
新年快乐,开工大吉
对于正则表达式,不知道你有没这种感觉,总是能按照需求写出来一些,但是不执行一下总觉得不靠谱。今天我们来简单的看看正则表单时
正则表达式
一般你会用正则做什么,大部分都是做一些字符串的检查?下面有几个问题,不妨试着通过正则表达式看你是否能够解决?
- 校验密码是否包含字母大小写、数字、特殊字符(!@#¥%^&)且长度为6到12位
- 将数字12345678用货币格式(每3位一个,)最终效果:12,345,678
- 替换一段文字中的占位字符部分(列如${}包含的内容),类似ES6中的模板语法
定义
正则表达式,又称规则表达式,(Regular Expression,在代码中常简写为regex、regexp或RE),是一种文本模式, 包括普通字符(例如,a 到 z 之间的字母)和特殊字符(称为”元字符”),是计算机科学的一个概念。正则表达式使用单个字符串来描述、匹配一系列匹配某个句法规则的字符串,一般被用来检索、替换那些符合某个模式(规则)的文本。
正则表达式是对字符串操作的一种逻辑公式,就是用事先定义好的一些特定字符、及这些特定字符的组合,组成一个“规则字符串”,这个“规则字符串”用来表达对字符串的一种过滤逻辑。
作用
回顾下上面的3个问题,我们使用正则基本上也就是完成类似的这些工作,从功能上我们可以划分为:
- 匹配 检查目标字符串是否与指定的规则匹配。列如密码强度校验、手机号码校验、URL地址校验等等,一般用来对一段字符串进行格式校验。
- 替换 按规则对字符串内容进行替换。列如将一段文字中的特殊字符替换成空字符串,主要实现对文本按指定规则进行内容的替换
- 截取 找到字符串中特定规则的片段。可以用来提取目标字符串中满足规则的片段
结构
正则表达式由普通字符以及元字符组成。其中普通字符包含0-9、a-z、A-Z以及各种符号;元字符则类似+ ? d s 这种具有特殊含义的字符。
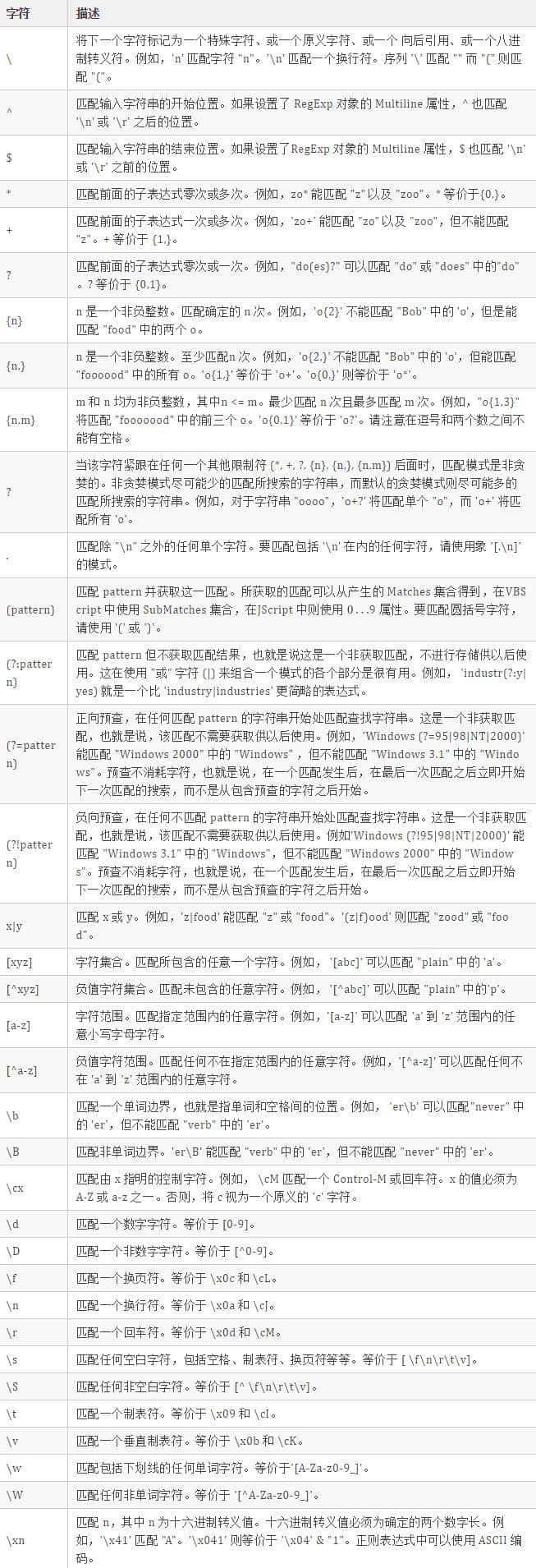
字符
- 普通字符

