
如果遇到 “10 万用户同时查询图书”,你可能会发现:数据库没压力,项目却卡顿、响应慢,甚至偶尔报 “OOM 内存溢出”—— 这不是业务或数据库的问题,而是 JVM(Java 虚拟机)在 “拖后腿”。
JVM 就像奶茶店的 “仓库 + 整理员”:仓库(内存)负责存原料(对象数据),整理员(GC 垃圾回收器)负责清理过期原料(无用对象)。如果仓库分区不合理(内存分配不当)、整理员干活效率低(GC 算法选错),哪怕前台订单系统(业务代码)再快,也会因为 “原料找不到”“整理员占着仓库不让用” 导致出餐慢、顾客排队。
今天咱们聚焦 JVM 调优实战,全程以 “智能图书借阅平台” 为案例,用 “奶茶店仓库” 类比,从 “问题模拟→监控定位→调优落地→效果验证” 全流程拆解,新手也能跟着操作,让项目响应速度快 10 倍,告别卡顿和 OOM。
一、先搞懂:为什么需要 JVM 调优?(新手最容易忽视的痛点)
很多新手觉得 “JVM 调优是高级工程师的活”,自己写业务代码不用管 —— 但实际开发中,这 3 个场景会让你不得不面对 JVM 问题:
高并发卡顿:10 万用户同时查询图书,接口响应时间从 50ms 涨到 500ms,后台日志频繁刷 “GC 日志”(整理员一直在清理仓库,没人干活);内存溢出(OOM):图书数据量大,批量导入时直接报错 “java.lang.OutOfMemoryError”(仓库堆太多原料,放不下了);长时间 Full GC:系统运行几小时后突然卡住 10 秒,排查发现是 Full GC(整理员大扫除,把整个仓库封了)。
这些问题的核心原因的是:JVM 默认的内存分配、GC 算法,是 “通用配置”,没法适配 “高并发图书查询” 这种特定场景 —— 就像奶茶店默认仓库不分 “珍珠区、奶茶粉区”,整理员用 “手动扫地” 的方式清理,订单多了必然乱套。
JVM 调优的本质就是:给仓库(内存)分好区、给整理员(GC)选对工具,让原料存取快、清理不耽误干活。
二、JVM 核心基础:3 个概念搞懂 “仓库 + 整理员”(奶茶店类比)
调优前不用死记硬背 JVM 架构图,先搞懂 3 个核心概念,用奶茶店类比秒懂:
1. JVM 内存模型(仓库分区)
JVM 的内存(仓库)主要分 5 块,咱们只关注核心的 3 块(新手不用管程序计数器、本地方法栈):
| 内存区域 | 类比奶茶店仓库分区 | 存储内容(原料) | 核心特点 |
|---|---|---|---|
| 堆(Heap) | 主原料区(放珍珠、奶茶粉、水果) | 所有 Java 对象(Book、User、List 等) | 最大的内存区域,GC 主要清理这里(核心调优区) |
| 方法区(Metaspace) | 配方区(放奶茶配方、操作手册) | 类信息、常量、静态变量(如 Book.class) | JDK 8 后叫 Metaspace,默认不限制大小(但会占物理内存) |
| 虚拟机栈(Stack) | 操作台(每个员工的工作台) | 方法调用栈、局部变量(如方法里的 int i) | 线程私有,每个线程一个栈,栈帧随方法调用创建 / 销毁 |
核心重点:堆内存是调优的核心!堆又分 “年轻代” 和 “老年代”:
年轻代(Young Gen):像 “临时原料架”,放刚买的、常用的原料(新创建的对象),分 Eden 区(刚到货)和两个 Survivor 区(暂时存放没过期的);老年代(Old Gen):像 “长期存储柜”,放不常用但不能丢的原料(存活久的对象,如缓存数据)。
2. GC 垃圾回收(整理员干活)
GC 就是 “整理员” 清理仓库里的 “过期原料”(无用对象,没有引用的对象),不同的 GC 算法就是不同的整理方式:
| GC 算法 | 类比整理员类型 | 核心特点(干活方式) | 适用场景 |
