
目录
大模型本地部署基础概述本地部署环境搭建详解主流大模型本地部署实战教程大模型应用开发案例性能优化与扩展方案常见问题与解决方案
1. 大模型本地部署基础概述
1.1 什么是大模型本地部署
大模型本地部署指将预训练的大型语言模型 (LLM) 安装并运行在个人计算机、本地服务器或私有云环境中,而非依赖云端 API 服务。这种部署方式能提供数据隐私保护、低延迟响应和定制化扩展等优势。
1.2 本地部署的优势与挑战
| 优势 | 挑战 |
|---|---|
| 数据隐私与安全 | 硬件要求高 |
| 无网络依赖 | 技术门槛较高 |
| 低延迟响应 | 维护成本增加 |
| 完全定制化 | 模型更新复杂 |
| 无 API 调用限制 | 能耗较高 |
1.3 本地部署适用场景
企业内部知识库问答系统医疗、金融等敏感领域应用边缘计算设备集成数据安全要求高的场景离线工作环境需求
2. 本地部署环境搭建详解
2.1 硬件准备
大模型本地部署对硬件有较高要求,尤其是 GPU:
graph TD
A[硬件准备] --> B[CPU]
A --> C[GPU]
A --> D[内存]
A --> E[存储]
B --> B1[推荐: Intel i7/i9 或 AMD Ryzen 7/9]
B --> B2[最低: 4核8线程]
C --> C1[推荐: NVIDIA RTX 4090/3090, A100]
C --> C2[最低: NVIDIA GTX 1650 (4GB VRAM)]
C --> C3[需支持CUDA 11.7+]
D --> D1[推荐: 32GB+ DDR4/DDR5]
D --> D2[最低: 16GB]
E --> E1[推荐: 1TB SSD]
E --> E2[最低: 500GB SSD]2.2 软件环境配置
2.2.1 操作系统选择
推荐: Ubuntu 22.04 LTS / Windows 11兼容: macOS 12+ (M 系列芯片需特殊配置)
2.2.2 基础软件安装
Windows 系统安装步骤:
powershell
# 安装Chocolatey包管理器
Set-ExecutionPolicy Bypass -Scope Process -Force; [System.Net.ServicePointManager]::SecurityProtocol = [System.Net.ServicePointManager]::SecurityProtocol -bor 3072; iex ((New-Object System.Net.WebClient).DownloadString('https://community.chocolatey.org/install.ps1'))
# 安装必要工具
choco install python git cmake -y
# 验证安装
python --version
git --version
cmake --versionUbuntu 系统安装步骤:
bash
# 更新系统
sudo apt update && sudo apt upgrade -y
# 安装必要工具
sudo apt install python3 python3-pip git cmake build-essential -y
# 验证安装
python3 --version
git --version
cmake --version2.2.3 Python 环境配置
bash
# 创建虚拟环境
python -m venv llm_env
# 激活虚拟环境
# Windows
llm_envScriptsactivate
# Linux/macOS
source llm_env/bin/activate
# 升级pip
pip install --upgrade pip2.2.4 GPU 驱动与 CUDA 配置
bash
# 安装NVIDIA驱动 (Ubuntu)
sudo apt install nvidia-driver-535 -y
# 安装CUDA Toolkit
# 访问https://developer.nvidia.com/cuda-downloads获取对应版本
# 示例: CUDA 11.8
wget https://developer.download.nvidia.com/compute/cuda/11.8.0/local_installers/cuda_11.8.0_520.61.05_linux.run
sudo sh cuda_11.8.0_520.61.05_linux.run
# 配置环境变量
echo 'export PATH=/usr/local/cuda-11.8/bin:$PATH' >> ~/.bashrc
echo 'export LD_LIBRARY_PATH=/usr/local/cuda-11.8/lib64:$LD_LIBRARY_PATH' >> ~/.bashrc
source ~/.bashrc
# 验证CUDA安装
nvcc --version
nvidia-smi3. 主流大模型本地部署实战教程
3.1 LLaMA 2 本地部署
3.1.1 准备工作
从 Meta 官网申请 LLaMA 2 访问权限:https://ai.meta.com/resources/models-and-libraries/llama-downloads/获取下载链接后,使用 wget 下载模型
3.1.2 部署步骤
bash
# 安装必要依赖
pip install transformers accelerate sentencepiece torch
# 克隆部署仓库
git clone https://github.com/oobabooga/text-generation-webui.git
cd text-generation-webui
# 创建模型目录并下载模型
mkdir models/LLaMA-2-7B-Chat
cd models/LLaMA-2-7B-Chat
# 这里替换为你的下载链接
wget "https://download.llamameta.net/*your-download-link*"
tar -xvf llama-2-7b-chat.tar.gz
# 返回上级目录并启动WebUI
cd ../..
