1.为什么会关注到这个 Unicode 主题
起初是想深入了解下浏览器中的 Base64 编码,于是触及到了码点(Code Point)、码元(Code Unit)、不同码元字节占用的相关概念。
现代浏览器都提供了btoa() 和 atob()这两个方法用于 Base64编解码,但是其仅适用于包含 ASCII 字符或可以用单个字节表明的字符而非所有 Unicode。
为了安全的使用这两个方法,开发者可以通过 TextEncoder 获取 UTF-16 编码的 JavaScript 字符串,并使用TextEncoder.encode() 将其转换为 UTF-8 编码的字节流 ,而 UTF-8 向后兼容 ASCII 且可以表明任何标准 Unicode 字符。同时,在 UTF-8 编码下每个码元占据 1 个字节。
换句话说,经过 TextEncoder.encode() 进行 UTF-8 编码后会返回 Uint8Array 类型数组,数组中每个元素的值都在 0~255 之间,可以通过单字节表明,符合 btoa() 和 atob() 的使用条件。
// From https://developer.mozilla.org/en-US/docs/Glossary/Base64#the_unicode_problem.
function base64ToBytes(base64) {
const binString = atob(base64);
return Uint8Array.from(binString, (m) => m.codePointAt(0));
}
// From https://developer.mozilla.org/en-US/docs/Glossary/Base64#the_unicode_problem.
function bytesToBase64(bytes) {
const binString = String.fromCodePoint(...bytes);
return btoa(binString);
}
// Sample string that represents a combination of small, medium, and large code points.
// This sample string is valid UTF-16.
// 'hello' has code points that are each below 128.
// '⛳' is a single 16-bit code units.
// '❤️' is a two 16-bit code units, U+2764 and U+FE0F (a heart and a variant).
// '' is a 32-bit code point (U+1F9C0), which can also be represented as the surrogate pair of two 16-bit code units 'ud83euddc0'.
const validUTF16String = 'hello⛳❤️';
// This will work. It will print:
// Encoded string: [aGVsbG/im7PinaTvuI/wn6eA]
const validUTF16StringEncoded = bytesToBase64(new TextEncoder().encode(validUTF16String));
console.log(`Encoded string: [${validUTF16StringEncoded}]`);
// This will work. It will print:
// Decoded string: [hello⛳❤️]
const validUTF16StringDecoded = new TextDecoder().decode(base64ToBytes(validUTF16StringEncoded));
