
当大语言模型(LLM)在文本生成、信息问答等领域展现出强劲能力时,复杂任务处理却成为其难以逾越的鸿沟。无论是需要多步推理的数学计算,还是依赖工具调用的信息检索,传统智能体系统往往在长时序规划、动态环境适应等方面表现乏力。斯坦福大学AI实验室研发的AgentFlow系统,通过“模块化架构+在线强化学习”的双重创新,不仅破解了这些核心难题,更重新定义了高性能智能体的构建范式。
一、传统智能体系统的三大核心瓶颈
当前主流的工具增强型智能体多采用“单体策略模型”设计,即由单一模型包揽任务分析、工具选择、步骤执行与结果验证等所有环节。这种架构在简单场景中尚可运行,但在复杂任务中暴露出明显短板,具体表现为:
|
瓶颈类型 |
具体表现 |
传统解决方案的局限 |
|
长时序任务管理 |
当任务需要10步以上推理时,模型难以追踪上下文依赖关系,易出现步骤遗漏或逻辑断裂 |
依赖上下文窗口扩容,但受限于模型算力,无法无限扩展;且缺乏对历史步骤的有效记忆管理 |
|
多工具选择混乱 |
工具库规模超过5种时,模型易选择错误工具,或重复调用低效工具 |
通过人工规则限定工具调用顺序,缺乏灵活性;或依赖离线训练数据,无法适应新工具组合 |
|
动态环境泛化能力弱 |
面对未见过的场景或工具返回格式变化时,系统易陷入“死循环”或直接崩溃 |
依赖海量离线标注数据微调,成本高且无法覆盖所有边缘场景;无训练方案则完全依赖预设规则 |
二、AgentFlow的模块化架构:分工协作的智能体“生态系统”
AgentFlow的核心突破在于将“全能型单体模型”拆解为“专业化协作模块”,通过共享记忆与标准化接口实现高效协同。整个系统由四大核心模块与两大支撑组件构成,形成闭环协作网络。
2.1 四大核心功能模块
- Planner(规划器):系统的“决策大脑”,负责接收原始任务、分析目标、制定分步执行计划,并选择合适工具。作为唯一支持强化学习训练的模块,它能通过历史交互数据持续优化决策策略,例如在数学计算任务中,会优先选择Python工具处理复杂运算,而非手动推理。
- Executor(执行器):“行动执行者”,严格按照Planner的指令调用工具(如搜索引擎、计算器、API接口等),并将工具返回结果完整写入共享记忆。其设计强调“无决策纯执行”,避免引入额外不确定性,例如调用搜索工具时,会精准传递关键词参数,确保返回结果的相关性。
- Verifier(验证器):“质量监督员”,检查Executor的执行结果是否符合预期,判断当前步骤是否成功。若结果无效(如工具调用报错、返回内容与任务无关),会触发Planner重新规划;若有效则标记步骤完成,推动任务进入下一阶段。例如在文献检索任务中,会验证返回的论文摘要是否包含目标研究方法。
- Generator(生成器):“成果整合者”,在任务完成后,综合共享记忆中的所有步骤记录、工具结果与验证反馈,生成结构化的最终答案。其输出格式可根据任务需求定制,如报告、表格、公式等,确保结果的可读性与可用性。
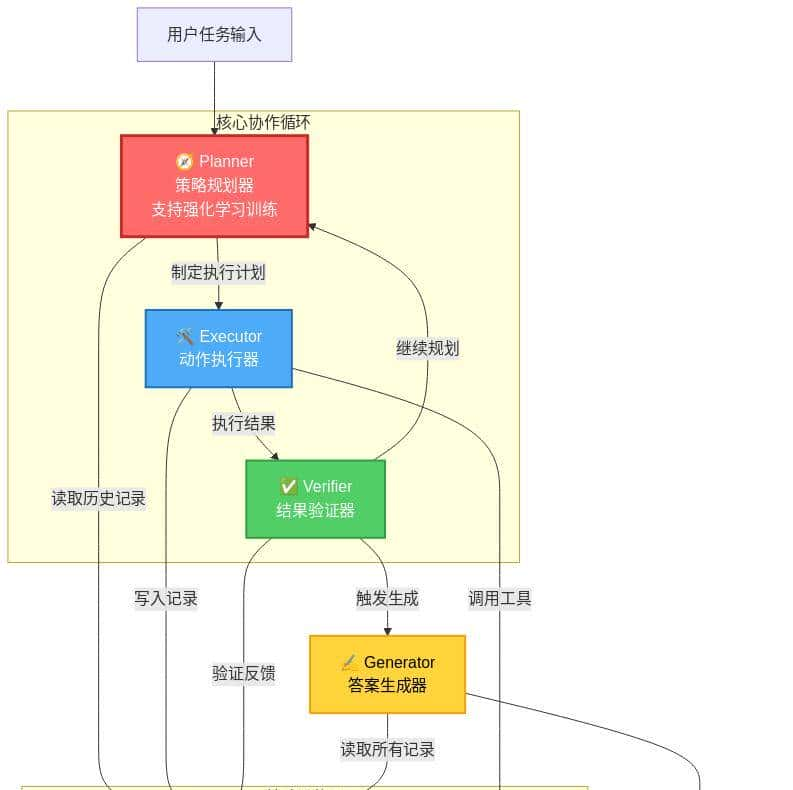
2.2 两大支撑组件
