

Google DeepMind研究团队在《自然》期刊发表的最新研究成果,标志着人工智能发展史上一个重大转折点的到来。该团队开发的DiscoRL系统首次实现了让AI智能体通过自身经验自主发现强化学习算法,而非依赖人类设计师的预设规则。这一突破不仅在Atari基准测试中全面超越现有算法,更在从未接触过的复杂任务中展现出惊人的泛化能力,为未来AI系统的自主进化开辟了全新路径。
传统强化学习算法的开发过程往往需要研究人员经过数年甚至数十年的反复试验、理论推导和实验验证,才能设计出有效的学习规则。而DiscoRL系统则颠覆了这一模式:多个智能体在不同环境中并行交互学习,系统通过观察这些智能体的表现自动优化学习规则,最终发现了性能超越人工设计的算法。

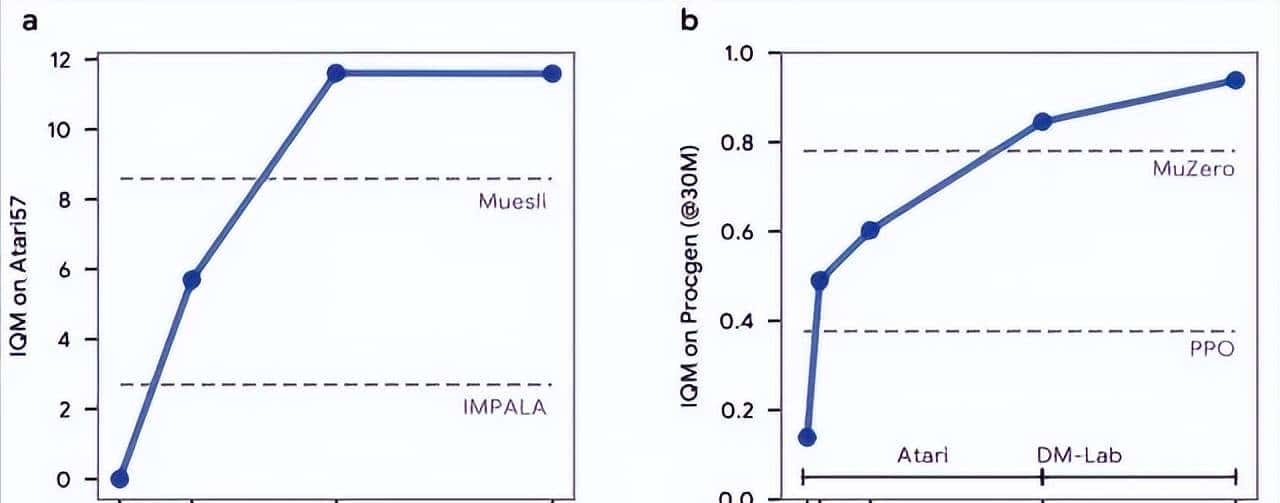
在标准的57个Atari游戏测试中,DiscoRL发现的Disco57规则达到了13.86的四分位数平均值,不仅超越了包括MuZero和Dreamer在内的所有现有强化学习算法,而且在计算效率方面也显著优于当前最先进的系统。更令人印象深刻的是,该系统在完全陌生的环境中同样表现卓越:在ProcGen二维游戏、Crafter基准测试以及NetHack竞赛中均取得了领先成绩。
双重优化机制的技术突破
DiscoRL系统的核心创新在于其独特的双重优化架构,这种设计巧妙地解决了让机器自主发现学习规则的根本挑战。在智能体层面,系统采用Kullback-Leibler散度来衡量智能体输出与目标之间的差距,确保训练过程的稳定性。每个智能体会产生策略决策、观测预测和动作预测三类输出,元网络则为这些输出生成相应的学习目标,指导智能体的参数更新。
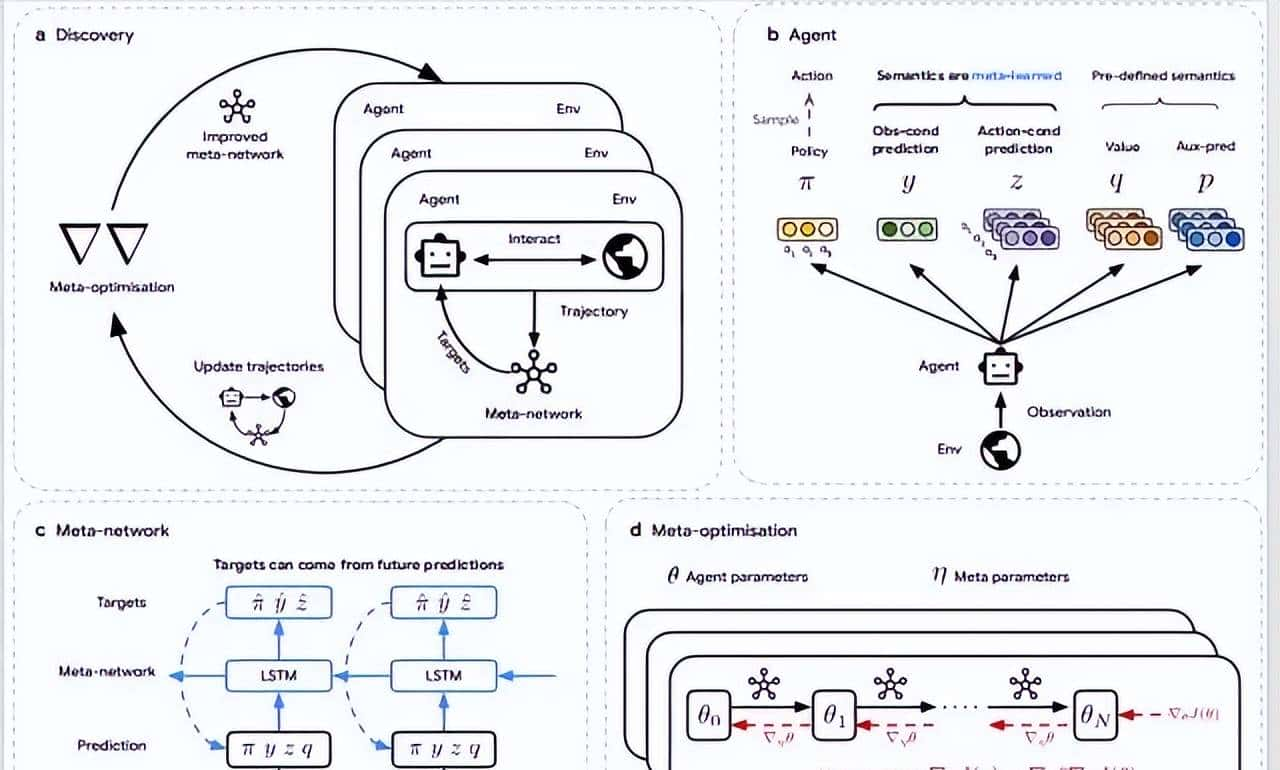