console.log(`Decoded string: [${validUTF16StringDecoded}]`);而至于解码操作,只需要将编码后的字符串[aGVsbG/im7PinaTvuI/wn6eA]先调用 atob() 进行 Base64 解码,然后转化为 Uint8Array 类型数组。接着通过调用 TextDecoder().decode() 将给定的类型数组解码为 JavaScript 中 UTF-16 的字符串并返回。
总之,其核心做法是将 UTF-8 下每个字节对应的码元进行单独 btoa() 编码和 atob() 解码。
2. Unicode 只是定义字符集
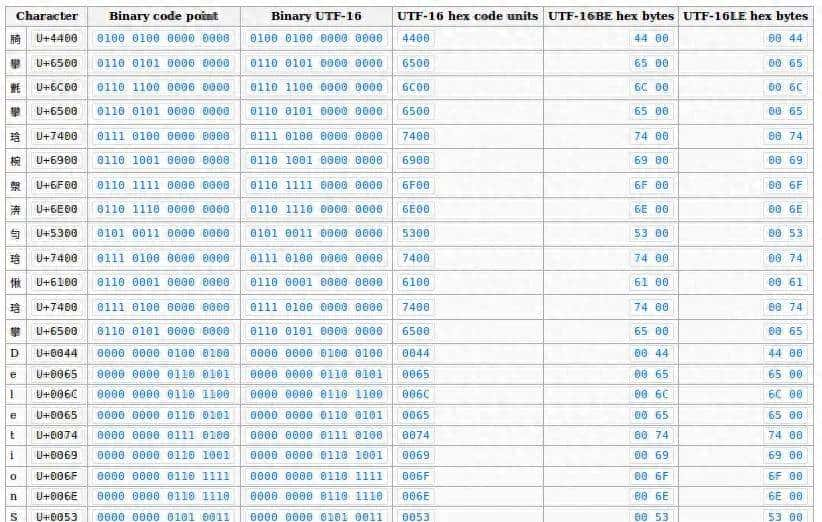
Unicode 不是一种编码方式,而是一个字符集标准(character set)。其为每个字符分配一个唯一的数字,称为 码点(Code Point),格式如 U+0041(代表 'A')。下表展示了部分中文的文字码点数据:
由于 Unicode 本身只定义码点,但要在计算机中存储或传输,需用采用具体编码,典型的编码方式包括:
- UTF-8:最常用于 Web、Linux、JSON 等,兼容 ASCII,变长(1–4 字节)
- UTF-16:JavaScript 内部使用,但对非 BMP(Basic Multilingual Plane) 字符需使用代理对,这一点下文会说到。
- UTF-32:定长,每个字符 4 字节,较少用
只要使用 UTF-8/UTF-16/UTF-32 编码,就能表明 Unicode 支持的所有字符。 但是值得注意的是,JavaScript 引擎会将字符串表明为 UTF-16 ,从而会破坏像 btoa() 这类函数,此类函数实际上是基于每个字符都映射到单个字节的假设来运行的。
一句话,Unicode 只是定义了字符集,而下面说的编码方式则决定到底用几个码元、几个字节表明该字符。
3.UTF-8 vs. UTF-16 用于对 Unicode 字符集编码
UTF-8 和 UTF-16 是 Unicode 标准的两种不同编码方式(encoding forms),它们同时存在的缘由主要与历史兼容性、存储效率、处理性能和平台习惯等因素有关。下面从几个关键角度解释为什么会有这两种编码方式。
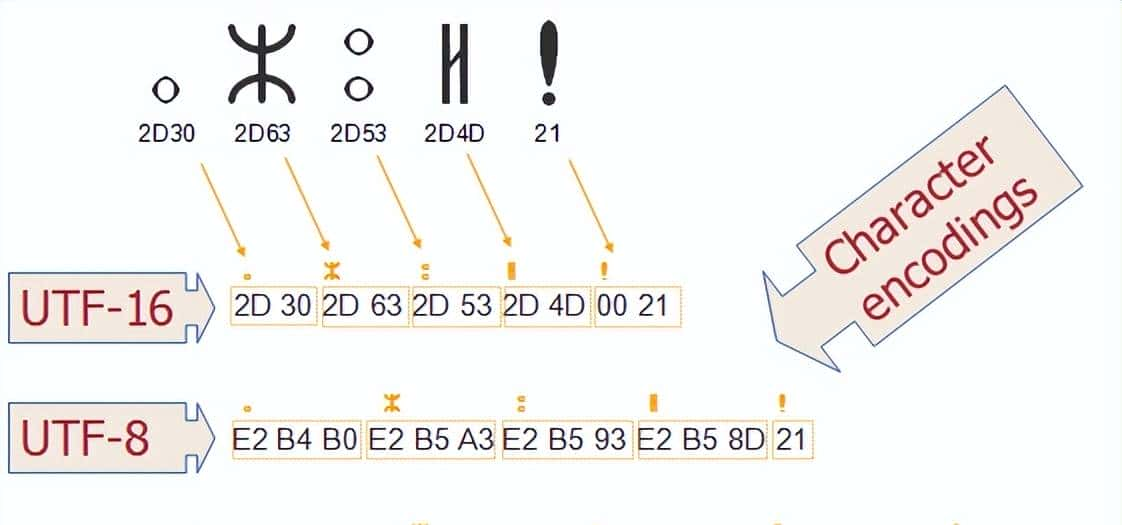
3.1 历史兼容性:UTF-8 兼容 ASCII
UTF-8 的最大优势是向后兼容 ASCII,所有 ASCII 字符(U+0000 到 U+007F)在 UTF-8 中都用单字节表明,且编码与 ASCII 完全一样。这意味着:
- 旧的 ASCII 文本无需转换即可被 UTF-8 解析
- 网络协议、文件系统、编程语言(如 C 的字符串)可以平滑过渡到 Unicode
- 在以英文为主的场景下,UTF-8 超级节省空间
3.2 存储效率:不同语言文本的字节开销不同
针对不同语言,UTF-8 和 UTF-16 都占据不同的字节数,例如:
- UTF-8:
- 拉丁字母(如英文):1 字节;
- 常见汉字(如中文、日文):3 字节;
- 少数生僻字符(如 emoji):4 字节
- UTF-16:
- 基本多文种平面(BMP,U+0000–U+FFFF)中的字符(包括绝大多数常用汉字):2 字节/字符
- 辅助平面字符(如部分 emoji、古文字):4 字节/字符(使用代理对)
总之,关于不同编码的体积占用可以总结为以下几点:
- 英文为主: UTF-8 更省空间
- 中文/日文为主 : UTF-16 可能更紧凑(2 字节 vs 3 字节)
3.3 处理性能与内存占用不同
除了兼容性、存储效率外,不同编码的性能和内存占用也有较大的区别:
- UTF-16 在某些系统(如 Windows、Java、JavaScript 引擎)中被广泛采用
- 固定 2 字节(对 BMP 字符)便于随机访问(如 str[100] 可快速定位)
- 早期 Unicode 设计时以为 65536 个码位足够,所以用 16 位表明
- 虽然后来扩展到 21 位(需要代理对),但系统已深度依赖 UTF-16
- UTF-8 是变长编码(1–4 字节),随机访问需从头扫描,但是也有优点
- 对流式处理(如网络传输、文件读取)更友善
- 无字节序(endianness)问题,而 UTF-16 需要 BOM 或约定字节序
3.4 平台与标准偏好
不同编码方式的选择有时候也依赖于平台类型,典型的例如:
- Web 和 Unix/Linux:几乎全部使用 UTF-8(HTML5 默认、Linux 文件系统、Git 等)
- Windows API / Java / JavaScript:内部使用 UTF-16, JavaScript 的 String 基于 UTF-16 单元
- 数据库/文件格式:可能根据场景选择(如 SQLite 支持 UTF-8,而某些旧系统用 UTF-16)
总之,不管最终选择 UTF-8 还是 UTF-16 ,两者之间都支持无损转换。不过,对于基本多文种平面(BMP, U+0000–U+FFFF)以外的字符(即 U+10000 到 U+10FFFF),UTF-16 需要使用代理对来编码。
4.码点 vs. 码元 vs.字节
4.1 码点 vs. 码元 vs.字节之间的关系
4.1.1 认识码点和码元
如前文所述,码点是 Unicode 标准中用来唯一标识一个字符的抽象数字编号,其是字符在 Unicode 字符聚焦的“身份证号”,与具体如何存储或传输无关。
码元是特定字符编码方案中用于表明文本的最小单位,不同编码下码元大小不同,例如:UTF-8 下是8位,而 UTF-16 下是 16位,而 UTF-32 下是 32位。
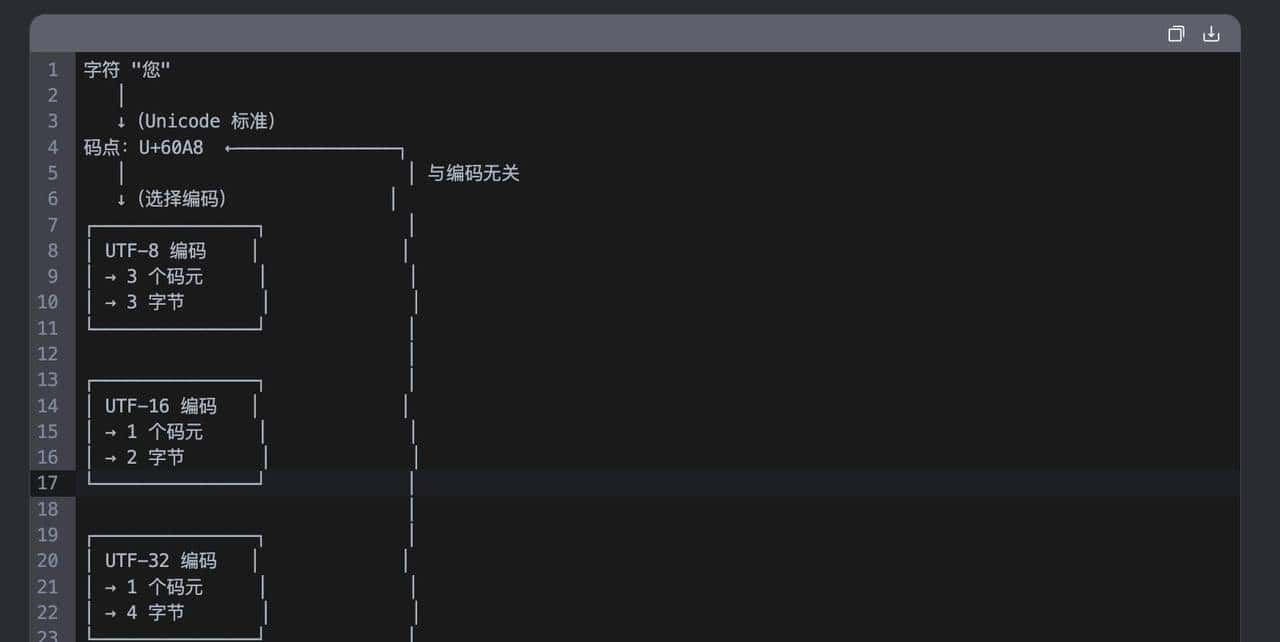
所以每个常用汉字 → 1 个码点(Code Point)→ 3 个 UTF-8 码元 → 3 个字节。
[228, 189, 160, 229, 165, 189]
↑_____________ ↑_____________
“你” “好”因此最终“你”转化为了 E4 BD A0,而“好”转化为了E5 A5 BD,最终每个字节分别对应于一个码元。
需要注意的是,在 UTF-16 编码中,一个码元一般固定为 2 字节。BMP 中的码点用一个码元表明,但是辅助平面中的码点需要用两个码元(即一个代理对)表明,此时一个生僻汉字一般会占用4个字节。
4.1.2 有些Unicode字符可能使用多个码点表明
以字符 “” 为例,其并非一个单一的 Unicode 码点,而是由多个码点组成的 ZWJ 序列(Zero Width Joiner Sequence)。具体来说,其由 (U+1F468)、零宽连接符(U+200D, ZWJ)和 (U+1F466)依次拼接而成。
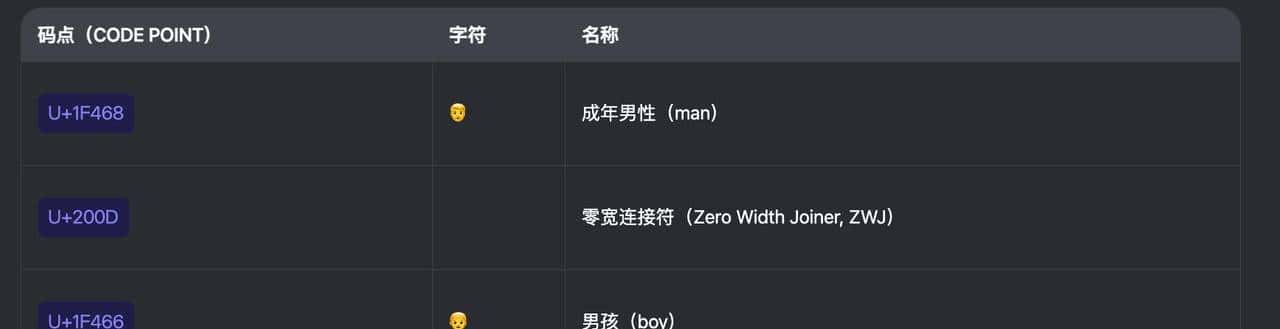
Unicode 之所以采用这种组合机制,而非为每一种家庭组合(如 )分配独立的码点,是为了避免字符集的爆炸式增长,这种设计被称为 Emoji ZWJ Sequence。当渲染引擎识别到这类序列时,会将其合成并显示为一个连贯的复合 emoji,例如 。
所以,“” = U+1F468 U+200D U+1F466。
4.2 什么是字形簇(Grapheme clusters)
字形簇(Grapheme clusters)是 Unicode 标准中用于表明“用户感知的一个字符”的基本单位,其解决了一个关键问题:在屏幕上看起来像“一个字符”的东西,在底层可能由多个 Unicode 码点组成。
即 Unicode 中的“字符”并不总是一对一对应用户眼中的“字符”。例如:
- 带重音符号的字母:é 可以是一个预组合字符(U+00E9),也可以是 e(U+0065) + 组合重音符号(U+0301)
- 表情符号序列:(“女程序员”)由 (U+1F469) + 零宽连接符(U+200D) + (U+1F4BB)组成
- 带旗帜的地区:某些国旗使用“区域指示符”对,如 = U+1F1FA + U+1F1F8。
在这些例子中,虽然底层是多个码点,但用户认为它们是“一个字符”。Grapheme cluster 就是用来界定这种“用户感知字符”边界的规则。
4.3 为什么 UTF-16 存储需要代理对
4.3.1 存储代理对是什么
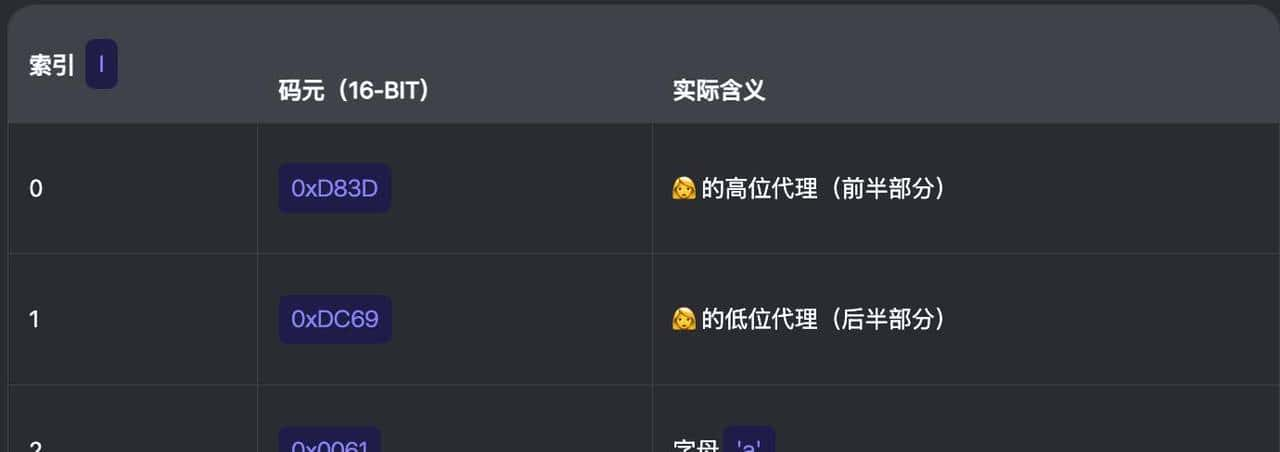
在 JS 中,字符串内部使用 UTF-16 表明,其中:
- 基本多文种平面(BMP) 的字符(U+0000 ~ U+FFFF)用 1 个 16 位码元(code unit) 表明
- 超出 BMP 的字符(如 emoji 、U+1F469)需用 2 个 16 位码元 表明,称为代理对(surrogate pair),占用4个字节
