
第一章 架构演进的必然:从单体到微服务的历史脉络
任何技术架构的诞生都不是偶然,而是 “业务需求” 与 “技术瓶颈” 碰撞后的必然结果。微服务架构并非凭空出现,而是经历了单体架构、面向服务架构(SOA)两个关键阶段的演进,最终成为解决复杂系统问题的主流方案。要理解微服务的价值,必须先回溯其历史脉络 —— 它是 “旧架构无法满足新需求” 时的必然选择。
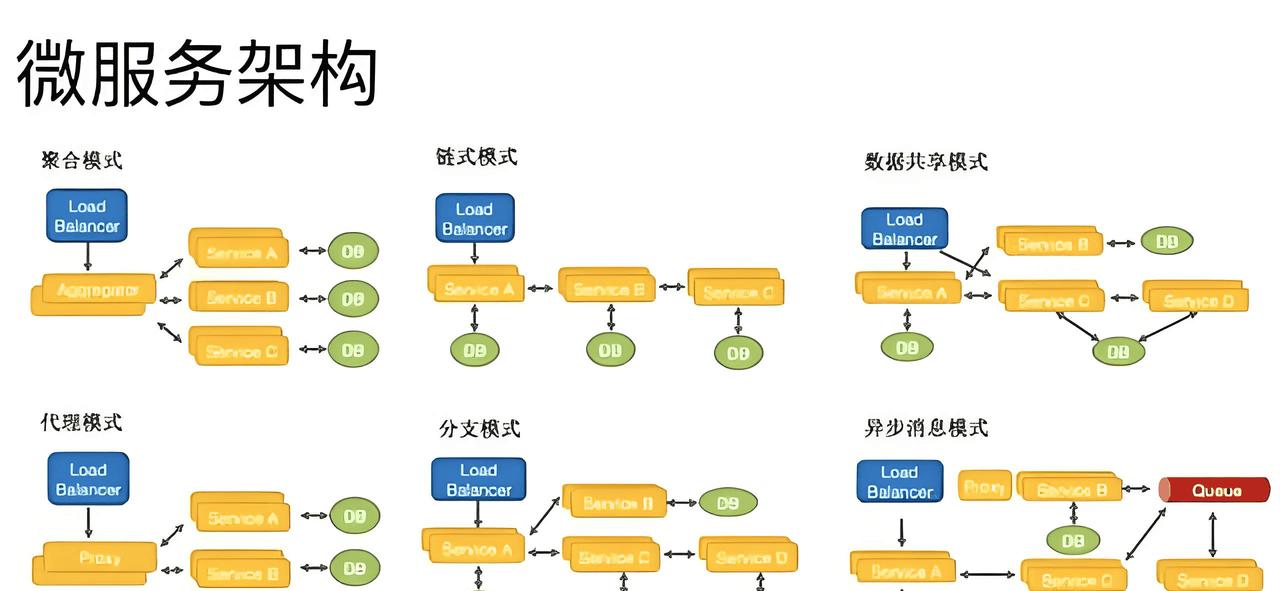
1.1 单体架构的辉煌与局限
在计算机技术发展的早期,单体架构(Monolithic Architecture)是绝对的主流。其核心特征是 “所有功能模块打包为一个部署单元”:前端页面、业务逻辑、数据访问层代码集中在一个项目中,编译后生成一个可执行文件(如 JAR 包、WAR 包),部署到一台或多台服务器上,通过负载均衡实现扩展。
1.1.1 单体架构的 “黄金时代”
单体架构的优势在项目初期极为明显,这也是它能长期主导的核心原因:
开发简单:无需考虑服务间通信、分布式协调等问题,团队只需专注于业务逻辑,技术栈统一(如 Java+Spring MVC+MySQL),新人上手成本低;
部署便捷:仅需将一个包上传到服务器,启动进程即可完成部署,无需复杂的运维工具链;
调试高效:一个请求的全链路(从前端到数据库)都在同一个进程内,通过日志或调试器可快速定位问题,无需跨服务追踪;
成本可控:初期无需投入大量资源搭建分布式基础设施(如服务注册、配置中心),适合小型团队或创业项目。
1.1.2 单体架构的 “瓶颈爆发”
当业务规模扩大、团队人数增加后,单体架构的局限性会逐渐暴露,且随着系统复杂度上升呈 “指数级恶化”:
部署耦合:任何一个微小的修改(如修复一个前端 bug、调整一行业务逻辑)都需要重新打包整个应用,部署全量服务 —— 这意味着 “牵一发而动全身”,部署风险极高,且无法做到 “按需部署”;
扩展僵化:单体应用只能作为一个整体扩展(如增加服务器节点),但实际业务中不同模块的负载差异极大(例如电商系统的 “商品详情页” QPS 是 “用户注册” 的 100 倍),整体扩展会导致资源浪费,无法实现 “精准扩缩容”;
技术栈锁定:整个应用只能使用一套技术栈(如 Java),若某模块需要更适合的技术(如用 Python 做数据分析、用 Go 做高性能网关),则无法引入 —— 技术栈的 “单一性” 会限制系统性能与开发效率;
团队协作低效:多个团队(如前端、订单、支付团队)共用一个代码仓库,代码冲突频繁,合并成本高;且一个团队的代码质量问题可能影响整个应用(如内存泄漏导致全服务崩溃),协作效率随团队规模扩大而急剧下降;
故障影响范围大:单体应用是一个 “单点故障源”—— 若其中一个模块(如支付模块)出现内存溢出,会导致整个应用进程崩溃,所有功能(商品浏览、订单创建、用户登录)全部不可用,系统韧性极差。
当系统达到 “百万级用户、千万级订单” 规模时,单体架构的瓶颈会彻底爆发,成为业务发展的 “绊脚石”—— 此时,架构升级已迫在眉睫。
1.2 面向服务架构(SOA)的过渡与瓶颈
为解决单体架构的耦合问题,2000 年后面向服务架构(Service-Oriented Architecture,SOA)应运而生。SOA 的核心理念是 “将系统拆分为多个独立的服务,通过标准化接口实现服务间通信”,本质是 “从单体的‘内聚’走向服务的‘拆分’”。
1.2.1 SOA 的核心设计与价值
SOA 的架构模型包含三个核心组件:
服务提供者(Service Provider):将业务功能封装为服务(如 “用户查询服务”“订单创建服务”),对外提供标准化接口(通常基于 SOAP 协议);
服务注册中心(Service Registry):存储服务的元数据(如服务地址、接口定义),供服务消费者查询;
服务消费者(Service Consumer):通过注册中心获取服务地址,调用服务提供者的接口;
企业服务总线(ESB):SOA 的 “核心枢纽”—— 所有服务间的通信都通过 ESB 转发,ESB 负责协议转换(如 HTTP 转 SOAP)、消息路由、数据格式转换等功能。
SOA 的出现解决了单体架构的部分痛点:
服务解耦:不同业务模块拆分为独立服务,可单独开发、部署、扩展,避免了 “全量部署” 的风险;
技术栈灵活:每个服务可选择适合自身的技术栈(如订单服务用 Java,报表服务用 Python),无需受限于统一技术栈;
团队协作优化:一个服务对应一个团队,代码仓库独立,协作冲突减少,责任边界更清晰。
1.2.2 SOA 的 “致命瓶颈”
SOA 虽然实现了 “服务拆分”,但并未解决 “分布式系统的复杂性”,其核心瓶颈集中在企业服务总线(ESB) 和 “服务粒度” 上:
ESB 的重量级问题:ESB 是 SOA 的 “单点依赖”—— 所有服务通信都经过 ESB,一旦 ESB 故障,整个系统的服务交互会全面中断;且 ESB 的功能复杂(协议转换、路由、监控),导致其体积庞大、性能低下,成为系统的 “性能瓶颈”;
服务粒度模糊:SOA 对 “服务拆分的粒度” 没有明确标准,实际落地中常出现 “服务过大”(如 “电商核心服务” 包含订单、支付、商品所有功能)或 “服务过小”(如 “用户姓名查询服务”“用户手机号查询服务” 拆分过细)的问题,最终仍未摆脱 “耦合” 或 “通信 overhead” 的困境;
去中心化缺失:SOA 的服务治理(如配置管理、监控)仍以 “中心化” 为主,例如所有服务的配置都存储在一个中心化配置库中,一旦配置库故障,服务无法正常启动;
敏捷性不足:SOA 的服务开发、部署仍需遵循复杂的流程(如 ESB 接口注册、审批),无法快速响应业务变化 —— 这与互联网时代 “快速迭代、试错” 的需求严重不符。
SOA 是 “从单体到微服务的过渡”,它验证了 “服务拆分” 的可行性,但并未解决分布式系统的核心痛点。当互联网业务进入 “高频迭代、高并发、高可用” 的新阶段时,微服务架构应运而生。
1.3 微服务架构的诞生:解决复杂系统的 “手术刀”
2011 年,“微服务(Microservices)” 一词首次在 “软件架构研讨会” 上被提出;2014 年,Martin Fowler(软件领域权威专家)与 James Lewis 发表《Microservices》一文,正式定义了微服务架构的核心理念 ——“将系统拆分为一组小型、自治、聚焦单一业务能力的服务,通过轻量级通信协议交互,实现独立开发、测试、部署与扩展”。
微服务的诞生,本质是为了解决 SOA 的 “重量级” 和 “中心化” 问题,同时满足互联网业务的三大核心需求:
敏捷迭代:业务需求变化快(如电商的 “618 大促”“双 11 活动”),需要快速开发、上线新功能,且支持 “局部修改、局部部署”;
高可用:系统需具备 “故障隔离” 能力 —— 某一个服务(如 “评价服务”)故障,不影响核心服务(如 “下单、支付服务”)的正常运行;
弹性扩展:不同服务的负载差异大(如 “商品搜索服务” QPS 是 “用户退款服务” 的 1000 倍),需要 “按需扩缩容”,避免资源浪费。
微服务并非 “SOA 的替代品”,而是 “SOA 的轻量化演进”—— 它继承了 “服务拆分” 的核心思想,同时通过 “去 ESB 化”“强自治”“细粒度拆分” 等设计,解决了 SOA 的瓶颈,成为互联网时代复杂系统架构的 “标配”。
第二章 微服务架构的核心定义与本质特征
要真正理解微服务,必须跳出 “‘小服务’就是微服务” 的误区 —— 微服务的核心不是 “规模小”,而是 “自治性” 与 “业务聚焦”。本节将从权威定义出发,拆解微服务的五大核心特征,揭示其 “去中心化、轻量级、强韧性” 的本质。
2.1 微服务的权威定义:不是 “小服务”,而是 “自治服务”
Martin Fowler 在《Microservices》一文中对微服务的定义如下:
“微服务架构是一种架构风格,它将应用程序构建为一系列小型、自治的服务,每个服务运行在自己的进程中,通过轻量级机制(通常是 HTTP API)通信,并且专注于完成单一业务能力。这些服务围绕业务领域构建,由独立的团队负责开发、测试、部署和维护,并且可以使用不同的技术栈。”
这一定义包含三个核心关键词,也是区分 “微服务” 与 “普通服务” 的关键:
自治(Autonomy):服务是 “端到端独立” 的 —— 从代码开发、测试、打包,到部署、运维、扩缩容,都无需依赖其他服务或团队,可独立完成;
单一业务能力(Single Business Capability):服务的拆分依据是 “业务”,而非 “技术”—— 例如 “订单服务” 聚焦 “订单创建、订单查询、订单取消” 等与 “订单” 相关的业务能力,而非 “数据库访问服务”“缓存服务” 等技术层面的拆分;
轻量级通信(Lightweight Communication):服务间通过简单、高效的协议交互(如 REST、gRPC),而非 SOA 中复杂的 ESB 与 SOAP 协议,减少通信 overhead。
简言之,微服务的本质是 “业务驱动的自治服务集合”—— 它的 “小” 是 “业务粒度小”,而非 “代码量小”;它的 “强” 是 “自治能力强”,而非 “功能复杂”。
2.2 微服务的五大核心特征:拆解与深度解读
微服务的特征并非孤立存在,而是相互关联、共同支撑 “敏捷、高可用、弹性扩展” 的目标。以下从五个维度深入解读,揭示每个特征的 “设计目的” 与 “实践要求”。
2.2.1 单一职责:聚焦 “一个业务能力”
“单一职责” 是微服务拆分的 “第一原则”,源于软件设计中的 “单一职责原则(SRP)”,但在微服务中被赋予了 “业务层面” 的含义 ——一个微服务只负责 “一个业务领域的核心能力”,不承担无关的业务逻辑。
例如,电商系统中的 “订单服务” 只负责:
订单创建(接收用户下单请求,生成订单号,关联商品、用户信息);
订单查询(根据用户 ID、订单号查询订单状态、详情);
订单操作(取消订单、修改订单地址、申请退款);
而 “商品库存扣减” 属于 “库存服务” 的职责,“用户支付” 属于 “支付服务” 的职责 ——“订单服务” 不会直接操作库存或支付,而是通过调用其他服务的接口实现。
单一职责的核心价值:
降低耦合:服务只依赖 “相关业务服务”,而非 “全量业务逻辑”,修改一个服务时不会影响无关业务;
简化维护:服务的业务边界清晰,开发者只需理解 “一个业务领域”,无需掌握整个系统;
便于扩展:单一职责的服务可根据自身负载独立扩展,无需考虑其他业务的资源需求。
实践误区规避:
避免 “技术驱动拆分”:例如将 “数据库访问层” 拆分为 “MySQL 服务”“MongoDB 服务”,这种拆分与业务无关,会导致服务间依赖复杂(如 “订单服务” 需调用 “MySQL 服务” 操作订单数据,同时调用 “MongoDB 服务” 操作订单日志);
避免 “过度拆分”:例如将 “订单服务” 拆分为 “订单创建服务”“订单查询服务”“订单取消服务”—— 拆分过细会导致服务数量激增,通信 overhead 增大,故障排查难度上升。
2.2.2 完全自治:从开发到运维的端到端独立
“完全自治” 是微服务的 “灵魂”,也是其区别于 SOA 的核心特征 ——一个微服务的全生命周期(开发、测试、部署、运维、扩缩容)都由独立团队负责,无需依赖其他团队或系统。
自治性体现在四个层面:
开发自治:团队拥有独立的代码仓库,可自主选择技术栈(如订单服务用 Java,搜索服务用 Go),无需与其他团队统一;
测试自治:团队自主设计测试用例(单元测试、接口测试、性能测试),搭建测试环境,无需依赖其他团队的测试资源;
部署自治:团队可自主决定部署时间、部署策略(如蓝绿部署、金丝雀发布),无需等待全系统的 “统一部署窗口”;
运维自治:团队负责服务的监控、告警、故障排查,例如 “订单服务” 的 QPS 突增,由订单团队负责扩容,无需依赖运维团队。
完全自治的核心价值:
提升迭代速度:团队无需等待其他团队的协作(如接口审批、部署排期),可快速响应业务需求,例如 “双 11” 前订单团队可独立完成 “订单预创建” 功能的开发与上线;
明确责任边界:“谁开发,谁负责”—— 服务出现故障时,无需跨团队推诿,可快速定位责任方,提升故障恢复效率;
鼓励技术创新:团队可根据业务需求选择更适合的技术栈(如用 Redis 做订单缓存,用 Kafka 做订单日志异步处理),而非受限于统一技术栈。
实践支撑条件:
团队模式匹配:需采用 “小而自治” 的团队结构(如 Amazon 的 “Two Pizza Team”—— 团队规模小到用两个披萨就能喂饱),避免 “一个团队负责多个服务” 或 “多个团队负责一个服务”;
工具链支持:需搭建自动化工具链(CI/CD 流水线、容器化部署、监控平台),让团队无需专业运维知识即可完成部署与运维。
2.2.3 去中心化:数据与治理的分布式思维
SOA 的核心问题之一是 “中心化依赖”(如 ESB、中心化配置库),而微服务通过 “去中心化” 解决这一痛点 ——微服务的 “数据” 与 “治理” 均采用分布式模式,避免单点依赖。
去中心化体现在两个核心层面:
去中心化数据管理:
去中心化数据的价值:
每个微服务拥有独立的数据库(或数据库实例),而非共享一个 “中心数据库”—— 例如 “订单服务” 使用 “order_db”,“用户服务” 使用 “user_db”,“商品服务” 使用 “product_db”;
