
00:00
以往的数字人技术,要么不够逼真,要么对输入要求太高。列如有些需要超级精细的 3D 模型,有些只能生成特定角度的视频,不够灵活。
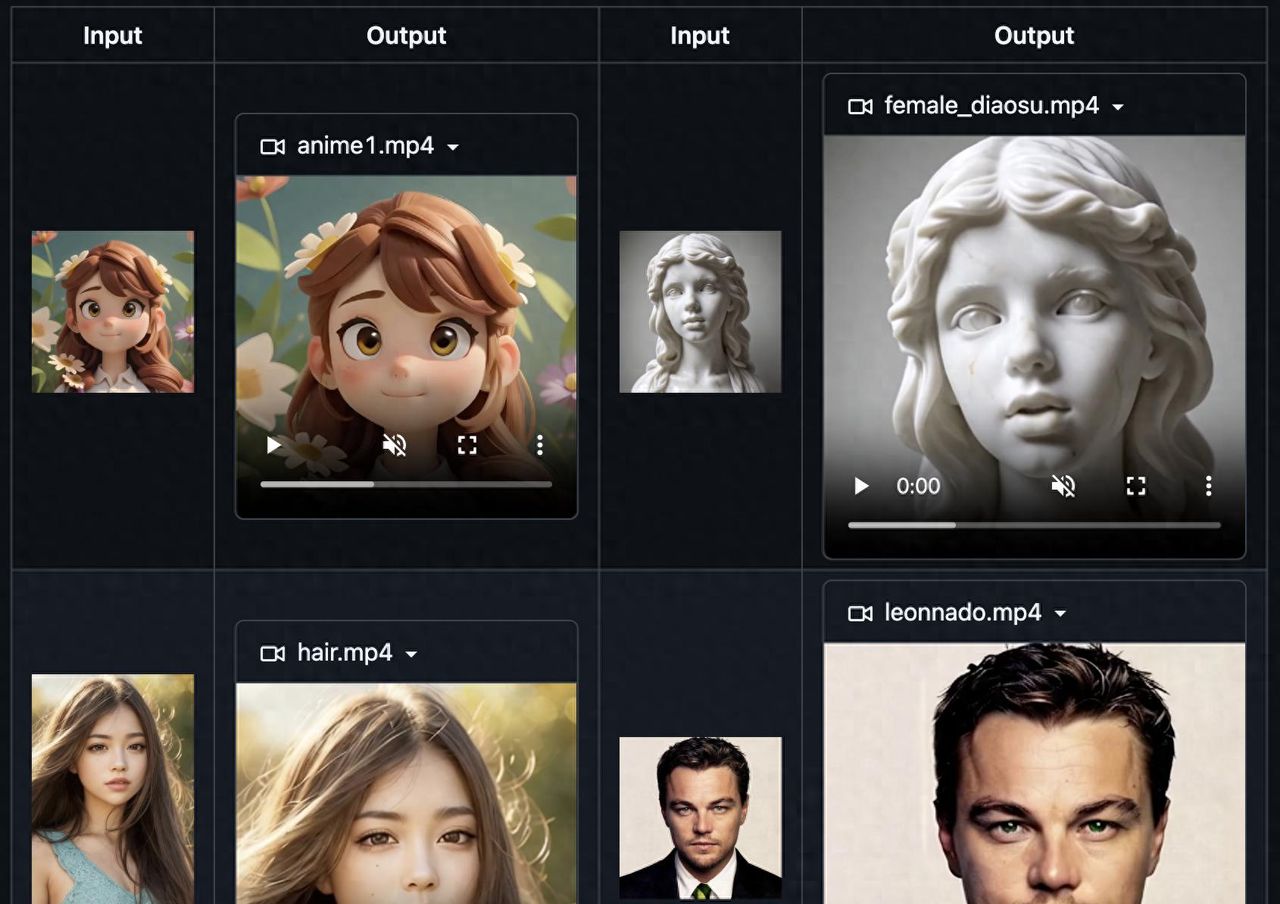
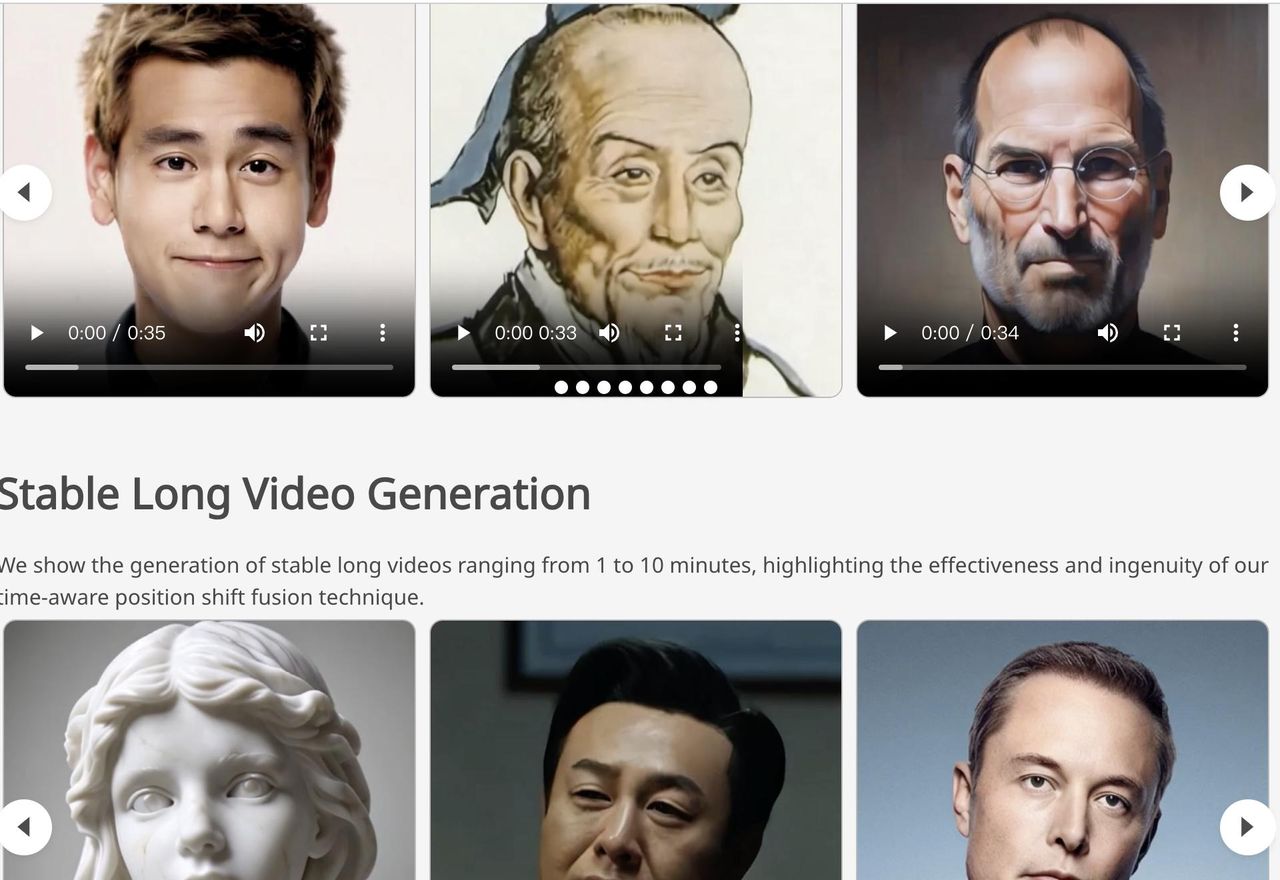
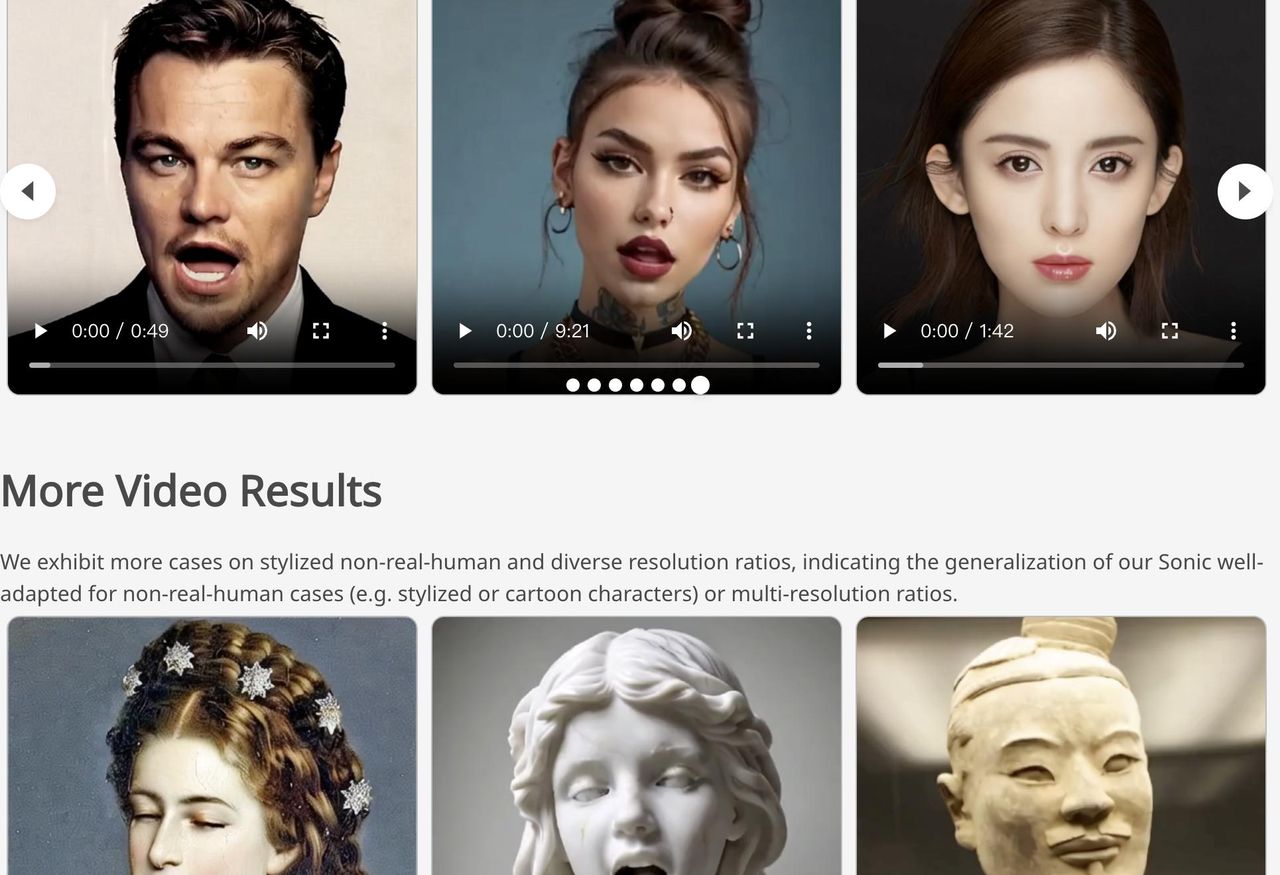
随着 AI 技术的飞速发展,数字人正变得越来越逼真、越来越智能。近日,腾讯发布了名为 Sonic 的全新数字人技术。Sonic 最大的亮点在于,它仅需一张照片和一段音频,就能生成高度逼真的人物说话视频。不过,Sonic 并非只是简单的“换脸”或“口型对齐”,而且表情自然、口型精准,甚至还能唱 RAP!它在背后融入了诸多创新技术,才得以实现如此惊艳的效果。

Sonic 是一种 AI 技术,能够根据一张静态照片和一段声音,生成逼真的人物说话视频,而且视频中的人物表情、口型和头部动作都能与声音完美同步。Sonic 的目标就是打造一个更通用、更逼真、更灵活的数字人生成方案。

列如我们输入如上一张图,然后给模型提供一段音频,Sonic模型会自动听取音频中的内容,并根据音频内容,把图片与音频合成一段视频,其中人物的口型,表情,动作简直不要太逼真。合成的视频如下:
00:00
在深入了解 Sonic 的技术细节之前,先思考一下,一个逼真的人体动画,究竟需要具备哪些要素:
- 准确的口型同步: 数字人物的口型必须与音频内容完美匹配,这是最基本的要求。
- 自然的表情变化: 人类的情感是复杂的,数字人物需要能够根据音频的情感和语境,自然地展现喜怒哀乐等各种表情。
- 灵活的头部动作: 头部是人体最灵活的部位之一,数字人物需要能够自然地转头、点头、摇头,才能显得更加生动。
- 长时序的稳定性: 生成较长的视频,需要保证人物的身份一致性,避免出现“变脸”等问题。

以往的数字人技术,往往难以同时兼顾以上所有要素。而 Sonic 则力求在各个方面都做到极致,打造更具“灵魂”的数字人。
Sonic 架构详解:多模态融合,全局音频感知
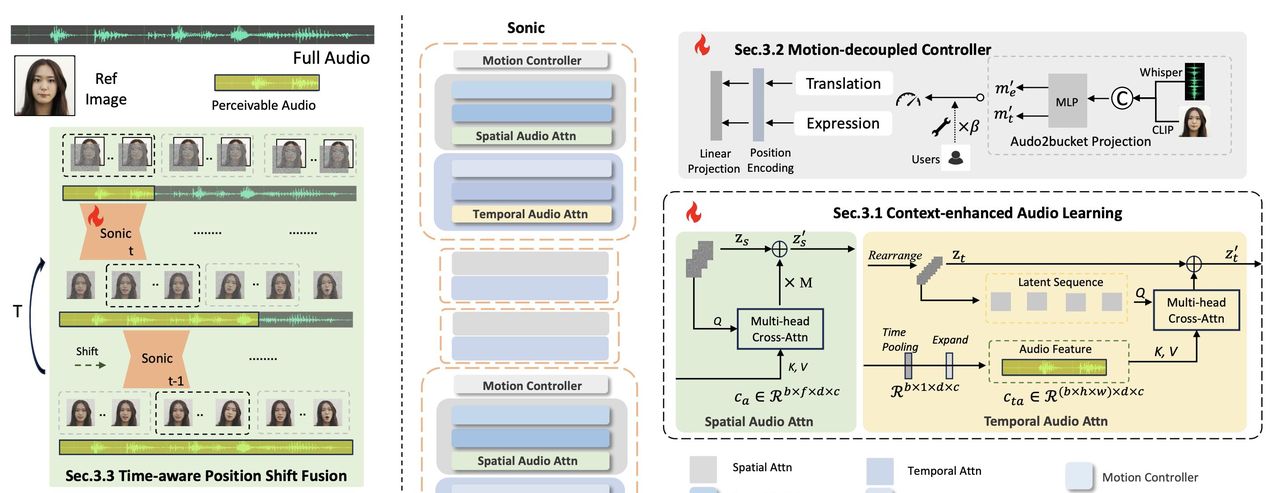
要理解 Sonic 的技术突破,我们第一需要了解它的整体架构。Sonic 并非简单地将音频和图像信息进行融合,而是采用了一种更精巧的设计:
多模态信息编码: Sonic 模型能够同时接收来自图像和音频的信息。对于图像,Sonic 主要提取人物的外貌特征,列如脸型、五官、发型等。对于音频,Sonic 则提取声音的语调、节奏、情感等信息。这些信息经过编码后,形成 Sonic 能够理解的向量表明。
全局音频感知模块: 这是 Sonic 的核心创新之一。Sonic 并没有像以往的技术那样,只关注音频的局部信息(列如每个音节的发音),而是更加注重理解音频的全局信息,包括:
- 长时序音频依赖: 通过 Context-enhanced audio learning 模块,Sonic 能够学习音频中长距离的时间依赖关系,从而更好地理解音频的上下文信息。
- 解耦运动控制器: 通过 Motion-decoupled Controller 模块,Sonic 将头部运动和表情变化解耦,实现更精细化的控制。
- 时序感知的运动融合: 将编码后的图像信息和全局音频信息进行融合,并使用一种叫做 “Time-aware Position Shift Fusion” 的技术,让模型能够生成时间上连贯的视频。这种方法不需要依赖额外的运动帧信息,因此能够显著降低计算复杂度。
技术创新一:Context-enhanced Audio Learning(上下文增强音频学习)
为了捕捉音频中的全局信息,Sonic 采用了 Context-enhanced Audio Learning 模块,其核心思想是:
- 更轻量级的音频特征提取: 使用 Whisper-Tiny 模型提取音频特征,比常用的 Wav2Vec 模型更轻量级,降低了计算负担。
- 多尺度音频信息融合: 融合了 Whisper-Tiny 模型多层特征,从而能够捕捉到音频中不同尺度的信息。
- 空间自适应的音频融合: 通过 Spatial Audio Attn 模块,将音频信息融合到图像的空域特征中,从而让模型能够根据音频信息来调整图像的表情。