- 高位代理(leading surrogate):范围 0xD800–0xDBFF
- 低位代理(trailing surrogate):范围 0xDC00–0xDFFF
"".length;// 2(由于 = U+1F469,需要代理对)
"".charCodeAt(0);// 0xD83D(高位代理)
"".charCodeAt(1);// 0xDC69(低位代理)为避免歧义,代理对的两个组成部分必须介于 0xD800 和 0xDFFF 之间,并且这些码元也不用于编码单码元字符。更准确地说,高位代理的值介于 0xD800 和 0xDBFF 之间(含),而低位代理的值介于 0xDC00 和 0xDFFF 之间(含)。
4.3.2 单独代理的蛀虫
单独代理(lone surrogate)是指满足以下描述之一的 16 位码元:
- 位于 0xD800–0xDBFF 范围内(含该范围,即高位代理),但其是字符串中的最后一个代码单元,或者下一个代码单元不是低位代理
- 位于 0xDC00–0xDFFF 范围内(含该范围,即低位代理),但其是字符串中的第一个码元或者前一个码元不是高位代理
单独代理不代表任何 Unicode 字符,可以简单理解为:一个本应成对出现的代理码元(高位或低位),在字符串中却“孤身一人”,无法还原为有效 Unicode 字符。它们是UTF-16 编码错误或数据损坏的标志,在健壮的程序中应被检测、拒绝或替换。
虽然大多数 JavaScript 内置方法都能正确处理它们,由于其都基于 UTF-16 码元工作,但在与其他系统交互时,单独代理一般不是有效值。例如, encodeURI() 会针对单独代理抛出 URIError,由于 URI 编码使用的是 UTF-8 编码,而 UTF-8 编码不支持单独代理的编码。
const illFormed = "https://example.com/search?q=uD800";
try {
encodeURI(illFormed);
} catch (e) {
console.log(e); // URIError: URI malformed
}
if (illFormed.isWellFormed()) {
console.log(encodeURI(illFormed));
} else {
console.warn("Ill-formed strings encountered."); // Ill-formed strings encountered.
}不包含任何单独代理的字符串被称为格式良好的字符串,可以安全地用于不处理 UTF-16 的函数,例如 :encodeURI() 或 TextEncoder。开发者可以使用 isWellFormed() 方法检查字符串是否格式良好,或者使用 toWellFormed() 方法对单独代理进行清理。
开发者必须谨慎对待当前迭代的字符串,例如:split(“”) 将按 UTF-16 码元拆分并分离代理对,且字符串索引也引用每个 UTF-16 码元的索引。但是,[Symbol.iterator]() 支持按 Unicode 码点进行迭代。
console.log("".length) // 2
"".split(""); // ['ud83d', 'ude04'];
// split 会分割为两个单独代理,所以要慎重
// "Backhand Index Pointing Right: Dark Skin Tone"
console.log("".length) // 4
[...""]; // ['', '']
// 拆分为基本的“反手食指指向右”表情符号和“深色肤色”表情符号
// "Family: Man, Boy"
console.log("".length) // 5
[...""]; // [ '', '', '' ]
// 拆分成“男人”和“男孩”表情符号,由 ZWJ 连接
// The United Nations flag
console.log(''.length) // 4
[...""]; // [ '', '' ]
// 拆分为两个“区域指示”字母“U”和“N”,所有旗帜表情符号均由两个区域指示字母连接而成接下来看看为什么上面代码中的 “”.length 会返回 5 呢?
