目录
人工智能技术及应用
例题解析
考试大纲题型示例
模拟卷答案
题包A
题包B
题包C
题包D
题包E
题包F
题包G
题包H
题包I
主包今年参加了“2025年上海市高等学校信息技术水平考试”,在复习的时候发现模拟卷是没有答案的,所以抽空做这一篇文章
人工智能技术及应用
例题解析
(一)单选题样例
题目:在机器学习中,损失函数(loss函数)的作用是
选项:A.牵引模型参数的更新B.增加网络层次C.修改模型参数D.防止过拟合
知识点:[38040104]损失函数
答案:A解析:
A选项正确:损失函数计算模型预测值与真实值之间的差异(误差),这个差异值会通过反向传播算法指导型参数的调整方向(如梯度下降),牵引参数不断优化以减小误差,是模型学习的核心驱动力,因此A正确。B选项错误:增加网络层次是模型结构设计的范畴(如加深神经网络层数),与损失函数的功能无关,因此B错误。
C选项错误:损失函数本身不直接修改模型参数,而是通过计算误差提供参数更新的“依据”,实际修改参数的是优化算法(如 SGD、Adam)因此C错误。
D选项错误:防止过拟合通常通过正则化(L1/L2 正则)dropout、早停等技术实现,损失函数的主要作用是衡量误差而非防止过拟合,因此只错误。
(二)多选题样例
题目:卷积神经网络CNN的层级结构包括
选项:A.卷积层
B.池化层(汇聚层)
C.循环层
D.全连接层
知识点:[38110201JCNN特点及经典模型(LeNet、ResNet答案:ABD
解析:
A选项(卷积层)卷积层是 CNN 的核心层级,通过卷积核提取输入数据公如图像)的局部特征,是CNN 区别于传统神经网络的关键结构之一,因此A正确。
B选项(池化层/汇聚层)池化层通常紧跟卷积层通过采样减少特征图维度、、降低计算量,同时保留关键特征,是CNN 的典型层级,因此B正确。
C选项(循环层):循环层(如 LSTM、GRU 中的层级)属于循环神经网络(RNN)的结构,用于处理序列数据的时序依赖关系,与 CNN的层级结构无关,因此C错误。D选项(全连接层):全连接层通常位于CNN的后端将前面卷积层、池化层提取的高维特征映射为一维向量最终用于分类或回归任务,是CNN的常见层级,因此D正确。
(三)主观题样例
城市数字化转型中,智能技术赋能数字生活,采用推荐系统促进消费升级,通过在线用户的特征预测出用户购买偏好。
如下表所示,其中“性别”属性中,0表示女,1表示男;“行业”属性中,0表示信息产业,1表示交通运输业,2表示金融业“购买偏好”属性中,1表示购买智能音箱,2表示购买扫地机器人,
根据用户的特征(“年龄”“性别”和“行业”)可以预测出用户要购买智能音箱或购买扫地机器人的偏好。
|
用户序号 |
年龄(岁) |
性别 |
行业 |
购买偏好 |
|
|
训练样本 |
1 |
21 |
1 |
0 |
1 |
|
2 |
19 |
0 |
0 |
1 |
|
|
3 |
44 |
1 |
1 |
2 |
|
|
4 |
32 |
1 |
2 |
1 |
|
|
5 |
49 |
0 |
1 |
2 |
|
|
6 |
28 |
0 |
1 |
2 |
|
|
7 |
25 |
1 |
2 |
1 |
|
|
测试样本 |
8 |
38 |
1 |
2 |
? |

步骤 1:训练数据集的标签(空 1)训练样本的“购买偏好”依次为:用户1(1)、用户 2(1)、用户 3(2)用户 4(1)、用户5(2)、用户、用户7(1)。因此,训练标签数组应与这些值-一对应。
选项中,A选项y=np.array([1,1,2,1,2,2,1])与训练样本的“购买偏好”完全匹配,因此选 A。
步骤 2:初始化 KNN 分类器(空 2)
KNeighborsClassifier 的核心参数是nkeighbors(指定“近邻个数 K”)。需要注意参数名是 nneighbors(复数形式),而非nneighbor(单数错误)。选项中,C 选项nneighbors=5 符合参数要求,因此空2选 C
步骤 3:模型训练(空 3)KNN 模型训练的方法是 ft(X,y),其中X是特征数据(训练样本的“年龄性别、行业”),y是标签数据(训练样本的“购买偏好”)选项中,E选项 knn.fit(x,y)符合 fit方法的参数要求(x是特征,y是标签),因此空 3选 E。
步骤 4:测试样本预测(空 4)
测试样本是“用户 8”,其特征为:年龄 38、性别 1、行业 2。因此预测时传入的特征应为 [[38,1,2]]。KNN 预测方法是 predict(测试特征),故选项 H 中 p= knn.predict([[38,1,2]])符合要求,空 4选 H。
考试大纲题型示例
1.单选题
在手写数字识别问题中,如果忽略训练数据的标签,仅根据特征组将训练数据分类,这是一
个________学习过程。
130
131
A
.无监督
B
.有监督
C
.弱监督
D
.半监督
【参考答案】
A
【能力目标】掌握无监督学习特点,考核人工智能基本素养。
【知识内容】知识点是机器学习中,无监督学习的概念。
2.多选题
文本语料库的可能用到的特征有________。
A
.文本中词计数
B
.词的向量标注
C
.词性标注(
Part of Speech Tag
)
D
.基本依存语法
【参考答案】
ABCD
【能力目标】 掌握自然语言处理基本概念,考核人工智能基本素养。
【知识内容】知识点是自然语言处理中分词、词性标注、句法分析基础知识。
3.程序选择题
【例
1
】
请在以下选项中选择正确函数填入相应程序空格内。
A
.