- 非打印字符

- 特殊字符

- 限定符

- 定位符

规则
- 匹配
- 贪婪匹配、惰性匹配贪婪匹配与惰性匹配影响的是被量词修饰的子表达式的匹配行为,贪婪模式在整个表达式匹配成功的前提下,尽可能多的匹配,而非贪婪模式在整个表达式匹配成功的前提下,尽可能少的匹配 (惰性模式:限定符后加上?)
源字符串:...<div>hello <div>Regex</div> !</div>...
贪婪模式:<div>.*</div> -> <div>hello <div>Regex</div> !</div>
惰性模式:<div>.*?</div> -> <div>hello <div>Regex</div>
- 回溯正则表达式匹配目标字符串时,它从左到右逐个测试表达式的组成部分,看是否能找到匹配项。在遇到量词时,需要决定何时尝试匹配更多字符。在遇到分支时,必须从可选项中选择一个尝试匹配。每当正则做类似的决定时,如果有必要,都会记录其他选择,以便匹配不成功时进行回溯,到最后一个决策点,再重新进行匹配。
我们可以简单的理解为,当正则匹配存在多种情况时,出现失败后的重试机制,直到所有情况都尝试失败才会最终失败。要注意有时这是超级耗费性能的
正则:ab{1,3}c 源字符串:abc
第一次匹配:a匹配到a
第二次匹配:b{1,3}匹配到b
第三次匹配:b{1,3}匹配到c,由于贪婪模式,尽可能多的匹配,当匹配到b后,会继续,碰到c,匹配失败,回溯最近一次成功的状态
第四次匹配:b{1,3}匹配到b
第五次匹配:c匹配到c,批次成功
为了减少回溯造成的性能问题,我们应该尽可能地明确需要匹配的目标字符,避免贪婪模式,列如使用b{1,3}?
- 分组、引用和断言
- 分组:语法()
- 按括号从左到右,从外到内依次为分组编号
- 使用(?<组名>)方式显示分配组名称
- 断言非分组
示例:
(A)(B(C)) 则会对应多个分组:
0: (A)(B(C))
1: (A)
2: (B(C))
3: (C)
- 引用:语法组号
- 通过组号引用分组,减少重复
// 引用主要是为了减少输入,但要注意正确引用
Pattern.compile("(###).*(\1)").matcher("### this is content ###")
- 断言:
- (?=pattern) 零宽正向先行断言(前瞻)
- (?!pattern) 零宽负向先行断言(否定前瞻)
- (?<=pattern) 零宽正向后行断言(正向后视)
- (?<!pattern) 零宽负向后行断言(否定后视)
第一个问题的解决方案就用到了断言
只判断,不匹配
- 模式
在javascript中,有i、g、m、s分别对应了不区分大小写、全局匹配、多行匹配以及包含换行符的元字符.匹配,而在Pattern中则提供了下面的几种模式:
- UNIX_LINES 换行符统一认定为
,(window系统默认是
) - CASE_INSENSITIVE 大小写不敏感,对应i
- COMMENTS 表达式中的空格及#开头的注释内容被忽略
- MULTILINE 多行模式,对应m
- LITERAL 字面值解析模式,元字符作为普通字符处理
- DOTALL .可以匹配任何字符,包括行结束符,对应上面的s
- UNICODE_CASE 配合CASE_INSENSITIVE实现对UNICODE大小写不敏感
- CANON_EQ 启用规范等价,列如”au030A”会匹配”?”
- UNICODE_CHARACTER_CLASS 启用Unicode版本的预定义字符类和POSIX字符类,这样类似w的匹配就不局限于英文字符了
元字符
所谓元字符就是指那些在正则表达式中具有特殊意义的专用字符,可以用来规定其前导字符(即位于元字符前面的字符)在目标对象中的出现模式。下面整理了元字符以及其对应的功能。
示例
下面来看下上面3个问题通过正则具体如何解决吧…
- 问题1,主要使用了断言来实现,当然你也可以拆分成多个正则进行匹配来达到一样的效果
@Test
public void checkPassword(){
String password = "aaa123@Z";
Pattern compile = Pattern.compile("(?=.*\d+)(?=.*[a-z]+)(?=.*[A-Z]+)(?=.*[!@#$%^&]+)[a-zA-Z\d!@#$%^&]{6,12}");
log.info(">>> {}", compile.matcher(password).matches());
}
- 问题2,同样借助了断言,实现字符串的查找,最终实现替换,当然我们替换的不是字符,而是匹配的位置
@Test
public void scientific(){
String number = "123456789";
String result = number.replaceAll("(?=\B(\d{3})+$)", ",");
log.info(">> {}", result);
}
- 问题3,通过分组实现字符串片段的查找,通过变量上下文重新组件字符串
@Test
public void replaceHolder(){
Map<String,String> context = new HashMap<>();
context.put("company","north");
context.put("project","blob");
context.put("model","regex");
String packages = "com.{company}.{project}.{model}.*";
Pattern pattern = Pattern.compile("(\{[^}]*\})");
Matcher matcher = pattern.matcher(packages);
StringBuffer result = new StringBuffer();
while (matcher.find()){
String group = matcher.group();
String key = group.substring(1, group.length()-1);
matcher.appendReplacement(result, context.getOrDefault(key,"") );
}
matcher.appendTail(result);
log.info( result.toString() );
}
工具库
https://www.runoob.com/regexp/regexp-operator.html
扩展知识
NFA引擎 DFA引擎
结束语
正则表达式是一种书写简单,功能强劲且常用的技术,基本所有的编程语言都有其相关的实现与支持。因此深入了解正则实现原理与书写规范超级重大。
该篇主要通过简单的几个示例介绍了正则表达式的功能以及一些基本结构与功能,希望能够抛砖引玉,让你对正则表达式有更深的认识。
来源;
https://mp.weixin.qq.com/s/XuRENQXqh8EXesnDztfi3Q
作者:指北君
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章










![[理论篇-10]AI 工作流(AI Workflow)—— 让 AI 像流水线一样干活](https://www.dunling.com/img/2.jpg)


佩服💪
收藏了,感谢分享
我恨正则表达式网站
正则表达式
正则表达式……
大神💪
太杂了
干货满满
正则表达式全部语言通用的吧
这东西规则挺多的,用的机会不多。看完用了一两次,之后又忘了
干货