图|智能体自主发现 RL 算法的全过程:(a) 发现过程:多个智能体在不同环境中并行交互与训练,遵循由元网络定义的学习规则;元网络在此过程中不断优化,以提升整体表现;(b) 智能体结构:每个智能体输出策略(π)、观测预测(y)、动作预测(z)、动作价值(q)与辅助策略预测(p),其中 y 与 z 的语义由元网络确定;(c) 元网络结构:元网络接收智能体的输出轨迹及环境奖励与终止信号,生成针对当前与未来时刻的目标预测;智能体据此最小化预测误差进行更新;(d) 元优化过程:通过对智能体更新过程的反向传播计算元梯度,优化元参数,以最大化智能体在环境中的累计回报。
在元优化层面,系统让多个智能体在不同环境中独立学习,元网络根据所有智能体的整体表现计算元梯度,并相应调整自身参数。这种设计的巧妙之处在于智能体参数会定期重置,使得学习规则能够在有限时间内快速提升表现,避免了传统方法中可能出现的局部最优问题。
元梯度的计算过程结合了智能体更新过程与标准强化学习目标的优化,具体通过反向传播算法和优势行动者-评论家方法实现。系统还配备了专门用于元学习阶段的价值函数进行性能评估,确保了整个发现过程的可靠性和效率。
这种双重优化机制的设计哲学体现了一个重大洞察:要让机器自主发现有效的学习规则,仅仅依靠单一层面的优化是不够的,必须在智能体学习和规则发现两个层面同时进行协调优化。
泛化能力的惊人表现
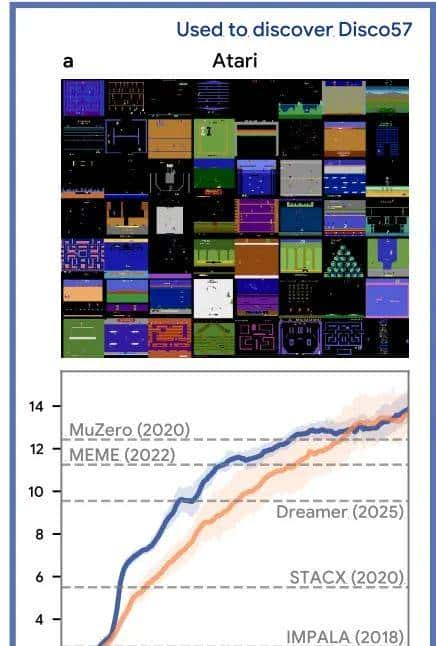
图|Disco57 在 Atari 实验中的评估结果。横轴表明环境交互步数(以百万为单位),纵轴表明在基准测试中 IQM 得分。
DiscoRL系统最令人瞩目的特性是其出色的泛化能力,这一点通过多个独立基准测试得到了充分验证。在16个ProcGen二维游戏中,Disco57规则超越了所有已发表的方法,包括在该领域具有标杆地位的MuZero和PPO算法。在Crafter基准测试中,系统同样展现出了强劲的竞争力,而在NetHack NeurIPS 2021挑战赛中获得第三名的成绩更是证明了其在复杂策略游戏中的潜力。