const s = "";
// 使用 for...of 按码点迭代,输出:1F468、200D、1F466
// 由于索引基于 UTF-16 码元(.length === 5)
console.log([...s])
// ['', '', '']
for (const char of s) {
console.log(char.codePointAt(0).toString(16).toUpperCase());
}这是由于:虽然”” 只有 3 个 Unicode 码点,但其中 2 个是非 BMP 字符(emoji),每个在 UTF-16 中需要用 2 个码元(代理对) 表明,而中间的 ZWJ 是 BMP 字符,只需 1 个码元,总共5个码元。
5. 聊聊 JavaScript 中处理码点码元的方法
5.1 String.length 获取的是字符串 UTF-16 码元的长度
JavaScript 使用 UTF-16 编码字符串,每个 Unicode 字符可能被编码为一个或两个码元(BMP 字符1个码元2个字节,而非BMP字符2个码元4个字节),因此 length 返回的值可能与字符串中实际的 Unicode 字符数不匹配。对于拉丁文、常见的 CJK 字符等不是问题。但如果使用的是某些特殊文字,例如:表情符号、数学符号或不常用的中文,则可能需要思考码元和字符间的差异。
const str = ''
console.log(''.length) // 2码元,4字节语言规范要求字符串的最大长度为 2^53 -1 个元素,这是准确整数的上限。但是,具有此长度的字符串需要 16384TiB 的存储空间,这在任何合理的设备内存中都无法容纳,因此实现往往会降低阈值以便将字符串的长度方便地存储在 32 位整数中。
- 在 V8 中,最大长度为 2^29 – 24(~1GiB)。在 32 位系统上,最大长度为 2^28 – 16(~512MiB)
- 在 Firefox 中,最大长度为 2^30 – 2(~2GiB),而在 65 之前的版本中为 2^28 – 1(~512MiB)
- 在 Safari 中,最大长度为 2^31 – 1(~4GiB)
如果使用其他编码(例如: UTF-8 文件或 Blob)处理大型字符串时需要特别注意,将数据加载到 JS 字符串时,编码始终为 UTF-16,此时字符串的大小可能与源文件的大小不同。
上面说过, .length 计算的是码元而非字符数。而如果要获取字符数,可以先用迭代器拆分字符串,由于迭代器会按字符进行迭代:
function getCharacterLength(str) {
// The string iterator that is used here iterates over characters,
// not mere code units
return [...str].length;
}
console.log(getCharacterLength("AuD87EuDC04Z")); // 3
console.log("AuD87EuDC04Z".length) // 4更进一步,如果开发者要按字形簇(grapheme clusters)计数字符则可以使用 Intl.Segmenter,即先把要拆分的字符串传递给 segment() 方法,然后遍历返回的 Segments 对象以获取长度:
function getGraphemeCount(str) {
const segmenter = new Intl.Segmenter("en-US", { granularity: "grapheme" });
// The Segments object iterator that is used here iterates over characters in grapheme clusters,
// which may consist of multiple Unicode characters
return [...segmenter.segment(str)].length;
}
console.log(getGraphemeCount("")); // 1
console.log(getGraphemeCount("")); // 15.2 利用 codePointAt() 获取码点
codePointAt()方法是获取码点而非码元
字符串的 codePointAt() 方法返回一个非负整数,该整数表明从给定索引处开始的字符的 Unicode 码点,Unicode 码点的范围是 0 ~ 1114111 (0x10FFFF)。但是需要特别注意的是:索引是基于 UTF-16 码元而非 Unicode 码点,由于有些码点包含多个码元,所以通过下标访问可能不太准确。
''.length // 2
''.codePointAt(0).toString(16) // "1f680"
''.codePointAt(1).toString(16) // de80
// 字符存在代理位,codePointAt 第一次获取完整的码点,第二次获取的是低代理位的无效码点(后续for循环中也会论述)
''.charCodeAt(0).toString(16) // "d83d" → 高代理
''.charCodeAt(1).toString(16) // "de80" → 低代理在 UTF-16 中,每个字符串索引都是一个码元,其值为 0~65535。更高的码点由一对 16 位代理伪字符(surrogate pseudo-characters)表明,此时 codePointAt() 返回的码点可能跨越两个字符串索引(下标访问异常的缘由),即占用 2 个 UTF-16 码点,总共4个字节。
"ABC".codePointAt(0); // 65
"ABC".codePointAt(0).toString(16); // 41
"".length; // 2
"".codePointAt(0); // 128525
"".codePointAt(1); // 56845
"".codePointAt(2); // undefined
"ud83dude0d".length // 2
"ud83dude0d".codePointAt(0); // 128525
"ud83dude0d".codePointAt(1); // 56845
"ud83dude0d".codePointAt(2); // undefined
"ud83dude0d".codePointAt(0).toString(16); // 1f60d需要注意的是,使用字符串索引进行循环会导致一样的码点被访问两次,一次是高位代理(leading surrogate),一次是低位代理(trailing surrogate)。并且第二次 codePointAt() 仅返回低位无效代理,所以最好避免通过索引循环。
codePointAt() 由于单码点跨域两个码元索引导致for循环异常
如果有下面的代码示例,通过 for 循环读取字符串中每一个码点。
const str = "a";
for (let i = 0; i < str.length; i++) {
console.log(str.codePointAt(i));
}第一看字符串 “a” 的结构,其包含一个 emoji,Unicode 码点是 U+1F469(十进制 128105)。其超出了基本多文种平面(BMP),所以在 JavaScript 的 UTF-16 编码中,需要用两个 16 位码元(code units) 表明,即一个代理对(surrogate pair)。其中高位代理(leading surrogate)为0xD83D,而低位代理(trailing surrogate)为 0xDC69。而”a” 只是普通 ASCII 字符,码点 U+0061,只需一个码元。