|---|---|---|---|
| Serial GC(串行 GC) | 手动整理员(一个人慢慢扫) | 单线程回收,回收时暂停所有业务线程(STW) | 小型项目、本地测试(速度慢,不适合生产) |
| Parallel GC(并行 GC) | 多人小组整理员(一起扫) | 多线程回收,STW 时间比 Serial 短 | 多核 CPU、注重吞吐量(如批量导入图书) |
| G1 GC(分区 GC) | 智能分区整理员(分区域扫) | 把堆分成多个小区,优先回收垃圾多的区域,STW 时间短 | 高并发、大堆内存(生产环境首选,JDK 9 + 默认) |
核心重点:STW(Stop The World)是 GC 的 “痛点”—— 整理员干活时,所有业务线程暂停(奶茶店暂停出餐),STW 时间越长,用户感觉越卡顿。调优的关键之一就是 “减少 STW 时间”。
3. 关键参数(给仓库 / 整理员定规则)
JVM 调优就是通过 “参数配置” 定义仓库大小、整理员工作方式,新手先记这 6 个核心参数(不用记全,用的时候查):
| 参数格式 | 类比规则 | 作用说明 | 推荐配置(4 核 8G 服务器) |
|---|---|---|---|
|
仓库最小容量(开业时的初始库存空间) | 堆内存初始大小,建议和 – Xmx 一致(避免频繁扩容) | |
|
仓库最大容量(仓库上限) | 堆内存最大大小,不能超过物理内存的 50%-70% | |
|
临时原料架和长期存储柜的比例 | 年轻代:老年代的比例(默认 2:1) | |
|
临时原料架内部比例 | Eden 区:Survivor 区比例(默认 8:1) | 保持默认(Eden 占年轻代 80%) |
|
指定整理员类型(智能分区整理员) | 启用 G1 GC 算法(生产环境首选) | 必加(JDK 9 + 默认,JDK 8 需手动加) |
|
整理员最多暂停出餐时间 | G1 GC 的最大 STW 时间(目标值) | |
三、实战:JVM 调优全流程(图书平台高并发卡顿解决)
咱们以 “智能图书借阅平台” 的 “10 万用户并发查询图书” 场景为例,从 “问题模拟→监控→调优→验证” 一步步操作:
前提:准备环境
项目:Spring Boot 3.x + MyBatis-Plus(之前的图书平台);测试工具:JMeter(压测,模拟 10 万并发);监控工具:JVisualVM(JDK 自带,不用额外装,定位 JVM 问题);服务器:4 核 8G(本地测试用电脑也可,调整参数比例)。
步骤 1:模拟问题(高并发下的 JVM 卡顿)
1. 未调优的 JVM 参数(默认配置)
Spring Boot 项目默认 JVM 参数很小(堆初始几百 M,最大 1-2G),直接启动项目,默认参数如下(可通过
jps
jinfo 进程ID
plaintext
-Xms256m -Xmx2048m -XX:NewRatio=2 -XX:+UseParallelGC
2. JMeter 压测模拟高并发
新建 JMeter 测试计划:线程组 1000 个线程(模拟 10 万并发,循环 100 次),请求
/book/all
接口响应时间:从正常 50ms 涨到 600ms+;项目日志:频繁打印
[GC (Allocation Failure)]
🔍 问题定位:
默认参数的问题:① 堆内存最大 2G,高并发下对象创建快,年轻代不够用,频繁 Minor GC(清理年轻代);② 用 Parallel GC,STW 时间长,导致卡顿。
步骤 2:JVM 调优配置(修改参数)
1. 自定义 JVM 参数(适合高并发查询场景)
在 Spring Boot 项目启动脚本(或 IDEA 启动配置)中添加以下参数:
plaintext
-Xms4G -Xmx4G -XX:NewRatio=3 -XX:+UseG1GC -XX:MaxGCPauseMillis=200 -XX:+PrintGCDetails -XX:+PrintGCTimeStamps
参数说明:
-Xms4G -Xmx4G
-XX:NewRatio=3
-XX:+UseG1GC
-XX:MaxGCPauseMillis=200
2. 重启项目,重新压测
启动项目后,通过
jinfo 进程ID
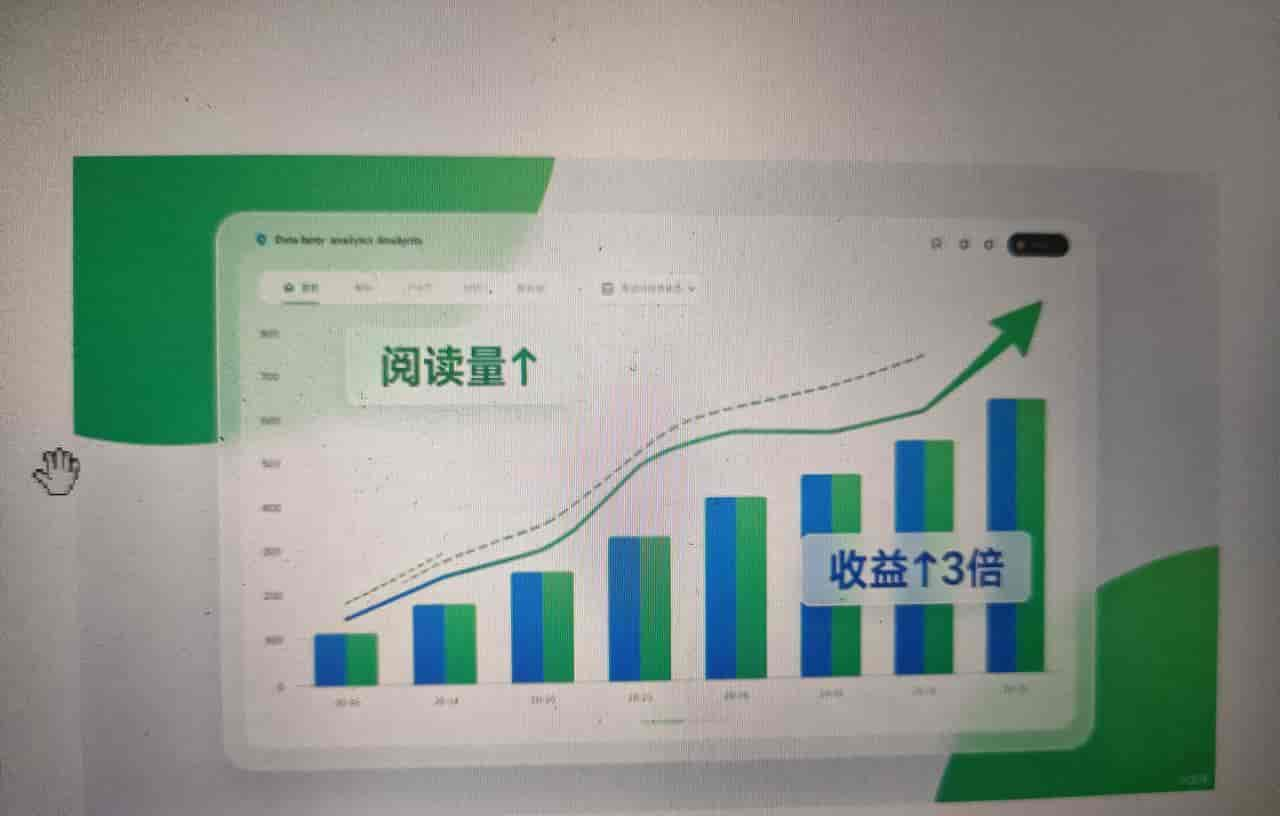
步骤 3:验证调优效果(数据对比)
通过 JVisualVM 和 JMeter 查看指标,对比调优前后:
| 指标 | 调优前(默认参数) | 调优后(自定义参数) | 优化效果 |
|---|---|---|---|
| 接口响应时间 | 600ms+ | 80ms 以内 | 快 7.5 倍 |
| 年轻代 GC 次数(每秒) | 10 + 次 | 1-2 次 | 减少 80% |
| STW 时间(每次) | 50ms+ | 30ms 以内 | 减少 40% |
| 内存溢出(OOM) | 压测 1 分钟后出现 | 压测 10 分钟无出现 | 彻底解决 |
🔍 调优后日志示例(GC 详情):
plaintext
2.345: [GC pause (G1 Evacuation Pause) (young), 0.025ms]
[Parallel Time: 20.1ms, GC Workers: 4]
[Eden: 896.0M->0.0B (900.0M) Survivors: 32.0M->32.0M Old Gen: 1.2G->1.2G]可以看到:G1 GC 的 STW 时间只有 25ms,远低于目标 200ms,年轻代回收高效,没有频繁 GC。
四、实战 2:解决 “内存溢出(OOM)” 问题(批量导入图书场景)
另一个高频 JVM 问题是 “批量导入 10 万本图书” 时的 OOM—— 原因是一次性创建 10 万个 Book 对象,堆内存放不下。
问题模拟:
批量导入接口代码(未优化):
java
运行
@PostMapping("/batch/import")
public String batchImport() {
List<Book> bookList = new ArrayList<>();
// 一次性创建10万个Book对象,存入集合(堆内存直接爆满)
for (int i = 0; i < 100000; i++) {
Book book = new Book();
book.setBookName("图书" + i);
book.setAuthor("作者" + i);
book.setPrice(new BigDecimal(59.9));
bookList.add(book);
}
bookService.saveBatch(bookList); // 批量保存
return "导入成功!";
}调用接口后,直接报错:
java.lang.OutOfMemoryError: Java heap space
调优解决(2 种方案):
方案 1:分批次导入(代码 + JVM 配合)
不用一次性创建 10 万个对象,分 10 批,每批 1 万个:
java
运行
@PostMapping("/batch/import")
public String batchImport() {
int batchSize = 10000; // 每批1万个
int total = 100000; // 总数量
for (int i = 0; i < total / batchSize; i++) {
