
做过RAG应用开发的技术同学,大多听过这样一句话:“RAG demo5分钟,上线上一年”。的确 ,用Langchain或LlamaIndex搭一个简单的检索增强生成流程并不复杂,但要让系统在实际业务中稳定输出高质量答案,却需要攻克分块优化、检索策略、上下文增强等一系列技术难点。许多时候,简单的RAG流程之所以效果拉胯,核心在于忽略了文本处理、检索优化、反馈闭环等关键环节的进阶设计。本文将结合实际开发经验,从技术原理、实践代码到落地场景,全面拆解RAG系统的进阶优化方案,帮你避开从demo到生产的那些“坑”。
文本分块:RAG的基础,决定检索的上限
文本分块看似是简单的“切割文本”,实则直接影响后续向量化和检索的准确性。分块的核心目标是在减少噪声的同时,最大程度保留语义相关性——如果块太小,会丢失上下文关联;如果块太大,又会引入冗余信息,稀释关键内容的权重。一个简单的判断标准是:如果一个文本块在脱离上下文的情况下,人类能读懂其含义,那么它对大模型也同样有意义。
在实际开发中,分块大小的选择需要综合思考三个因素:内容性质、向量模型能力和用户查询特点。列如处理短消息类内容时,句子级分块更合适;而处理长文档时,可能需要段落级分块。同时,向量模型的token长度限制也很关键,列如某些嵌入模型在512token左右表现最佳,分块时就需要以此为参考。用户查询的长度也会影响分块策略,短查询更适合匹配句子级向量,长查询则可能需要段落级向量的支持。
常见的分块方法各有优劣,需要根据业务场景灵活选择。固定大小分块是最常用的方式,通过设置固定的token数和块重叠部分,平衡语义完整性和检索精度。在Langchain中,我们可以用CharacterTextSplitter实现这一功能,列如设置chunk_size为256,chunk_overlap为20,这样既能避免块之间的语义断裂,又能保证每个块的独立性。代码示例如下:
text = "你的文本内容"
from langchain.text_splitter import CharacterTextSplitter
text_splitter = CharacterTextSplitter(
separator = "
",
chunk_size = 256,
chunk_overlap = 20
)
docs = text_splitter.create_documents([text])
“内容感知”分块则更贴合文本的自然结构,列如按标点符号、换行符分割,或使用NLTK、spaCy等NLP库进行句子分割。其中spaCy的句子分割功能最为精准,能处理缩写、省略号等复杂情况,适合对分块精度要求较高的场景。递归分块则是一种分层迭代的分割方式,通过多组分隔符逐步缩小块大小,直到达到预期效果,这种方法能在保证块大小相近的同时,尽可能遵循文本的自然边界。
对于Markdown、LaTeX这类结构化文本,专用分块工具能发挥更大作用。列如Langchain的MarkdownTextSplitter可以根据标题、列表等语法结构进行分块,确保技术文档或论文的逻辑完整性。而语义分块则是更高级的方案,它通过嵌入模型捕捉句子间的语义关联,将主题相关的句子划分为一个块。实现时,先将文档分解为句子,为每个句子创建包含前后语境的句子组,生成嵌入后计算组间语义距离,当距离超过阈值时则划分新块。Langchain的SemanticChunker已经集成了这一功能,虽然目前还是实验性模块,但在主题性强的文档处理中效果显著。
确定最佳块大小是一个迭代过程,第一需要预处理语料,去除无效标签和冗余信息,然后选择128、256、512等不同token数的块大小进行测试,通过检索效果评估找到平衡点。列如在处理产品文档时,我们测试发现256token的块大小在召回率和准确率上表现最优,既能捕捉产品特性的细节,又不会因块过大导致检索噪声。
向量化与索引:让检索更高效精准