python server.py --model LLaMA-2-7B-Chat --load-in-4bit3.1.3 基本使用代码
python
运行
from transformers import AutoTokenizer, AutoModelForCausalLM
# 加载模型和分词器
model_name = "./models/LLaMA-2-7B-Chat"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
load_in_4bit=True,
device_map="auto"
)
# 生成文本函数
def generate_text(prompt, max_length=200, temperature=0.7):
inputs = tokenizer(prompt, return_tensors="pt").to("cuda")
outputs = model.generate(
**inputs,
max_length=max_length,
temperature=temperature,
do_sample=True,
pad_token_id=tokenizer.eos_token_id
)
return tokenizer.decode(outputs[0], skip_special_tokens=True)
# 使用示例
prompt = "请解释什么是人工智能?"
response = generate_text(prompt)
print(response)3.2 Mistral 本地部署
bash
# 安装依赖
pip install transformers accelerate torch sentencepiece
# 下载模型 (使用Hugging Face Hub)
pip install huggingface-hub
huggingface-cli login # 需要登录Hugging Face账号
# 创建部署脚本
cat > mistral_deploy.py << EOF
from transformers import AutoModelForCausalLM, AutoTokenizer
model_id = "mistralai/Mistral-7B-Instruct-v0.1"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(
model_id,
load_in_4bit=True,
device_map="auto"
)
def chat_with_mistral(prompt, max_tokens=100):
messages = [
{"role": "user", "content": prompt}
]
encodeds = tokenizer.apply_chat_template(messages, return_tensors="pt")
model_inputs = encodeds.to("cuda")
generated_ids = model.generate(
model_inputs,
max_new_tokens=max_tokens,
do_sample=True
)
decoded = tokenizer.batch_decode(generated_ids)
return decoded[0]
# 测试
if __name__ == "__main__":
user_input = "请推荐一本学习Python的入门书籍"
response = chat_with_mistral(user_input)
print(response)
EOF
# 运行部署脚本
python mistral_deploy.py3.3 量化模型部署(以 GPTQ 量化为例)
对于显存有限的设备,量化模型是一个很好的选择:
bash
# 安装GPTQ依赖
pip install auto-gptq
# 下载量化模型并部署
cat > gptq_deploy.py << EOF
from auto_gptq import AutoGPTQForCausalLM
