
大家都知道在计算机的世界里,一切都是由0和1组成的。对于计算机而言,”猫” 和 “狗” 这两个词,本质上只是两个不同的字符串编码(列如UTF-8编码),它们之间没有任何内在联系。计算机无法像人一样,凭直觉就知道猫和狗都是宠物,都是哺乳动物,它们在概念上是相近的。这种理解语义(Meaning)的能力,是传统计算与人智能之间一道巨大的鸿沟。

直到一个概念的出现,提供了跨越这条鸿沟的钥匙,那就是——向量(Vector)。
如今,从你手机上的智能推荐,到与你对话的大语言模型(LLM),其背后都离不开向量的支撑。向量不仅是数学家工具箱里的常客,更已成为现代人工智能的“通用语言”。
本文从以下三个方向探讨向量的作用:
- 什么是向量? 它如何从一个纯数学概念,演变为承载世间万物语义的“数字灵魂”。
- 大语言模型(LLM)如何处理向量? 揭示LLM“思考”和“推理”的内部机制。
- 向量数据库扮演什么角色? 为什么说它是LLM不可或缺的“外接大脑”和“长期记忆”。
一、什么是向量?
1.1 向量的数学本源
在中学数学中,我们就接触过向量。它一般被定义为在空间中具有大小和方向的量。在二维坐标系中,一个从原点 (0,0) 指向 (3,4) 的箭头就是一个向量,我们可以用数组 [3, 4] 来表明它。
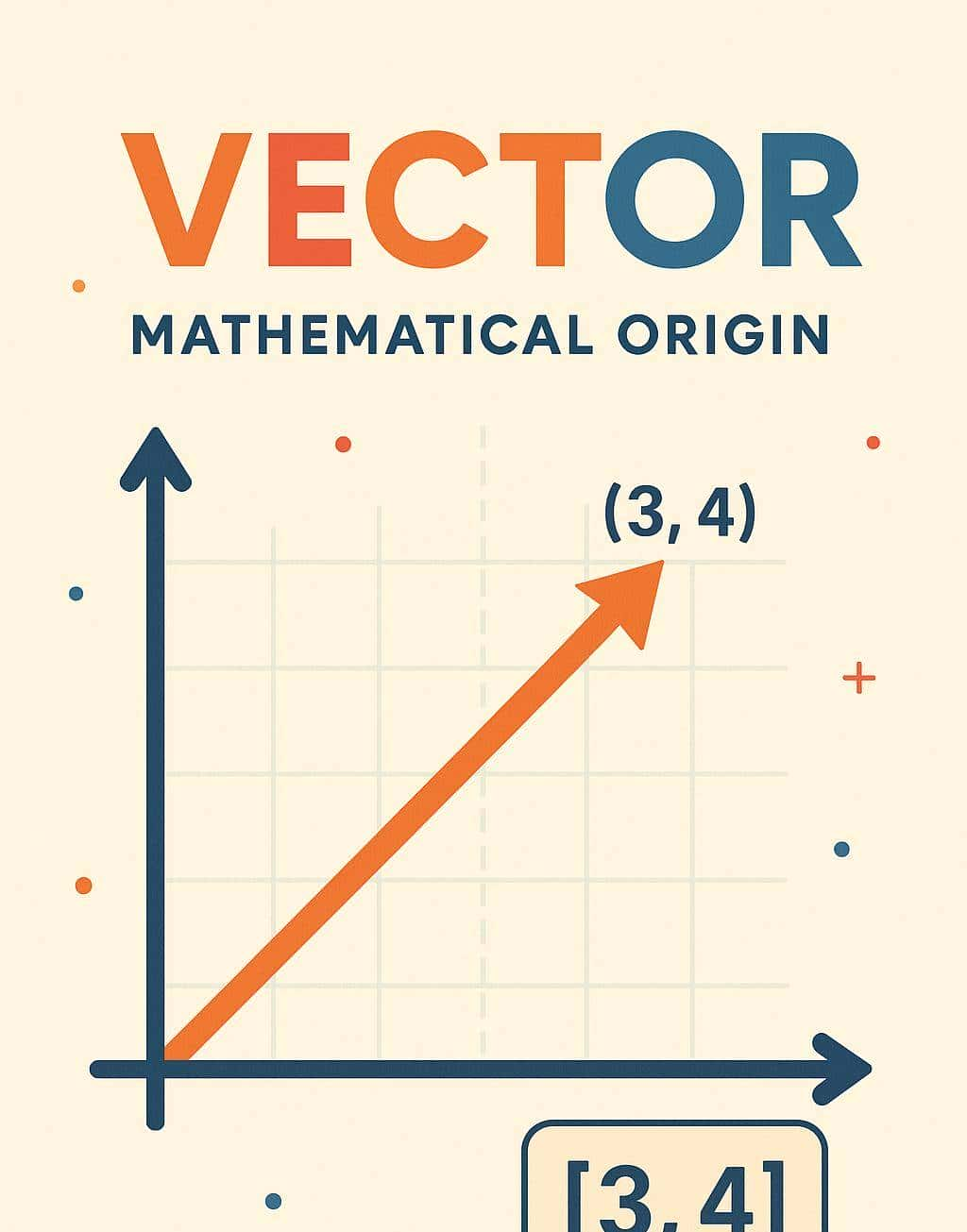
- 大小(Magnitude):代表向量的长度,可以通过勾股定理计算(√(3²+4²) = 5)。
- 方向(Direction):代表向量在空间中所指向的方向。