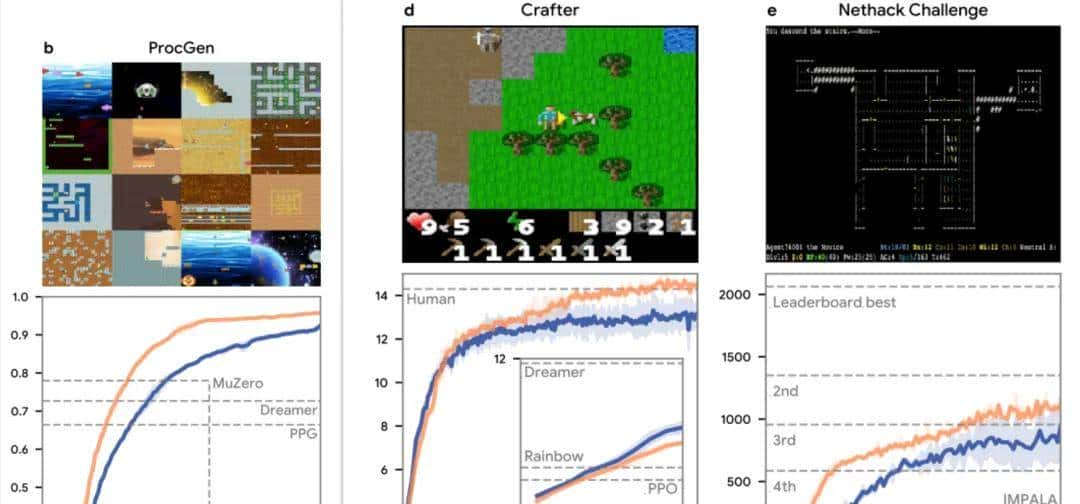
图|Disco57 在 ProcGen、Crafter、 NetHack NeurIPS 中的评估结果。
值得注意的是,这些测试环境在系统的训练过程中从未出现过,这意味着DiscoRL真正实现了从已知环境到未知环境的知识迁移。这种泛化能力的实现机制可能源于系统在发现过程中接触了足够多样化的环境,从而学习到了更加通用的学习原理。
研究团队进一步验证了环境多样性对发现效果的影响。基于Atari、ProcGen和DMLab-30三个基准的103个环境,他们发现了另一种强化学习规则Disco103。实验结果证实,用于发现的环境越复杂、越多样,所发现的强化学习规则就越强劲、越具泛化能力。这一发现揭示了一个重大规律:算法发现的质量直接取决于训练数据的多样性和计算资源的投入。
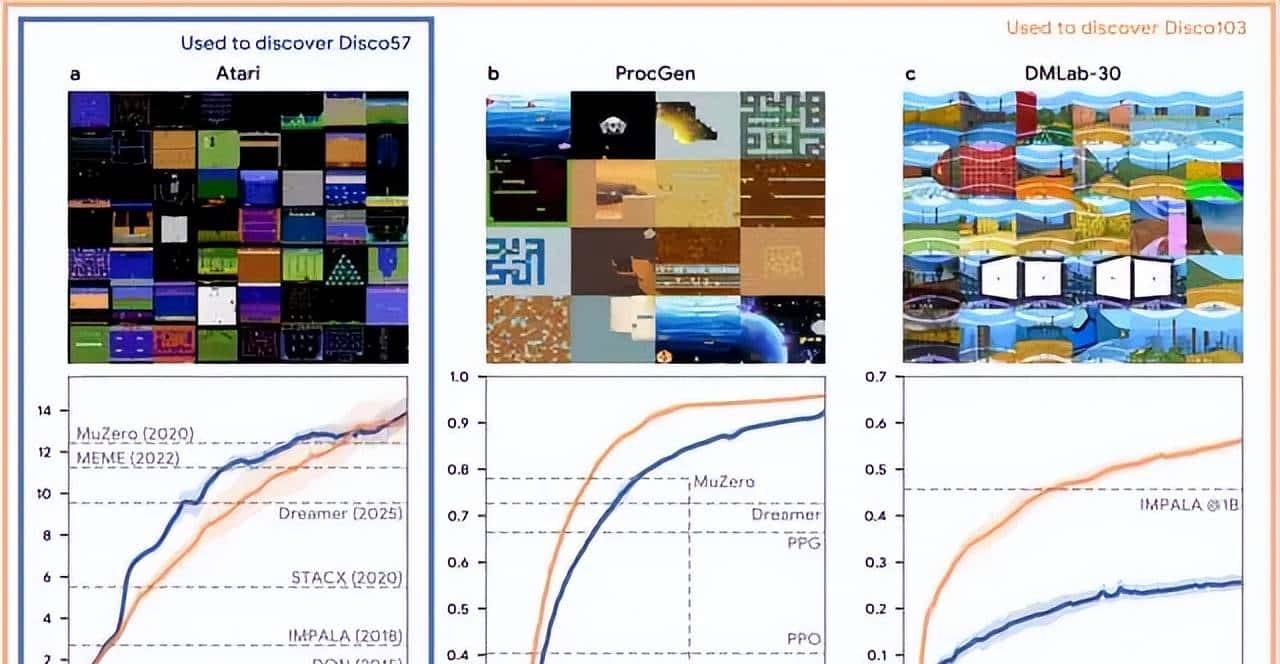
图|Disco103 与 Disco57 在一样测试中的对比结果。蓝线(Disco57)表明在 Atari 基准上发现的规则,橙线(Disco103)表明在 Atari、ProcGen 和 DMLab-30 基准上共同发现的规则。
在Crafter基准测试中,Disco103甚至达到了人类水平的表现,在Sokoban游戏中也接近了MuZero的最先进性能。这些结果不仅验证了系统的技术可行性,更重大的是证明了机器发现的算法的确 能够在某些方面达到甚至超越人类设计的水平。
效率革命与未来展望
从开发效率的角度来看,DiscoRL系统展现出了相比传统方法的显著优势。研究团队发现,最优表现的Disco57规则在每个Atari游戏约6亿步内就能被发现,这相当于在57个游戏上进行3轮实验。相比之下,传统的人工设计强化学习算法往往需要研究人员进行数百次甚至数千次实验,投入大量的时间和人力资源。