from transformers import AutoTokenizer, pipeline
model_name_or_path = "TheBloke/Llama-2-7B-Chat-GPTQ"
model_basename = "gptq_model-4bit-128g"
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path)
model = AutoGPTQForCausalLM.from_quantized(
model_name_or_path,
model_basename=model_basename,
use_safetensors=True,
trust_remote_code=True,
device="cuda:0",
use_triton=False,
quantize_config=None
)
# 创建文本生成管道
generator = pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
max_new_tokens=1024,
temperature=0.7,
top_p=0.95,
repetition_penalty=1.15
)
# 使用示例
prompt = "写一篇关于环境保护的短文,大约300字"
response = generator(prompt)
print(response[0]['generated_text'])
EOF
# 运行
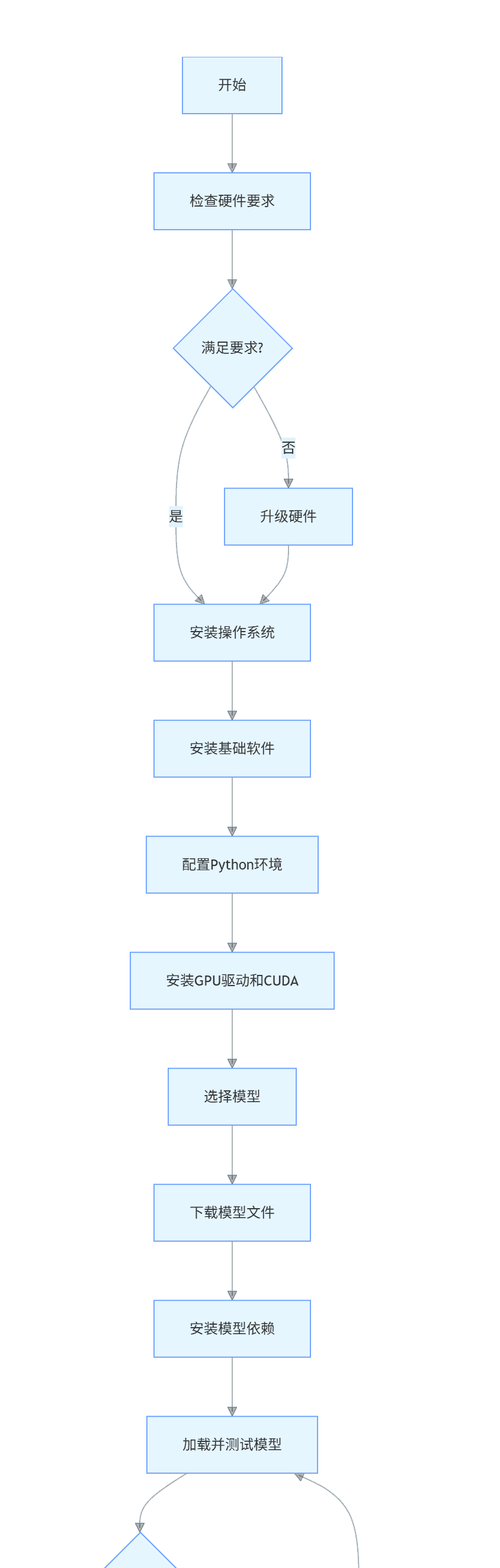
python gptq_deploy.py3.4 部署流程总览
graph TD
A[开始] --> B[检查硬件要求]
B --> C{满足要求?}
C -->|是| D[安装操作系统]
C -->|否| E[升级硬件]
E --> D
D --> F[安装基础软件]
F --> G[配置Python环境]
G --> H[安装GPU驱动和CUDA]
H --> I[选择模型]
I --> J[下载模型文件]
J --> K[安装模型依赖]
K --> L[加载并测试模型]
L --> M{测试成功?}
M -->|是| N[部署完成]
M -->|否| O[排查问题并重新配置]
O --> L4. 大模型应用开发案例
4.1 本地知识库问答系统
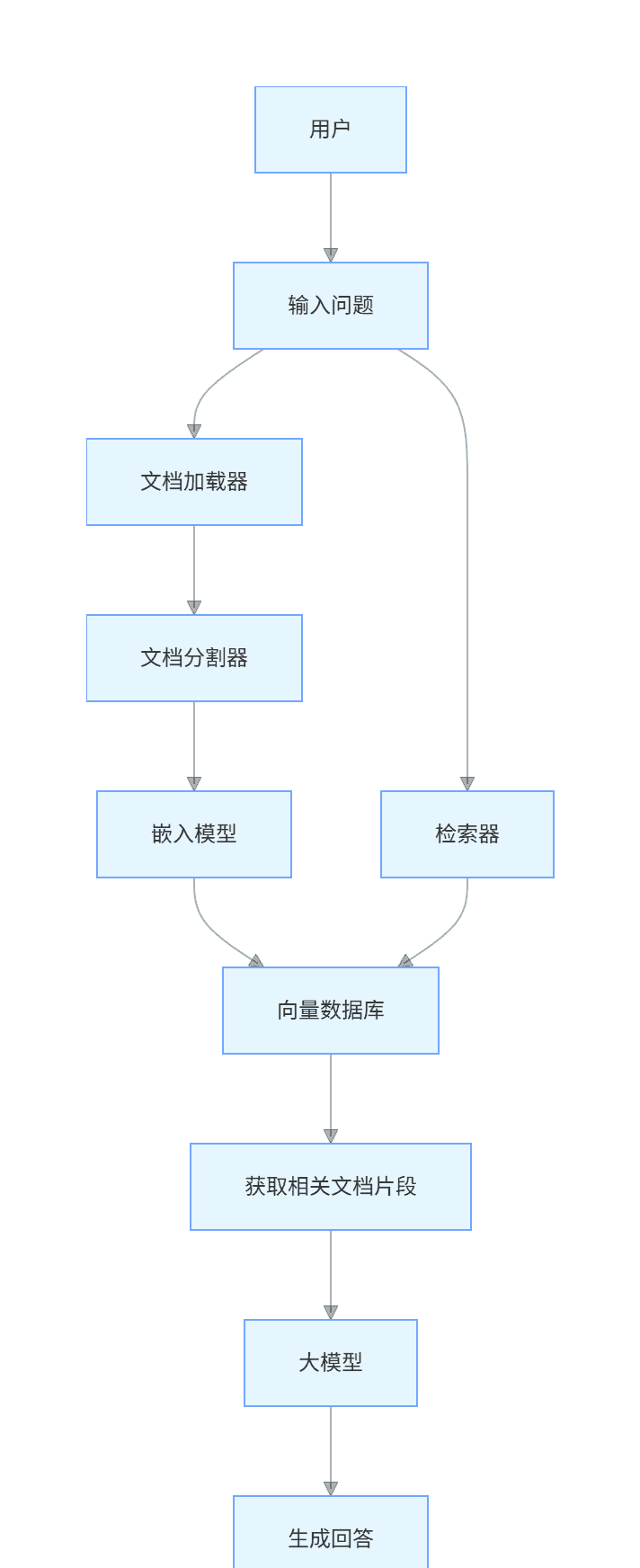
该系统能将本地文档导入大模型,实现基于特定文档的问答功能。
4.1.1 系统架构
graph TD
A[用户] --> B[输入问题]
B --> C[文档加载器]
C --> D[文档分割器]
D --> E[嵌入模型]
E --> F[向量数据库]
B --> G[检索器]
G --> F
F --> H[获取相关文档片段]
H --> I[大模型]
I --> J[生成回答]
J --> K[返回给用户]4.1.2 实现代码
python
运行
# 安装必要依赖
!pip install langchain transformers torch sentence-transformers faiss-gpu unstructured python-magic-bin
from langchain.document_loaders import DirectoryLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.embeddings import HuggingFaceEmbeddings
from langchain.vectorstores import FAISS
from langchain.llms import HuggingFacePipeline
from langchain.chains import RetrievalQA
from transformers import AutoModelForCausalLM, AutoTokenizer, pipeline
import torch
# 1. 加载文档
def load_documents(directory):
loader = DirectoryLoader(directory)