服务间不直接访问对方的数据库,而是通过 API 调用获取数据 —— 例如 “订单服务” 需要用户信息时,调用 “用户服务” 的 “查询用户接口”,而非直接查询 “user_db”;
若需跨服务查询(如 “查询用户的所有订单”),则通过 “服务聚合” 实现(如由 “用户中心服务” 调用 “订单服务” 接口,聚合数据后返回)。
避免 “数据库耦合”:若多个服务共享数据库,一个服务的 SQL 优化失误(如慢查询)会影响所有服务;独立数据库可隔离风险;
支持数据存储多样化:不同服务可选择适合的数据库 —— 例如 “订单服务” 用 MySQL(强一致性)存储订单数据,“商品评论服务” 用 MongoDB(高写入性能)存储评论,“商品搜索服务” 用 Elasticsearch(全文检索)存储商品信息;
提升数据安全性:每个服务只管理自身的数据,避免 “一个服务故障导致全量数据泄露”。
去中心化治理:
去中心化治理的价值:
微服务不依赖 “中心化治理平台”(如 SOA 的治理中心),而是通过 “契约”(如 API 文档、OpenAPI 规范)实现服务间的协作;
服务的配置管理采用 “分布式配置中心”(如 Apollo、Nacos),但配置中心本身支持集群部署,避免单点故障;
服务的监控、追踪采用 “分布式工具链”(如 Prometheus、Zipkin),数据分散存储但可统一查询,避免 “中心化监控平台” 的性能瓶颈。
避免 “单点故障”:没有任何一个组件是 “系统必需的依赖”,即使配置中心的一个节点故障,服务仍可使用本地缓存的配置继续运行;
提升系统韧性:治理能力分布在各个服务中,而非集中在一个平台,系统抗风险能力更强。
2.2.4 轻量级通信:高效、简洁的服务交互
微服务的 “轻量级通信” 是相对于 SOA 的 “重量级 ESB” 而言的 ——服务间通过简单、标准化的协议交互,减少通信开销,提升交互效率。
主流的轻量级通信协议分为两类:
同步通信协议:
REST(Representational State Transfer):基于 HTTP/HTTPS,采用 JSON 格式传输数据,接口直观(如GET /api/v1/orders/{orderId}查询订单),开发成本低,适合 “请求 – 响应” 型场景(如查询订单、创建用户);
gRPC:基于 HTTP/2,采用 Protocol Buffers(PB)二进制格式传输数据,支持双向流、多路复用,性能比 REST 高 5-10 倍(二进制格式解析快、HTTP/2 减少连接数),适合 “高并发、低延迟” 场景(如商品库存扣减、实时推荐)。
异步通信协议:
基于消息队列:通过 RabbitMQ、Kafka 等消息中间件实现服务间通信,发送方(生产者)将消息发送到队列后即可返回,无需等待接收方(消费者)处理,适合 “解耦” 场景(如订单创建后,异步发送 “订单通知” 到消息队列,由 “通知服务” 消费并发送短信给用户);
基于事件驱动:服务通过发布 “事件”(如 “订单创建事件”“支付成功事件”)通知其他服务,其他服务订阅感兴趣的事件并做出响应,适合 “跨服务联动” 场景(如 “支付成功事件” 触发 “订单状态更新”“库存扣减”“积分增加” 三个操作)。
轻量级通信的核心价值:
降低通信 overhead:相比 SOA 的 SOAP 协议(XML 格式、复杂的协议头),REST/gRPC 的传输效率更高,尤其在高并发场景下可减少网络带宽占用;
简化服务集成:协议标准化(如 REST 遵循 HTTP 规范,gRPC 遵循 PB 规范),不同技术栈的服务(如 Java 服务调用 Go 服务)可轻松交互;
支持灵活扩展:同步通信适合 “实时性要求高” 的场景,异步通信适合 “解耦、削峰” 的场景,可根据业务需求选择。
实践注意事项:
避免 “过度同步调用”:若一个服务需要同步调用多个服务(如 “创建订单” 需调用 “用户服务”“商品服务”“库存服务”“支付服务”),会导致 “调用链过长”,一旦其中一个服务延迟,整个请求的响应时间会大幅增加;此时应结合异步通信(如 “创建订单” 后异步调用 “库存扣减”);
确保接口兼容性:服务接口需遵循 “语义化版本”(如 v1、v2),避免接口变更导致其他服务调用失败 —— 例如 “订单查询接口” 新增字段时,需保持旧版本接口可用,待所有调用方迁移后再删除旧版本。
2.2.5 技术栈多样化:按需选择的灵活性
微服务的 “技术栈多样化” 是 “完全自治” 的延伸 ——每个服务团队可根据业务需求、性能要求、团队技术能力,自主选择技术栈,无需与其他团队统一。
例如,一个电商系统的技术栈选择可如下:
订单服务:Java + Spring Cloud + MySQL(需强一致性、事务支持,Java 生态成熟);
商品搜索服务:Go + Elasticsearch(需高并发、全文检索能力,Go 性能高,Elasticsearch 适合搜索);
用户画像服务:Python + Spark + MongoDB(需数据分析、机器学习能力,Python 生态丰富,MongoDB 适合存储非结构化数据);
API 网关:Kong(基于 Nginx,高性能、支持插件扩展,适合流量转发、限流)。
技术栈多样化的核心价值:
匹配业务需求:不同业务对技术的要求不同(如搜索需性能,数据分析需算法),多样化技术栈可让 “最适合的技术解决最适合的问题”;
提升团队效率:团队可选择熟悉的技术栈(如 Python 团队负责用户画像服务),减少学习成本,提升开发效率;
避免技术债积累:若统一技术栈,当技术栈过时(如旧版本框架存在安全漏洞)时,需全系统升级,成本极高;而多样化技术栈可逐个服务升级,风险可控。
实践风险控制:
避免 “技术滥用”:技术栈选择需以 “业务价值” 为导向,而非 “技术炫技”—— 例如一个简单的 “通知服务” 无需使用 Kubernetes+Istio,用 Java+Spring Boot 即可满足需求;
统一基础工具链:虽然技术栈多样化,但基础工具链(如 CI/CD、监控、日志收集)需统一,避免每个团队重复造轮子 —— 例如所有服务都使用 GitLab CI 做持续集成,使用 Prometheus 做监控。
第三章 微服务架构的全景组件:构建分布式系统的 “骨架”
微服务不是 “服务的简单堆砌”,而是需要一套 “基础设施组件” 支撑其运行 —— 这些组件如同 “骨架”,将分散的服务连接成一个完整、可运维、高可用的系统。本节将拆解微服务的九大核心组件,分析其功能、技术选型与协同关系,呈现微服务架构的 “全景图”。
3.1 微服务架构全景图:组件间的协同关系
在深入讲解单个组件前,先通过一张 “微服务架构全景图” 理解组件间的协同逻辑(以电商 “用户下单” 场景为例):
用户通过前端(Web/APP)发起 “下单请求”,请求首先进入API 网关;
API 网关验证用户身份(通过安全认证组件的 JWT 令牌),并将请求路由到订单服务;
订单服务需要用户信息,通过服务注册与发现组件查询 “用户服务” 的地址,调用用户服务接口;
订单服务需要商品库存信息,通过服务注册与发现组件查询 “库存服务” 的地址,调用库存服务接口;
订单服务的配置(如订单超时时间、支付方式)从配置中心获取;
订单创建成功后,通过消息队列发送 “订单创建事件”,通知服务订阅该事件并发送短信给用户;
整个请求的链路数据(哪个服务调用了哪个服务、响应时间)被分布式追踪组件记录;
各服务的运行指标(QPS、错误率)被监控组件收集,实时展示在可视化平台;
所有服务的日志被日志收集组件汇总,存储到日志分析平台,供故障排查使用;
所有服务通过容器化部署到Kubernetes,由 Kubernetes 负责服务的扩缩容、故障恢复。
从这个场景可见,微服务的组件不是孤立的 ——API 网关是 “入口”,服务注册发现是 “导航”,配置中心是 “参数库”,消息队列是 “通信管道”,监控追踪是 “神经系统”,容器编排是 “部署底座”。这些组件共同支撑了 “下单” 这一业务流程的顺畅运行。
3.2 核心组件一:服务注册与发现 ——“服务的通讯录”
在单体架构中,服务间的调用是 “进程内调用”(如 Java 的方法调用),无需考虑 “服务地址”;但在微服务中,服务部署在多台服务器上,地址(IP + 端口)会随扩缩容、故障恢复动态变化 ——服务注册与发现组件的核心功能,就是 “记录服务地址” 并 “帮助服务找到对方的地址”。
3.2.1 核心原理:注册、心跳、发现
服务注册与发现的工作流程分为三步:
服务注册(Registration):服务启动时,将自身的元数据(服务名、IP、端口、健康检查地址)发送到 “注册中心”,注册中心将这些信息存储到 “服务注册表”(如内存、数据库);
健康检查(Health Check):注册中心定期(如每 30 秒)向服务发送 “健康检查请求”(如调用/actuator/health接口),若服务连续多次无响应,注册中心将其从 “服务注册表” 中移除,避免其他服务调用故障服务;
服务发现(Discovery):服务消费者(如订单服务)需要调用服务提供者(如用户服务)时,先向注册中心查询 “用户服务” 的所有可用地址,然后通过 “负载均衡算法”(如轮询、随机、加权轮询)选择一个地址发起调用。
3.2.2 主流技术选型对比:Eureka、Consul、Nacos
目前主流的服务注册与发现组件有三个:Eureka(Netflix 开源,已停更但仍广泛使用)、Consul(HashiCorp 开源)、Nacos(Alibaba 开源)。三者的核心差异如下表:
|
特性 |
Eureka |
Consul |
Nacos |
|
一致性协议 |
AP(最终一致性) |
CP(强一致性) |
支持 AP/CP 切换 |
|
健康检查方式 |
客户端主动心跳 |
客户端心跳 + 服务端主动检查 |
客户端心跳 + 服务端主动检查 + HTTP 健康检查 |
|
核心功能 |
服务注册与发现 |
服务注册与发现 + 配置中心 + 服务网格 |
服务注册与发现 + 配置中心 + 动态 DNS |
|
跨数据中心支持 |
不支持 |
支持(WAN 集群) |
支持(跨集群同步) |
|
易用性 |
高(Spring Cloud 集成好) |
中(需部署 Consul Agent) |
高(中文文档 + Spring Cloud Alibaba 集成好) |
|
社区活跃度 |
低(已停更) |
中 |
高(Alibaba 维护) |
|
适用场景 |
中小规模、追求可用性的场景 |
大规模、需强一致性的场景(如金融) |
全场景(中小规模用 AP,大规模用 CP) |
选型建议:
若团队熟悉 Spring Cloud,且系统规模不大(服务数 < 100),追求高可用性,可选择 Eureka;
若系统规模大(服务数 > 500),需跨数据中心部署,且对一致性要求高(如金融支付场景),可选择 Consul;
若需 “服务注册发现 + 配置中心” 一体化解决方案,且希望有中文文档和活跃社区支持,优先选择 Nacos(目前国内互联网公司的主流选择)。
3.3 核心组件二:配置中心 ——“动态配置的统一入口”
在单体架构中,配置(如数据库地址、缓存过期时间、接口超时时间)通常存储在配置文件(如 application.properties)中,若需修改配置,需重新打包、部署应用 —— 这在微服务场景下完全不可行(微服务数量可能达数百个,全量部署成本极高)。配置中心的核心功能,是 “集中管理所有服务的配置,支持动态修改配置并实时推送给服务,无需重启服务”。
3.3.1 配置中心的价值:解决 “配置地狱”
配置中心的核心价值体现在三个方面:
集中管理:所有服务的配置(如订单服务的超时时间、支付服务的密钥)都存储在配置中心,避免 “配置分散在各个服务的配置文件中”,便于统一维护、审计;
动态推送:修改配置后(如将订单超时时间从 30 分钟改为 60 分钟),配置中心实时将新配置推送给所有订单服务实例,无需重启服务,大幅提升运维效率;
环境隔离:支持多环境(开发、测试、生产)配置隔离,例如 “开发环境的数据库地址” 与 “生产环境的数据库地址” 分开存储,避免配置混淆导致的故障;
安全管控:敏感配置(如数据库密码、支付密钥)可在配置中心加密存储,避免明文存储在配置文件中导致泄露 —— 服务获取配置时自动解密,确保安全性。
3.3.2 主流技术选型:Apollo、Nacos、Spring Cloud Config
主流的配置中心组件有三个:Apollo(携程开源)、Nacos(Alibaba 开源)、Spring Cloud Config(Spring 官方开源)。三者的核心差异如下表:
|
特性 |
Apollo |
Nacos |
Spring Cloud Config |
|
动态配置推送 |
支持(实时推送) |
支持(实时推送) |
不支持(需结合 Spring Cloud Bus) |
|
配置格式支持 |
Properties、YAML、JSON 等 |
Properties、YAML、JSON 等 |
Properties、YAML 等 |
|
敏感配置加密 |
支持(内置加密功能) |
支持(内置加密功能) |
不支持(需结合第三方加密工具) |
|
服务注册发现集成 |
不支持(需配合 Eureka/Consul) |
