深入探讨三个典型的人工智能与深度学习应用案例:图像分类(使用卷积神经网络)、自然语言处理中的文本生成(使用Transformer模型)以及时间序列预测(使用LSTM)。
案例一:基于CNN的图像分类(CIFAR-10)
1. 背景介绍
CIFAR-10 是一个经典的图像分类数据集,包含60,000张32×32彩色图像,分为10个类别(如飞机、汽车、鸟等),常用于测试深度学习模型性能。卷积神经网络(CNN)因其在图像识别任务中的卓越表现,成为该任务的首选架构。
2. 技术原理
CNN通过卷积层自动提取图像的空间特征,池化层降低维度,全连接层进行分类。其核心优势在于局部感受野和参数共享,能有效捕捉图像的平移不变性。
3. 代码实现(Python + TensorFlow/Keras)
python
编辑
import tensorflow as tf
from tensorflow.keras import layers, models
import matplotlib.pyplot as plt
# 加载并预处理数据
(x_train, y_train), (x_test, y_test) = tf.keras.datasets.cifar10.load_data()
x_train, x_test = x_train / 255.0, x_test / 255.0
# 构建CNN模型
model = models.Sequential([
layers.Conv2D(32, (3, 3), activation='relu', input_shape=(32, 32, 3)),
layers.MaxPooling2D((2, 2)),
layers.Conv2D(64, (3, 3), activation='relu'),
layers.MaxPooling2D((2, 2)),
layers.Conv2D(64, (3, 3), activation='relu'),
layers.Flatten(),
layers.Dense(64, activation='relu'),
layers.Dense(10, activation='softmax')
])
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
# 训练模型
history = model.fit(x_train, y_train, epochs=10,
validation_data=(x_test, y_test))
# 可视化训练过程
plt.figure(figsize=(12, 4))
plt.subplot(1, 2, 1)
plt.plot(history.history['accuracy'], label='Training Accuracy')
plt.plot(history.history['val_accuracy'], label='Validation Accuracy')
plt.title('Model Accuracy')
plt.xlabel('Epoch')
plt.ylabel('Accuracy')
plt.legend()
plt.subplot(1, 2, 2)
plt.plot(history.history['loss'], label='Training Loss')
plt.plot(history.history['val_loss'], label='Validation Loss')
plt.title('Model Loss')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.legend()
plt.show()4. Mermaid 流程图
flowchart TD
A[开始] –> B[加载CIFAR-10数据集]
B –> C[归一化像素值到[0,1]]
C –> D[构建CNN模型]
D –> E[编译模型: Adam优化器, 交叉熵损失]
E –> F[训练模型: 10轮]
F –> G{验证准确率 > 70%?}
G — 是 –> H[保存模型]
G — 否 –> I[调整超参数]
I –> D
H –> J[结束]
5. Prompt 示例(用于AI辅助开发)
“请用TensorFlow Keras构建一个用于CIFAR-10图像分类的CNN模型,包含3个卷积层和2个最大池化层,最后接全连接层。要求输出训练和验证的准确率与损失曲线。”
6. 图表说明
上图展示了典型的训练过程可视化结果:
左图:训练准确率稳步上升,验证准确率在约70%左右趋于稳定,表明模型具备良好泛化能力。右图:训练损失持续下降,验证损失在后期略有波动,提示可能轻微过拟合。
案例二:基于Transformer的文本生成(GPT风格)
1. 背景介绍
Transformer 架构自2017年提出以来,彻底改变了自然语言处理领域。其核心是自注意力机制,能够并行处理序列信息,避免了RNN的时序依赖问题。本案例使用简化版Transformer实现文本续写。
2. 技术原理