图|DiscoRL 最佳规则在每款游戏约6亿步内被发现;随着用于发现的训练环境数量的增加,DiscoRL 在未见过的 ProcGen 基准测试上的性能也变得更强。
这种效率提升的意义不仅体目前成本节约上,更重大的是为算法创新开辟了新的可能性。当算法发现过程能够自动化进行时,研究人员就能够将更多精力投入到更高层次的问题探索中,而不是陷入繁琐的参数调优和规则设计工作。
实验数据还显示,随着用于发现的环境数量增加,DiscoRL在未见过环境中的表现也随之提升。这种可扩展性特征表明,未来的算法发现系统可以通过简单地增加训练环境和计算资源来持续改善性能,形成一种类似于深度学习中”规模定律”的发展模式。
研究团队明确指出,这一发现预示着未来高级AI系统的强化学习算法设计可能将完全由机器主导,不再需要人类的直接参与。这种转变将从根本上改变AI研究的模式,从人类驱动的算法创新转向机器驱动的自主发现。
不过,这一技术突破也带来了深刻的思考。当机器能够自主发现和改善学习算法时,我们如何确保这些算法的安全性和可控性?如何理解和解释机器发现的复杂规则?这些问题的答案将直接影响未来AI技术的发展方向和应用前景。
研究团队坦诚地承认,虽然这一发现令人振奋并展现了巨大的学术潜力,但当前社会可能还没有做好充分准备来迎接这项技术。这种担忧并非多余:当AI系统获得了自主改善学习能力的能力时,其发展轨迹可能会超出人类的预期和控制范围。
DiscoRL的成功不仅仅是一项技术突破,更是AI发展历程中的一个重大里程碑。它标志着我们正在进入一个新的时代,在这个时代中,机器不仅能够学习现有的知识,还能够创造新的学习方法。这种元学习能力的实现,为通用人工智能的最终实现提供了重大的技术基础。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











