语言模型,其核心能力在于语言能力。它是大语言模型,与传统模型相比,它最大的特点就是“大”。
二、用户视角的大模型
我们利用大模型编程,就是在扮演大模型用户的角色。我们想要有效地使用大模型,就需要让自己成为大模型的高级用户,这就需要我们站在用户的视角理解大模型的特点。理解了这些特点,除了有助于我们更好地理解 AI 应用如何开发,也有助于我们日常更好地使用像 ChatGPT 这样的应用。
下面我们就以 GPT 模型为例,介绍大模型的典型特点,我把 GPT 特点总结为四个“知”:
知识丰富:GPT 拥有海量的知识,可以回答各种类型的问题,涉及的领域也非常广泛,包括历史、文化、科学、技术等诸多方面。
知人晓事:GPT 能够根据上下文理解人们的意图和兴趣,提供个性化的回答和解决方案。它会基于聊天的过程中了解到的用户信息做出最为切合的回应。
知错就改:GPT 能在对话中不断学习和改进。如果用户指出它的某个回答存在问题,它会承认错误,并学习从中改进,在将来的对话中避免类似错误。
知法守法:GPT 会遵守道德和法律规范,不会作出危险、不道德或违法的回应,也不会对危险问题给予回应。这样既确保了用户交互的合法性和安全性,也确保了自己不会被利用去破坏社会秩序。
2.1、知识丰富
在 AI 领域中,一个模型能力强弱很大程度上取决于其训练数据量的多寡。大语言模型的“大”主要是指数据量大。在训练模型的过程中,Open AI 采用了海量的数据,如维基百科、新闻报道、小说、社交媒体帖子等。有了海量数据的加持,GPT 几乎对大部分已有的知识都有所了解。也是因为 GPT 的训练数据源非常广泛,它可以回答许多类型的问题,并能够为用户提供很多有用的信息。对于大部分的知识类问题,GPT 都能够给出一个合适的答案。比如,在下面的对话中,我问 GPT 太阳系有多少行星,GPT 就给出了简明扼要的回答。当我把这个话题从行星进一步延伸到小行星,它给出的回复依然是非常经典。

2.2、知人晓事
GPT 还展现出了较强的“知人晓事”的能力,它能够根据上下文理解人们的意图和兴趣,作出的回答不是僵化的,而是个性化的。首先,GPT 能够理解人类语言,并作出相应的回答。从表现上看,它会分析输入的文本,理解话语背后的意图和重点,然后给出相关的回复。如果用户问一个开放的问题,它会考虑多个方面后作出回答;如果用户的问题较为具体,它也能给出相应的明确回复。其次,GPT 能够根据不同的交流对象和环境,理解他们的不同立场与需求,并据此调整自己的回复角度。如果用户是一个小孩子,它会用简单易懂的言语来回答问题。如果用户是一个专业人士,它可以使用更加专业的词汇和表达方式。如果用户提到自己处于某个具体的环境中或剧情场景下,GPT 也能站在对应的角度来构思回答。这体现了它对人与语境的深刻理解。在下面的例子里,我请 GPT 给小学生解释一下氧气的作用,我们不难看出,这个回答还是相当浅显易懂的,非常适合让小学生去理解。
 深入地理解 GPT 的这个“知人晓事”的特点,对于用好 GPT 而言,是至关重要的。市面上有大量的提示词模板,其中,设定角色是很多提示词模板的关键操作,这一设定的关键就是利用 GPT 知人晓事的特点。我们可以根据自己的需求,选择以不同的角色、不同的角度与 GPT 对话,它都可以做到理解与回应。这也使得与 ChatGPT 的交流变得生动有趣,不再单一枯燥。正是因为具有“知人晓事”这一特点,相比于传统的对话机器人,ChatGPT 看上去才是那么善解人意,这也是它受欢迎的一个重要原因。
深入地理解 GPT 的这个“知人晓事”的特点,对于用好 GPT 而言,是至关重要的。市面上有大量的提示词模板,其中,设定角色是很多提示词模板的关键操作,这一设定的关键就是利用 GPT 知人晓事的特点。我们可以根据自己的需求,选择以不同的角色、不同的角度与 GPT 对话,它都可以做到理解与回应。这也使得与 ChatGPT 的交流变得生动有趣,不再单一枯燥。正是因为具有“知人晓事”这一特点,相比于传统的对话机器人,ChatGPT 看上去才是那么善解人意,这也是它受欢迎的一个重要原因。
2.3、知错就改
虽然拥有广博的知识和理解能力,但在回答问题的过程中,GPT 也难免会出现错误或不够准确的回答。这主要是以下几个原因造成的:
数据源的不确定性:GPT 的知识库是通过从互联网上收集的数据来构建的。然而,这些数据的质量和准确性并不是完全可靠的。有些数据来源可能存在着错误和偏见,这就会对 GPT 的知识产生一定的影响。
训练数据的不足:GPT 是通过对大量的文本数据进行训练来学习语言知识的。然而,这些训练数据并不包含所有的知识,有些领域的知识甚至没有包含在训练数据中。因此,当 GPT 回答某些特定领域的问题时,就可能出现错误。
语言的歧义性:人类语言是具有歧义性的。同样的一句话,在不同的语境下可能会有不同的含义。尽管 GPT 能够理解人类语言,但是在处理歧义性问题时,它仍然可能出现错误。
模型的局限性:GPT 是一种基于模型的 AI 技术。它的回答主要基于模型的计算结果,而这些计算结果可能受到模型的局限性影响。例如,模型的计算能力不足,或者模型的结构不够优秀,都会对模型的回答产生一定的影响。
由于这些不足的存在,我们经常会看到 GPT 出现所谓“一本正经的胡说八道”。虽然 GPT 可能犯错,但它具有“知错就改”的特点。当你指出 GPT 回答有误时,它会在内部对问题进行重新分析和处理,从而得出更加准确和恰当的回答。下面的例子是我使用 GPT 3.5 时出现的问题:

2.4、知法守法
Open AI 在模型训练过程中对 GPT 进行一定程度的限制,确保其产生的所有内容都符合法律和道德规范,不会给用户或社会带来负面影响。
首先,GPT 生成的每条回答都经过严格检验,不会包含任何非法、危险或不良信息,这包括但不限于涉及版权、隐私、人身安全等方面。比如,当用户提问关于盗版软件下载的问题时,GPT 会明确告知用户这种行为是非法的,并引导用户寻找合法途径。在一些政治敏感话题上,GPT 也需要遵守相应的法律法规,避免在涉及政治、宗教、种族等方面出现偏见或不当言论。
其次,当提出的问题存在不良倾向时,GPT 也需要给予关怀和引导。比如,当用户提问与自杀相关的问题时,GPT 不会简单地给出“建议自杀”的回答,而会尽力引导用户寻求专业的帮助和支持,避免对用户造成不良影响。类似地,当用户提问涉及违法犯罪的问题时,GPT 也会明确告知用户这种行为是违法的,并引导用户寻找合法的解决方案。
在下面的例子里,我问了 GPT 一个不恰当的问题,GPT 没有回答我怎么做,而是提醒我,这种做法是不合适的。

至此,我们已经对大模型有了一个初步的了解,这些内容虽然是针对 GPT 进行讲解的,但由于技术上的通用性,其它的 LLM 也基本上可以这样理解。下一讲,我们将会从技术角度再来理解一下大模型。
注:后续技术类文章会同步到我的公众号里,搜索公众号 小志的博客 感兴趣的读友可以去找来看看。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...