documents = loader.load()
return documents
# 2. 分割文档
def split_documents(documents, chunk_size=500, chunk_overlap=50):
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=chunk_size,
chunk_overlap=chunk_overlap
)
texts = text_splitter.split_documents(documents)
return texts
# 3. 创建向量数据库
def create_vector_db(texts):
embeddings = HuggingFaceEmbeddings(model_name="all-MiniLM-L6-v2")
db = FAISS.from_documents(texts, embeddings)
db.save_local("local_kb_db")
return db
# 4. 加载大模型
def load_llm(model_path):
tokenizer = AutoTokenizer.from_pretrained(model_path)
model = AutoModelForCausalLM.from_pretrained(
model_path,
load_in_4bit=True,
device_map="auto",
torch_dtype=torch.bfloat16
)
pipe = pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
max_new_tokens=512,
temperature=0.7,
top_p=0.95,
repetition_penalty=1.15
)
llm = HuggingFacePipeline(pipeline=pipe)
return llm
# 5. 创建问答链
def create_qa_chain(llm, db):
qa_chain = RetrievalQA.from_chain_type(
llm=llm,
chain_type="stuff",
retriever=db.as_retriever(search_kwargs={"k": 3}),
return_source_documents=True
)
return qa_chain
# 6. 问答函数
def answer_question(qa_chain, question):
result = qa_chain({"query": question})
return result["result"], result["source_documents"]
# 主函数
def main():
# 配置
document_directory = "./documents" # 存放文档的目录
model_path = "./models/LLaMA-2-7B-Chat" # 模型路径
# 初始化
print("加载文档...")
documents = load_documents(document_directory)
print(f"加载了 {len(documents)} 个文档")
print("分割文档...")
texts = split_documents(documents)
print(f"分割为 {len(texts)} 个片段")
print("创建向量数据库...")
db = create_vector_db(texts)
print("加载大模型...")
llm = load_llm(model_path)
print("创建问答链...")
qa_chain = create_qa_chain(llm, db)
print("知识库问答系统已就绪!")
# 交互循环
while True:
question = input("
请输入你的问题 (输入 'exit' 退出): ")
if question.lower() == 'exit':
break
print("思考中...")