random.choice
()
B
.
getAge
()
C
.
range
()
D
.
getSex
()
E
.
random.randint
()
F
.
write
()
编写程序,生成
20
个人的模拟信息,包括性别、年龄并把生成的信息写入文本文件。程序
如下:
def getSex
():
return
(
1
) (('男', '女'))
def getAge
():
return str
(
random.randint
(
18
,
100
))
def main
(
filename
):
132
with open
(
filename
, '
w
',
encoding
='
utf-8
')
as fp
:
# 写入表头
fp.write
('
Sex
,
Age
n
')
# 生成
20
个人的随机信息
for i in range
(
20
):
sex
= (
2
)
age
= (
3
)
line
= ','
.join
([
sex
,
age
])+'
n
'
fp.write
(
line
)
【参考答案】(
1
)【
A
】;(
2
)【
D
】;(
3
)【
B
】
【能力目标】考核人工智能基本素养和编程实现调试能力。
【知识内容】知识点是机器学习中的数据集。
【例
2
】请在以下选项中选择正确代码填入相应程序空格内。
A
.
ss.fit
_
transform
(
X
_
train
)
B
.
knc.predict
(
X
_
test
)
C
.
data
,
target
,
test
_
size
=
0.7
D
.
ss.transform
(
X
_
train
)
E
.
classification
_
report
(
y
_
test
,
y
_
predict
F
.
data
,
target
,
test
_
size
=
0.3
G
.
knc.predict
(
X
_
train
)
H
.
knc.fit
(
X
_
train
,
y
_
train
)
I
.
report
(
y
_
test
,
y
_
predict
J
.
knc.fit
(
X
_
test
,
y
_
test
)
程序实现以下功能:
1
.读取鸢尾花数据集,将数据集随机划分为训练集和测试集,且测试集所占比例为
30%
。
2
.对训练集进行标准化拟合和转换,对测试集进行标准化转换。
3
.基于
KNN
算法进行分类,利用训练集的特征数据和标签数据进行模型拟合。
4
.对测试集的特征数据进行类别预测,预测结果储存在变量
y
_
predict
中。
5
.根据测试集的标签数据,以及预测结果,计算并显示主要分类指标的文本报告。
请从以下选项中选择正确的代码填入相应的横线处,补全程序。
程序运行结果如下图所示。注意:考生只可补全代码,不可修改或删除横线处以外任何代码。
程序代码如下:
#导入库
from sklearn.datasets import load
_
iris
from sklearn.model
_
selection import train
_
test
_
split
from sklearn.preprocessing import StandardScaler
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import classification
_
report
#导入用于显示主要分类指标文本报
告的函数
#利用
load
_
iris
读取鸢尾花数据集
iris
=
load
_
iris
()
data
=
iris.data
target
=
iris.target
X
_
train
,
X
_
test
,
y
_
train
,
y
_
test
=
train
_
test
_
split
(___(
1
)___,
random
_
state
=
8
) #
3
分切分数据
集,测试集占比
30%
#标准化数据
ss
=
StandardScaler
()
X
_
train
= ___(
2
)___ #
3
分 对训练集拟合和转换
X
_
test
=
ss.transform
(
X
_
test
)
#使用
K
近邻分类器对测试数据进行类别预测
133
knc
=
KNeighborsClassifier
()
___(
3
)___ #
3
分 模型拟合
y
_
predict
= ___(
4
)___ #
3
分 模型预测
#显示主要分类指标的文本报告
report
= ___(
5
)___,
target
_
names
=
iris.target
_
names
) #
3
分
print
(
report
)
【参考答案】
(
1
)
F
、
data
,
target
,
test
_
size
=
0.3
(
2
)
A
、
ss.fit
_
transform
(
X
_
train
)
(
3
)
H
、
knc.fit
(
X
_
train
,
y
_
train
)
(
4
)
B
、
knc.predict
(
X
_
test
)
(
5
)
E
、
classification
_
report
(
y
_
test
,
y
_
predict
【能力目标】