Transformer由编码器-解码器组成,但纯生成任务(如GPT)仅使用解码器。每个解码器层包含多头自注意力和前馈网络,并引入位置编码保留序列顺序信息。
3. 代码实现(PyTorch)
python
编辑
import torch
import torch.nn as nn
import math
class PositionalEncoding(nn.Module):
def __init__(self, d_model, max_len=5000):
super().__init__()
pe = torch.zeros(max_len, d_model)
position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1)
div_term = torch.exp(torch.arange(0, d_model, 2).float() * (-math.log(10000.0) / d_model))
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
self.register_buffer('pe', pe)
def forward(self, x):
x = x + self.pe[:x.size(1), :]
return x
class TransformerDecoderOnly(nn.Module):
def __init__(self, vocab_size, d_model=512, nhead=8, num_layers=6):
super().__init__()
self.embedding = nn.Embedding(vocab_size, d_model)
self.pos_encoder = PositionalEncoding(d_model)
decoder_layer = nn.TransformerDecoderLayer(d_model, nhead, dim_feedforward=2048)
self.transformer_decoder = nn.TransformerDecoder(decoder_layer, num_layers)
self.fc_out = nn.Linear(d_model, vocab_size)
def forward(self, src, tgt):
# 简化:假设src=tgt(自回归)
src_emb = self.embedding(src) * math.sqrt(self.embedding.embedding_dim)
src_emb = self.pos_encoder(src_emb)
output = self.transformer_decoder(src_emb, src_emb)
return self.fc_out(output)
# 示例使用(需配合分词器和训练循环)
# model = TransformerDecoderOnly(vocab_size=10000)
# output = model(input_ids, input_ids)注:完整训练需大量文本数据和GPU资源,此处仅展示模型结构。
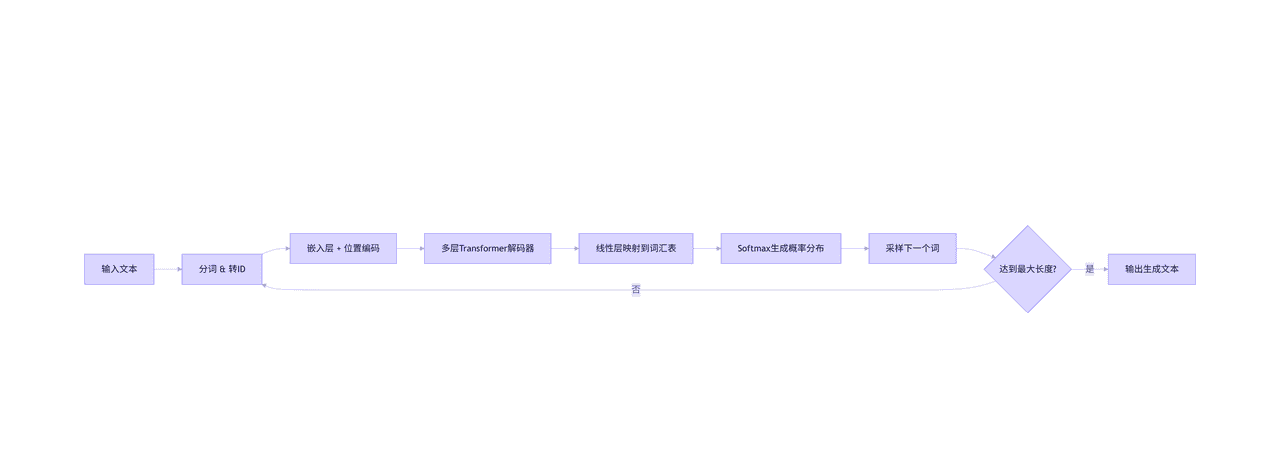
4. Mermaid 流程图
flowchart LR
A[输入文本] –> B[分词 & 转ID]
B –> C[嵌入层 + 位置编码]
C –> D[多层Transformer解码器]
D –> E[线性层映射到词汇表]
E –> F[Softmax生成概率分布]
F –> G[采样下一个词]
G –> H{达到最大长度?}
H — 否 –> B
H — 是 –> I[输出生成文本]
5. Prompt 示例
“请用PyTorch实现一个仅含解码器的Transformer模型,用于文本生成。要求包含位置编码、多头注意力和前馈网络,并说明如何进行自回归生成。”
6. 图表说明
Transformer 的注意力权重可通过热力图可视化。例如,在生成“猫坐在垫子上”时,模型在预测“垫子”时会高度关注“坐”和“上”,体现语义关联。
案例三:基于LSTM的时间序列预测(股票价格)
1. 背景介绍
时间序列预测广泛应用于金融、气象、能源等领域。LSTM(长短期记忆网络)作为RNN的改进版本,能有效捕捉长期依赖关系,适合处理股价等非平稳序列。
2. 技术原理
LSTM通过门控机制(输入门、遗忘门、输出门)控制信息流动,缓解梯度消失问题。对于单变量预测,可将历史窗口作为输入,预测下一时刻值。
3. 代码实现(Python + Keras)
python
编辑
import numpy as np
import pandas as pd
from sklearn.preprocessing import MinMaxScaler
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import LSTM, Dense
import yfinance as yf
# 获取苹果公司股价数据
data = yf.download('AAPL', start='2020-01-01', end='2023-01-01')