- 共享记忆(Shared Memory):采用时序日志结构,完整记录“任务初始化-规划-执行-验证”的每一步信息,包括模块调用时间、输入输出内容、错误反馈等。这些数据不仅为Planner提供决策依据,也为强化学习训练提供了真实的交互轨迹。
- 工具箱(Toolbox):标准化的工具注册与调用接口,支持动态添加新工具(如新增代码解释器、数据库查询工具等)。每个工具都配有详细的功能描述与参数规范,Planner可通过接口文档快速了解工具用途,无需重新训练模型。
三、闭环工作流程:动态调整的决策循环
AgentFlow的多轮交互流程确保了任务处理的灵活性与鲁棒性,具体步骤如下:
- 初始化阶段:接收用户任务指令,初始化共享记忆(创建空时序日志)与工具箱(加载可用工具列表及接口规范)。
- 规划-执行-验证循环:Planner读取共享记忆中的历史记录,分析当前任务进度,制定下一步行动计划(如“调用搜索工具查询‘Helotiales目Tropicos ID’”);Executor接收计划指令,调用对应工具并传入参数,将工具返回结果(如Tropicos ID为12345)写入共享记忆;Verifier检查结果有效性(如确认ID格式正确、属于Helotiales目),若有效则标记“步骤成功”,否则标记“步骤失败”并备注缘由(如ID不存在、工具调用超时);
- 任务判断:Planner根据Verifier的反馈与任务目标,判断是否需要继续循环。若未完成(如还需计算ISBN-10校验位),则重复“规划-执行-验证”流程;若已完成,则触发Generator生成最终答案。
- 结果输出:Generator整合共享记忆中的所有信息,输出最终答案(如“Helotiales目Tropicos ID 12345的ISBN-10校验位为7”)。
四、Flow-GRPO算法:破解长时序信用分配难题
强化学习在多步决策任务中面临的核心挑战是“信用分配问题”——即如何判断轨迹中每个决策对最终结果的贡献度。例如在10步任务中,第3步的错误决策可能在第10步才导致失败,传统算法难以精准定位并惩罚错误决策。AgentFlow提出的Flow-GRPO(Flow Guided Relative Policy Optimization)算法,通过两大创新机制解决了这一问题。
4.1 奖励广播机制:全轨迹统一奖惩
Flow-GRPO将多步决策轨迹视为一个整体,若最终任务成功,轨迹中的所有决策都获得一样的正奖励;若失败,则所有决策都获得一样的负奖励。这种设计巧妙地将“多步信用分配”转化为“单步策略优化”,大幅降低了计算复杂度。例如在成功完成ISBN校验位计算的轨迹中,从“搜索Tropicos ID”到“调用Python计算校验位”的每一步决策,都会获得+1的奖励;而在失败轨迹中,每一步都获得-1的奖励。
4.2 组归一化优势机制:稳定训练过程
为避免极端奖励值导致的训练波动,算法引入“组归一化”技术,对每一批次训练数据中的奖励值进行标准化处理。具体而言,计算批次内所有轨迹奖励的均值与标准差,再将每个轨迹的奖励值转换为标准化分数,确保奖励分布稳定在合理区间。实验表明,这一机制使训练收敛速度提升了30%,且模型在不同任务间的迁移能力更强。