我们可以计算两个向量之间的距离(如欧氏距离)或夹角(如余弦类似度),从而判断它们在空间中的接近程度和方向的类似性。这是向量最基础、也最重大的特性。
1.2 语义向量(Embeddings)的诞生
如果说二维或三维空间可以表明物理位置,那么我们是否可以构建一个拥有成百上千个维度(dimensions)的高维空间,用它来表明抽象的概念呢?
科学家们正是这么做的。他们提出,世界上所有的概念——无论是单词、句子、段落,还是一张图片、一段音频——都可以被表明为这个高维空间中的一个向量。这个过程,我们称之为嵌入(Embedding)。
这个高维空间,我们称之为语义空间(Semantic Space)。在这个空间里,向量的核心特性被赋予了新的含义:
物理空间上的距离 = 语义概念上的类似度
这意味着,如果两个向量在语义空间中的位置超级接近,那么它们所代表的概念在意义上也是类似的。
- 向量 [0.1, 0.8, …] 可能代表“猫”。
- 向量 [0.12, 0.78, …] 可能代表“小猫”。
- 向量 [0.15, 0.82, …] 可能代表“虎斑猫”。
- 向量 [0.3, 0.6, …] 可能代表“狗”。
- 向量 [0.9, 0.2, …] 可能代表“汽车”。
你会发现,“猫”相关的向量聚集在一起,离“狗”的向量不远,但离“汽车”的向量超级遥远。这种神奇的特性,使得数学运算可以直接应用于语义理解。例如,著名的 vector('King') – vector('Man') + vector('Woman') 的结果,在语义空间中与 vector('Queen') 的向量极为接近。
1.3 向量是如何产生的?