(
1
)理解训练相关概念,考核机器学习基础和应用能力;
(
2
)理解数据预处理,考核机器学习基础和应用能力;
(
3
)掌握
KNN
算法的应用,考核机器学习基础和应用能力;
(
4
)掌握
KNN
算法的应用,考核机器学习基础和应用能力;
(
5
)理解评价指标,考核机器学习基础和应用能力。
【知识内容】
(
1
)训练相关概念(数据集的切分);
(
2
)数据预处理(数据集的标准化);
(
3
)
KNN
算法的应用(
KNN
的模型拟合);
(
4
)
KNN
算法的应用(
KNN
的模型预测);
(
5
)评价指标(分类指标报告)。
4.程序设计
要求:请补全程序中缺失的部分。
题目:采用
Sklearn
绘制散点图,并呈现在右上方。
134
import xlrd
import matplotlib.pyplot as plt
import numpy as np
from sklearn import model
_
selection
from sklearn.linear
_
model import LogisticRegression
from sklearn import metrics
data
=
xlrd.open
_
workbook
(
sandianshuju.xlsx
')
sheet
=
data.sheet
_
by
_
index
(
0
)
Density
=
sheet.col
_
values
(
6
)
Sugar
=
sheet.col
_
values
(
7
)
Res
=
sheet.col
_
values
(
8
)
# 读取原始数据
X
=
np.array
( [
Density
,
Sugar
] )
#
y
的尺寸为(
17
)
y
=
np.array
(
Res
)
X
=
X.reshape
(
17
,
2
)
# 绘制分类数据
f1
=
plt.figure
(
1
)
plt.title
('
watermelon
_
3a
')
plt.xlabel
('
density
')
plt.ylabel
('
ratio
_
sugar
')
# 绘制散点图(
x
轴为密度,
y
轴为含糖率,呈现在右上方)
plt.scatter
(
X
[
y
==
0
,
0
],
X
[
y
==
0
,
1
],
marker
= '
o
',
color
= '
k
',
s
=
100
,
label
= '
bad
')
plt.scatter
(
X
[
y
==
1
,
0
],
X
[
y
==
1
,
1
],
marker
= '
o
',
color
= '
g
',
s
=
100
,
label
= '
good
')
plt.legend
( (
1
) )
plt.show
( )
162
# 从原始数据中选取一半数据进行训练,另一半数据进行测试
X
_
train
,
X
_
test
,
y
_
train
,
y
_
test
=
model
_
selection.train
_
test
_
split
(
X
,
y
,
test
_
size
=
0.5
,
random
_
state
=
0
)
135
# 逻辑回归模型
log
_
model
=
LogisticRegression
( )
# 训练逻辑回归模型
log
_
model.fit
(
X
_
train
,
X
_
test
)
# 预测
y
的值
y
_
pred
=
log
_
model.predict
( (
2
) )
# 查看测试结果
print
(
metrics.confusion
_
matrix
(
y
_
test
,
y
_
pred
))
print
(
metrics.classification
_
report
(
y
_
test
,
y
_
pred
))
【参考答案】(
1
)
loc
= '
upper right
';(
2
)
X
_
test
【能力目标】本题需要一定的知识综合理解能力,涉及机器学习模型库的使用,图形可视化
的实现方法,考核人工智能基本素养、智能算法思维能力和编程实现调试能力。
【知识内容】知识点是机器学习中的
Logistic
回归实现。
5.程序阅读题
阅读和分析程序,按下列要求完成题目。程序通过神经网络对
Fashion MNIST
数据集进行分
类训练和模型评估。程序运行结果如样张所示。注意:此题仅做阅读和分析,无需运行和调试。
请针对程序中
5
处【_题号_】所在的代码行,从以下选项中选择对该行恰当的代码解释,并
将选项编号填入【】内,如【
A
】,注意编号不区分大小写。
A
.导入
tf
库,命名为
tensorflow
。
B
.以
load
_
model
('
model
_
2024.h5
')为名保存模型。
C
.显示训练集的前
9
个图像及其类别。
D
.显示测试集的前
10
个图像及其类别。
E
.加载名为
model
_
2024.h5
的模型。
F
.添加名为
softmax
的输入层,该层包含
10
神经元,激活函数为
Output
。
G
.模型评估。
H
.添加名为
Output
的输出层,该层包含
10
神经元,激活函数为
softmax
。
I
.模型构建。
J
.导入
tensorflow