向量化是RAG系统的核心环节,它将文本转化为数值向量,使计算机能够计算语义类似度。选择嵌入模型时,不能盲目追求排行榜名次,而要结合业务场景和分块长度。列如处理短文本块时,BGE-small这类轻量模型就能满足需求;而处理长文本或专业领域文档时,可能需要BGE-large或E5-large等更复杂的模型。此外,是否需要本地化部署、推理速度要求等也是选择模型的重大因素。
在Langchain中,我们可以轻松集成Hugging Face的嵌入模型,并结合Chroma、FAISS等向量数据库实现向量存储和检索。以下是一个典型的实现代码:
from langchain_community.vectorstores import Chroma, FAISS
from langchain_huggingface import HuggingFaceEmbeddings
# 初始化嵌入模型
embedding_instance = HuggingFaceEmbeddings(
model_name="your-model-path",
model_kwargs={"device": "cuda"}, # 支持GPU加速
encode_kwargs={"normalize_embeddings": True} # 归一化向量,提升检索效果
)
vector_path = "./vector_store"
# 存入Chroma向量库
Chroma.from_documents(
documents=texts,
embedding=embedding_instance,
persist_directory=vector_path
)
# 存入FAISS向量库(适合单机部署)
vs = FAISS.from_documents(
documents=texts,
embedding=embedding_instance
)
vs.save_local(vector_path)
向量索引的设计直接影响检索效率。对于小规模语料(万级以下),平面索引的暴力搜索就能满足需求,但当语料规模达到10万级以上时,就需要使用近似最近邻(ANN)算法,列如FAISS的HNSW算法、Annoy的树结构等,这些算法能在牺牲少量精度的情况下,大幅提升检索速度。如果需要分布式部署或更丰富的检索功能,Elasticsearch、OpenSearch等托管方案也是不错的选择,它们支持向量检索与关键词检索结合,还能通过元数据过滤实现更精准的检索。
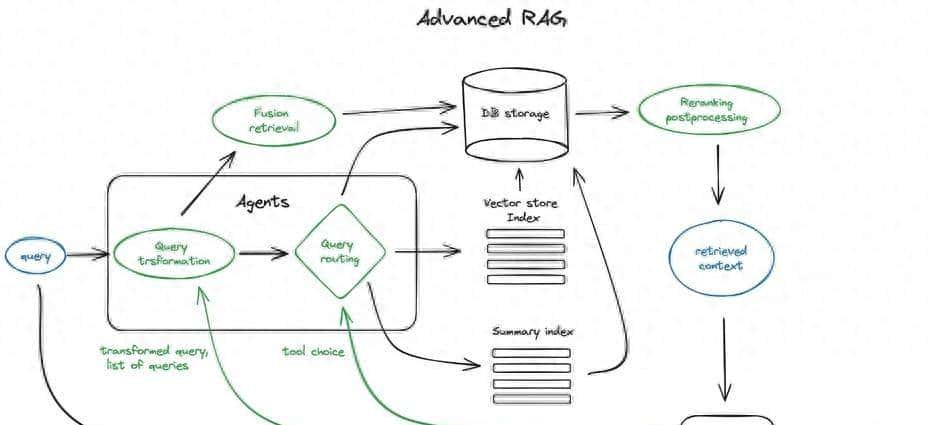
多层索引是处理大规模知识库的有效方案。当知识库包含大量文档时,直接检索所有文本块效率很低,这时可以构建两层索引:一层是文档摘要索引,另一层是文本块索引。检索时,先通过摘要索引筛选出与查询相关的文档,再在这些文档的文本块中进行细粒度检索,这样能大幅缩小检索范围,提升效率。列如在处理一本书的知识库时,我们可以先为每个章节生成摘要,建立摘要索引,用户查询时先找到相关章节,再在章节内检索具体内容。
假设问题与HyDE(假设向量文档)则是提升检索精度的进阶技巧。假设问题方法让LLM为每个文本块生成相关问题,将这些问题向量化后建立索引,检索时用用户查询匹配这些假设问题,再映射到原始文本块。这种方法能提升查询与文本块的语义匹配度,尤其适合问答类场景。而HyDE则是让LLM先根据用户查询生成一个假设性答案,将这个答案的向量与查询向量结合进行检索,利用假设答案中的语义信息补充查询,提升检索相关性。
上下文增强技术则是在检索到相关文本块后,通过扩展上下文提升大模型的推理能力。句子窗口检索将每个句子单独嵌入,检索到相关句子后,扩展其前后k个句子作为上下文,既保证了检索精度,又提供了足够的语境。父文档检索器则是将文档递归分割为父块和子块,检索子块后,将其对应的父块作为上下文补充,适合层级结构明显的文档。这两种方法都能在不降低检索精度的前提下,为大模型提供更完整的推理依据。
混合检索与重排序:融合多种检索优势
单一的检索方式往往存在局限,向量检索擅长捕捉语义关联,但对关键词匹配不够敏感;关键词检索(如BM25)能精准匹配字面信息,但缺乏语义理解能力。混合检索通过融合这两种方式的优势,能显著提升检索效果。
