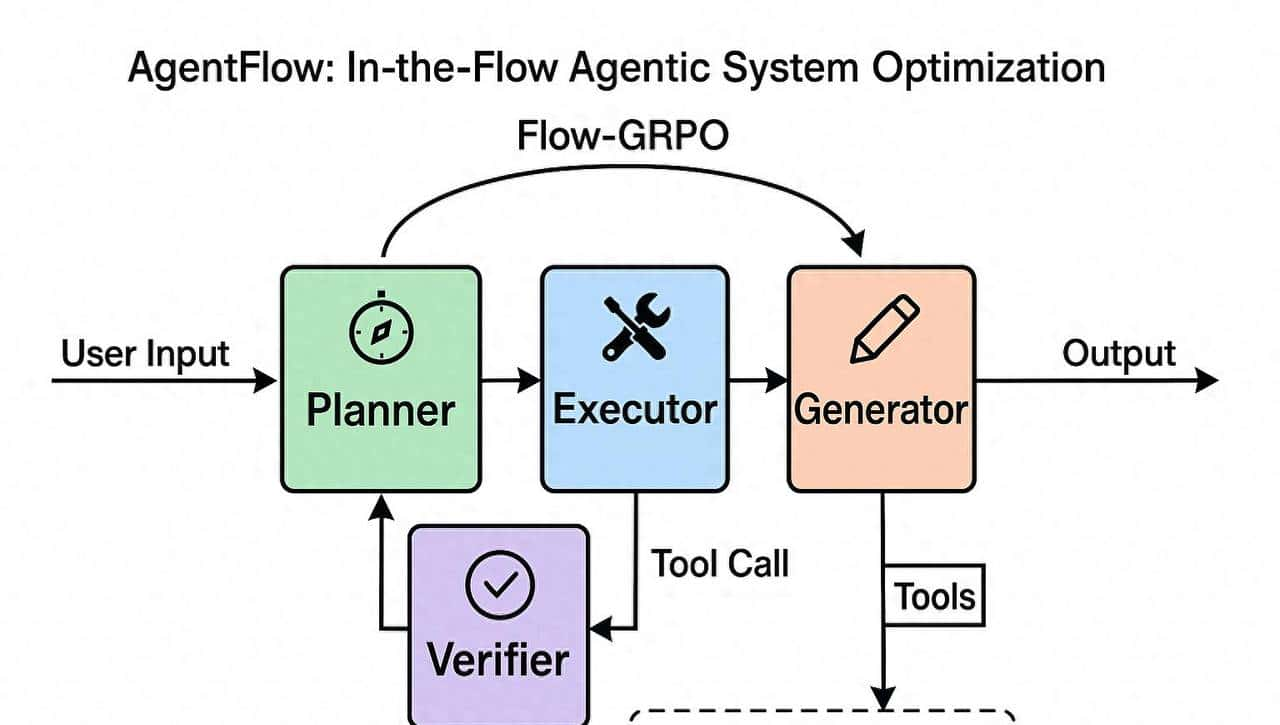
GitHub 项目 lupantech/AgentFlow 是一个由 Stanford、UW、以及上海 AI 团队联合推出的多智能体(multi-agent)系统优化框架,全名叫 AgentFlow: In-the-Flow Agentic System Optimization。
它的核心目标是:
让智能体(agents)在使用工具、规划任务、推理与验证等复杂场景中,能够通过强化学习(RL)在真实交互流程中自我优化。
一、AgentFlow 的总体架构原理
AgentFlow 的核心思想是 “模块化多智能体 + 在线优化 (Flow-GRPO)”。
它不像传统做法那样只训练一个大语言模型(LLM)去做一切,而是拆解为 四个协作模块,每个模块都是一个独立的 agent:
|
模块 |
功能 |
示例 |
|
Planner(规划者) |
负责分解任务、制定行动计划(下一步用哪个工具、怎么操作) |
“先搜索资料 → 再计算 → 再总结” |
|
Executor(执行者) |
负责调用工具(搜索引擎、Python解释器等)完成实际操作 |
调用 google_search() 或运行一段 Python 代码 |
|
✅ Verifier(验证者) |
负责检查执行结果的正确性、过滤错误 |
验证返回结果是否合理 |
|
✍️ Generator(生成者) |
负责生成最终输出文本(总结、报告、答案) |
将多步结果整理成最终回复 |
这些模块通过一个共享的记忆 (memory) 与消息通道 (flow) 协同工作。
二、核心算法:Flow-GRPO
AgentFlow 的名字来自它的核心优化算法 Flow-based Group Refined Policy Optimization (Flow-GRPO)。
这是一种强化学习(RL)变体,用于在“智能体执行任务的整个流程中”优化策略。
原理简述:
- 传统问题:
- 普通 LLM + tool calling 方法中,训练只发生在静态数据(offline)。
- 智能体无法在实际交互中学习或改善。
- AgentFlow 的改善:
- 把“智能体整个任务执行流(Flow)”视为一个序列化的强化学习过程。
- 每个模块(Planner、Executor、Verifier、Generator)在执行时会生成一条轨迹(trajectory)。
- 通过 reward signal(如任务是否成功、答案准确度、奖励稀疏信号)对整个轨迹进行优化。
- Group Refined Policy Optimization:
- 不是单智能体优化,而是“群体优化 (Group-based)”。
- 多个模块的策略一起被更新,利用跨模块的信息协同提升整体表现。
因此,Flow-GRPO 的核心优势是:
它能让智能体在执行真实任务(带工具调用的推理过程)时在线地优化自己的行为策略,而不是依赖静态标注数据。
三、模块之间的交互流程
下图(项目 README 中的 framework.png)展示了整体架构:
用户输入 → Planner → Executor → Verifier → Generator → 输出
↑ ↓
工具调用 ← Flow Memory
- 所有模块共享一个 “Flow Memory”,记录每轮的输入、输出、上下文状态。
- 规划者根据历史记录生成下一步计划。
- 执行者调用外部工具完成动作。
- 验证者检查并修正输出。
- 生成者整理最终答案。
- Flow-GRPO 在整个流上执行强化学习,更新 Planner 的策略参数。
四、多工具协同 (Multi-Tool Integration)