所以,整个字符串在内存中的码元序列是:
此时,下面代码输出为3:
const str = "a";
console.log(str.length===3) // 注意!不是 2!接下来利用下标遍历进入 for 循环,调用 str.codePointAt(i):
第一次:i = 0,执行 str.codePointAt(0)。此时从索引 0 开始,看到 0xD83D高位代理
- JavaScript 检查下一个码元是不是低位代理?发现是的,索引 1 是 0xDC69 低位代理,所以其正确组合成一个完整的码点,即 128105(即 U+1F469,)
第二次:i = 1,调用 str.codePointAt(1)。此时从索引 1 开始,当前码元是 0xDC69低位代理
- JavaScript 检查是否是高位代理,发现不是,而是低位代理。根据规范,如果起始位置不是一个高位代理,codePointAt() 就直接返回该位置的码元值作为 16 位整数,所以返回:0xDC69 → 十进制是 56425
此时问题来了:这个 56425不是一个合法的 Unicode 码点,其只是 UTF-16 编码中的低位代理,不能单独存在。此时误以为其是另一个字符,实际上它只是 的后半截,而此时的数字56425是毫无意义的。
同理,即使不是for循环,通过多次调用 codePointAt() 也会存在该问题:
const str = '';
console.log(str.length) // 2
console.log(str.codePointAt(0).toString(16));
// "1f680" → 字符 '' 的完整 Unicode 码点(U+1F680)
console.log(str.codePointAt(1).toString(16));
// "de80" → 索引 1 处的 UTF-16 码元值(即低位代理本身)
console.log(str.charCodeAt(0).toString(16));
// "d83d" → 高位代理(leading surrogate)
console.log(str.charCodeAt(1).toString(16));
// "de80" → 低位代理(trailing surrogate)为了解决这个问题,开发者可以 for…of 语句或 spread 展开字符串,这两种方法都会调用字符串的 [Symbol.iterator](),其会按码点进行迭代。然后,使用 codePointAt(0) 方法获取每个元素的码点。
const str = "a";
for (const codePoint of str) {
console.log(codePoint.codePointAt(0).toString(16));
}
[...str].map((cp) => cp.codePointAt(0).toString(16));
// ['1f469', '61']5.3 通过 charCodeAt() 获取码元
charCodeAt() 方法返回一个介于 0 ~ 65535 的整数,表明给定索引处的 UTF-16 码元。
由于 charCodeAt() 始终将字符串索引为 UTF-16 码元序列,因此其可能返回单独的代理项。而要获取给定索引处的完整 Unicode 码点,可以使用
String.prototype.codePointAt()。
同时,由于 Unicode 码点的范围是 0~1114111 (0x10FFFF),因此 charCodeAt() 始终返回小于 65536 的值,且较高的码点会由一对 16 位代理伪字符表明。因此,为了获取值大于 65535 的完整字符,不仅需要检索 charCodeAt(i),还需要检索 charCodeAt(i + 1),就像操作包含两个字符的字符串一样或者改用 codePointAt(i)。
const str = "";
console.log(str.charCodeAt(0)); // 55362, or d842, which is not a valid Unicode character
console.log(str.charCodeAt(1)); // 57271, or dfb7, which is not a valid Unicode character6.UTF-8 和 UTF-16 如何转化
6.1 将 UTF-8 字节序列还原为 UTF-16 字符串
如前文所言,UTF-8 和 UTF-16 都是 Unicode 的编码方式(encoding forms),只是用不同的字节序列来表明同一个 Unicode 码点。即,所有合法的 Unicode 字符(U+0000 到 U+10FFFF)都可以用 UTF-8 和 UTF-16 正确表明(尽管方式不同)。
因此,只要知道一段字节是 UTF-8 还是 UTF-16 编码的,就可以:
- 解码为统一的 Unicode 码点序列(如 U+4F60 U+597D)
- 再用另一种编码方式重新编码为对应的字节序列
这个过程是标准的、可逆的、无信息丢失的。假设原始文本是中文 “你好”:
- UTF-8 编码:
- “你” → 0xE4 0xBD 0xA0
- “好” → 0xE5 0xA5 0xBD
- 完整字节:E4 BD A0 E5 A5 BD
- UTF-16LE 编码(小端,无 BOM):
- “你” → U+4F60 → 60 4F
- “好” → U+597D → 7D 59
- 完整字节:60 4F 7D 59
转换步骤如下:
- 第一步:将 UTF-8 字节E4 BD A0 E5 A5 BD解码并得到 Unicode 码点序列[U+4F60, U+597D]
// UTF-8 字节(十六进制): E4 BD A0 E5 A5 BD
const bytes = new Uint8Array([0xE4, 0xBD, 0xA0, 0xE5, 0xA5, 0xBD]);
// 使用 TextDecoder 解码为字符串,传入 Uint8Array
const decoder = new TextDecoder('utf-8');
const str = decoder.decode(bytes);
console.log(str);
// 输出: "你好"6.2 将 UTF-16 字符串转化为 UTF-16 码点序列
有了 UTF-16 字符串,开发者接下来可以调用 codePointAt() 继续获取 UTF-16 的码点序列,由于 JavaScript 字符串本身就是以 UTF-16 编码存储的。
const str = "你好"
const codePoints = Array.from(str).map(char => char.codePointAt(0));
console.log(codePoints.map(cp => 'U+' + cp.toString(16).toUpperCase().padStart(4, '0')));
// 输出 UTF-16 码点序列: ["U+4F60", "U+597D"]在最终得到Unicode 码点序列为 [U+4F60, U+597D] 。
6.3 将 UTF-16 字符串转化为 UTF-16 码点