BM25是最常用的关键词检索算法,它基于概率模型,通过词项频率(TF)和逆文档频率(IDF)计算文档与查询的类似度。BM25的核心优势是能平衡文档长度的影响,避免长文档因包含更多词项而获得过高评分。在Langchain中,我们可以通过BM25Retriever实现这一功能,还能自定义分词策略,列如使用jieba分词处理中文文本:
from typing import List
from langchain.schema import Document
from langchain_community.retrievers import BM25Retriever
import jieba
# 自定义jieba分词函数
def jieba_tokenizer(text: str) -> List[str]:
jieba.load_userdict("your-user-dict.txt") # 加载自定义词典
return jieba.lcut(text, cut_all=False)
# 初始化BM25检索器
texts: List[Document] = [你的文本块列表]
bm25_retriever = BM25Retriever(
docs=texts,
k=5, # 返回前5个相关结果
preprocess_func=jieba_tokenizer
)
Elasticsearch作为成熟的搜索引擎,默认使用BM25算法,同时支持向量检索,适合大规模分布式部署。在Langchain中集成Elasticsearch时,需要先部署Elasticsearch集群,然后通过ElasticsearchStore实现文本块的存储和检索,代码如下:
from elasticsearch import Elasticsearch
from langchain_community.vectorstores import ElasticsearchStore
from langchain_openai import OpenAIEmbeddings
# 连接Elasticsearch集群
conn = Elasticsearch(
"https://127.0.0.1:9200",
basic_auth=("elastic", "changeme"),
verify_certs=False
)
# 初始化Elasticsearch向量存储
embeddings = OpenAIEmbeddings()
db = ElasticsearchStore.from_documents(
docs=texts,
embeddings=embeddings,
index_name="rag_index",
es_connection=conn
)
# 执行检索
query = "你的查询"
results = db.similarity_search(query)
混合检索的关键是如何融合不同检索方式的结果,互惠排名融合(RRF)是常用的融合算法,它通过计算文档在不同检索结果中的排名,生成最终的排序结果。在Langchain中,EnsembleRetriever可以实现这一功能,通过设置不同检索器的权重,融合向量检索和BM25的结果:
from langchain.retrievers import EnsembleRetriever
from langchain_community.vectorstores import FAISS
# 初始化向量检索器(FAISS)
faiss_vectorstore = FAISS.from_texts(texts, embeddings)
faiss_retriever = faiss_vectorstore.as_retriever(search_kwargs={"k": 2})
# 初始化BM25检索器
bm25_retriever = BM25Retriever.from_texts(texts, preprocess_func=jieba_tokenizer)
bm25_retriever.k = 2