prices = data['Close'].values.reshape(-1, 1)
# 数据归一化
scaler = MinMaxScaler(feature_range=(0, 1))
scaled_prices = scaler.fit_transform(prices)
# 构造时间窗口(过去60天预测第61天)
def create_dataset(data, window_size=60):
X, y = [], []
for i in range(window_size, len(data)):
X.append(data[i-window_size:i, 0])
y.append(data[i, 0])
return np.array(X), np.array(y)
X, y = create_dataset(scaled_prices)
X = X.reshape((X.shape[0], X.shape[1], 1))
# 划分训练/测试集
split = int(0.8 * len(X))
X_train, X_test = X[:split], X[split:]
y_train, y_test = y[:split], y[split:]
# 构建LSTM模型
model = Sequential([
LSTM(50, return_sequences=True, input_shape=(X_train.shape[1], 1)),
LSTM(50),
Dense(1)
])
model.compile(optimizer='adam', loss='mean_squared_error')
model.fit(X_train, y_train, epochs=20, batch_size=32, validation_data=(X_test, y_test))
# 预测并反归一化
predicted = model.predict(X_test)
predicted_prices = scaler.inverse_transform(predicted)
actual_prices = scaler.inverse_transform(y_test.reshape(-1, 1))
# 可视化结果
plt.figure(figsize=(14, 6))
plt.plot(actual_prices, label='Actual Price', color='blue')
plt.plot(predicted_prices, label='Predicted Price', color='red', alpha=0.7)
plt.title('Apple Stock Price Prediction (LSTM)')
plt.xlabel('Days')
plt.ylabel('Price (USD)')
plt.legend()
plt.show()4. Mermaid 流程图
5. Prompt 示例
“请用Keras构建一个LSTM模型,使用过去60天的苹果公司收盘价预测第61天的价格。要求包括数据获取、预处理、模型训练和结果可视化。”
6. 图表说明
预测曲线通常能捕捉股价的整体趋势,但在剧烈波动时存在滞后。MSE(均方误差)和MAE(平均绝对误差)是常用评估指标。实际应用中需结合技术指标和外部因素提升精度。
综合对比与总结
| 案例 | 模型类型 | 输入数据 | 输出 | 典型应用场景 |
|---|---|---|---|---|
| 图像分类 | CNN | 图像(32×32×3) | 类别概率 | 医疗影像、自动驾驶 |
| 文本生成 | Transformer | 词ID序列 | 下一个词概率 | 聊天机器人、内容创作 |
| 时间序列预测 | LSTM | 数值序列 | 连续值 | 股票预测、电力负荷 |
关键洞察:
数据驱动:所有深度学习模型高度依赖高质量数据。CIFAR-10的标注图像、大规模文本语料、干净的时间序列是成功前提。架构选择:CNN擅长空间特征,RNN/LSTM处理时序,Transformer统一序列建模——选择取决于数据结构。工程实践:归一化、早停、学习率调度等技巧对性能至关重要。伦理考量:AI生成内容需标注,金融预测不可作为投资建议。
附录:环境配置建议
Python 3.8+库依赖:
bash
编辑
pip install tensorflow torch matplotlib scikit-learn yfinance pandas numpy硬件:GPU(如NVIDIA RTX 3090)可显著加速训练;CPU亦可运行小规模实验。
结语
人工智能与深度学习已深度融入现代技术栈。通过理解上述案例的原理与实现,开发者可举一反三,应用于更广泛的场景——从医疗诊断到智能客服,从工业预测性维护到创意内容生成。未来,随着多模态模型(如CLIP、Flamingo)的发展,跨模态理解将成为新前沿。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...