支持(一体化) |
不支持(需配合 Eureka/Consul) |
|
易用性 |
高(Web 界面友好,操作简单) |
高(Web 界面友好,中文文档) |
中(需结合 Git,操作较复杂) |
|
社区活跃度 |
中(携程维护) |
高(Alibaba 维护) |
中(Spring 官方维护) |
|
适用场景 |
对配置管理要求高的场景(如金融、电商) |
需 “配置中心 + 服务注册发现” 一体化的场景 |
轻量级场景,且已使用 Spring Cloud 生态 |
选型建议:
若对配置管理的 “易用性、功能完整性” 要求高(如需要细粒度的权限控制、配置变更审计),优先选择 Apollo;
若希望 “配置中心 + 服务注册发现” 一体化,减少组件数量,优先选择 Nacos;
若系统规模小,且已使用 Spring Cloud Config+Git 的组合,无需额外功能,可继续使用 Spring Cloud Config(但需注意动态推送需配合 Spring Cloud Bus)。
3.4 核心组件三:API 网关 ——“微服务的统一门面”
微服务的服务数量多,每个服务都有独立的地址(如http://user-service:8080、http://order-service:8080),若前端直接调用这些服务,会面临三个问题:
地址管理复杂:前端需存储所有服务的地址,若服务地址变化(如扩缩容),前端需同步修改;
跨域问题:不同服务可能部署在不同域名下,前端调用会面临浏览器的跨域限制;
安全风险:服务直接暴露在公网,易受攻击(如恶意调用、SQL 注入)。
API 网关的核心功能,是 “作为微服务的统一入口,负责路由转发、鉴权、限流、监控等功能,屏蔽微服务的复杂性,为前端提供简洁、安全的接口”。
3.4.1 API 网关的核心功能:路由、鉴权、限流、监控
API 网关的核心功能可概括为 “入口管理四件套”:
路由转发:将前端的请求转发到对应的微服务 —— 例如将/api/v1/users/*转发到 “用户服务”,将/api/v1/orders/*转发到 “订单服务”;支持 “动态路由”(路由规则可实时修改,无需重启网关);
认证授权:验证用户身份的合法性 —— 例如前端请求携带 JWT 令牌,网关验证令牌的有效性(是否过期、签名是否正确),若无效则直接返回 401 错误,避免非法请求进入微服务;
限流熔断:保护微服务不被过载请求压垮 —— 例如限制 “订单服务” 的 QPS 为 1000,当请求量超过 1000 时,网关直接返回 503 错误;若 “订单服务” 故障,网关触发 “熔断”,暂时停止转发请求到该服务,避免故障扩散;
监控日志:收集所有请求的元数据(请求路径、响应时间、错误码),并记录日志 —— 例如统计 “商品服务” 的 QPS、平均响应时间,当响应时间超过阈值时触发告警;日志可用于故障排查(如某请求失败,可通过网关日志定位是哪个服务的问题);
跨域处理:网关统一处理跨域请求(如设置Access-Control-Allow-Origin响应头),避免前端单独处理跨域问题;
协议转换:支持前端用 HTTP 协议调用,网关将请求转换为微服务间的 gRPC 协议,提升服务间通信效率。
3.4.2 主流技术选型对比:Spring Cloud Gateway、Zuul、Kong
主流的 API 网关组件有三个:Spring Cloud Gateway(Spring 官方开源)、Zuul(Netflix 开源,已停更,目前使用 Zuul 2.x)、Kong(基于 Nginx+OpenResty,开源商业双版本)。三者的核心差异如下表:
|
特性 |
Spring Cloud Gateway |
Zuul 2.x |
Kong |
|
底层技术 |
Netty(异步非阻塞) |
Netty(异步非阻塞) |
Nginx+OpenResty(异步非阻塞) |
|
性能 |
高(支持高并发) |
中(性能略低于 Gateway) |
极高(Nginx 内核,适合超高并发) |
|
功能完整性 |
中(需自定义插件扩展) |
中(需自定义插件扩展) |
高(内置丰富插件,如限流、鉴权、监控) |
|
Spring Cloud 集成度 |
高(原生集成) |
中(需额外配置) |
低(需通过 API 集成) |
|
易用性 |
高(Java 开发者友好) |
中(Java 开发者友好) |
中(配置驱动,需学习 Kong 配置) |
|
社区活跃度 |
高(Spring 官方维护) |
低(已停更) |
高(商业公司维护,有企业版) |
|
适用场景 |
中小规模、Spring Cloud 生态的场景 |
已逐步被 Gateway 替代 |
大规模、超高并发场景(如互联网大厂的网关层) |
选型建议:
若已使用 Spring Cloud 生态,且系统规模不大(QPS<10 万),优先选择 Spring Cloud Gateway(开发成本低,集成方便);
若系统规模大(QPS>100 万),需超高性能和丰富的插件功能,优先选择 Kong(如美团、阿里的网关层多基于 Kong 或自研 Nginx 网关);
避免选择 Zuul 1.x(同步阻塞,性能差),若已使用 Zuul,建议升级到 Zuul 2.x 或迁移到 Spring Cloud Gateway。
3.5 核心组件四:服务通信 ——“服务间的对话方式”
微服务间的协作依赖 “服务通信”—— 例如 “订单服务” 需要调用 “用户服务” 获取用户信息,“支付服务” 需要调用 “订单服务” 更新订单状态。服务通信的核心是 “选择合适的通信方式,确保服务间交互的高效、可靠、可追溯”。
根据 “是否需要等待响应”,服务通信分为 “同步通信” 和 “异步通信” 两类,两者适用场景不同,需结合业务需求选择。
3.5.1 同步通信:REST、gRPC 的场景与优劣
同步通信的核心特征是 “请求方需等待响应方处理完成后才能继续执行”,适合 “实时性要求高、需要获取响应结果” 的场景(如查询订单详情、验证用户身份)。
主流的同步通信协议有两种:
REST(基于 HTTP/1.1):
优点:开发成本低(HTTP 协议直观,JSON 格式易读),兼容性好(任何语言、框架都支持 HTTP),调试方便(可通过 Postman、curl 直接调用);
缺点:性能较低(HTTP/1.1 不支持多路复用,每个请求需建立一个 TCP 连接;JSON 是文本格式,解析速度慢),不支持双向流(只能 “请求 – 响应” 模式);
适用场景:实时性要求不高、请求量不大的场景(如管理后台的订单查询、用户信息修改)。
gRPC(基于 HTTP/2+Protocol Buffers):
优点:性能高(HTTP/2 支持多路复用,一个 TCP 连接可处理多个请求;PB 是二进制格式,解析速度比 JSON 快 5-10 倍),支持双向流(请求方和响应方可同时发送数据,如实时聊天、数据流传输),代码自动生成(基于 PB 定义文件,可自动生成多语言客户端代码);
缺点:开发成本高(需学习 PB 语法,调试需专用工具如 gRPC UI),兼容性差(浏览器不直接支持 gRPC,需通过网关转换为 HTTP);
适用场景:高并发、低延迟的场景(如商品库存扣减、实时推荐、金融交易)。
同步通信的实践建议:
避免 “长链路同步调用”:若一个请求需要同步调用 3 个以上服务(如 “创建订单”→调用用户服务→调用商品服务→调用库存服务→调用支付服务),会导致 “链路延迟叠加”(每个服务响应时间 100ms,总延迟 400ms 以上),影响用户体验;此时应拆分链路,将非实时步骤改为异步通信;
加入 “超时重试” 机制:同步调用时需设置超时时间(如 1000ms),避免服务无响应导致请求阻塞;同时加入重试机制(如失败后重试 2 次),应对网络抖动等临时故障,但需注意 “幂等性”(如 “扣库存” 接口需支持重试,避免重复扣减)。
3.5.2 异步通信:消息队列(RabbitMQ、Kafka)的解耦价值
异步通信的核心特征是 “请求方发送请求后无需等待响应,直接继续执行”,适合 “实时性要求低、需要解耦、削峰” 的场景(如订单通知、日志收集、数据同步)。
主流的异步通信方式是 “基于消息队列的通信”,其工作流程如下:
发送方(生产者)将消息(如 “订单创建消息”)发送到消息队列的 “主题 / 队列” 中;
消息队列存储消息,确保消息不丢失(如持久化到磁盘);
接收方(消费者)订阅 “主题 / 队列”,从消息队列中获取消息并处理;
处理完成后,消费者向消息队列发送 “确认消息”,消息队列删除该消息(避免重复处理)。
主流的消息队列组件有两个:RabbitMQ、Kafka,两者的核心差异如下表:
|
特性 |
RabbitMQ |
Kafka |
|
消息模型 |
交换机(Exchange)+ 队列(Queue),支持多种路由模式(direct、topic、fanout) |
主题(Topic)+ 分区(Partition),基于分区实现负载均衡 |
|
消息可靠性 |
高(支持事务、确认机制、持久化) |
中(默认异步持久化,可配置同步持久化提升可靠性) |
|
吞吐量 |
中(万级 QPS) |
高(十万级 QPS) |
|
延迟 |
低(毫秒级) |
中(毫秒级,批量发送时更低) |
|
适用场景 |
可靠性要求高的场景(如订单支付、金融交易) |
高吞吐量场景(如日志收集、用户行为分析、实时数据管道) |
|
社区活跃度 |
高(Erlang 开发,稳定成熟) |
高(Apache 顶级项目,广泛使用) |
异步通信的核心价值:
解耦服务:发送方无需知道接收方的存在(如 “订单服务” 发送消息后,无需关心是 “通知服务” 还是 “统计服务” 处理),即使接收方下线,发送方仍可正常发送消息;
削峰填谷:高并发场景下(如 “双 11” 下单峰值),消息队列可暂存大量请求,消费者按自身能力逐步处理,避免微服务被 “瞬时峰值” 压垮;
异步化链路:将长链路拆分为 “同步 + 异步” 两部分(如 “创建订单” 同步处理核心逻辑,“发送通知、更新统计” 异步处理),提升请求响应速度;
数据最终一致性:通过 “消息重试” 确保数据最终一致(如 “支付成功消息” 未被 “订单服务” 处理,消息队列会重新投递,直到处理成功)。
异步通信的实践注意事项:
确保消息不丢失:需开启消息持久化(消息存储到磁盘)、生产者确认(消息成功发送到队列后才返回)、消费者确认(处理完成后才确认消息);
处理重复消息:由于网络抖动、消息重试等原因,消费者可能收到重复消息,需在业务层实现 “幂等性”(如 “订单状态更新” 接口,先查询订单当前状态,若已更新则忽略重复消息);
避免消息积压:需监控消息队列的 “消息堆积量”,当堆积量超过阈值时(如 10000 条),及时扩容消费者实例,避免消息处理延迟导致业务异常。
3.6 核心组件五:服务容错 ——“微服务的韧性保障”
微服务是分布式系统,“网络不可靠、服务会故障” 是常态 —— 例如 “库存服务” 因数据库慢查询导致响应延迟,“支付服务” 因第三方接口故障暂时不可用。若不做任何处理,一个服务的故障会通过 “服务调用链” 扩散,导致 “雪崩效应”(如库存服务延迟→订单服务延迟→API 网关延迟→整个系统不可用)。
服务容错的核心功能,是 “通过熔断、降级、限流等策略,隔离故障服务,保护核心业务不受影响,提升系统的韧性”。
3.6.1 容错三大策略:熔断、降级、限流
服务容错的三大核心策略,分别针对 “服务故障”“资源不足”“流量过载” 三种场景:
熔断(Circuit Breaker):
核心逻辑:模仿 “电路保险丝”—— 当服务调用失败率超过阈值(如 50%)时,“熔断开关” 从 “闭合” 变为 “打开”,暂时停止调用该服务,直接返回 “熔断响应”(如默认值、错误提示);经过一段时间(如 30 秒)后,开关变为 “半打开” 状态,允许少量请求尝试调用服务,若调用成功则恢复 “闭合” 状态,否则继续 “打开”;
适用场景:服务故障(如服务宕机、响应超时),避免 “无效调用” 浪费资源;
示例:“支付服务” 故障,调用失败率达 60%,熔断开关打开,“订单服务” 调用支付服务时直接返回 “支付服务暂时不可用,请稍后重试”,避免订单服务线程被大量阻塞。
降级(Degradation):
核心逻辑:当系统资源不足(如 CPU 使用率达 90%、内存不足)时,关闭 “非核心功能”,优先保障 “核心功能” 的正常运行;
适用场景:资源不足、高峰期流量大,需牺牲非核心功能保核心;
示例:“双 11” 高峰期,电商系统关闭 “商品评价”“历史订单导出” 等非核心功能,优先保障 “下单、支付、商品浏览” 等核心功能。
限流(Rate Limiting):
核心逻辑:限制单位时间内的请求数量(如 QPS=1000),超过限制的请求直接拒绝或排队,避免服务被过载请求压垮;
适用场景:流量峰值、恶意请求(如爬虫),保护服务不被 “流量洪水” 淹没;
示例:“商品搜索服务” 的限流阈值为 QPS=5000,当请求量达 6000 时,多余的 1000 个请求返回 “当前请求过多,请稍后重试”。
3.6.2 主流技术选型:Resilience4j、Hystrix、Sentinel
主流的服务容错组件有三个:Resilience4j(轻量级开源)、Hystrix(Netflix 开源,已停更)、Sentinel(Alibaba 开源)。三者的核心差异如下表:
|
特性 |
Resilience4j |
Hystrix |
Sentinel |
|
核心功能 |
熔断、降级、限流、重试 |
熔断、降级、限流、舱壁模式 |
熔断、降级、限流、热点参数限流、系统自适应限流 |
|
轻量级程度 |
高(无依赖,体积小) |
中(依赖 Netflix 组件) |
中(需引入 Sentinel 客户端) |
|
监控可视化 |
需结合 Prometheus+Grafana |
支持 Hystrix Dashboard |
支持 Sentinel Dashboard(中文界面) |
|
易用性 |
中(需手动配置) |
中(注解驱动) |
高(注解驱动 + 配置中心动态配置) |
|
社区活跃度 |
中(持续维护) |
低(已停更) |
高(Alibaba 维护,中文文档) |
|
适用场景 |
轻量级场景,避免依赖冗余 |
已逐步被替代 |
中大规模场景,尤其是 Alibaba 生态用户 |
选型建议:
若系统追求 “轻量级”,不希望引入过多依赖,优先选择 Resilience4j(如 Spring Cloud 2020 版本后已推荐 Resilience4j 替代 Hystrix);
若已使用 Alibaba 生态(如 Spring Cloud Alibaba),或需要 “热点参数限流”(如限制某商品 ID 的查询 QPS)、“系统自适应限流”(根据 CPU、内存动态调整限流阈值),优先选择 Sentinel;
避免选择 Hystrix(已停更,无新功能,且不支持 Java 11+),若已使用 Hystrix,建议迁移到 Resilience4j 或 Sentinel。
3.7 核心组件六:服务监控与可观测性 ——“微服务的神经系统”
微服务的服务数量多、部署分散,故障排查难度极大 —— 例如 “用户下单失败”,可能是 API 网关限流、订单服务故障、库存服务超时、数据库连接池耗尽等多种原因导致。若没有有效的监控手段,故障排查会如同 “大海捞针”。
服务监控与可观测性的核心功能,是 “通过收集 Metrics(指标)、Logs(日志)、Traces(链路追踪)三类数据,全面掌握微服务的运行状态,快速定位故障根因”—— 这三类数据被称为 “可观测性三支柱”。
3.7.1 监控三支柱:Metrics、Logs、Traces
Metrics(指标):
定义:对服务运行状态的 “量化描述”,如 QPS(每秒请求数)、响应时间(RT)、错误率(Error Rate)、CPU 使用率、内存使用率、数据库连接数等;
作用:实时监控服务的 “健康状态”,当指标超过阈值时触发告警(如错误率 > 5%、CPU 使用率 > 90%);
收集工具:Prometheus(开源指标收集工具,支持时序数据存储、灵活查询);
可视化工具:Grafana(开源可视化平台,支持将 Prometheus 指标转化为仪表盘,如 “订单服务 QPS 趋势图”“全系统错误率对比图”)。
Logs(日志):
定义:服务运行过程中产生的 “文本记录”,包含时间戳、日志级别(INFO/WARN/ERROR)、请求 ID、业务数据、异常堆栈等信息;
作用:详细记录服务的运行细节,用于故障排查(如某请求失败,可通过日志查看异常堆栈)、审计(如记录 “用户支付” 的关键信息);
收集工具链:ELK Stack(Elasticsearch+Logstash+Kibana)——Logstash 收集日志,Elasticsearch 存储日志,Kibana 查询、分析日志;或 EFK Stack(Elasticsearch+Fluentd+Kibana,Fluentd 轻量性更好);
实践要点:日志需包含 “请求 ID”(全链路唯一标识),便于关联同一请求的所有日志(如 “下单请求” 的日志从 API 网关→订单服务→用户服务,通过同一请求 ID 串联)。
Traces(链路追踪):
定义:记录一个请求从 “入口” 到 “出口” 经过的所有服务、每个服务的处理时间,形成 “调用链路”;
作用:定位 “链路延迟” 的根因(如 “下单请求” 总延迟 500ms,通过链路追踪发现 “库存服务” 处理耗时 400ms,进一步定位是库存服务的 SQL 慢查询导致);
核心概念:
Span:一个服务的一次处理过程(如 “订单服务调用用户服务” 是一个 Span),包含 Span ID(唯一标识)、父 Span ID(关联上一个服务的 Span)、处理时间;
Trace:一个请求的全链路 Span 集合,通过 Trace ID(全链路唯一标识)关联;
收集工具:Zipkin(Twitter 开源,轻量级)、Jaeger(Uber 开源,支持分布式上下文传递);
实践要点:链路追踪需 “无侵入式埋点”(如通过 Spring Cloud Sleuth 自动为请求添加 Trace ID/Span ID),避免手动埋点增加开发成本。
3.7.2 主流工具链:Prometheus+Grafana、ELK、Zipkin/Jaeger
微服务监控的 “标准工具链” 是三者的组合:
指标监控:Prometheus(收集)+ Grafana(可视化)—— 实时监控服务的健康状态,触发告警;
日志分析:ELK/EFK Stack—— 收集、存储、查询日志,用于故障排查;
链路追踪:Zipkin/Jaeger—— 追踪请求链路,定位延迟根因。
工具链协同示例:
当 “用户下单失败” 时,排查流程如下:
3.8 核心组件七:服务网格(Service Mesh)——“微服务的网络管控中枢”
随着微服务数量增长(如超过 100 个),服务间通信的复杂度会急剧上升:如何统一管理服务间的流量(如灰度发布、流量染色)?如何实现服务间的加密通信(TLS)?如何在不修改业务代码的情况下添加监控、限流、熔断逻辑?
3.8.1 服务网格的核心架构:数据平面与控制平面
服务网格的架构分为两层,两者协同工作:
3.8.2 服务网格的核心价值与适用场景
服务网格的核心价值体现在 “解耦” 与 “统一管控”:
3.9 核心组件八:容器编排与部署 ——“微服务的运行底座”
微服务的服务数量多(如数十个甚至数百个),每个服务又有多个实例(如订单服务部署 5 个实例),若通过手动部署(如 SSH 登录服务器上传 JAR 包),运维成本极高。容器编排与部署组件的核心功能,是 “自动化管理微服务的部署、扩缩容、故障恢复、滚动更新”,为微服务提供稳定的运行底座。
3.9.1 容器化:微服务部署的 “标准化封装”
在容器编排前,需先将微服务 “容器化”—— 即将微服务及其依赖(如 JRE、配置文件)打包为 “容器镜像”,确保微服务在任何环境(开发、测试、生产)中运行环境一致,解决 “开发环境能跑,生产环境跑不了” 的问题。
3.9.2 容器编排:Kubernetes 的核心能力
当容器数量超过 10 个时,手动管理(如启动、停止、扩缩容)变得困难,需通过 “容器编排平台” 实现自动化管理。目前主流的容器编排平台是Kubernetes(K8s),其核心能力包括:
3.9.3 CI/CD 流水线:微服务的 “自动化交付管道”
容器化与 Kubernetes 解决了 “如何运行微服务”,而 “CI/CD 流水线” 解决了 “如何快速、安全地将微服务从代码变为运行的容器”——CI/CD 流水线的核心功能,是 “自动化完成代码编译、测试、构建镜像、部署到 K8s” 的全流程,实现 “代码提交即部署”。
3.10 核心组件九:分布式事务 ——“微服务的数据一致性保障”
在单体架构中,事务通过 “数据库事务” 实现(如
BEGIN TRANSACTION
COMMIT
ROLLBACK
3.10.1 分布式事务的核心挑战:CAP 理论与最终一致性
分布式事务的核心挑战源于CAP 理论:在分布式系统中,一致性(Consistency)、可用性(Availability)、分区容错性(Partition Tolerance)三者不可兼得,必须取舍。由于网络分区(如服务间通信中断)是常态,分布式系统通常选择 “AP”(可用性 + 分区容错性),牺牲强一致性,追求 “最终一致性”(即经过一段时间后,所有服务的数据最终达到一致状态)。
3.10.2 主流分布式事务解决方案:2PC、TCC、SAGA、本地消息表
第四章 微服务拆分实践:从 “业务域” 到 “服务边界”
微服务的 “拆分” 是落地的核心难点 —— 拆分过粗会回到 “单体架构” 的老路,拆分过细会导致服务数量激增、通信 overhead 增大。微服务拆分的核心原则是 “业务驱动”,即基于 “业务域” 划分服务边界,确保每个服务聚焦一个独立的业务能力。本节将从拆分原则、方法、案例三个维度,讲解微服务拆分的实践路径。
4.1 微服务拆分的四大核心原则
微服务拆分需遵循四大原则,这些原则是确保拆分后服务 “高内聚、低耦合” 的基础:
4.1.1 领域驱动设计(DDD)原则:以 “业务域” 为核心
领域驱动设计(Domain-Driven Design,DDD)是微服务拆分的 “黄金方法论”—— 它将业务系统划分为多个 “限界上下文(Bounded Context)”,每个限界上下文对应一个微服务。
4.1.2 单一职责原则(SRP):一个服务只做 “一件事”
单一职责原则在微服务拆分中的体现是 “一个服务只负责一个业务能力”,不承担无关业务逻辑:
4.1.3 高内聚、低耦合原则:服务内部 “紧密协作”,服务之间 “松散交互”
4.1.4 演进式拆分原则:从 “粗粒度” 到 “细粒度”,避免 “一步到位”
微服务拆分不是 “一次性完成的”,而是 “演进式” 的 —— 初期可先将系统拆分为几个粗粒度服务,随着业务发展和团队成熟,再逐步拆分为更细粒度的服务:
4.2 微服务拆分的五大实践方法
掌握拆分原则后,需通过具体方法落地拆分。以下五大方法可帮助团队高效识别服务边界:
4.2.1 事件风暴(Event Storming):通过 “业务事件” 梳理服务边界
事件风暴是 DDD 中常用的 “团队协作式” 拆分方法,通过梳理业务流程中的 “事件”,识别限界上下文和服务边界,适合团队共同参与(如产品经理、开发工程师、测试工程师)。
4.2.2 业务流程分析法:按 “端到端业务流程” 拆分
业务流程分析法适合 “业务流程清晰” 的系统(如电商、物流),通过拆分 “端到端业务流程”,将每个流程或流程中的 “关键步骤” 拆分为独立服务。
4.2.3 团队组织结构分析法(康威定律):“团队结构决定系统结构”
康威定律(Conway's Law)指出:“系统设计必然反映组织沟通结构”—— 即团队如何协作,系统就会如何设计。微服务拆分应与团队组织结构匹配,避免 “一个服务由多个团队负责” 或 “一个团队负责多个无关服务”。
4.2.4 数据依赖性分析法:按 “数据独立” 拆分
微服务的 “数据去中心化” 要求每个服务拥有独立的数据库,因此 “数据依赖性” 是拆分服务的重要依据 —— 若两个业务模块共享大量数据(如 “商品信息” 和 “商品库存”),则适合拆分为同一服务;若数据独立(如 “订单数据” 和 “用户数据”),则适合拆分为不同服务。
4.2.5 性能与扩展性分析法:按 “负载特征” 拆分
不同业务模块的 “负载特征” 差异极大(如 “商品搜索” 的 QPS 是 “用户退款” 的 1000 倍),若将高负载模块与低负载模块放在同一服务,会导致 “资源浪费”(低负载模块被迫与高负载模块一起扩容)或 “性能瓶颈”(高负载模块占用资源,导致低负载模块响应延迟)。
4.3 微服务拆分案例:电商系统从单体到微服务的演进
以 “电商系统” 为例,完整呈现从单体架构到微服务架构的拆分过程,包含 “初期→中期→后期” 三个阶段,具体拆分逻辑和服务边界如下:
4.3.1 阶段一:单体架构(业务验证期)
业务特征:用户量少(<10 万),业务流程简单(仅支持商品浏览、下单、支付),团队规模小(<10 人)。
4.3.2 阶段二:粗粒度微服务(业务增长期)
拆分逻辑:基于 “核心业务域” 拆分,优先解决 “扩展僵化” 问题,拆分为 5 个粗粒度服务。
4.3.3 阶段三:细粒度微服务(业务成熟期)
业务特征:用户量达百万级,业务流程复杂(支持商品搜索、评价、促销、物流、数据分析),高并发需求突出(双 11 峰值 QPS 达 100 万)。
第五章 微服务落地的挑战与解决方案:从 “理论” 到 “实践” 的坑与桥
微服务架构虽有诸多优势,但落地过程中会面临 “分布式复杂性”“运维成本高”“团队能力不匹配” 等一系列挑战。本节将梳理微服务落地的六大核心挑战,并提供经过实践验证的解决方案,帮助团队避开 “坑”,顺利实现从理论到实践的落地。
5.1 挑战一:分布式系统的复杂性 ——“看不见的依赖与故障”
挑战描述:
微服务是分布式系统,相比单体架构,新增了 “服务间通信”“分布式事务”“分布式锁”“链路延迟” 等复杂性:
5.2 挑战二:运维成本急剧上升 ——“从管一个应用到管一百个服务”
挑战描述:
单体架构中,运维只需管理 “几个应用实例 + 一个数据库”;微服务架构中,运维需管理 “数十个服务 + 数十个数据库 + 多个中间件(Nacos、Kafka、Elasticsearch)”,运维成本呈指数级上升:
5.3 挑战三:团队能力不匹配 ——“从‘全栈开发’到‘领域专家’的转型”
挑战描述:
微服务的 “自治” 特征要求团队具备 “端到端能力”(开发、测试、部署、运维),但传统团队分工明确(开发只写代码,运维只管部署),能力不匹配问题突出:
5.4 挑战四:服务接口的兼容性与版本管理 ——“接口变更导致全链路故障”
挑战描述:
微服务间通过 API 接口交互,接口变更(如新增字段、修改参数类型、删除接口)若处理不当,会导致 “调用方服务失败”,甚至引发全链路故障:
5.5 挑战五:数据冗余与一致性 ——“服务独立数据库带来的数据同步问题”
挑战描述:
微服务的 “数据去中心化” 要求每个服务拥有独立数据库,但业务场景中常需 “跨服务数据查询”(如 “查询用户的所有订单” 需用户数据和订单数据),导致 “数据冗余” 与 “一致性” 问题:
5.6 挑战六:安全风险加剧 ——“从‘一个入口’到‘多个入口’的安全防护”
挑战描述:
单体架构中,安全防护只需聚焦 “一个应用入口”(如 Web 端);微服务架构中,服务数量多、接口暴露多,安全风险加剧:
第六章 微服务架构的未来展望:从 “云原生” 到 “智能自治”
微服务架构并非 “终点”,而是随着技术发展持续演进的 “过程”。当前,云原生技术(Kubernetes、服务网格、Serverless)、人工智能(AI)、低代码平台等技术正推动微服务向 “更轻量、更智能、更高效” 的方向发展。本节将展望微服务架构的三大未来趋势,为团队的长期技术规划提供参考。
6.1 趋势一:云原生微服务 ——“基于 Kubernetes 的全栈标准化”
云原生技术的核心是 “让应用更好地在云环境中运行”,而 Kubernetes 已成为云原生的 “操作系统”。未来,微服务将全面基于 Kubernetes 构建,实现 “基础设施标准化、服务部署自动化、资源管理精细化”。
6.1.1 核心演进方向
6.2 趋势二:智能微服务 ——“AI 驱动的自治与优化”
人工智能技术(如机器学习、深度学习)将赋予微服务 “智能决策” 能力,推动微服务从 “人工运维” 向 “智能自治” 演进,实现 “故障自动预测、资源自动优化、流量自动调度”。
6.2.1 核心演进方向
6.3 趋势三:低代码微服务 ——“降低开发门槛,提升交付效率”
低代码平台(Low-Code Platform)的核心是 “通过可视化拖拽、配置化开发替代传统编码”,未来将与微服务结合,形成 “低代码微服务”,降低微服务的开发门槛,让非专业开发人员(如产品经理、业务分析师)也能参与微服务开发,提升交付效率。
6.3.1 核心演进方向
第七章 总结:微服务架构的 “道” 与 “术”
微服务架构的落地,不仅是 “技术选型” 的过程,更是 “理念转型” 的过程。它的 “道”(核心理念)是 “业务驱动、自治、去中心化”,它的 “术”(技术手段)是 “组件化、自动化、可观测性”。只有 “道”“术” 结合,才能真正发挥微服务的价值。
7.1 微服务的
通过 Grafana 查看 “订单服务” 的错误率 —— 发现错误率突增到 10%,初步判断故障源于订单服务或其依赖服务;在 Kibana 中搜索 “订单服务” 的 ERROR 级别日志,筛选 “下单请求” 对应的请求 ID(如
trace-id: 123456
数据平面(Data Plane):
由 “Sidecar 代理”(如 Envoy)组成,每个微服务实例旁都会部署一个 Sidecar 代理;所有服务间的通信都必须经过 Sidecar 代理(如 “订单服务” 调用 “用户服务” 时,请求先发送到订单服务的 Sidecar,再由该 Sidecar 转发到用户服务的 Sidecar,最后由用户服务的 Sidecar 转发到用户服务);负责执行具体的通信逻辑:流量转发、TLS 加密、监控数据收集、限流熔断、灰度发布等;无状态:不存储配置信息,仅接收控制平面的指令。
控制平面(Control Plane):
由 “管控组件”(如 Istio 的 Pilot、Citadel、Galley)组成,是服务网格的 “大脑”;负责管理配置:接收用户定义的规则(如 “将 10% 流量路由到新版本订单服务”),将规则转换为 Sidecar 可理解的格式,并推送到所有 Sidecar 代理;负责服务发现:维护服务注册表,为 Sidecar 提供服务地址;负责安全管控:生成 TLS 证书,分发到所有 Sidecar,确保服务间通信加密;有状态:存储服务网格的配置和元数据。
业务代码与通信逻辑解耦:开发团队无需在业务代码中编写监控、限流、TLS 加密等逻辑(这些由 Sidecar 代理完成),可专注于业务开发;统一流量管理:支持灰度发布(如金丝雀发布、蓝绿发布)、流量染色(如将测试流量路由到测试环境服务)、故障注入(如模拟服务延迟,测试系统容错能力);统一安全管控:自动为服务间通信启用 TLS 加密,无需业务代码修改;支持基于身份的认证(如通过 Service Account 认证服务身份);统一可观测性:Sidecar 自动收集服务间通信的 Metrics(如延迟、错误率)、Logs(如请求日志)、Traces(如调用链路),无需业务代码埋点。
微服务数量庞大(如超过 100 个),通信逻辑维护成本高;对流量管理(如灰度发布、多环境隔离)要求高;对安全性要求高(如金融、政务场景,需服务间通信加密);技术栈多样化,无法通过统一框架(如 Spring Cloud)实现通信逻辑管控。
Istio:目前最成熟的服务网格方案,由 Google、IBM、Lyft 联合开源,支持 Kubernetes 部署,生态丰富;Linkerd:轻量级服务网格,性能比 Istio 高(Sidecar 基于 Rust 开发),部署简单,适合中小规模场景;Consul Connect:HashiCorp 开源,与 Consul 服务注册发现集成紧密,适合已使用 Consul 的团队。
避免 “过度引入”:服务网格会增加系统复杂度(如 Sidecar 代理会增加延迟、控制平面需要运维),若微服务数量少于 50 个,优先通过 Spring Cloud 等框架实现通信逻辑,无需引入服务网格;关注性能损耗:Sidecar 代理会增加请求延迟(通常 1-5ms),高并发场景(如 QPS>10 万)需进行性能测试,确保延迟在可接受范围。
容器镜像(Image):只读模板,包含微服务运行所需的代码、依赖、环境变量(如
order-service:v1.0
order-service:v1.0
环境一致性:镜像包含所有依赖,确保开发、测试、生产环境一致;轻量级:容器共享宿主机的内核,启动速度快(秒级),资源占用比虚拟机低;可移植性:镜像可在任何支持 Docker 的环境中运行(如 Linux、Windows、云服务器)。
服务部署与滚动更新:
通过 “Deployment” 资源定义微服务的部署配置(如 “订单服务部署 5 个实例,使用
order-service:v1.0
扩缩容:
支持 “手动扩缩容”(如通过命令
kubectl scale deployment order-service --replicas=10
故障恢复:
持续监控容器状态,若容器崩溃(如 JVM 内存溢出),K8s 会自动重启容器;若某台宿主机故障,K8s 会将该主机上的容器调度到其他健康主机上,确保服务可用性。
服务发现与负载均衡:
通过 “Service” 资源为微服务创建统一的访问地址(如
order-service.default.svc.cluster.local
存储管理:
支持 “持久化存储”(通过 PV/PVC 资源),解决容器重启后数据丢失的问题(如订单服务的数据库数据存储在持久化卷中,容器重启后数据不丢失)。
代码管理:GitLab、GitHub(存储代码,支持分支管理、代码评审);持续集成(CI):GitLab CI、Jenkins(代码提交后,自动编译、执行单元测试、接口测试,构建容器镜像并推送到镜像仓库);镜像仓库:Harbor、Docker Hub(存储容器镜像,支持镜像版本管理、安全扫描);持续部署(CD):ArgoCD、Flux(从镜像仓库拉取新镜像,自动更新 K8s 的 Deployment 配置,完成服务部署)。
开发工程师将代码提交到 GitLab 的
develop
order-service:develop-123
main
order-service:v1.0
提升交付效率:自动化替代手动操作,将 “代码提交到生产部署” 的时间从几天缩短到几小时;降低交付风险:每次提交都执行测试,提前发现问题;部署过程自动化,避免手动操作失误;支持敏捷迭代:快速响应业务需求,实现 “小步快跑、快速试错”。
2PC(Two-Phase Commit,两阶段提交):
核心原理:引入 “事务协调者”,将分布式事务分为两个阶段:
准备阶段(Prepare):事务协调者向所有参与者(如订单服务、库存服务)发送 “准备请求”,参与者执行本地事务(如插入订单、扣减库存)但不提交,向协调者返回 “准备成功” 或 “准备失败”;提交阶段(Commit):若所有参与者均返回 “准备成功”,协调者向所有参与者发送 “提交请求”,参与者提交本地事务;若有任何一个参与者返回 “准备失败”,协调者向所有参与者发送 “回滚请求”,参与者回滚本地事务。
优点:实现简单,强一致性;缺点:同步阻塞(准备阶段参与者需等待协调者指令,无法释放资源),单点故障(协调者故障会导致所有参与者阻塞),不适合高并发场景;适用场景:低并发、对强一致性要求高的场景(如金融转账),目前已较少在微服务中使用。
TCC(Try-Confirm-Cancel,补偿事务):
核心原理:将每个参与者的业务操作拆分为 “Try”“Confirm”“Cancel” 三个阶段,由业务代码实现补偿逻辑:
Try 阶段:尝试执行业务操作,预留资源(如订单服务创建 “待确认” 订单,库存服务预留库存);Confirm 阶段:确认执行业务操作,释放预留资源(如订单服务将 “待确认” 订单改为 “已确认”,库存服务扣减预留库存),Confirm 操作必须是幂等的(可重复执行);Cancel 阶段:取消执行业务操作,回滚预留资源(如订单服务删除 “待确认” 订单,库存服务释放预留库存),Cancel 操作也必须是幂等的;
优点:无锁阻塞,性能高,适合高并发场景;缺点:业务侵入性强(需手动编写 Try/Confirm/Cancel 逻辑),开发成本高;适用场景:高并发、对性能要求高的场景(如电商下单、支付),典型案例是支付宝的分布式事务方案。
SAGA 模式:
核心原理:将分布式事务拆分为 “一系列本地事务”,每个本地事务对应一个 “补偿事务”;若某个本地事务执行失败,触发前面所有已执行本地事务的补偿事务,回滚数据:
正向流程:执行 T1(订单服务插入订单)→执行 T2(库存服务扣减库存)→执行 T3(支付服务记录支付);补偿流程:若 T3 执行失败,执行 C2(库存服务恢复库存)→执行 C1(订单服务删除订单);
实现方式:
编排式:由 “SAGA 协调者” 统一管理事务流程(如通过 Flowable、Camunda 等工作流引擎),协调者调用各服务的本地事务和补偿事务;choreography 式:无中央协调者,各服务通过事件通信(如订单服务执行 T1 后发送 “订单创建事件”,库存服务接收事件后执行 T2,再发送 “库存扣减事件”),失败时由服务自身触发补偿。
优点:业务侵入性低(补偿事务可独立实现),支持长事务(如跨天的订单确认);缺点:一致性延迟(需等待所有补偿事务执行完成),补偿事务需处理幂等性和并发问题;适用场景:长事务、业务流程复杂的场景(如供应链管理、订单履约),是目前微服务中最常用的分布式事务方案。
本地消息表(Local Message Table):
核心原理:将 “业务操作” 与 “消息发送” 放在同一个本地事务中,确保业务操作成功后,消息必然发送;接收方消费消息后执行本地事务,若失败则重试:
发送方:执行本地事务(如订单服务插入订单)→将 “订单创建消息” 插入本地消息表→提交本地事务→将消息发送到消息队列;接收方:从消息队列消费消息→执行本地事务(如库存服务扣减库存)→若成功则标记消息为 “已消费”,若失败则不标记,等待重试;消息重试:发送方定期扫描本地消息表,将未发送成功的消息重新发送到消息队列;接收方定期扫描未消费的消息,重新执行本地事务。
优点:实现简单(基于消息队列和本地数据库),业务侵入性低;缺点:依赖消息队列的可靠性,重试可能导致数据重复(需处理幂等性);适用场景:中小规模微服务、对一致性要求不高的场景(如日志同步、数据统计)。
高并发、性能优先:选择 TCC;业务流程复杂、长事务:选择 SAGA(推荐编排式,便于管理);中小规模、实现成本优先:选择本地消息表;强一致性、低并发:选择 2PC(谨慎使用)。
核心概念:
领域(Domain):业务系统的核心范围(如电商系统的 “订单领域”“用户领域”“商品领域”);限界上下文(Bounded Context):领域内的一个独立子域,拥有自己的业务规则、数据模型、术语表,与其他限界上下文通过 “上下文映射图”(Context Map)定义交互关系;聚合(Aggregate):限界上下文内的 “数据单元”,由多个实体(Entity)和值对象(Value Object)组成,聚合根(Aggregate Root)是聚合的唯一入口(如 “订单” 是聚合根,包含 “订单项”“订单地址” 等实体)。
拆分逻辑:
