目录
特征筛选方法
方法一:过滤法
1. 方差筛选
2. 单变量特征选择
方法二:包裹法
递归特征消除
方法三:嵌入法
1. 使用L1正则化的模型
2. 基于树模型的特征重要性
特征筛选方法
特征筛选方法通常分为三类,其严格性和复杂度递增:
过滤法:基于特征的统计属性进行筛选,独立于任何机器学习模型。优点:速度快、计算成本低。缺点:未考虑特征与模型的关系,可能漏掉重要特征组合。包裹法:使用模型的性能作为评价准则来选择一个最优的特征子集。优点:考虑特征与模型的交互,通常能获得性能更好的特征子集。缺点:计算成本非常高,尤其特征数量多时。嵌入法:特征选择过程嵌入在模型训练过程中。模型在训练时会自动进行特征选择。优点:结合了过滤法的效率和包裹法的准确性,是最常用且实用的方法。
方法一:过滤法
这类方法使用统计检验来评估每个特征与目标变量之间的关联度。
1. 方差筛选
思想:方差接近0的特征几乎为常数,对模型没有贡献,可以移除。
## 过滤法
# 1. 方差筛选
import pandas as pd
from sklearn.feature_selection import VarianceThreshold
from sklearn.datasets import make_classification
X, y = make_classification(n_samples=100, n_features=10, n_informative=5, n_redundant=2, random_state=42)
X_df = pd.DataFrame(X, columns=[f'feature_{i}' for i in range(X.shape[1])])
# 初始化方差阈值选择器 (例如,移除方差小于0.01的特征)
selector = VarianceThreshold(threshold=0.01)
X_low_variance = selector.fit_transform(X_df)
# 查看被保留的特征
selected_features = X_df.columns[selector.get_support()]
print(f"原始特征数: {X_df.shape[1]}") # 10
print(f"方差筛选后特征数: {X_low_variance.shape[1]}") # 10
print(f"保留的特征: {list(selected_features)}") # ['feature_0', 'feature_1', 'feature_2', 'feature_3', 'feature_4', 'feature_5', 'feature_6', 'feature_7', 'feature_8', 'feature_9']2. 单变量特征选择
思想:使用统计检验(如卡方检验、F检验、互信息)单独评估每个特征与目标的关系。
# 2. 单变量特征选择
from sklearn.feature_selection import SelectKBest, f_classif, mutual_info_classif, chi2
from sklearn.preprocessing import MinMaxScaler
# 为了使用卡方检验,确保数据为非负数
X_scaled = MinMaxScaler().fit_transform(X_df)
# 选择K个最好的特征 (这里以F检验为例)
k = 5
selector_f = SelectKBest(score_func=f_classif, k=k) # 适用于回归问题用 f_regression
X_kbest_f = selector_f.fit_transform(X_df, y)
# 查看每个特征的得分和选择结果
scores = selector_f.scores_
selected_mask = selector_f.get_support()
selected_features_f = X_df.columns[selected_mask]
print("F检验得分:", scores) # [ 1.23090684 6.40419177 21.48981748 0.18309405 0.12397718 8.50993664 1.30182774 10.90883545 1.45030549 22.27310935]
print(f"F检验选择的Top-{k}特征: {list(selected_features_f)}") # ['feature_1', 'feature_2', 'feature_5', 'feature_7', 'feature_9']
# 使用互信息 (可以捕捉非线性关系)
selector_mi = SelectKBest(score_func=mutual_info_classif, k=k)
X_kbest_mi = selector_mi.fit_transform(X_df, y)
selected_features_mi = X_df.columns[selector_mi.get_support()]
print(f"互信息选择的Top-{k}特征: {list(selected_features_mi)}") # ['feature_1', 'feature_2', 'feature_3', 'feature_5', 'feature_9']方法二:包裹法
递归特征消除
思想:从一个包含所有特征的特征集开始,反复构建模型(如逻辑回归、SVM),每次剔除最不重要的特征(如模型系数最小的特征),直到达到指定的特征数量。
## 包裹法
# 递归特征消除
from sklearn.feature_selection import RFE
from sklearn.linear_model import LogisticRegression
from sklearn.svm import SVC
estimator = LogisticRegression(max_iter=1000, random_state=42)
# 选择要保留的特征数量
n_features_to_select = 5
selector_rfe = RFE(estimator=estimator, n_features_to_select=n_features_to_select, step=1) # step=1表示每次移除一个特征
X_rfe = selector_rfe.fit_transform(X_df, y)
# 查看选择过程和结果
print("特征排名(1表示被选中):", selector_rfe.ranking_) # [6 5 1 2 1 1 3 1 4 1]
print("哪些特征被选中:", selector_rfe.support_) # [False False True False True True False True False True]
selected_features_rfe = X_df.columns[selector_rfe.support_]
print(f"RFE选择的{ n_features_to_select}个特征: {list(selected_features_rfe)}") # ['feature_2', 'feature_4', 'feature_5', 'feature_7', 'feature_9']
# RFECV:通过交叉验证自动确定最佳特征数量
from sklearn.feature_selection import RFECV