库,命名为
tf
。
136
137
# 导入库
import tensorflow astf
#【_
1
_】
import matplotlib.pyplot as plt
# 载入
fashion
_
mnist
数据集
fashion
_
mnist
=
tf.keras.datasets.fashion
_
mnist
(
X
_
train
,
y
_
train
), (
X
_
test
,
y
_
test
) =
fashion
_
mnist.load
_
data
()
# 建立映射表
class
_
names
= ['
T-shirt/top
', '
Trouser
', '
Pullover
', '
Dress
', '
Coat
',
'
Sandal
', '
Shirt
', '
Sneaker
', '
Bag
', '
Ankle boot
']
plt.figure
(
figsize
=(
12
,
8
))
for i in range
(
0
,
9
):
plt.subplot
(
3
,
3
,
i
+
1
)
plt.imshow
(
X
_
train
[
i
],
cmap
='
gray
')
plt.xticks
([])
plt.yticks
([])
plt.title
(”
True
=”+
str
(
class
_
names
[
y
_
train
[
i
]]))
plt.show
() #【_
2
_】
# 利用
reshape
函数转换数字图像
X
_
train
_
reshape
=
X
_
train.reshape
(
X
_
train.shape
[
0
],
28
*
28
)
X
_
test
_
reshape
=
X
_
test.reshape
(
X
_
test.shape
[
0
],
28
*
28
)
# 归一化数字图像
X
_
train
_
norm
,
X
_
test
_
norm
=
X
_
train
_
reshape / 255.0
,
X
_
test
_
reshape / 255.0
# 构建
Sequential
模型
138
model
=
tf.keras.models.Sequential
()
model.add
(
tf.keras.layers.Dense
(
40
,
input
_
dim
=
28
*
28
,
activation
='
relu
',
name
='
Hidden1
'))
model.add
(
tf.keras.layers.Dense
(
40
,
activation
='
relu
',
name
='
Hidden2
'))
model.add
(
tf.keras.layers.Dense
(
10
,
activation
='
softmax
',
name
='
Output
')) #【_
3
_】
# 打印模型概况
print
(
model.summary
())
# 模型编译
print
('
compiling…
n
')
model.compile
(
optimizer
='
adam
',
loss
='
sparse
_
categorical
_
crossentropy
',
metrics
=['
accuracy
'])
print
('
fitting…
n
')
model.fit
(
X
_
train
_
norm
,
y
_
train
,
epochs
=
4
,
validation
_
split
=
0.25
,
verbose
=
2
)
print
('
evaluating …
n
')
model.evaluate
(
X
_
test
_
norm
,
y
_
test
,
verbose
=
2
) #【_
4
_】
modelname
='
model
_
2024.h5
'
print
('
model saving …
n
')
model.save
(
modelname
)
print
('
loading model …
n
')
model
=
tf.keras.models.load
_
model
(
modelname
) #【_
5
_】
print
('
predicting…
n
')
prediction
=
model.predict
_
classes
(
X
_
test
_
norm
)
139
print
(“{:
15
}
t
{:
15
}”
.format
(”
True
“,”
Prediction
“))
for i in range
(
0
,
9
):
print
(“{:
15
}
t
{:
15
}”
.format
(
str
(
class
_
names
[
y
_
test
[
i
]]),
str
(
class
_
names
[
prediction
[
i
]])))
【参考答案】
J
、
C
、
H
、
G
、
E
【能力目标】本题需要一定的知识综合理解能力,涉及神经网络的构建与评估,以及图形可
视化的实现方法等,考核人工智能基本素养、智能算法思维能力。
【知识内容】知识点是神经网络的构建。
6.方案设计
如何为自动驾驶汽车提供训练数据?如何进行训练?