那么,这种能捕捉语义的向量是如何出来的呢?它们并非由人手动设计,而是通过模型训练学习到的。
这个过程可以类比为一位机智的图书馆管理员整理书籍:
- 海量数据输入:给模型“阅读”海量的文本(如整个维基百科)。
- 上下文学习:模型(如早期的Word2Vec,或现代的BERT、GPT等)的目标是根据一个词的上下文来预测这个词,或者反之。例如,在“一只___在追逐老鼠”这句话中,模型需要学会预测出“猫”这个词。
- 调整向量位置:为了更好地完成预测任务,模型会不断调整每个词的向量表明。如果两个词(如“猫”和“小猫”)常常出目前类似的语境中,模型就会自不过然地将它们的向量在语义空间中拉近。
- 最终产出:训练结束后,模型就为词汇表中的每个词都生成了一个高维向量。这个过程就像管理员最终为每本书都分配了一个独特的编码,内容类似的书籍编码也相近。
这个负责将原始数据(文本、图片等)转换为向量的模型,称之为编码器(Encoder)。
二、大语言模型(LLM)如何“思考”?—— 向量的运算与推理
当我们向ChatGPT这样的LLM提问时,它并不是在“阅读”我们的文字,而是在处理我们文字所对应的向量。向量。

2.1 LLM的核心语言
理解LLM工作原理的第一步,就是要彻底抛弃“模型理解文字”的观念,建立“模型处理向量”的认知。整个过程可以分解为以下几个核心步骤。
2.2 LLM处理向量的全过程
假设我们向LLM输入一句话:“中国的首都是哪里?”
- 分词(Tokenization)
LLM第一会将这句话切分成它能理解的最小单元,即Tokens。这个过程可能产生类似 [“中国”, “的”, “首都”, “是”, “哪里”, “?”] 这样的结果。Token是模型词汇表中的基本单位。 - 嵌入(Embedding)
接下来,LLM会调用它的嵌入层(Embedding Layer),将每一个Token转换为一个高维向量。 - 此时,我们得到了一组代表原始句子中每个Token的初始向量。这些向量包含了每个Token的孤立语义,但还没有上下文信息。
- “中国” -> v_china = [0.5, 0.2, …, -0.1]
- “首都” -> v_capital = [0.7, 0.6, …, 0.3]
- …
- 注意力机制(Attention Mechanism)—— 核心中的核心
这是LLM(特别是其底层的Transformer架构)能够理解上下文、展现出“智能”的关键所在。注意力机制允许模型在处理一个Token时,“关注”到句子中所有其他Token,并判断它们之间的关联性。 - 这个过程在数学上是通过向量运算实现的:
- 通过这个过程,模型为每个Token生成了一个新的、融合了上下文信息的向量。
- 例如,在处理“首都”这个Token时,注意力机制会发现它与“中国”的向量关联性极高。因此,在生成“首都”的新向量时,会大量融入“中国”向量的信息。最终,“首都”的向量就不再是一个泛指的“capital”,而是一个特指“capital of China”的、高度情境化的向量。
- 这个过程会在模型的多个层(Transformer Blocks)中反复进行,每一层都会让向量的语义表达更加丰富和准确。
- 计算关联度:模型会计算当前处理的Token向量(查询Query)与句子中所有其他Token向量(键Key)之间的点积(Dot Product)。点积的结果越大,代表两个向量在方向上越类似,即语义关联性越强。
- 加权求和:然后,模型使用这些关联度分数(经过Softmax归一化后)作为权重,对句子中所有Token的向量(值Value)进行加权求和。
- 生成(Generation)
经过多层Transformer的处理后,LLM得到了一个包含完整上下文信息的最终向量。它的任务是基于这个向量,预测下一个最有可能出现的Token。 - 模型会生成一个概率分布,列出词汇表中所有Token成为下一个Token的可能性。
- 在我们的例子中,”北京” 这个Token的向量,会由于与输入问题最终形成的上下文向量高度类似,而获得最高的概率。
- 模型选择“北京”,将其作为新的输入,然后重复上述过程,直到生成完整的回答或遇到终止符。