有了 UTF-16 码点序列,开发者甚至可以从码点序列获取 UTF-16 存储的码元信息,例如:
function codePointsToUtf16CodeUnits(codePoints) {
const str = String.fromCodePoint(...codePoints);
const codeUnits = [];
// 上面说过,.length 获取的是码元长度
// .charCodeAt() 获取的就是指定下标的码元
for (let i = 0; i < str.length; i++) {
codeUnits.push(str.charCodeAt(i));
}
return codeUnits;
}
const codePoints = [0x4F60, 0x597D];
const utf16CodeUnits = codePointsToUtf16CodeUnits(codePoints);
console.log(utf16CodeUnits);
// 输出: [20320, 22909]
console.log(utf16CodeUnits.map(cu => '0x' + cu.toString(16).toUpperCase()));
// 输出: ["0x4F60", "0x597D"]由于“你”和“好”都属于基本多文种平面(BMP), [U+4F60, U+597D] 两个码元拆开得到 60 4F 7D 59,总共4个字节。
6.4 将 UTF-16 字符串转化为 UTF-8 码点
接下来再看看如何将 UTF-16 转化为 UTF-8。
实则在 JavaScript 中,将 UTF-16 编码的字符串(即 JS 原生字符串)转换为 UTF-8 字节序列,最标准、可靠的方式是使用 TextEncoder 。
const str = "你好"; // 对应码点 U+4F60, U+597D
const encoder = new TextEncoder(); // 默认就是 'utf-8'
const utf8Bytes = encoder.encode(str);
console.log(utf8Bytes);
// 输出: Uint8Array [228, 189, 160, 229, 165, 189]
// 转为十六进制便于查看
console.log([...utf8Bytes].map(b => b.toString(16).padStart(2, '0')).join(' '));
// 输出: e4 bd a0 e5 a5 bd由于 UTF-8 中一个码元用一个字节表明,所以从 e4 bd a0 e5 a5 bd可以看出一个中文占用三个字节。
7.Unicode编码与类型数组TypedArray关系
7.1 什么是 ArrayBuffer
ArrayBuffer 对象用于表明通用的原始二进制数据缓冲区,其是一个字节数组。
开发者无法直接操作 ArrayBuffer 的内容,相反需要创建一个类型化的数组对象(TypedArray)或 DataView 对象,两者都以特定格式表明缓冲区并支持读取和写入缓冲区内容。
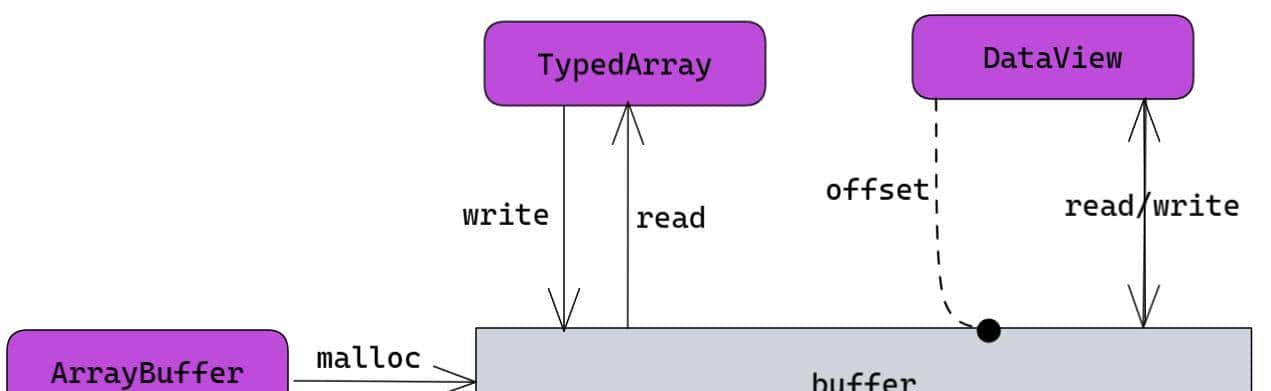
ArrayBuffer() 构造函数会创建一个 ArrayBuffer 对象,其长度以字节为单位,开发者也可以从现有数据,例如: Base64 字符串或本地文件获取数组缓冲区。下面是使用 Base64 字符串构造 ArrayBuffer 的示例:
function base64ToArrayBuffer(base64) {
// 移除可能的 data URL 前缀(如 "data:...;base64,")
const raw = base64.replace(/^data:.*?;base64,/, '');
const bin = atob(raw); // 解码 Base64 为二进制字符串
const len = bin.length;
const bytes = new Uint8Array(len);
for (let i = 0; i < len; i++) {
bytes[i] = bin.charCodeAt(i);
}
return bytes.buffer; // 返回类型数组引用的 ArrayBuffer
}
// 示例:一个表明 "Hello" 的 Base64 字符串
const base64Str = "SGVsbG8="; // "Hello" 的 Base64
const buffer = base64ToArrayBuffer(base64Str);
console.log(buffer); // ArrayBuffer { byteLength: 5 }
// 验证内容
const text = new TextDecoder().decode(new Uint8Array(buffer));
console.log(text); // "Hello"如果要从本地文件创建 ArrayBuffer 也超级简单,例如:
<input type="file" id="fileInput" />
<script>
document.getElementById('fileInput').addEventListener('change', async (event) => {
const file = event.target.files[0];
if (!file) return;
// 方法 1:使用 FileReader
const reader = new FileReader();
reader.onload = () => {
const buffer = reader.result; // 这就是 ArrayBuffer
console.log('File size:', buffer.byteLength, 'bytes');
console.log('ArrayBuffer:', buffer);
};
reader.readAsArrayBuffer(file);
// 方法 2(现代浏览器):使用 Blob.arrayBuffer()
// const buffer = await file.arrayBuffer();
// console.log('ArrayBuffer (via arrayBuffer):', buffer);
});
</script>7.2 什么是类型数组TypedArray
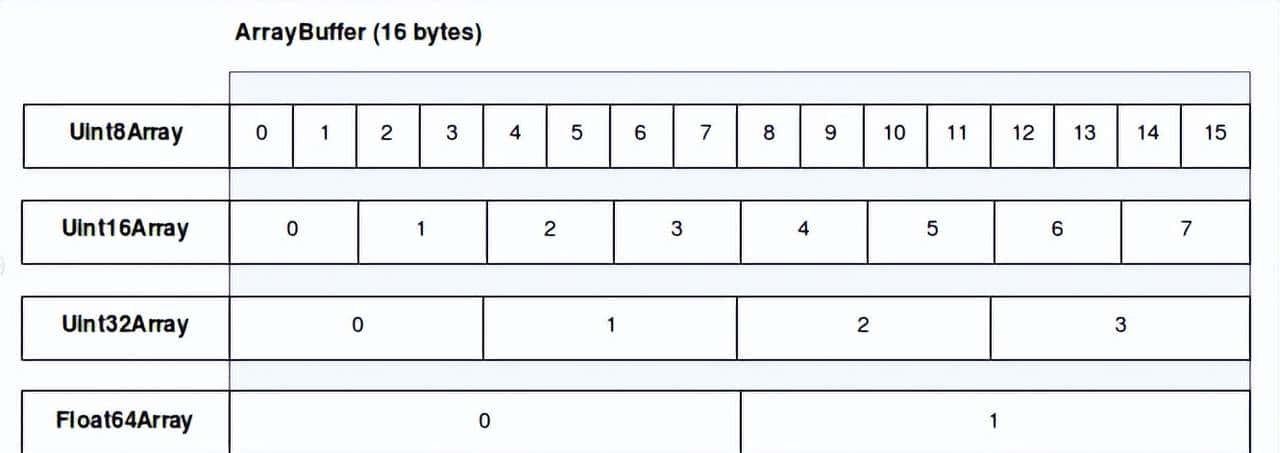
Uint8Array、Int16Array、Uint32Array 等是不同方式查看 ArrayBuffer 内存的“镜头”,类似于比例尺。
- Uint8Array:每次看 1 字节(8 位),值范围 0~255
- Int16Array:每次看 2 字节(16 位),解释为有符号整数(-32768~32767)
- Uint16Array:每次看 2 字节,解释为无符号整数(0~65535)
类型数组不关心内容含义,即不管是图片、音频、文本编码,还是传感器数据都可以用它们读写。
7.3 类型数组和 Unicode 的关系是什么
Unicode 编码和 TypedArray 本身没有直接的语义关系,但它们在实际应用中常协同工作。
- Unicode 是一套字符编码标准,定义了每个字符对应的码点(如 U+0041 表明 'A')
- TypedArray(如 Uint8Array、Uint16Array 等)是 JavaScript 中用于操作原始二进制数据的视图,其不关心数据的语义含义