answer, sources = answer_question(qa_chain, question)
print("
回答:")
print(answer)
print("
参考来源:")
for i, source in enumerate(sources, 1):
print(f"{i}. {source.metadata['source']}")
if __name__ == "__main__":
main()4.1.3 Prompt 设计示例
plaintext
使用以下提供的上下文信息来回答用户的问题。如果上下文信息中没有相关内容,直接说明"根据提供的资料,我无法回答这个问题",不要编造信息。
上下文:
{context}
问题: {question}
回答:4.2 代码助手应用
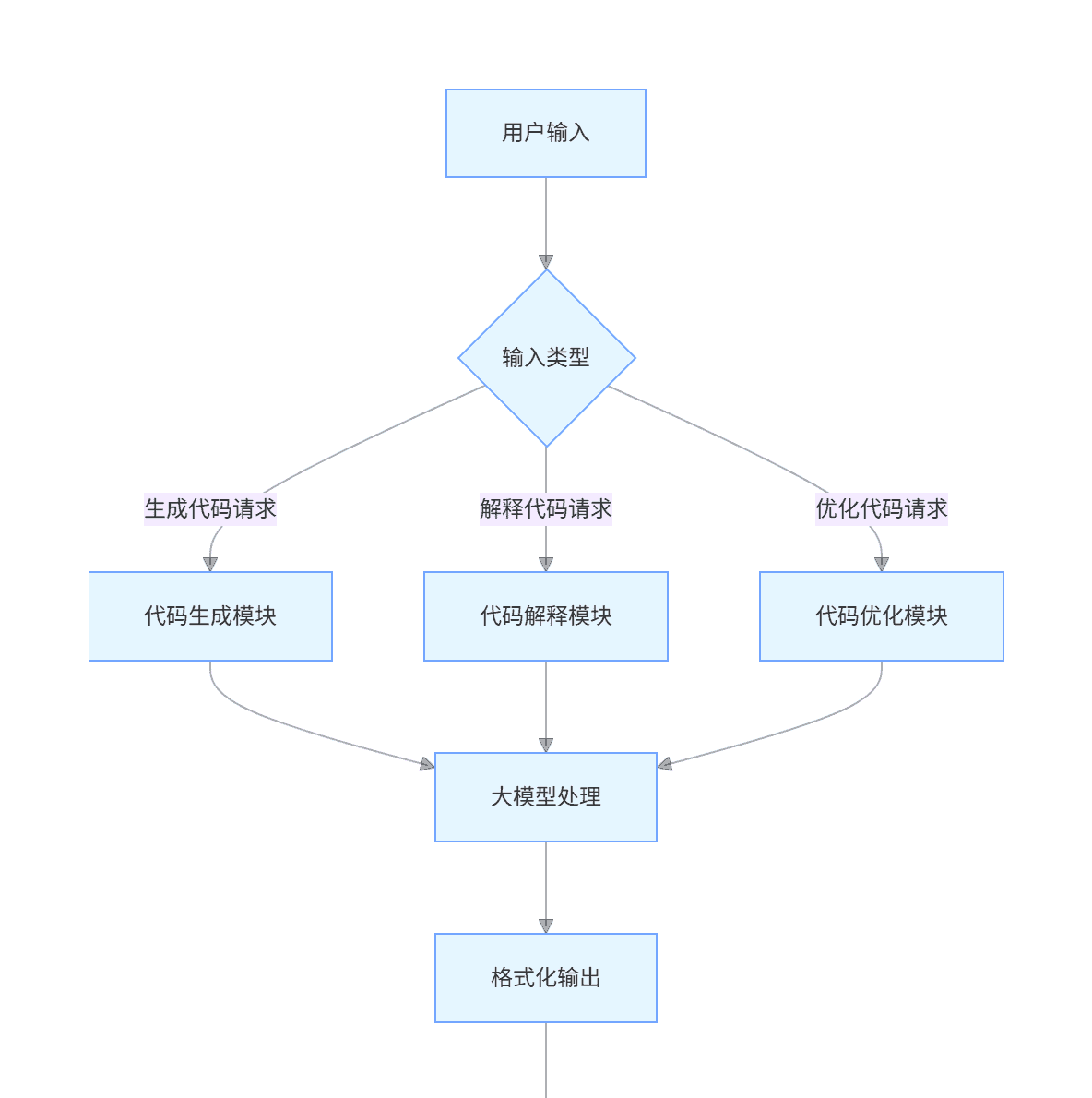
开发一个本地运行的代码助手,能帮助用户生成、解释和优化代码。
4.2.1 功能设计
graph TD
A[用户输入] --> B{输入类型}
B -->|生成代码请求| C[代码生成模块]
B -->|解释代码请求| D[代码解释模块]
B -->|优化代码请求| E[代码优化模块]
C --> F[大模型处理]
D --> F
E --> F
F --> G[格式化输出]
G --> H[返回结果给用户]4.2.2 实现代码
python
运行
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer, pipeline
class CodeAssistant:
def __init__(self, model_path):
"""初始化代码助手"""
self.tokenizer = AutoTokenizer.from_pretrained(model_path)
self.model = AutoModelForCausalLM.from_pretrained(
model_path,
load_in_4bit=True,
device_map="auto",
torch_dtype=torch.bfloat16
)
self.code_pipeline = pipeline(
"text-generation",
model=self.model,
tokenizer=self.tokenizer,
max_new_tokens=1024,
temperature=0.6,
top_p=0.95,
repetition_penalty=1.2
)
# 定义不同功能的提示词模板
self.generate_template = """
请生成一个{language}函数,实现以下功能: {description}
要求:
1. 代码必须可运行
2. 包含适当的注释
3. 考虑边界情况
4. 返回完整代码,不需要额外解释
"""
self.explain_template = """
请解释以下{language}代码的工作原理:
```{language}
{code}
要求:
分步骤解释说明关键算法或数据结构解释可能的优化点”””
self.optimize_template = “””请优化以下 {language} 代码:
{language}
{code}
问题描述: {issues}要求:
保留原功能提高性能或可读性解释优化点返回优化后的完整代码”””
def generate_code (self, language, description):”””生成代码”””prompt = self.generate_template.format (language=language,description=description).strip ()
result = self.code_pipeline(prompt)return result[0]['generated_text'][len(prompt):].strip()
def explain_code (self, language, code):”””解释代码”””prompt = self.explain_template.format (language=language,code=code).strip ()
result = self.code_pipeline(prompt)return result[0]['generated_text'][len(prompt):].strip()
def optimize_code (self, language, code, issues=””):”””优化代码”””prompt = self.optimize_template.format (language=language,code=code,issues=issues).strip ()
result = self.code_pipeline(prompt)return result[0]['generated_text'][len(prompt):].strip()
def main():
初始化代码助手,使用适合代码生成的模型
print (“正在加载代码助手模型…”)assistant = CodeAssistant (“./models/CodeLlama-7b-Instruct-hf”)print (“代码助手已就绪!”)