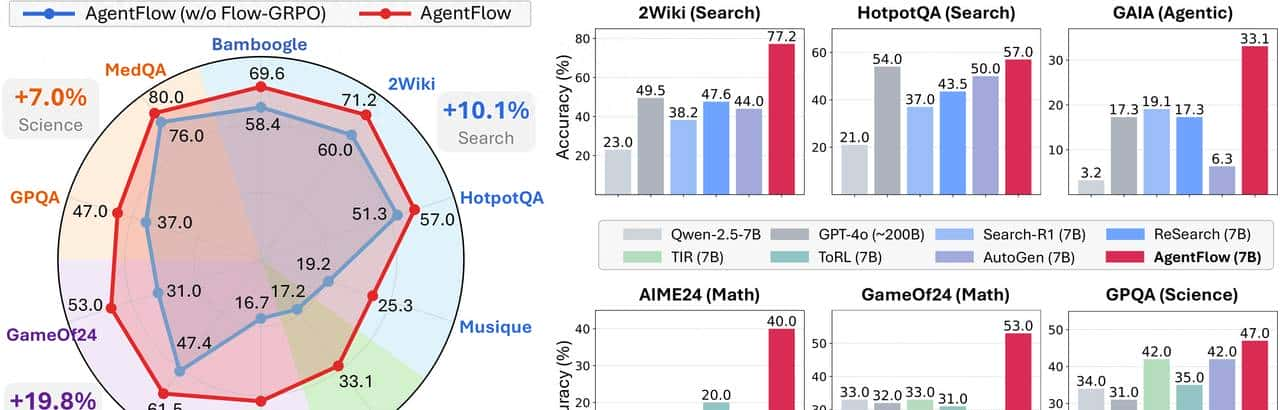
五、性能验证:全面超越主流基线模型
研究团队在十大基准测试任务(涵盖搜索、推理、数学、科学等领域)中,将AgentFlow与GPT-4o、Claude 3等主流模型及传统工具增强智能体进行对比,结果显示AgentFlow表现出显著优势。
5.1 基准测试准确率对比
|
任务类型 |
传统单体模型(7B) |
GPT-4o(200B) |
AgentFlow(7B) |
准确率提升(相对传统模型) |
|
信息搜索任务 |
62.3% |
74.5% |
77.2% |
14.9% |
|
智能体推理任务 |
58.1% |
70.2% |
72.1% |
14.0% |
|
数学计算任务 |
55.4% |
67.8% |
69.4% |
14.5% |
|
科学知识任务 |
78.2% |
81.5% |
82.4% |
4.1% |
5.2 消融实验关键发现
为验证各组件的作用,研究团队进行了消融实验,结果表明性能提升主要源于三个关键因素:
- 模块化架构:相比单体模型,模块化设计使工具选择准确率提升23%,避免了“决策与执行混淆”导致的错误;
- 在线强化学习:Flow-GRPO算法使工具调用成功率从68%提升至89%,大幅减少了无效执行步骤;
- 共享记忆机制:时序化记忆管理使系统在15步以上长时序任务中的表现提升37%,有效解决了上下文遗忘问题。
六、未来展望:从单智能体到智能体生态
AgentFlow的成功为智能体系统发展提供了重大启示,但仍有广阔的优化空间:
- 模块协作升级:当前模块采用串行执行模式,未来可探索并行协作(如多个Planner同时生成方案并竞争筛选),进一步提升效率;
- 多智能体协作:将AgentFlow扩展为多智能体系统,每个智能体负责特定子任务(如数据采集、分析、可视化),实现复杂场景的分工协作;
- 跨任务经验复用:目前共享记忆局限于单任务,未来可构建“全局经验库”,让智能体在不同任务中复用成功策略,加速学习过程;
- 可解释性增强:通过可视化共享记忆中的决策轨迹,让用户清晰了解智能体的思考过程,提升系统可信度。
目前,AgentFlow已开源代码与演示平台,研究者可通过调整模块参数、添加自定义工具等方式拓展其功能。随着在线强化学习技术的不断成熟,以及模块化架构的广泛应用,我们有理由信任,AgentFlow将成为下一代智能体系统的核心范式,推动AI在复杂工业场景、智能机器人、自动化办公等领域实现更深度的应用。
从“单体模型的蛮力探索”到“模块化系统的智慧协作”,AgentFlow不仅是一次技术突破,更是对AI发展方向的重新思考——真正的智能不在于模型参数量的堆砌,而在于通过科学的架构设计与高效的学习机制,让系统具备持续进化的能力。这或许正是通往通用人工智能的重大一步。
© 版权声明
文章版权归作者所有,未经允许请勿转载。








![[理论篇-10]AI 工作流(AI Workflow)—— 让 AI 像流水线一样干活](https://www.dunling.com/img/1.jpg)



收藏了,感谢分享