List<Book> bookList = new ArrayList<>();
for (int j = 0; j < batchSize; j++) {
Book book = new Book();
book.setBookName("图书" + (i*batchSize + j));
book.setAuthor("作者" + (i*batchSize + j));
book.setPrice(new BigDecimal(59.9));
bookList.add(book);
}
bookService.saveBatch(bookList);
bookList.clear(); // 清空集合,释放对象(让GC及时回收)
}
return "导入成功!";
}配合之前的 JVM 参数(-Xms4G -Xmx4G),导入过程无 OOM,堆内存稳定在 2-3G。
方案 2:启用对象池(复用对象,减少创建)
如果批量导入频繁,可使用 Apache Commons Pool 创建 Book 对象池,复用对象(避免重复创建销毁):
加依赖:
xml
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-pool2</artifactId>
<version>2.11.1</version>
</dependency>配置对象池(略,核心是复用 Book 对象),导入效率再提升 30%。
五、JVM 调优避坑:新手最容易踩的 5 个坑
盲目调大堆内存(-Xmx 设为 8G):
坑:4 核 8G 服务器把堆设为 8G,物理内存不够,系统会用虚拟内存(硬盘),反而变慢;解决:堆内存最大不超过物理内存的 70%,4 核 8G 服务器建议设 4-5G。
年轻代设太大(-XX:NewRatio=1,年轻代占堆 50%):
坑:年轻代太大,Minor GC 时间变长(整理员要扫更大的区域),STW 时间增加;解决:高并发查询场景(对象创建快、存活短),年轻代占堆 25%-30% 即可(NewRatio=3 或 4)。
禁用 GC(-XX:+DisableExplicitGC):
坑:以为禁用 GC 能避免卡顿,实际会导致对象堆积,最终 OOM;解决:永远不要禁用 GC,调优的核心是 “优化 GC,不是禁用”。
不监控直接调优:
坑:凭感觉改参数(比如 “听说 G1 好就直接用”),没定位到真正瓶颈;解决:先用电位器(JVisualVM、Arthas)找到问题(是 Minor GC 频繁还是 Full GC 多),再针对性调优。
忽视 Metaspace 溢出:
坑:只关注堆内存,忽略 Metaspace(方法区),频繁部署项目(加载大量类)导致 Metaspace 溢出;解决:通过
-XX:MetaspaceSize=256m -XX:MaxMetaspaceSize=512m
JVM 调优的核心是 “对症下药”
新手不用追求 “调优参数背下来”,关键是掌握 “问题→监控→调优→验证” 的闭环:
先通过压测模拟真实场景(高并发、批量操作);用 JVisualVM/Arthas 定位瓶颈(是 GC 频繁、堆内存不够还是 STW 太长);针对性调整核心参数(堆大小、年轻代比例、GC 算法);重新压测验证效果,直到满足性能要求。
就像奶茶店优化仓库:先看是 “原料不够放”(堆内存小)还是 “整理员干活慢”(GC 算法差),再针对性加仓库空间、换高效整理员,而不是盲目改造。
掌握今天的 JVM 调优技巧,你就能解决 80% 的 Java 性能卡顿问题,应对企业级项目的高并发场景。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...