两者关系:当开发者需要在 JavaScript 中以特定编码(如 UTF-8/UTF-16)将 Unicode 字符串序列化为字节或从字节反序列化为字符串时,一般会借助 TypedArray 存储和处理字节。
UTF-16 编码使用 Uint16Array类型数组
UTF-16 编码的 JavaScript 字符串内部使用 16 位码元,可通过 Uint16Array 操作
const str = "A";
// 'A' 是 U+0041,'' 是 U+1F600(需要代理对)
const uint16Arr = Uint16Array.from(
{ length: str.length },
(_, i) => str.charCodeAt(i)
);
console.log(uint16Arr);
// 输出: Uint16Array [65, 55357, 56832],其中 65 = 0x0041 → 'A' ,55357 = 0xD83D, 56832 = 0xDE00 → 代理对,表明 U+1F600 ()
// 2. 从 Uint16Array 重建字符串
const reconstructed2 = String.fromCharCode(...uint16Arr);
console.log(reconstructed2); // "A" ✅
console.log(reconstructed2 === str); // true需要注意:Uint16Array 表明的是 UTF-16 码元序列,因此必须用 String.fromCharCode 重建字符串。而 String.fromCodePoint 用于码点序列,与 Uint16Array 的语义不匹配。
那么为什么不能直接用 Uint16Array 来表明码点序列?主要是基于以下几个缘由:
Uint16Array 每个元素是 16 位无符号整数(0~65535),但 Unicode 码点范围是 0 到 0x10FFFF(1114111),超过 65535 的码点(如 = U+1F600 = 128512)无法用单个 Uint16Array 元素表明。
因此,码点序列一般用普通 Array(或 Uint32Array,如果环境支持)存储,而不是 Uint16Array。
const str = "A";
// 1. 获取码点序列(使用 Array,由于码点可能 > 65535)
const codePoints = Array.from(str, c => c.codePointAt(0));
// 或更严谨地处理代理对(但 Array.from(str) 已自动处理):
// const codePoints = [...str].map(c => c.codePointAt(0));
console.log(codePoints);
// 输出: [65, 128512] 其中 'A' → U+0041 = 65,而 '' → U+1F600 = 128512 (完整码点,不是代理对)
// 2. 用 fromCodePoint 重建字符串(接收码点)
const reconstructed = String.fromCodePoint(...codePoints);
console.log(reconstructed); // "A" ✅
console.log(reconstructed === str); // true最后,String.fromCharCode 能正确还原包含代理对的字符串,是由于其“原样”拼接传入的 16 位码元,而 JavaScript 字符串本身就是基于 UTF-16 编码的,其只要代理对的两个码元顺序正确,引擎会自动将其解释为一个完整的 Unicode 字符。
UTF-8 编码的字节序列用 Uint8Array表明
// 原始字符串(包含 ASCII、非 ASCII 和 emoji)
const str = "Hello, 世界! ";
// 1. 编码:字符串 → UTF-8 字节序列(Uint8Array)
const utf8Bytes = new TextEncoder().encode(str);
console.log(utf8Bytes);
// 输出示例: Uint8Array(19) [72, 101, 108, 108, 111, 44, 32, ...]
// 2. 解码:Uint8Array → 字符串
const decoder = new TextDecoder('utf-8');
const restored = decoder.decode(utf8Bytes);
console.log(restored === str); // true ✅
console.log(restored); // "Hello, 世界! "需要注意的是,类型数组本身只是一个原始字节容器,其不理解字符边界。但当使用 TextDecoder('utf-8') 对 Uint8Array 解码时,解码器会严格按照 UTF-8 的编码规则解析字节序列,自动识别:
- 单字节字符(ASCII):0xxxxxxx
- 双字节字符:110xxxxx 10xxxxxx
- 三字节字符:1110xxxx 10xxxxxx 10xxxxxx
- 四字节字符:11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
总之,只要字节序列完整且合法,无论一个字符占 1~4 字节,都能正确还原。
TypeArray 和 Unicode 的关系可以概括为:TypedArray 是实现 Unicode 编码/解码的底层工具之一,但本身并不理解 Unicode。两者属于不同抽象层次:Unicode 是语义层,TypedArray 是存储/操作层。
参考资料
https://unicode.org/reports/tr51/
https://developer.mozilla.org/en-US/docs/Web/API/TextDecoder/decode
https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/String/fromCodePoint
https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/String/length
https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/String/charCodeAt
https://dylanbeattie.net/2016/10/25/the-mystery-of-chinese-junk.html
https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/String#utf-16_characters_unicode_code_points_and_grapheme_clusters
https://www.toutiao.com/article/7524128572483568179/
https://www.cnblogs.com/feixianxing/p/18386857/javascript-array-buffer-data-view-typed-array
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...