
把本地大模型和检索框架混在一起,能把回答变得更好查源、更能说清来龙去脉。LightRAG就是这么一套东西:把语义向量检索和知识图谱检索并行起来,最后把两边拿到的证据交给模型去组织答案。跟单纯靠向量匹配比起来,能把“为什么这么说”这类东西一起交代清楚,不再只是一句没有出处的结论。
想跑起来,步骤实则不复杂。我这边是把LightRAG放本机,用Ollama跑一个轻量的本地模型,演示里用了IBM的Granite系列作为例子。先去 ollama.com 下客户端,把模型拉下来并启动,默认服务会监听在本机的11434端口,LightRAG通过这个端口去调用模型接口。关键配置都放在一个.env文件里,仓库里有env.example,拷一份改成.env,把模型地址、端口、存储方式等都写明就行。
配置好之后,代码里要先把LLM和嵌入函数的调用逻辑定好。Ollama的调用要稍微适配一下,把模型名和地址用partial固定住,之后把这个调用函数注入到LightRAG初始化里。初始化顺序要对,先把存储和管道状态准备好,函数名像initialize_storages、
initialize_pipeline_status这些是必须走的,缺了这步后面读写会报错或者状态不对。
把文档塞进系统时,LightRAG不是简单把文本丢进向量库。插入接口(示例里是ainsert)会做几件事:把长文本切片、生成向量、抽取实体并尝试建立实体间的关系,然后把这些关系写进图数据库,同时把向量写入向量库。也就是说,插入后数据既有语义向量,也有实体关系网络,这就是混合检索的基础。插入完最好抽样检查一下,看看实体抽取和向量表明有没有明显问题,别到用的时候发现图谱里全是噪声。
发起查询的接口(示例里是aquery)支持几种检索模式:纯向量、纯图谱、混合。混合模式会并行跑向量检索和图检索,再把两边结果合并交给LLM做最后生成。返回结果一般带上来源片段,代码里可以通过retriever_output.docs把这些引用片段拿出来。这样就解决了“模型胡说八道”的一部分问题:答案里能附带来源,用户能追溯到原始段落看原话。
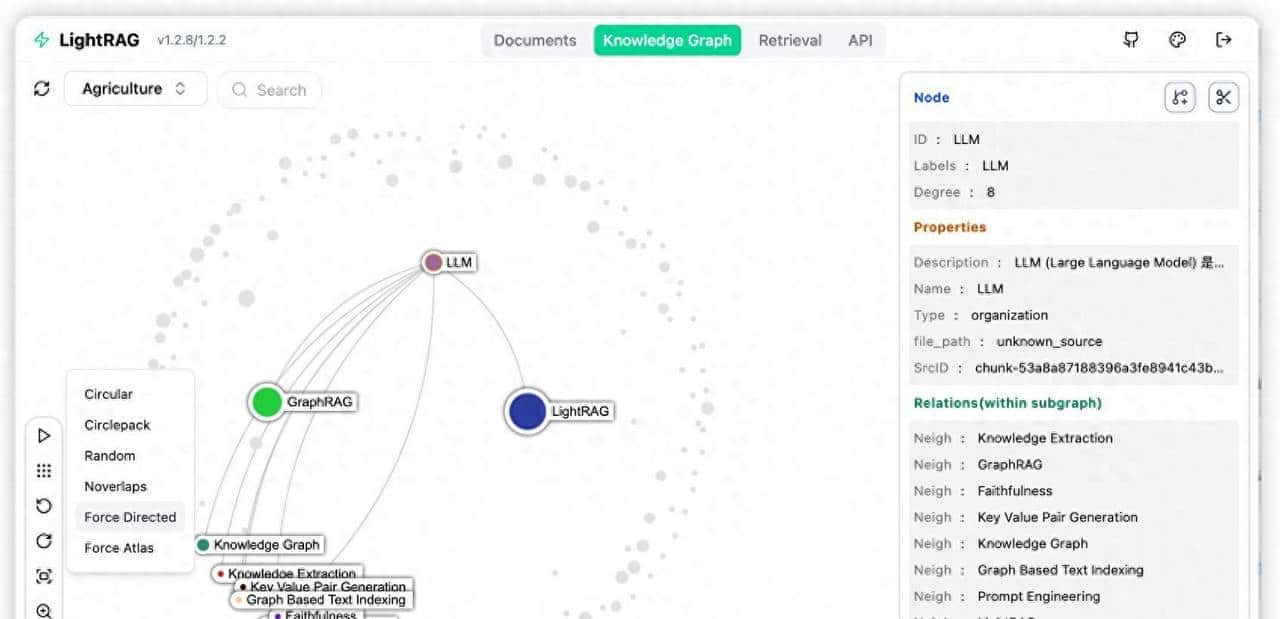
为了更直观地看清图谱和实体关系,可以用Streamlit搭个小界面,把NetworkX的图渲染出来。可视化界面会显示节点、边和权重,让你不仅知道哪段文被引用,还能看到为什么被关联——由于实体之间有一条关系链。举例来说,量子安全加密这个例子里,你能看到“量子计算—Shor算法—传统加密脆弱性”这样的路径,又看到“格密码—抗量子攻击”的另一条路径,两条链路一块儿作用,生成的答案在逻辑和证据上都会更完整。