while True:print (”
请选择功能:”)print (“1. 生成代码”)print (“2. 解释代码”)print (“3. 优化代码”)print (“4. 退出”)
choice = input (“请输入选项 (1-4):”)
if choice == “1”:language = input (“请输入编程语言:”)description = input (“请描述要实现的功能:”)print (“正在生成代码…”)code = assistant.generate_code (language, description)print (”
生成的代码:”)print (f”
{language}") print(code) print("
elif choice == “2”:language = input (“请输入编程语言:”)print (“请输入要解释的代码 (输入空行结束):”)code_lines = []while True:line = input ()if not line:breakcode_lines.append (line)code = ”
“.join (code_lines)print (“正在解释代码…”)explanation = assistant.explain_code (language, code)print (”
代码解释:”)print (explanation)
elif choice == “3”:language = input (“请输入编程语言:”)print (“请输入要优化的代码 (输入空行结束):”)code_lines = []while True:line = input ()if not line:breakcode_lines.append (line)code = ”
“.join (code_lines)issues = input (“请描述代码存在的问题 (可选):”)print (“正在优化代码…”)optimized = assistant.optimize_code (language, code, issues)print (”
优化后的代码及说明:”)print (optimized)
elif choice == “4”:print (“再见!”)break
else:print (“无效选项,请重试。”)
if name == “main“:main()
plaintext
#### 4.2.3 应用示例
**生成代码示例:**
- 输入语言:Python
- 功能描述:"实现一个快速排序算法,对列表进行排序,并处理空列表和重复元素的情况"
**解释代码示例:**
- 输入语言:JavaScript
- 代码:
```javascript
function debounce(func, delay) {
let timeout;
return function(...args) {
clearTimeout(timeout);
timeout = setTimeout(() => func.apply(this, args), delay);
};
}优化代码示例:
输入语言:Python代码:
python
运行
def find_duplicates(lst):
duplicates = []
for i in range(len(lst)):
for j in range(i+1, len(lst)):
if lst[i] == lst[j] and lst[i] not in duplicates:
duplicates.append(lst[i])
return duplicates问题描述:”这个函数运行太慢,特别是处理大型列表时”
4.3 自动文档生成工具
利用大模型自动生成项目文档,包括 API 文档、使用说明等。
4.3.1 实现代码
python
运行
import os
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer, pipeline
class DocGenerator:
def __init__(self, model_path):
"""初始化文档生成器"""
self.tokenizer = AutoTokenizer.from_pretrained(model_path)
self.model = AutoModelForCausalLM.from_pretrained(
model_path,
load_in_4bit=True,
device_map="auto",
torch_dtype=torch.bfloat16
)
self.generator = pipeline(
"text-generation",
model=self.model,
tokenizer=self.tokenizer,
max_new_tokens=1500,
temperature=0.5,
top_p=0.9,
repetition_penalty=1.1
)
# 文档生成模板
self.api_doc_template = """
请为以下{language}代码生成API文档:
```{language}
{code}
文档应包含:
功能概述参数说明 (名称、类型、描述、是否必填)返回值说明 (类型、描述)异常 / 错误说明使用示例注意事项请使用 Markdown 格式输出。”””
self.readme_template = “””请为一个 {project_type} 项目生成 README.md 文档,项目信息如下:项目名称: {project_name}项目描述: {description}主要功能: {features}技术栈: {tech_stack}
文档应包含以下部分:
项目简介安装步骤快速开始功能说明配置说明贡献指南许可证信息请使用 Markdown 格式输出,语言简洁明了。”””
def generate_api_doc (self, language, code):”””生成 API 文档”””prompt = self.api_doc_template.format (language=language,code=code).strip ()
result = self.generator(prompt)return result[0]['generated_text'][len(prompt):].strip()
def generate_readme (self, project_type, project_name, description, features, tech_stack):”””生成 README 文档”””prompt = self.readme_template.format (project_type=project_type,project_name=project_name,description=description,features=features,tech_stack=tech_stack).strip ()
result = self.generator(prompt)return result[0]['generated_text'][len(prompt):].strip()