rfecv = RFECV(estimator=estimator, step=1, cv=5, scoring='accuracy') # 使用5折交叉验证,以准确率评估
rfecv.fit(X_df, y)
print(f"
RFECV确定的最佳特征数量: {rfecv.n_features_}") # 5
print("被选中的特征:", X_df.columns[rfecv.support_]) # Index(['feature_2', 'feature_4', 'feature_5', 'feature_7', 'feature_9'], dtype='object')
# 绘制特征数量与交叉验证得分的关系
import matplotlib.pyplot as plt
plt.figure(figsize=(10, 6))
plt.plot(range(1, len(rfecv.cv_results_['mean_test_score']) + 1), rfecv.cv_results_['mean_test_score'])
plt.xlabel("Number of Features Selected")
plt.ylabel("Cross Validation Score (accuracy)")
plt.title("Recursive Feature Elimination with Cross-Validation")
plt.grid(True)
plt.show()
方法三:嵌入法
这类方法在模型训练过程中自动进行特征选择。
1. 使用L1正则化的模型
思想:L1正则化(Lasso)会将不重要的特征系数压缩为0,从而实现特征选择。
## 嵌入法
# 1. 使用L1正则化的模型
from sklearn.linear_model import Lasso, LogisticRegression
from sklearn.preprocessing import StandardScaler # L1正则化对尺度敏感,需要标准化
# 回归问题 - Lasso
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X_df)
lasso = Lasso(alpha=0.1) # alpha是正则化强度,可通过交叉验证调整
lasso.fit(X_scaled, y)
# 查看系数,系数为0的特征被剔除
lasso_coef = lasso.coef_
selected_features_lasso = X_df.columns[lasso_coef != 0]
print(f"Lasso回归系数: {lasso_coef}")
# [-0. 0. 0.10746866 0. -0. -0.01519567
# 0. 0.05716647 0. -0.12494623]
print(f"Lasso选择的特征数: {len(selected_features_lasso)}") # 4
print(f"特征: {list(selected_features_lasso)}") # ['feature_2', 'feature_5', 'feature_7', 'feature_9']
# 分类问题 - L1正则化的逻辑回归
logistic_l1 = LogisticRegression(penalty='l1', solver='liblinear', C=0.1, random_state=42) # C是alpha的倒数
logistic_l1.fit(X_scaled, y)
logistic_coef = logistic_l1.coef_[0]
selected_features_logistic = X_df.columns[logistic_coef != 0]
print(f"
L1逻辑回归系数: {logistic_coef}")
# [ 0. 0. 0.48837018 0. 0. -0.06893589
# 0. 0.24726681 0. -0.55167154]
print(f"L1逻辑回归选择的特征数: {len(selected_features_logistic)}") # 4
print(f"特征: {list(selected_features_logistic)}") # ['feature_2', 'feature_5', 'feature_7', 'feature_9']2. 基于树模型的特征重要性
思想:树模型(如随机森林、XGBoost)可以计算每个特征在减少不纯度(基尼不纯度或信息增益)方面的贡献度。
# 2. 基于树模型的特征重要性
from sklearn.ensemble import RandomForestClassifier
from xgboost import XGBClassifier
# 随机森林
rf = RandomForestClassifier(n_estimators=100, random_state=42)
rf.fit(X_df, y)
# 获取特征重要性
importances_rf = rf.feature_importances_
# 将特征名和重要性对应起来,并排序
feature_importance_df = pd.DataFrame({'feature': X_df.columns, 'importance': importances_rf})
feature_importance_df = feature_importance_df.sort_values('importance', ascending=False)
print("随机森林特征重要性:")
print(feature_importance_df)
# feature importance
# 9 feature_9 0.245956
# 2 feature_2 0.167019
# 5 feature_5 0.118863
# 6 feature_6 0.098968
# 7 feature_7 0.092285
# 1 feature_1 0.083474
# 4 feature_4 0.062016
# 0 feature_0 0.049380
# 3 feature_3 0.046692
# 8 feature_8 0.035349
# 可视化
plt.figure(figsize=(10, 6))
plt.barh(feature_importance_df['feature'], feature_importance_df['importance'])
plt.xlabel('Feature Importance')
plt.title('Random Forest Feature Importance')
plt.gca().invert_yaxis() # 最重要的在顶部
plt.show()
# 根据重要性阈值选择特征 (例如,选择重要性大于平均值的特征)
threshold = importances_rf.mean()
selected_mask = importances_rf > threshold
selected_features_rf = X_df.columns[selected_mask]
print(f"
基于重要性的特征选择: {list(selected_features_rf)}")
# ['feature_2', 'feature_5', 'feature_9']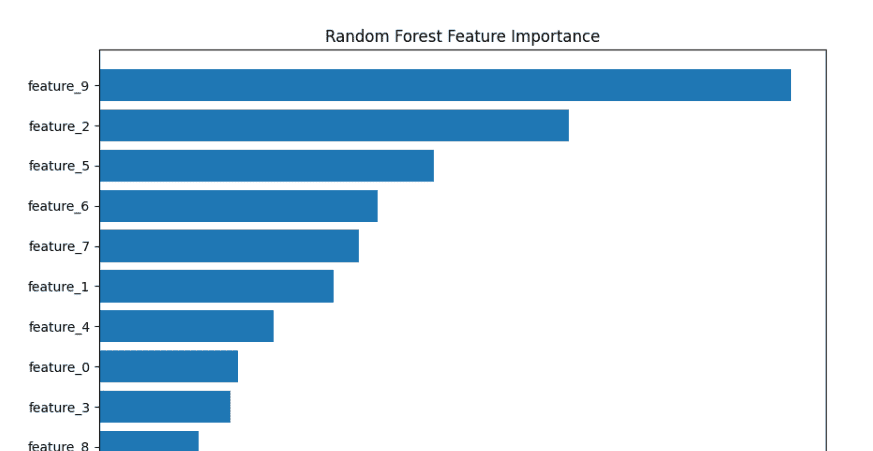
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...