梳理业务领域,识别核心领域(如电商的 “订单领域”)、支撑领域(如 “支付领域”“库存领域”)、通用领域(如 “用户领域”“通知领域”);在每个领域内划分限界上下文(如 “订单领域” 可划分为 “订单创建”“订单查询”“订单履约” 三个限界上下文);每个限界上下文对应一个微服务,限界上下文内的聚合对应服务的 “数据模型”,聚合根的方法对应服务的 “API 接口”。
示例:电商系统通过 DDD 拆分后的服务包括:
用户服务(限界上下文:用户注册、用户信息管理、用户认证);商品服务(限界上下文:商品管理、商品分类、商品库存);订单服务(限界上下文:订单创建、订单查询、订单取消);支付服务(限界上下文:支付方式管理、支付处理、退款);通知服务(限界上下文:短信通知、邮件通知、推送)。
反例:“订单服务” 同时处理 “订单创建”“支付处理”“库存扣减”—— 违反单一职责,导致服务耦合度高;正例:“订单服务” 只处理 “订单创建、查询、取消”,“支付处理” 交给 “支付服务”,“库存扣减” 交给 “库存服务”—— 每个服务聚焦单一业务能力。高内聚:服务内部的模块、接口、数据模型围绕 “核心业务能力” 设计,关联性强。例如 “订单服务” 的 “订单创建接口”“订单查询接口”“订单取消接口” 均围绕 “订单管理” 展开,内部协作紧密;低耦合:服务之间通过 “标准化 API” 交互,不依赖对方的内部实现(如 “订单服务” 调用 “支付服务” 时,只需知道 “支付接口” 的参数和返回值,无需知道 “支付服务” 如何与第三方支付平台交互);耦合度判断标准:若一个服务的代码修改,导致另一个服务必须同步修改,则耦合度过高。例如 “订单服务” 修改了 “订单状态枚举”,导致 “支付服务” 必须同步修改状态判断逻辑 —— 这是典型的 “紧耦合”,需通过 “接口版本化”(如 v1、v2)解决。
初期(业务验证阶段):将电商系统拆分为 “用户商品服务”(包含用户、商品、库存)、“订单支付服务”(包含订单、支付、通知)——2 个服务,降低开发和运维成本;中期(业务增长阶段):将 “用户商品服务” 拆分为 “用户服务”“商品服务”“库存服务”,将 “订单支付服务” 拆分为 “订单服务”“支付服务”“通知服务”——5 个服务,适应业务复杂度增长;后期(业务成熟阶段):根据需求进一步拆分,如将 “商品服务” 拆分为 “商品管理服务”“商品搜索服务”“商品评价服务”——8 个服务,满足高并发、高可用需求。
识别领域事件:在白板上用 “橙色便签” 记录业务流程中的所有 “事件”(事件是 “已发生的事实”,如 “订单创建成功”“支付成功”“库存扣减成功”);识别命令:用 “蓝色便签” 记录触发事件的 “命令”(命令是 “要执行的操作”,如 “创建订单” 命令触发 “订单创建成功” 事件);识别聚合 / 实体:用 “黄色便签” 记录事件涉及的 “聚合 / 实体”(如 “订单创建成功” 事件涉及 “订单” 聚合);划分限界上下文:根据事件、命令、聚合的关联性,用 “虚线” 将相关的便签圈起来,每个圈对应一个 “限界上下文”(如 “订单创建”“订单查询”“订单取消” 相关的便签圈为 “订单限界上下文”);映射服务:每个限界上下文对应一个微服务,限界上下文内的命令对应服务的 API 接口(如 “创建订单” 命令对应订单服务的
/api/v1/orders
领域事件:订单创建成功、库存扣减成功、支付成功、订单状态更新成功、通知发送成功;命令:创建订单、扣减库存、处理支付、更新订单状态、发送通知;聚合:订单、库存、支付、用户、通知;限界上下文:订单上下文(包含订单聚合、创建订单命令、订单创建成功事件)、库存上下文(包含库存聚合、扣减库存命令、库存扣减成功事件)、支付上下文(包含支付聚合、处理支付命令、支付成功事件);映射服务:订单服务、库存服务、支付服务。
梳理系统的核心业务流程(如电商的 “下单流程”“支付流程”“物流流程”“退款流程”);分析每个业务流程的 “步骤”(如 “下单流程” 包括:用户选择商品→提交订单→扣减库存→创建支付单→支付→更新订单状态);将 “独立的业务流程” 或 “跨流程复用的步骤” 拆分为服务:
独立流程:如 “物流流程” 拆分为 “物流服务”;复用步骤:如 “扣减库存” 在 “下单流程”“退款流程” 中均会用到,拆分为 “库存服务”;
验证服务边界:确保每个服务的流程不依赖其他服务的内部步骤(如 “订单服务” 只需调用 “库存服务” 的 “扣减库存接口”,无需关心库存服务如何查询库存、更新数据库)。
梳理团队组织结构(如电商公司的团队包括:用户团队、商品团队、订单团队、支付团队、运维团队);为每个 “业务团队” 分配对应的 “业务域”(如用户团队负责 “用户域”,订单团队负责 “订单域”);每个业务团队负责的业务域对应一个或多个微服务(如订单团队负责 “订单服务”“订单履约服务”);定义团队间的协作方式(如用户团队和订单团队通过 “用户服务 API” 协作,而非直接修改对方代码)。
梳理系统的核心数据实体(如用户、商品、订单、支付、库存);分析数据实体之间的 “依赖关系”:
强依赖:实体 A 的字段直接引用实体 B 的主键(如订单表的
user_id
id
JOIN
拆分原则:
紧耦合数据:放在同一服务(如商品表和商品库存表放在 “商品服务”);强依赖 / 弱依赖数据:放在不同服务(如订单表放在 “订单服务”,用户表放在 “用户服务”),通过 API 调用获取关联数据。
避免 “跨服务数据库 JOIN”:若两个服务的数据库需要频繁 JOIN,说明数据拆分不合理,需重新调整服务边界;合理设计 “冗余字段”:为减少 API 调用,可在服务间冗余少量非核心数据(如订单表冗余 “用户名” 字段,避免每次查询订单时都调用用户服务),但需确保冗余数据的一致性(如用户名修改时,同步更新订单表的冗余字段)。
分析每个业务模块的 “负载特征”:
流量特征:QPS(峰值 / 均值)、请求量波动(如 “双 11” 峰值是日常的 10 倍);资源特征:CPU 使用率、内存占用、IO 密集型 / CPU 密集型(如商品搜索是 IO 密集型,数据分析是 CPU 密集型);扩展性需求:是否需要独立扩容(如商品搜索需单独扩容 Elasticsearch 集群);
拆分原则:
高负载模块:拆分为独立服务(如 “商品搜索” 拆分为 “商品搜索服务”),便于独立扩容;资源密集型模块:拆分为独立服务(如 “数据分析” 拆分为 “数据服务”),避免占用核心服务资源;流量波动大的模块:拆分为独立服务(如 “促销活动” 拆分为 “促销服务”),便于在活动期间临时扩容。
高 QPS 模块:商品搜索(QPS 10 万)、商品详情(QPS 5 万)→拆分为 “商品搜索服务”“商品详情服务”;资源密集型模块:用户画像分析(CPU 使用率 80%)→拆分为 “用户画像服务”;流量波动大的模块:促销活动(活动期间 QPS 20 万,日常 1 万)→拆分为 “促销服务”。
前端:Web 端(商品展示、下单页面);后端:一个 Java 应用(包含用户、商品、订单、支付所有业务逻辑);数据库:一个 MySQL 数据库(包含 user、product、order、payment、inventory 表);部署:应用打包为 WAR 包,部署到 2 台 Tomcat 服务器,通过 Nginx 负载均衡。
服务注册发现:Nacos;配置中心:Nacos(与服务注册发现一体化);API 网关:Spring Cloud Gateway;消息队列:Kafka(用于服务间异步通信,如订单创建后通知服务发送短信);监控:Prometheus + Grafana;部署:Docker + Kubernetes(每个服务部署 3 个实例,支持自动扩缩容)。
扩展灵活:商品服务 QPS 激增时,仅扩容商品服务实例,无需扩容其他服务;团队协作:每个团队负责一个服务,代码冲突减少,迭代速度提升;故障隔离:通知服务故障,不影响下单、支付核心功能。
服务网格:Istio(管理 12 个服务的流量,支持灰度发布、TLS 加密);分布式事务:SAGA 模式(基于 Seata 框架,确保下单、库存、支付的数据一致性);链路追踪:Jaeger(追踪跨 12 个服务的复杂链路);日志分析:ELK Stack(收集 12 个服务的日志,支持全文检索);缓存:Redis 集群(用于商品详情、用户会话、库存计数缓存);数据库:分库分表(订单表、用户表采用 Sharding-JDBC 分库分表,支撑百万级数据)。
高可用:核心服务(订单、支付)部署 5 个实例,支持故障自动恢复,可用性达 99.99%;高并发:商品搜索服务通过 Elasticsearch 支撑 10 万 QPS,秒杀活动通过 Redis+Kafka 支撑 50 万 QPS;敏捷迭代:每个团队可独立发布服务,双 11 前促销团队 2 周内完成 “秒杀活动” 功能开发与上线;可扩展:新增 “跨境电商” 业务时,仅需新增 “跨境订单服务”“跨境支付服务”,无需修改现有服务。
服务依赖复杂:一个请求可能依赖 5 个以上服务(如 “下单” 依赖订单、用户、库存、支付、促销服务),任何一个依赖服务故障都会导致请求失败;分布式故障难排查:“下单失败” 可能是 API 网关限流、订单服务数据库慢查询、库存服务 Redis 缓存击穿、支付服务第三方接口超时等原因导致,排查如同 “大海捞针”;数据一致性难保障:跨服务的数据库操作(如订单创建 + 库存扣减)无法通过传统事务保证,易出现 “订单创建成功但库存未扣减” 的不一致数据。
构建 “可观测性体系”,让分布式系统 “透明化”:
指标监控:通过 Prometheus 收集所有服务的 Metrics(QPS、响应时间、错误率、CPU 使用率),用 Grafana 制作 “全链路仪表盘”,实时监控服务健康状态;日志聚合:通过 ELK Stack 收集所有服务的日志,统一日志格式(包含 trace-id、service-name、timestamp、level、message),支持按 trace-id 查询全链路日志;链路追踪:通过 Jaeger/Zipkin 实现全链路追踪,标记每个服务的 Span 耗时,快速定位延迟根因(如 “库存服务 Span 耗时 300ms,是 SQL 慢查询导致”);告警机制:设置多级告警阈值(如错误率 > 1% 告警,>5% 严重告警),通过短信、钉钉、邮件通知运维团队,确保故障早发现。
采用 “容错机制”,隔离分布式故障:
熔断:通过 Sentinel/Resilience4j 为每个依赖服务设置熔断阈值(如失败率 > 50% 触发熔断),避免故障服务拖垮调用方;降级:核心服务(如订单)依赖非核心服务(如推荐)时,若推荐服务故障,自动降级为 “返回默认推荐列表”,确保核心功能可用;限流:在 API 网关和核心服务设置限流(如订单服务 QPS=1 万),避免瞬时峰值压垮服务;超时与重试:所有服务间调用设置超时时间(如 1000ms),避免请求阻塞;对幂等接口(如查询、扣减库存)设置重试(如重试 2 次),应对网络抖动。
选择合适的 “分布式事务方案”,保障数据一致性:
高并发场景(如电商下单):采用 SAGA 模式(基于 Seata 框架),将 “订单创建→库存扣减→支付处理” 拆分为本地事务,失败时触发补偿;金融级场景(如转账):采用 TCC 模式,手动编写 Try/Confirm/Cancel 逻辑,确保强一致性;中小规模场景:采用本地消息表(基于 Kafka+MySQL),实现简单的数据一致性。
部署复杂:每个服务需单独打包、部署、版本管理,手动部署效率低且易出错;资源管理难:服务实例数量多(如 12 个服务,每个服务 3 个实例,共 36 个实例),需手动分配 CPU、内存资源,易出现 “资源浪费” 或 “资源不足”;中间件运维复杂:Nacos、Kafka、Elasticsearch 等中间件需部署集群、监控、扩容,对运维能力要求高;故障恢复慢:服务实例故障后,需手动重启或迁移,恢复时间长(如 10 分钟以上)。
构建 “自动化运维体系”,替代手动操作:
容器化:所有服务和中间件打包为 Docker 镜像,确保环境一致性,简化部署;容器编排:采用 Kubernetes 管理容器,实现 “自动化部署、扩缩容、故障恢复”:
部署自动化:通过 Kubernetes 的 Deployment 资源定义服务实例数、镜像版本,执行
kubectl apply
CI/CD 流水线:通过 GitLab CI+ArgoCD 实现 “代码提交→编译→测试→构建镜像→部署到 K8s” 的全自动化,无需手动干预(如代码合并到 main 分支后,自动部署到生产环境)。
构建 “云原生基础设施”,降低中间件运维成本:
中间件容器化:Nacos、Kafka、Elasticsearch 等中间件通过 Kubernetes 部署(如使用 Helm Charts 一键部署 Kafka 集群),统一资源管理;托管服务:对非核心中间件(如 Redis、MySQL),优先使用云厂商的托管服务(如阿里云 RDS、Redis 集群),减少自建运维成本;基础设施即代码(IaC):通过 Terraform、Ansible 编写基础设施配置代码(如 K8s 集群配置、中间件部署配置),实现基础设施的版本管理和自动化创建,避免 “手动配置不一致”。
构建 “标准化运维规范”,统一运维流程:
服务命名规范:统一服务名称格式(如
order-service