def generate_docs_from_directory (self, dir_path, output_dir, language):”””从目录生成文档”””
创建输出目录
if not os.path.exists(output_dir):os.makedirs(output_dir)
遍历目录中的文件
for root, dirs, files in os.walk(dir_path):for file in files:
只处理指定语言的文件
if file.endswith (f'.{language}'):file_path = os.path.join (root, file)print (f”正在处理: {file_path}”)
读取文件内容
with open(file_path, 'r', encoding='utf-8') as f:code = f.read()
生成文档
doc = self.generate_api_doc(language, code)
保存文档
doc_filename = os.path.splitext(file)[0] + '.md'doc_path = os.path.join(output_dir, doc_filename)with open(doc_path, 'w', encoding='utf-8') as f:f.write(doc)
print (f”文档已保存至: {doc_path}”)
def main ():print (“正在加载文档生成器模型…”)doc_gen = DocGenerator (“./models/LLaMA-2-13B-Chat”)print (“文档生成器已就绪!”)
while True:print (”
请选择功能:”)print (“1. 生成 API 文档”)print (“2. 生成 README 文档”)print (“3. 批量生成目录下的文档”)print (“4. 退出”)
choice = input (“请输入选项 (1-4):”)
if choice == “1”:language = input (“请输入编程语言:”)print (“请输入代码 (输入空行结束):”)code_lines = []while True:line = input ()if not line:breakcode_lines.append (line)code = ”
“.join (code_lines)
print (“正在生成 API 文档…”)api_doc = doc_gen.generate_api_doc (language, code)
保存文档
filename = input (“请输入保存的文件名 (无需扩展名):”) + “.md”with open (filename, 'w', encoding='utf-8') as f:f.write (api_doc)print (f”API 文档已保存至 {filename}”)
elif choice == “2”:project_type = input (“项目类型 (如: Python 库、Web 应用等):”)project_name = input (“项目名称:”)description = input (“项目描述:”)features = input (“主要功能 (用逗号分隔):”)tech_stack = input (“技术栈 (用逗号分隔):”)
print (“正在生成 README 文档…”)readme = doc_gen.generate_readme (project_type, project_name, description, features, tech_stack)
with open (“README.md”, 'w', encoding='utf-8') as f:f.write (readme)print (“README.md 已生成”)
elif choice == “3”:dir_path = input (“请输入代码目录路径:”)output_dir = input (“请输入文档输出目录路径:”)language = input (“请输入编程语言:”)
print (“开始批量生成文档…”)doc_gen.generate_docs_from_directory (dir_path, output_dir, language)print (“批量生成完成”)
elif choice == “4”:print (“再见!”)break
else:print (“无效选项,请重试。”)
if name == “main“:main()
plaintext
## 5. 性能优化与扩展方案
### 5.1 模型量化
模型量化是减少模型大小和内存占用的有效方法:
```python
# 4-bit量化示例
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
model_id = "meta-llama/Llama-2-7b-chat-hf"
tokenizer = AutoTokenizer.from_pretrained(model_id)
# 加载4-bit量化模型
model = AutoModelForCausalLM.from_pretrained(
model_id,
load_in_4bit=True,
device_map="auto",
torch_dtype=torch.bfloat16,
quantization_config=BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_use_double_quant=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.bfloat16
)
)不同量化精度对比:
| 量化精度 | 模型大小减少 | 性能损失 | 适用场景 |
|---|---|---|---|
| FP16 | 50% | 小 | 追求精度,有足够 GPU 资源 |
| INT8 | 75% | 中 | 平衡性能和资源 |
| INT4 | 87.5% | 较大 | 资源受限,对精度要求不高 |
5.2 模型并行与分布式部署
对于超大型模型,可以使用模型并行技术:
python
运行
# 模型并行示例
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
model_name = "meta-llama/Llama-2-70b-chat-hf"
tokenizer = AutoTokenizer.from_pretrained(model_name)
# 使用模型并行将模型分布到多个GPU
model = AutoModelForCausalLM.from_pretrained(
model_name,
device_map="auto", # 自动分配到多个GPU
torch_dtype=torch.bfloat16,
low_cpu_mem_usage=True
)