【参考答案】
提供数据:(
1
)汽车数据收集:传感器信号、视频等(
2
)模拟环境数据
训练方法:(
1
)监督学习;(
2
)强化学习
【能力目标】本题需要一定的知识综合知识,理解无人驾驶和智能交通领域知识基础和应用
常识,考核问题理解分析能力、创新应用拓展能力和持续学习演进能力。
【知识内容】知识点是智能交通的定义及主要技术。
7.分析论述
鸟能飞的实例见下表:

(
1
)请画出鸟飞的决策树(注:上机考试时提供多个模块供拖拽、连接、补全数字);
(
2
)鸟飞的规则是什么?
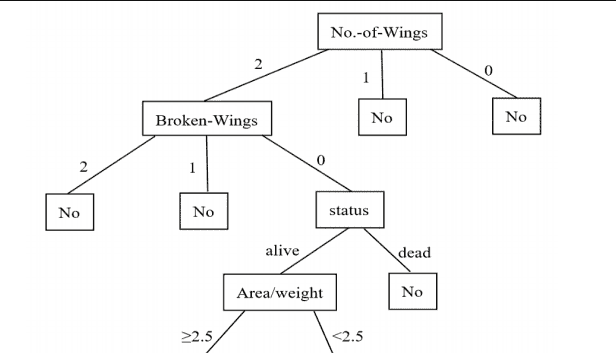
【参考答案】(1)
(
2
)
Fly
=(
no.-of-wings
=
2
)∧(
broken-wings
=
0
) ∧(
status
=
alive
) ∧(
area/weight
≥
2.5
)
【能力目标】 掌握决策树模型构建及应用,考核人工智能基本素养、问题理解分析能力。
【知识内容】知识点是机器学习中的决策树模型原理与方法。
模拟卷答案
题包A
一、单选题
1. A 2. C 3. D 4. B 5. B
6. B 7. A 8. A 9. A 10. D
二、多选题
1. ABD 2. ABD 3. ABC 4. ABCD 5. ABD
6. ABCD 7. ABCD 8. AB 9. ABCD 10. ABCD
三、程序填空题
(1) A (2) E (3) C
题包B
一、单选题
1. D 2. D 3. A 4. B 5. D
6. A 7. B 8. B 9. A 10. A
二、程序填空题
(1) F (2) E (3) A
题包C
一、单选题
1. D 2. C 3. A 4. B 5. C
6. A 7. B
二、多选题
1. ABCD 2. ABCD 3. BCD
三、程序填空题
(1) E (2) C (3) F
题包D
一、单选题
1. C 2. C 3. B 4. A 5. A
6. B 7. A 8. C 9. A
二、多选题
1. ABCD
三、程序填空题
(1) F (2) D (3) A
题包E
一、单选题
1. D 2. B 3. A 4. B
二、多选题
1. AC 2. ABCD 3. AB 4. BCD 5. ABC 6. ABC
三、程序填空题
(1) A (2) D (3) E
题包F
一、单选题
1. B 2. A 3. C 4. A
二、多选题
1. ABC 2. ABC 3. ABCD 4. CD 5. B 6. ABC
三、程序填空题
(1) B (2) C (3) E
题包G
一、单选题
1. A 2. A 3. B 4. A 5. A 6. D
二、多选题
1. BC 2. ABC 3. AB 4. ABCD
三、程序填空题
(1) A (2) C (3) F
题包H
一、编程题
1. (1) A (2) C (3) E (4) H
2. (1) A (2) D (3) F (4) D
3. (1) `labelCounts = {}`
(2) `labelCounts[currentLabel] += 1`
(3) `prob * np.log2(prob)`
二、论述题
| | 是否相同 | SVM | 逻辑回归 |
| 目标 | 否 | E | F |
| 优化目标 | 否 | C | D |
| 输出结果 | 否 | F | G |
| 适合场景 | 否 | A | B |
题包I
一、编程题
1. (1) B (2) D (3) F (4) G
2. (1) A (2) C (3) E (4) H
二、方案设计题
数据获取模块 —— 技术方法:网络爬虫 —— 指标:数据量
数据预处理模块 —— 技术方法:文本清洗 —— 指标:精度
特征提取模块 —— 技术方法:用多层卷积计算特征 —— 指标:层数
情感分类模块 —— 技术方法:CNN分类器 —— 指标:准确率、召回率、F1值
三、论述题
(1) 15 (2) 23 (3) 0.2 (4) 0.8 (5) 16.6 (6) C (7) 27.71
声明:著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
创作声明:部分内容由AI辅助生成
内容来源网络,进行整合/再创作
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...