AgentFlow 内置了多种工具接口,可以通过 Executor 模块调用:
|
工具名称 |
功能 |
|
python_coder |
执行 Python 代码,支持计算/绘图 |
|
google_search |
搜索网页内容 |
|
wikipedia_search |
调用维基百科 |
|
web_search |
通用网页爬取 |
|
base_generator |
文本生成模型(默认 Qwen2.5-7B) |
这种设计让智能体具备“动态选工具 + 推理 + 校验”的综合能力。
五、训练机制与数据集
AgentFlow 使用两类数据集混合训练:
|
数据集 |
用途 |
|
FlashRAG_datasets (NQ) |
搜索类任务(agentic reasoning) |
|
DeepMath-103K |
数学推理任务 |
训练管线:
python data/get_train_data.py # 下载训练数据
python data/aime24_data.py # 下载验证数据
bash train/serve_with_logs.sh # 启动服务
bash train/train_with_logs.sh # 开始训练
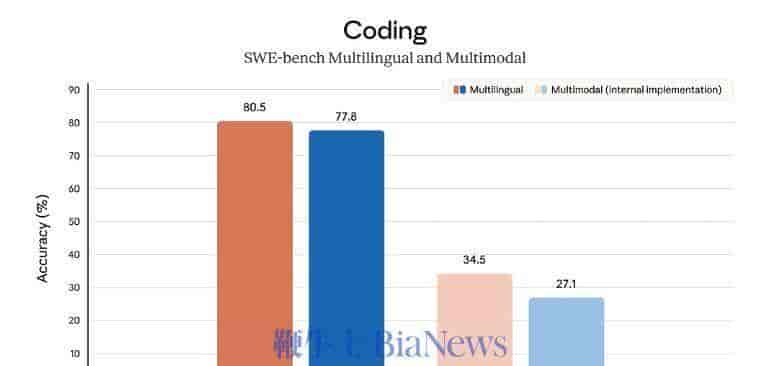
六、性能成果
在论文与 README 中,AgentFlow 使用 Qwen2.5-7B-Instruct 作为骨干模型,在 10 个任务基准上超越主流模型:
|
领域 |
提升幅度 |
|
搜索类任务 |
+14.9% |
|
Agentic 推理任务 |
+14.0% |
|
数学任务 |
+14.5% |
|
科学任务 |
+4.1% |
甚至超过了 GPT-4o (~200B 参数) 在部分推理任务的表现。
七、快速运行示例
from agentflow.agentflow.solver import construct_solver
llm_engine_name = "dashscope" # Qwen-2.5-7B 引擎
solver = construct_solver(llm_engine_name=llm_engine_name)
output = solver.solve("What is the capital of France?")
print(output["direct_output"])
输出:
Paris
八、适用场景
AgentFlow 特别适用于:
- 多步推理与规划(reasoning + planning)
- 复杂工具调用(Tool-Augmented Reasoning)
- 多模态长程任务(如科研问答、诊断推荐)
- 多智能体协作学习(协同强化学习)
九、项目本质总结
|
层面 |
说明 |
|
类型 |
多智能体 + 在线强化学习 框架 |
|
目标 |
让智能体在真实工具调用中自我优化 |
|
技术核心 |
Flow-GRPO 算法 |
|
架构特色 |
Planner / Executor / Verifier / Generator 四模块协作 |
|
代表意义 |
从“静态推理”走向“动态交互 + 自我改善”的新一代 Agent 框架 |
AgentFlow 架构图(包含四个模块与 Flow-GRPO 优化循环)?
那样可以更直观地理解整个系统的原理。
© 版权声明
文章版权归作者所有,未经允许请勿转载。








![[理论篇-10]AI 工作流(AI Workflow)—— 让 AI 像流水线一样干活](https://www.dunling.com/img/7.jpg)




这个是搬运还是自己创作的呢?
收藏了,感谢分享