# 测试生成
inputs = tokenizer("Hello, world!", return_tensors="pt").to("cuda:0")
outputs = model.generate(** inputs, max_new_tokens=50)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))5.3 推理优化
python
运行
# 使用FlashAttention加速推理
from transformers import AutoModelForCausalLM, AutoTokenizer
model_id = "mistralai/Mistral-7B-Instruct-v0.1"
tokenizer = AutoTokenizer.from_pretrained(model_id)
# 启用FlashAttention
model = AutoModelForCausalLM.from_pretrained(
model_id,
use_flash_attention_2=True,
device_map="auto",
torch_dtype=torch.bfloat16
)
# 测试
inputs = tokenizer("What is the meaning of life?", return_tensors="pt").to("cuda")
outputs = model.generate(**inputs, max_new_tokens=100)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))5.4 缓存策略
实现对话历史缓存,减少重复计算:
python
运行
class CachedChatbot:
def __init__(self, model, tokenizer):
self.model = model
self.tokenizer = tokenizer
self.cache = {} # 用于缓存对话历史的隐藏状态
def generate_response(self, user_message, history=None):
history = history or []
# 创建缓存键
cache_key = tuple((user, bot) for user, bot in history)
# 检查缓存
if cache_key in self.cache:
# 使用缓存的隐藏状态
input_ids = self.tokenizer(user_message, return_tensors="pt").input_ids.to("cuda")
past_key_values = self.cache[cache_key]
outputs = self.model.generate(
input_ids,
past_key_values=past_key_values,
max_new_tokens=100,
do_sample=True
)
else:
# 构建完整对话
messages = []
for user, bot in history:
messages.append({"role": "user", "content": user})
messages.append({"role": "assistant", "content": bot})
messages.append({"role": "user", "content": user_message})
input_ids = self.tokenizer.apply_chat_template(
messages,
return_tensors="pt"
).to("cuda")
# 生成时保存past_key_values用于缓存
outputs = self.model.generate(
input_ids,
max_new_tokens=100,
do_sample=True,
return_dict_in_generate=True,
output_past=True
)
# 更新缓存
self.cache[cache_key] = outputs.past_key_values
response = self.tokenizer.decode(outputs.sequences[0], skip_special_tokens=True)
return response6. 常见问题与解决方案
6.1 内存不足问题
症状:运行时出现
CUDA out of memory
解决方案:
使用更小的模型(如 7B 代替 13B 或 70B)采用模型量化(4-bit 或 8-bit 量化)启用梯度检查点:
model.gradient_checkpointing_enable()
torch.cuda.empty_cache()
6.2 模型下载缓慢或失败
解决方案:
使用 Hugging Face 镜像站手动下载模型文件并放到指定目录增加超时设置:
python
运行
from huggingface_hub import configure_http_backend
import requests
session = requests.Session()
session.timeout = 600 # 10分钟超时
configure_http_backend(backend_factory=lambda: session)6.3 推理速度慢
解决方案:
使用 GPU 而非 CPU 运行启用 FlashAttention使用量化模型减少生成的最大 token 数降低温度参数(temperature)使用更高效的推理框架(如 vLLM、Text Generation Inference)
bash
# 使用vLLM加速推理
pip install vllm
# 启动vLLM服务器
python -m vllm.entrypoints.api_server --model meta-llama/Llama-2-7b-chat-hf --quantization awq --port 80006.4 模型响应质量差
解决方案:
使用更大的模型调整生成参数(提高 temperature 增加多样性)优化提示词(更明确、更具体)使用专为特定任务微调的模型实现提示词工程技巧(如思维链提示)
6.5 部署后无法访问
解决方案:
检查防火墙设置,确保端口开放确认绑定的 IP 地址是否正确(0.0.0.0 允许外部访问)检查服务是否正常运行:
ps aux | grep python
结语
大模型本地部署为开发者和企业提供了更多灵活性和数据控制权。随着硬件成本降低和模型优化技术的进步,本地部署正变得越来越普及。本文涵盖了从环境搭建到实际应用开发的完整流程,希望能帮助读者顺利实现大模型的本地部署和应用开发。
未来,随着模型压缩、量化技术的进一步发展,以及专用 AI 硬件的普及,大模型本地部署将变得更加容易,应用场景也将更加广泛。开发者可以根据自身需求选择合适的模型和部署方案,充分发挥大模型的潜力。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...