# 融合检索器
ensemble_retriever = EnsembleRetriever(
retrievers=[bm25_retriever, faiss_retriever],
weights=[0.5, 0.5] # 权重可根据实际效果调整
)
但在实际项目中,简单的权重融合并不总是理想。我在开发产品库检索系统时发现,不同检索器的结果质量存在差异,直接融合可能导致关键信息丢失。因此,我们采用了“先重排序再融合”的策略:先用reranker模型对每个检索器的结果单独排序,再将排序后的结果合并去重,最后取top-N结果。这种方式能减少低质量结果对最终效果的影响,提升检索的稳定性。
结果合并时的排序策略也很重大,常用的有两种:交替排序和头尾排序。交替排序将不同检索器的结果交替排列,每次加入结果前先去重,适合结果质量相近的情况;头尾排序则将一个检索器的结果放在前面,另一个放在后面(尾部结果倒序),利用大模型对文本前后信息更敏感的特点,提升关键信息的利用率。在检索结果较多时,头尾排序的效果往往更优。
查询转换与反馈循环:让检索更懂用户需求
查询转换是通过LLM优化用户查询,使其更适合检索的技术,核心是让检索系统更好地理解用户的真实意图。常见的查询转换方式有三种:问题改写、子查询分解和回退提示。
问题改写是将用户的自然语言查询转化为更精准的检索式,列如用户问“办理某产品需要多少钱”,可以改写为“某产品的资费”,突出关键词,提升检索效率。子查询分解则用于处理复杂查询,列如用户问“Langchain和LlamaIndex哪个更优秀”,可以分解为“Langchain的Github星数”“LlamaIndex的Github星数”“Langchain的核心功能”“LlamaIndex的核心功能”等子查询,分别检索后再合并结果,让大模型能够综合判断。在Langchain中,MultiQueryRetriever可以自动生成多个子查询,代码如下:
from langchain.retrievers.multi_query import MultiQueryRetriever
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(temperature=0)
# 初始化多查询检索器
multi_query_retriever = MultiQueryRetriever.from_llm(
retriever=vectordb.as_retriever(),
llm=llm
)
# 执行检索
query = "What are the approaches to Task Decomposition?"
results = multi_query_retriever.get_relevant_documents(query)
回退提示则是让LLM生成一个更通用的查询,与原始查询一起检索,获取更广泛的上下文。列如用户问“某产品的高级功能如何使用”,可以生成回退查询“某产品的功能介绍”,通过通用查询获取产品的整体信息,辅助大模型理解高级功能的使用场景。
生成反馈循环是提升RAG系统长期效果的关键,它将用户查询和系统生成的答案存储到向量库中,形成动态更新的知识库。常规RAG系统中,LLM和向量库是单向交互,而反馈循环让两者形成闭环:用户提问后,先检索历史QA库,若存在类似问题则直接返回答案;若不存在则检索原始知识库,生成答案后将QA对存入向量库,供后续查询使用。
这种机制有几个显著优势:一是能实现个性化回答,随着用户交互增多,系统会积累更多场景化知识;二是能降低响应延迟,历史QA库相当于缓存,类似问题无需重复检索;三是能持续优化效果,通过人工或LLM评估筛选高质量QA对,减少错误和偏见。在实际部署中,我们可以将历史QA库与原始知识库分开存储,优先检索QA库,提升检索效率。
多轮对话与响应合成:打造流畅的交互体验
单体RAG系统只能处理单次问答,无法支持多轮对话,而实际应用中用户往往会进行追问或上下文关联查询。列如用户先问“某产品的优势是什么”,再问“这些优势适用于哪些场景”,第二次查询依赖第一次的回答内容,需要系统理解对话上下文。