2.3 一个生动的比喻:生日会
想象你参与一个生日会。你(一个Token)想了解大家在聊什么(理解上下文)。
- 初始状态:你只知道自己的身份(初始向量)。
- 注意力机制:你开始“竖起耳朵”,倾听周围每个人的谈话(计算与其他Token向量的关联度)。你发现A和B在聊电影,C和D在聊体育。你与A和B的谈话内容更契合(关联度高)。
- 形成上下文理解:你将听到的、与你相关度高的信息(A和B的谈话)进行整合,形成了对当前派对氛围的理解(生成了新的、包含上下文的向量)。
- 发言:当有人问你问题时,你基于这个理解来组织语言,做出得体的回应(生成下一个Token)。
LLM的每一层,都像是在这个生日会上进行一轮更深入的“社交”和“倾听”,从而让自己的理解越来越深刻。
三、向量数据库 —— LLM的长期记忆
尽管LLM内部的向量处理能力极其强劲,但它自身存在几个固有缺陷。
3.1 LLM的局限性
- 知识截止日期:LLM的知识被“冻结”在它训练完成的那一刻。它不知道之后发生的新闻、发布的财报或更新的产品信息。
- 上下文窗口限制(Context Window):LLM一次能处理的Token数量是有限的(如几千到几十万不等)。你无法将一本完整的书或整个公司的内部文档一次性“喂”给它。
- 私有性与数据安全:对于企业而言,将敏感的内部数据上传给第三方LLM进行微调(Fine-tuning),存在数据泄露的风险,且成本高昂。
- 幻觉(Hallucination):当被问及不确定的信息时,LLM有时会“一本正经地胡说八道”,编造看似合理但完全错误的实际。
如何让LLM拥有可更新的、海量的、私有的长期记忆?答案就是向量数据库。
3.2 什么是向量数据库?
向量数据库是一种专门为存储、索引和查询海量高维向量而优化的数据库。

与存储结构化数据(如行和列)的关系型数据库(如MySQL)不同,向量数据库的核心功能只有一个:类似性搜索(Similarity Search)。它的任务是:
给定一个查询向量(Query Vector),在数以百万计甚至数十亿的向量集合中,以毫秒级的速度,找到与它最类似的 K 个向量(即“最近邻”)。
3.3 核心技术:近似最近邻(ANN)搜索
如果暴力搜索,即用查询向量与数据库中的每一个向量计算距离,那么当数据量达到百万级时,查询将慢得无法接受。因此,向量数据库的“魔法”在于其高效的**近似最近邻(Approximate Nearest Neighbor, ANN)**索引算法。

ANN的核心思想是:牺牲一点点精度,换取数量级的速度提升。它不保证100%找到最准确的近邻,但在99%以上的准确率下,将搜索速度提升成千上万倍。
3.4 RAG(检索增强生成)—— LLM与向量数据库组合
RAG(Retrieval-Augmented Generation)是目前将LLM与私有知识结合应用最主流、最高效的范式。它完美地将向量数据库的“检索能力”与LLM的“生成能力”结合起来。
四、应用场景
向量技术与LLM、向量数据库的结合,正在催生一场深刻的产业变革。
4.1 实际应用案例
- 智能语义搜索:企业内部的“Google”,员工可以像对话一样搜索公司所有文档,找到最相关的信息,而不仅仅是匹配关键词。
- 个性化推荐系统:通过将用户行为和商品信息向量化,可以为用户推荐他们可能从未见过、但与其“品味向量”高度类似的商品。
- 智能客服与问答:基于企业的产品手册、FAQ文档构建RAG系统,7×24小时为客户提供精准、可靠的回答。
- 多模态检索:在向量数据库中存储图片、音频、视频的向量,实现“以图搜图”、“以歌搜歌”等高级功能。
- 代码辅助与生成:将代码库向量化,协助开发者查找类似功能的代码片段,甚至自动生成符合项目规范的新代码。
总结
- 大语言模型(LLM),是强劲的“向量处理器”,它通过复杂的向量运算(如注意力机制)来理解上下文、进行推理和创造。
- 向量数据库,则是LLM的“外部记忆体”,通过高效的RAG架构,为LLM提供了海量的、可更新的、安全的知识支持。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...