技术创新二:Motion-decoupled Controller(运动解耦控制器)
仅仅对准口型是不够的,真实的人物动画需要丰富的头部动作和表情变化。为了实现这一目标,Sonic 采用了 Motion-decoupled Controller,其核心思想是:
- 解耦头部运动和表情: 将头部运动和表情变化分解为独立的控制参数,从而实现更精细化的控制。
- 可调节的运动幅度: 允许用户手动调整头部运动和表情变化的幅度,从而实现更个性化的动画效果。
- 音频驱动的运动预测: 通过音频驱动的方式,自动预测头部运动和表情变化的幅度,从而实现更自然的动画效果。
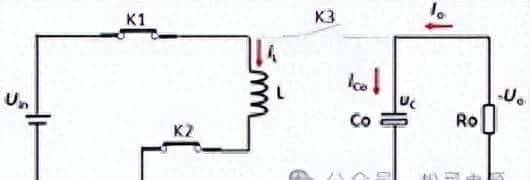
技术创新三:Time-aware Position Shift Fusion(时序感知的位置偏移融合)
生成长视频的关键在于保证视频的流畅性,避免出现跳帧、抖动等问题。为了实现这一目标,Sonic 采用了 Time-aware Position Shift Fusion 技术,其核心思想是:
- 分段处理: 将长视频分成多个片段,分别进行处理。
- 位置偏移: 在处理每个片段时,都会思考到它和前后片段的联系,从而保证视频的整体流畅性。
- 循环填充: 对于视频的开头和结尾,采用循环填充的方式,保证视频的完整性。
实验结果:Sonic 实力碾压

为了验证 Sonic 的效果,腾讯的研究人员进行了大量的实验。实验结果表明,Sonic 在多个指标上都超越了其他的模型,包括:
- FID(Fréchet Inception Distance): 用于衡量生成图像的质量,数值越低越好。Sonic 在 FID 指标上取得了明显优势。
- Sync-C(Synchronization Confidence): 用于衡量口型同步的准确性,数值越高越好。Sonic 在 Sync-C 指标上也表现出色。
此外,研究人员还进行了主观评估,让志愿者对生成的视频进行打分。结果表明,志愿者对 Sonic 的视频质量、流畅性、身份保持等方面都给出了很高的评价。
Sonic,让数字人触手可及
腾讯的 Sonic 技术,通过全局音频感知、运动解耦控制和时序感知的运动融合,实现了对口型、表情和动作的精准控制,让数字人变得更加逼真、自然、生动。这项技术不仅提升了数字人的观赏性,也为数字人的应用带来了更广阔的空间,有望在虚拟偶像、在线教育、智能客服等领域发挥重大作用。

值得一提的是,Sonic 技术在保证逼真度的同时,还支持对卡通人物和非人物图像进行动画处理,这意味着我们可以用这项技术,让各种各样的角色都“活”起来!
jixiaozhong.github.io/Sonic/© 版权声明
文章版权归作者所有,未经允许请勿转载。














收藏了,感谢分享
即梦,了解一下,ominihuman1 了解一下,全图不裁切了解一下 都是弟弟
都不是实时的,,,,
,可以实时的,也有对应的技术