解决这一问题的核心是查询压缩技术,即将历史对话和当前查询压缩为一个新的查询,再进行检索。Langchain的ContextChatEngine和CondensePlusContextMode是两种常用的实现方式。ContextChatEngine将历史对话和检索到的上下文一起传递给LLM,适合对话历史较短的场景;CondensePlusContextMode则通过LLM将历史对话和当前查询压缩为一个语义完整的查询,再进行检索,适合长对话场景。
在实际生产中,ContextChatEngine的效果往往不够理想,由于用户的口语化追问可能缺少关键信息,直接检索难以获得相关结果。因此,我们需要优化查询压缩的提示词,让LLM更精准地捕捉上下文关联。列如提示词可以设计为:“结合以下对话历史和当前查询,生成一个包含所有关键信息的检索查询,确保不丢失上下文:对话历史:xxx,当前查询:xxx”。
响应合成是RAG系统的最后一步,需要基于检索到的上下文生成准确、流畅的答案。最简单的方式是将所有相关上下文拼接后传递给LLM,但这种方式可能导致prompt过长,影响生成效果。更优的方案包括迭代优化、摘要压缩和多答案融合:迭代优化将上下文逐块传递给LLM,逐步细化答案;摘要压缩先对上下文进行摘要,保留核心信息;多答案融合则基于不同上下文块生成多个答案,再合并为最终结果。
在处理多来源引用时,需要让大模型明确标注答案的引用来源,增强可信度。实现方式有两种:一是在prompt中要求LLM标注引用源编号,二是通过模糊匹配将生成的答案与原始文本块关联。列如在prompt中加入:“请基于提供的上下文生成答案,并在答案中注明引用的上下文编号(如[来源1])”。
微调与评估:持续优化系统性能
模型微调是进一步提升RAG效果的手段,主要包括嵌入模型微调与reranker模型微调。嵌入模型微调通过领域内数据训练,让模型更好地捕捉专业术语的语义关联,列如在医疗领域,微调后的嵌入模型能更精准地理解疾病名称、药物名称的关联。根据实测,BGE-large-en-v1.5经过领域数据微调后,RAG系统的检索效果能提升2%左右。
reranker模型微调则是提升结果排序准确性的关键,它通过交叉编码器对检索到的文本块进行重新评分,输出相关度分数。微调时,将查询与文本块配对,标注相关(1)或不相关(0),训练模型学习领域内的相关性判断标准。实测显示,reranker模型微调后,文本块的配对得分能提升4%,显著改善检索结果的排序质量。
评估是RAG系统迭代优化的基础,主要分为人工评估和自动化评估。人工评估需要构建包含查询、相关文档ID的数据集,计算召回率、准确率、F1分数和命中率等指标。召回率衡量系统能否检索到所有相关文档,准确率衡量检索结果的准确性,命中率则衡量至少检索到一个相关文档的比例。在实际开发中,召回率和命中率是最重大的指标,由于大模型能过滤部分噪声,但无法利用未检索到的相关信息。
自动化评估则可以通过RAGAs框架实现,它无需人工标注真实答案,而是利用LLM评估检索和生成的效果。RAGAs的核心指标包括上下文精度(检索到的上下文是否相关)、上下文召回(是否检索到所有必要信息)、忠实度(答案是否基于上下文)和答案相关性(答案是否符合查询需求)。这些指标能全面评估RAG系统的性能,协助开发者定位瓶颈。
总结:RAG进阶之路的核心逻辑
从demo到生产,RAG系统的优化是一个层层递进的过程,核心逻辑是围绕“精准检索”和“有效生成”两个核心,通过分块优化、混合检索、上下文增强、反馈循环等技术,持续提升系统的准确性、效率和用户体验。
在实际开发中,没有放之四海而皆准的方案,需要根据业务场景灵活选择技术组合:处理结构化文档时,优先使用专用分块工具;大规模知识库优先采用多层索引和混合检索;多轮对话场景重点优化查询压缩和上下文管理。同时,评估是持续优化的关键,通过人工评估和自动化评估结合,不断调整分块策略、检索参数和模型参数,才能让RAG系统真正落地生效。
© 版权声明
文章版权归作者所有,未经允许请勿转载。














收藏了,感谢分享