order-service-dev
开发团队:传统开发工程师只熟悉业务代码编写,不掌握 Docker、K8s、监控工具的使用,无法独立完成服务部署和故障排查;运维团队:传统运维工程师只熟悉服务器管理,不理解微服务的业务逻辑和依赖关系,无法高效排查 “业务相关的故障”(如订单服务调用支付服务失败);团队协作:开发团队和运维团队沟通成本高(如开发提交的镜像有问题,运维需反复沟通确认),导致部署效率低。
转型 “DevOps 团队”,打破开发与运维的壁垒:
团队结构调整:将 “开发工程师” 和 “运维工程师” 编入同一团队(如订单团队包含 2 名开发、1 名 DevOps 工程师),实现 “开发运维一体化”;技能培训:为开发工程师提供 Docker、K8s、Prometheus 等运维技能培训,为运维工程师提供微服务业务逻辑培训,确保团队成员具备 “全栈能力”;责任共担:明确 “开发团队对服务的全生命周期负责”(从代码编写到生产运维),避免 “开发甩锅运维” 的情况。
推行 “领域驱动的团队模式”,培养 “领域专家”:
团队与业务域对齐:每个团队负责一个或多个相关的业务域(如订单团队负责订单服务、物流服务),团队成员长期深耕该领域,成为 “领域专家”;业务知识沉淀:团队内部建立 “领域知识库”(如 Wiki),记录业务规则、服务边界、API 文档、故障案例,确保知识传承;跨职能协作:团队内包含 “产品经理、开发、测试、DevOps” 角色,实现 “业务需求→开发→测试→部署” 的端到端协作,减少跨团队沟通成本。
引入 “平台团队”,为业务团队提供 “基础设施支撑”:
平台团队职责:搭建和维护 “微服务基础设施平台”(如 CI/CD 流水线、监控平台、服务网格),提供标准化工具和文档(如 “一键部署服务” 的脚本、“故障排查指南”);业务团队聚焦:业务团队无需关心基础设施的搭建,只需使用平台团队提供的工具,专注于业务开发和服务运维;反馈闭环:平台团队定期收集业务团队的需求(如 “需要新增日志查询功能”),持续优化基础设施平台,提升业务团队效率。
接口不兼容变更:如支付服务将 “支付接口” 的
amount
/api/orders
制定 “接口设计规范”,确保接口兼容性:
接口风格统一:采用 RESTful 风格设计接口(如
GET /api/v1/orders/{orderId}
POST /api/v1/orders
user_id
userId
新增字段:接口响应新增字段时,旧版本调用方可忽略该字段,避免解析失败;修改字段:避免修改已有字段的类型或含义,若必须修改,新增字段替代(如新增
amount_long
amount
10001
20001
推行 “接口版本化管理”,实现平滑升级:
版本标识方式:在接口路径中包含版本号(如
/api/v1/orders
/api/v2/orders
Accept: application/vnd.xxx.v1+json
主版本号(如 v1→v2):不兼容变更(如删除接口、修改核心字段),需调用方同步升级;次版本号(如 v1.1→v1.2):兼容变更(如新增字段、新增接口),旧版本调用方可正常使用;
灰度发布:新版本接口上线时,先路由 10% 流量到新版本,验证无问题后逐步增加流量,若出现问题可快速回滚到旧版本。
实现 “接口文档自动化”,确保文档与代码一致:
接口文档工具:使用 Swagger/OpenAPI 自动生成接口文档(如 Spring Boot 项目集成
springdoc-openapi
@Operation
@Parameter
数据冗余:为减少跨服务调用,服务间会冗余数据(如订单服务冗余 “用户名” 字段),但冗余数据需同步更新(如用户名修改时,需同步更新订单服务的 “用户名” 字段),否则会出现数据不一致;跨服务查询复杂:若不冗余数据,“查询用户的所有订单” 需订单服务调用用户服务获取用户名,再聚合返回,增加接口响应时间;数据孤岛:每个服务的数据库独立,缺乏统一的数据视图,数据分析时需跨多个数据库取数,效率低。
合理设计 “数据冗余策略”,平衡性能与一致性:
冗余数据选择:只冗余 “读多写少、非核心” 的数据(如订单服务冗余 “用户名”“商品名称”,不冗余 “用户余额”“商品库存” 等高频变更数据);数据同步方式:
同步同步:高频变更的冗余数据(如 “用户手机号”),通过服务调用同步更新(如用户服务修改手机号后,调用订单服务的 “更新用户手机号接口”);异步同步:低频变更的冗余数据(如 “用户名”),通过消息队列异步更新(如用户服务修改用户名后,发送 “用户信息变更事件” 到 Kafka,订单服务消费事件更新冗余字段);
一致性保障:冗余数据同步失败时,通过 “重试机制”(如消息队列重试)或 “补偿任务”(如定时任务对比用户服务和订单服务的用户名,不一致则修正)确保最终一致。
采用 “服务聚合” 或 “API 网关聚合” 解决跨服务查询:
服务聚合:由 “聚合服务” 负责跨服务数据查询和聚合(如新增 “用户订单聚合服务”,调用用户服务获取用户数据,调用订单服务获取订单数据,聚合后返回给前端);API 网关聚合:API 网关(如 Spring Cloud Gateway)支持 “请求转发 + 响应聚合”,前端发送一个请求到网关,网关转发到多个服务,聚合响应后返回(如网关转发请求到用户服务和订单服务,聚合用户信息和订单列表后返回);缓存优化:聚合服务或网关对聚合结果进行缓存(如 Redis),减少重复查询,提升响应速度(如缓存 “用户 ID=123 的订单列表”,有效期 5 分钟)。
构建 “数据中台”,解决数据孤岛问题:
数据采集:通过数据同步工具(如 Flink CDC、DataX)将各服务的数据库数据同步到数据中台的统一存储(如 ClickHouse、Hive);数据建模:在数据中台构建 “统一数据模型”(如用户主题、订单主题),消除数据冗余和不一致;数据服务:数据中台提供标准化的数据服务接口(如 “用户订单统计接口”“商品销售分析接口”),供业务系统和数据分析使用,避免直接访问业务数据库。
接口未授权访问:如 “订单查询接口” 未验证用户身份,攻击者直接调用接口获取他人订单信息;敏感数据泄露:服务间通信未加密(如 HTTP 明文传输),攻击者窃听网络流量获取 “支付密码”“银行卡号” 等敏感数据;服务滥用:攻击者恶意调用高并发接口(如 “创建订单接口”),导致服务过载;依赖组件漏洞:微服务依赖大量开源组件(如 Spring Boot、Netty),组件漏洞(如 Log4j2 漏洞)可能被利用,导致服务被入侵。
构建 “全链路身份认证与授权体系”,防止未授权访问:
统一身份认证:采用 OAuth 2.0/OpenID Connect 协议实现统一认证,用户登录后获取 JWT 令牌,所有服务接口调用需携带令牌;令牌验证:在 API 网关层统一验证令牌有效性(如验证签名、过期时间),避免每个服务重复验证;细粒度授权:基于 RBAC(角色基础访问控制)模型实现授权(如 “普通用户只能查询自己的订单,管理员可查询所有订单”),授权规则存储在配置中心,支持动态更新;服务间认证:服务间调用采用 “服务账号” 认证(如 Istio 的 mTLS 认证),确保只有授权的服务才能调用接口,防止内部服务被未授权访问。
实现 “全链路通信加密”,保护敏感数据:
外部通信加密:前端与 API 网关之间采用 HTTPS 通信,加密传输数据;内部通信加密:服务间通信采用 TLS 加密(如通过 Istio 的 mTLS 自动为服务间通信启用 TLS,无需修改业务代码);敏感数据存储加密:数据库中的敏感数据(如支付密码、银行卡号)采用加密存储(如 AES 加密),密钥存储在专用密钥管理系统(如阿里云 KMS),避免密钥泄露;数据脱敏:日志和接口响应中的敏感数据需脱敏(如手机号显示为 “1381234”,银行卡号显示为 “ **** **** 1234”),防止日志泄露导致敏感信息暴露。
构建 “多层次安全防护体系”,抵御攻击:
入口防护:在 API 网关层部署 WAF(Web 应用防火墙),抵御 SQL 注入、XSS、CSRF 等常见 Web 攻击;流量防护:在 API 网关和核心服务部署限流和熔断,防止恶意请求压垮服务(如限制 “创建订单接口” 的单 IP QPS=10);依赖组件安全:建立 “开源组件漏洞管理机制”,定期扫描依赖组件(如使用 OWASP Dependency-Check),发现漏洞及时升级;安全审计:记录所有敏感操作日志(如用户登录、订单支付、权限变更),定期审计日志,发现异常操作(如异地登录、批量查询订单);渗透测试:定期对微服务系统进行渗透测试,模拟攻击者攻击,发现安全漏洞并修复。
服务网格成为标准组件:
随着微服务数量增长,服务间通信的复杂度进一步提升,服务网格(如 Istio)将从 “可选组件” 变为 “标准组件”,统一负责流量管理、安全、可观测性;服务网格将与 Kubernetes 深度融合(如 Istio 的 Sidecar 代理通过 Kubernetes 的 Inject 机制自动注入),简化部署和运维;轻量级服务网格(如 Linkerd 2.x、Cilium)将成为主流,解决 Istio 的 “性能损耗” 和 “复杂度高” 问题。
Serverless 架构与微服务融合:
Serverless 架构(如 AWS Lambda、阿里云函数计算)的 “按需付费、无服务器管理” 特性,将与微服务结合,形成 “Serverless 微服务”;适合 Serverless 的微服务场景:流量波动大(如促销活动通知)、执行时间短(如数据处理、文件转换)、非核心服务(如日志分析);实现方式:通过 Knative(基于 Kubernetes 的 Serverless 框架)将微服务打包为 “函数”,自动实现 “按需扩缩容”(无请求时缩容到 0 实例,节省资源)。
GitOps 成为主流部署模式:
GitOps 的核心是 “将基础设施和应用配置存储在 Git 仓库中,通过 Git 的版本管理实现部署自动化”;未来,微服务的部署将全面采用 GitOps 模式(如 ArgoCD、Flux):
配置存储:服务的 Kubernetes 配置(Deployment、Service)、应用配置(如 Nacos 配置)存储在 Git 仓库;自动同步:ArgoCD 定期同步 Git 仓库的配置到 Kubernetes 集群,若集群配置与 Git 不一致,自动修复;版本回滚:若部署出现问题,只需回滚 Git 仓库的配置,ArgoCD 自动同步回滚,简化回滚流程。
边缘计算与微服务结合:
随着 5G、IoT 技术的发展,边缘计算(如边缘节点部署服务,减少网络延迟)需求增加,微服务将向 “边缘 + 云端” 混合架构演进;边缘微服务场景:IoT 设备数据处理(如工业传感器数据实时分析)、低延迟服务(如自动驾驶的实时决策);实现方式:通过 Kubernetes 边缘版(如 K3s、OpenYurt)在边缘节点部署轻量级微服务,与云端微服务协同工作(如边缘服务处理实时数据,云端服务存储历史数据和数据分析)。
智能可观测性:从 “被动监控” 到 “主动预测”:
传统监控是 “被动式”(故障发生后告警),未来将通过 AI 实现 “主动式预测”:
异常预测:基于机器学习模型(如 LSTM、ARIMA)分析历史 Metrics 数据(QPS、响应时间、CPU 使用率),预测未来可能出现的异常(如 “1 小时后订单服务 CPU 使用率将达 90%”),提前触发扩容;根因自动定位:通过图神经网络(GNN)分析服务依赖关系和链路数据,当故障发生时,自动定位根因(如 “支付服务超时是由于第三方支付接口延迟导致,而非自身故障”),减少人工排查时间;日志智能分析:通过自然语言处理(NLP)技术分析日志,自动提取故障关键词(如 “数据库连接超时”),生成故障报告,甚至自动触发修复脚本。
智能资源调度:从 “静态配置” 到 “动态优化”:
传统 Kubernetes 的资源调度是 “基于静态规则”(如 CPU 使用率 > 80% 扩容),未来将通过 AI 实现 “动态优化”:
精准扩容:基于业务场景(如 “双 11 前 30 分钟订单服务 QPS 将激增”)和历史数据,预测所需实例数,提前扩容,避免资源浪费;资源碎片优化:通过强化学习模型,优化容器在宿主机的调度策略,减少资源碎片(如将小内存容器调度到同一宿主机,释放大内存宿主机供大服务使用);成本优化:在云环境中,基于云厂商的价格波动(如阿里云的按量付费价格随时段变化),自动调度服务到低成本节点,降低云资源成本。
智能流量管理:从 “静态规则” 到 “动态适配”:
传统服务网格的流量管理是 “基于静态规则”(如 “10% 流量路由到新版本”),未来将通过 AI 实现 “动态适配”:
灰度发布智能决策:基于机器学习分析用户画像(如 “新用户对新版本的接受度更高”),动态调整流量比例(如 “新用户 100% 路由到新版本,老用户 10% 路由到新版本”);故障自动隔离:通过实时分析服务的错误率和响应时间,当某个服务实例出现异常时,自动将流量路由到健康实例,无需人工配置熔断规则;流量优先级调度:基于业务优先级(如 “支付请求优先级高于订单查询请求”),自动调整流量调度策略,确保核心业务的流量优先被处理。
智能安全防护:从 “被动防御” 到 “主动抵御”:
传统安全防护是 “被动式”(如 WAF 拦截已知攻击),未来将通过 AI 实现 “主动式抵御”:
异常访问检测:基于机器学习分析用户行为(如 “正常用户的下单频率是 1 小时 1 次,异常用户是 1 分钟 10 次”),自动识别恶意访问,触发限流或封禁;漏洞自动扫描:通过深度学习分析代码和依赖组件,自动发现潜在漏洞(如 “SQL 注入漏洞”“Log4j2 漏洞”),并生成修复建议;智能加密:基于 AI 分析数据的敏感程度(如 “银行卡号是高敏感数据,用户名是低敏感数据”),自动选择加密算法和密钥长度,平衡安全性和性能。
微服务可视化设计与生成:
低代码平台将提供 “微服务可视化设计器”:
服务边界设计:通过拖拽 “业务模块”(如订单、用户),自动生成服务边界和依赖关系图;API 设计:通过可视化表单定义 API 接口(如请求参数、响应参数、请求方法),自动生成 API 文档和代码(如 Spring Boot 接口代码);数据模型设计:通过拖拽 “数据实体”(如订单实体包含订单号、金额、状态),自动生成数据库表结构和 ORM 代码(如 MyBatis 映射文件);
生成的代码符合微服务规范(如包含服务注册发现、配置中心集成代码),可直接部署到 Kubernetes。
微服务集成可视化配置:
低代码平台将提供 “微服务集成配置器”,通过可视化配置实现服务间的集成,无需编写代码:
同步调用:配置 “服务 A 调用服务 B 的接口”,自动生成 Feign 客户端代码;异步通信:配置 “服务 A 发送事件到 Kafka,服务 B 消费事件”,自动生成 Kafka 生产者和消费者代码;第三方集成:配置 “调用支付宝支付接口”,自动生成 SDK 调用代码和参数映射逻辑。
微服务运维可视化:
低代码平台将提供 “微服务运维控制台”,通过可视化操作实现微服务的运维,无需掌握 Kubernetes 命令:
部署管理:可视化选择服务版本、实例数,点击 “部署” 按钮即可完成 Kubernetes 部署;监控查看:可视化展示服务的 QPS、响应时间、错误率,支持按时间维度筛选;故障处理:可视化触发 “重启服务”“扩缩容”“回滚版本” 等操作,简化运维流程。
行业化微服务模板:
低代码平台将提供 “行业化微服务模板”,针对电商、金融、物流等行业,预定义常见的微服务(如电商的订单服务、支付服务,金融的转账服务、对账服务);团队可基于模板快速定制(如修改订单服务的字段、添加支付服务的新支付方式),大幅缩短微服务的开发周期(如从 “3 个月” 缩短到 “2 周”)。
“道”:核心理念不可偏离
微服务的 “道” 是其存在的价值基石,脱离这些核心理念的 “微服务”,本质仍是 “分布式单体”,无法解决根本问题。
7.1.1 业务驱动是 “第一原则”
微服务的拆分、组件选择、技术栈决策,都必须围绕 “业务需求” 展开 ——业务需要什么,架构就适配什么,而非 “技术能做什么,架构就堆砌什么”。
若业务处于 “初创期”(用户量 < 10 万,迭代周期长),单体架构可能比微服务更高效,无需盲目拆分; 若业务处于 “增长期”(用户量百万级,高频迭代),需按 “业务域” 拆分粗粒度服务,优先解决 “扩展僵化” 问题; 若业务处于 “成熟期”(用户量千万级,高并发),再按 “性能需求、复用性” 拆分细粒度服务,引入服务网格、数据中台等组件。
脱离业务需求的 “技术炫技”(如初创公司引入 Istio、分库分表),只会增加系统复杂度,拖慢业务迭代。
7.1.2 自治是 “效率之源”
微服务的 “自治” 不仅是 “服务独立部署”,更是 “团队独立决策、端到端负责”——团队结构决定架构效率,这是康威定律的核心启示。
7.1.3 去中心化是 “韧性之基”
微服务的 “去中心化”(数据去中心化、治理去中心化),是为了避免 “单点依赖”,提升系统的抗风险能力 ——分布式系统的韧性,源于 “不把所有鸡蛋放在一个篮子里”。
7.2 微服务的 “术”:技术手段服务于理念
微服务的 “术”(技术组件、工具链)是支撑理念落地的 “脚手架”,但技术本身不是目的 ——选择技术的唯一标准,是能否高效实现核心理念。
7.2.1 组件化:用 “标准化组件” 解决 “分布式复杂性”
微服务的核心组件(服务注册发现、配置中心、API 网关等),不是孤立的 “技术插件”,而是协同解决 “分布式系统痛点” 的整体方案:
7.2.2 自动化:用 “工具链自动化” 降低 “运维成本”
微服务的运维复杂度,必须通过 “自动化工具链” 来抵消 ——自动化是微服务从 “能跑” 到 “能稳定跑” 的关键。
7.2.3 可观测性:用 “数据驱动” 替代 “经验判断”
微服务的 “可观测性三支柱”(Metrics、Logs、Traces),是让分布式系统 “透明化” 的 “眼睛”——没有可观测性,微服务就是 “黑盒”,故障排查、性能优化都无从谈起。
7.3 微服务落地的关键启示:从 “实践” 中提炼的 “避坑指南”
微服务落地不是 “一帆风顺” 的,无数团队在 “拆分、运维、协作” 中踩过坑 —— 以下启示源于大量实践,可帮助团队少走弯路。
7.3.1 不盲目跟风:“适合的才是最好的”
微服务不是 “银弹”,它有明确的适用场景 ——只有当业务复杂度、团队规模达到阈值,微服务的收益才会大于成本。
7.3.2 演进式拆分:“小步快跑,持续优化”
微服务拆分不是 “一次性工程”,而是 “持续迭代的过程”——初期拆粗、后期拆细,比 “一步到位” 更安全。
微服务的落地,本质是 “团队能力的转型”——没有 “能自主开发、自主运维” 的团队,再好的技术组件也无法发挥价值。
7.3.4 重视基础建设:“早建监控,早避大坑”
微服务的 “基础建设”(可观测性、自动化工具链),不是 “后期优化项”,而是 “前期必选项”——基础建设不到位,业务跑起来也会 “心惊胆战”。
7.4 全文总结:微服务是 “架构选择”,更是 “业务选择”
回顾微服务的演进脉络(从单体到 SOA,再到微服务),不难发现:每一次架构变革,都是 “业务需求” 驱动 “技术创新” 的结果—— 单体架构适配 “简单业务、小团队”,SOA 适配 “企业级业务、跨部门协作”,微服务适配 “互联网业务、高频迭代、高并发”。
开发自治:让订单团队自主选择 Java 技术栈,搜索团队自主选择 Go 技术栈,避免 “统一技术栈” 限制创新;运维自治:让业务团队负责服务的监控、告警、故障排查,避免 “开发甩锅运维” 的协作内耗;决策自治:让团队自主决定需求优先级(如订单团队可优先排期 “双 11 订单预创建” 功能),无需等待跨部门审批。
只有实现 “团队自治”,才能将微服务的 “敏捷迭代” 从理念转化为实践 —— 一个能自主决策、快速响应的团队,比一套复杂的技术组件更能驱动业务增长。
数据去中心化:订单数据存于订单库,用户数据存于用户库,避免 “一个数据库故障导致全系统瘫痪”;治理去中心化:配置中心集群部署,服务网格控制平面多节点冗余,避免 “一个组件故障导致全链路中断”;流量去中心化:API 网关多节点部署,核心服务多实例运行,通过负载均衡分散流量,避免 “单点过载”。
去中心化不是 “无中心”,而是 “多中心、互备份”,它让系统在面对网络分区、组件故障时,仍能保持核心业务可用 —— 这是微服务相比单体架构的核心优势之一。
服务注册发现 + API 网关:解决 “服务地址动态变化” 与 “统一入口管理” 的问题,支撑 “服务自治”;配置中心 + 分布式事务:解决 “多环境配置管理” 与 “跨服务数据一致性” 的问题,支撑 “业务驱动的迭代”;监控 + 链路追踪 + 日志聚合:解决 “分布式故障难排查” 的问题,支撑 “运维自治”。
选择组件时,需避免 “堆砌组件”—— 例如中小规模系统(服务数 < 50),用 Nacos 同时实现服务注册发现与配置中心,比单独部署 Eureka+Apollo 更高效;只有当系统规模突破阈值(服务数 > 100),才需要引入服务网格等重量级组件。
CI/CD 流水线(GitLab CI+ArgoCD):将 “代码提交→部署上线” 的周期从 “天级” 压缩到 “小时级”,支撑 “敏捷迭代”;容器编排(Kubernetes):实现 “服务扩缩容、故障恢复” 的自动化,避免 “手动操作失误”,支撑 “运维自治”;告警自动化(Prometheus+Alertmanager):将 “人工监控” 变为 “自动告警”,故障发现时间从 “小时级” 缩短到 “分钟级”,支撑 “高可用”。
自动化不是 “取代人”,而是 “让人聚焦高价值工作”—— 运维工程师无需重复执行 “部署、扩缩容” 等机械操作,可将精力投入 “基础设施优化、故障根因分析”;开发工程师无需等待 “运维排期”,可自主完成服务发布 —— 这是自动化的核心价值。
Metrics:用 “量化数据”(QPS、响应时间)监控服务健康状态,提前识别 “资源不足”“流量峰值” 等风险;Logs:用 “结构化日志”(含 trace-id、服务名)记录服务运行细节,快速定位 “代码异常”“配置错误” 等问题;Traces:用 “链路数据”(Span 耗时、调用关系)分析 “跨服务延迟”,定位 “慢查询”“冗余调用” 等性能瓶颈。
构建可观测性体系时,需避免 “过度采集”—— 例如非核心服务,无需采集全量 Trace 数据,只需保留错误链路的 Trace;只有核心服务(订单、支付),才需要全量采集数据,确保故障可追溯。
若业务简单(如单功能工具类应用)、团队规模小(<5 人),单体架构的开发效率、运维成本更有优势;若业务复杂(多业务域、高频迭代)、团队规模大(>10 人),微服务的 “解耦、自治” 优势才能显现。
避免 “为了微服务而微服务”—— 不少初创公司在用户量不足 1 万时就拆分 10 个服务,最终因运维成本过高、团队协作低效,又被迫合并回单体,得不偿失。
初期(业务验证期):拆分为 2-3 个粗粒度服务(如 “用户商品服务”“订单支付服务”),降低开发、运维成本;中期(业务增长期):按 “业务域” 拆分为 5-8 个服务(如 “用户服务”“商品服务”“订单服务”),解决 “扩展僵化” 问题;后期(业务成熟期):按 “性能、复用性” 拆分为 10 + 个服务(如 “商品搜索服务”“促销服务”),满足高并发需求。
演进式拆分的核心是 “保留调整空间”—— 每个服务的边界不是 “写死的”,而是随着业务变化持续优化,例如当 “商品评价” 功能用户量激增时,再从 “商品服务” 中拆分出 “商品评价服务”。
技能转型:让开发工程师学习 Docker、K8s 基础运维技能,让运维工程师理解业务逻辑,打破 “开发不懂运维、运维不懂业务” 的壁垒;流程转型:推行 “敏捷开发”“每日站会”“迭代复盘”,让团队快速响应需求变化,及时解决协作问题;文化转型:建立 “谁开发、谁负责” 的责任文化,避免 “开发甩锅运维”“运维抱怨开发” 的内耗,形成 “共同对业务负责” 的共识。
团队能力的转型,比技术组件的部署更难,但也更关键 —— 一个具备 DevOps 能力的团队,即使使用简单的技术组件,也能实现微服务的高效运转;反之,若团队能力不匹配,即使部署了 Istio、Kubernetes,也会因运维不善导致系统频繁故障。
项目启动初期:同步搭建 Prometheus+Grafana 监控、ELK 日志聚合,确保服务上线后能 “看到” 运行状态;服务拆分初期:同步搭建 CI/CD 流水线、Kubernetes 集群,确保服务能 “自动化部署、扩缩容”;核心服务上线前:同步完成 “熔断、降级、限流” 配置,确保服务能 “抗住流量峰值、隔离故障”。
基础建设的投入,短期内看似增加了成本,但长期来看能大幅减少 “故障排查时间”“人工操作成本”—— 例如一个完善的监控体系,能让故障发现时间从 “2 小时” 缩短到 “5 分钟”,避免因故障导致的业务损失。
7.3.3 团队能力先行:“DevOps 转型比技术选型更重要”
微服务的落地,本质是 “团队能力的转型”——没有 “能自主开发、自主运维” 的团队,再好的技术组件也无法发挥价值。
技能转型:让开发工程师学习 Docker、K8s 基础运维技能,让运维工程师理解业务逻辑,打破 “开发不懂运维、运维不懂业务” 的壁垒; 流程转型:推行 “敏捷开发”“每日站会”“迭代复盘”,让团队快速响应需求变化,及时解决协作问题; 文化转型:建立 “谁开发、谁负责” 的责任文化,避免 “开发甩锅运维”“运维抱怨开发” 的内耗,形成 “共同对业务负责” 的共识。
团队能力的转型,比技术组件的部署更难,但也更关键 —— 一个具备 DevOps 能力的团队,即使使用简单的技术组件,也能实现微服务的高效运转;反之,若团队能力不匹配,即使部署了 Istio、Kubernetes,也会因运维不善导致系统频繁故障。
7.3.4 重视基础建设:“早建监控,早避大坑”
微服务的 “基础建设”(可观测性、自动化工具链),不是 “后期优化项”,而是 “前期必选项”——基础建设不到位,业务跑起来也会 “心惊胆战”。
7.4 全文总结:微服务是 “架构选择”,更是 “业务选择”
回顾微服务的演进脉络(从单体到 SOA,再到微服务),不难发现:每一次架构变革,都是 “业务需求” 驱动 “技术创新” 的结果—— 单体架构适配 “简单业务、小团队”,SOA 适配 “企业级业务、跨部门协作”,微服务适配 “互联网业务、高频迭代、高并发”。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...