我做过一次具体测试,拿三篇关于量子安全加密的文档来试,分别覆盖技术原理、应用场景和与传统加密的对比。插入后问系统“量子安全加密为什么能抵抗量子计算攻击?”,它不仅给出解释,还把文中关于格密码抗量子攻击原理的段落和与Shor算法有关的背景一起拉出来。这样一来,回答里既解释了Shor算法如何威胁传统加密,又列出了格密码的基本防护思路,而且引用片段是可追溯的,能看到原文段落。这种方式比单纯向量检索的结果,更能把因果和证据链连起来。
技术上有几个实务细节要注意。LightRAG默认用NetworkX做图数据库,适合小规模测试;上生产环境提议接Neo4j之类的图数据库以便扩展。文本切分策略也得调好,切太细会让索引膨胀,切太粗会影响检索精度。实体和关系抽取的准确率直接决定图谱质量,抽取器误判了,图谱就脏了,检索结果也会被拖累。Ollama方便,但不同模型API有差异,调用时要准备好异常处理和超时控制。
工程实践上,注入LLM和嵌入函数时把模型名、地址等参数固定成可复用的模块会省事。初始化步骤按顺序走,存储、管道状态、索引都得先准备好。数据插入可以批量化,但提议插入后做抽样检查;查询接口最好支持多种模式切换,便于在不同场景下测试和调优。图谱存储和向量库的规模会影响性能,测试环境和生产环境在存储选型上要区别对待。
组件替换这块,LightRAG的模块化比较友善。想换模型就把Ollama替换成别的本地推理引擎,或者把嵌入模型换成自己训练的向量器;图数据库能换,small测试用NetworkX够用,企业级就接Neo4j之流。只要把接口适配好,管道其他部分基本不用大动,这对工程化落地很重大,能按需求替换组件而不必重写整套系统。
落地场景挺多:公司内部知识库问答需要源头可查,客服系统要追溯文档定位责任,法律和医疗等对溯源要求高的领域混合检索能把结构化证据链和文本证据一并提供。把模型放在本地还有个实际好处:敏感数据不用上云,合规压力小一些。
最后说两件容易踩坑的事。第一,实体抽取和关系抽取的错误会直接把图谱变脏,得有监控和定期修正策略;第二,文本分割策略和索引设计得跟语料类型匹配,别盲目套默认值。把这些环节监控起来,定期做质量回检,长时间运行才不会越跑越糟。
© 版权声明
文章版权归作者所有,未经允许请勿转载。












收藏了,感谢分享