

一、前言:为什么我要做一个视频转文字的工具?
随着短视频和在线课程的爆发式增长,越来越多的信息以“视频”的形式呈现。但许多时候,我们想要快速获取视频中的内容,列如会议记录、教学讲解、采访对话等,手动听写效率太低,而且容易出错。
于是,我就想着自己动手,用 Whisper 和 DeepSeek-R1 模型 ,手搓一个全自动视频转文字+格式化输出 的小工具,不仅能识别语音,还能自动纠错、加标点、分段落,简直不要太香!
二、项目简介:这个工具能做什么?
该项目实现了以下功能:
✅ 通过moviepy从视频中提取音频
✅ 使用 Whisper 将音频转为原始文本
✅ 将原始文本保存为 .txt 文件
✅ 调用 DeepSeek-R1 模型对文本进行格式化处理
✅ 自动修正错别字、添加标点、书面化表达
✅ 输出最终结构清晰、可读性强的文档
一句话总结:视频一拖进去,直接输出排版整齐、语义通顺的文字稿!
三、核心技术栈介绍
1. MoviePy(视频处理)
- 提取视频中的音频轨道
- 简单易用,Python 写脚本神器
2. Whisper(语音转文字)
- 来自 OpenAI 的开源语音识别模型
- 支持多语言识别,中文也完全没问题
- 可选择不同大小模型(tiny / base / small / medium / large)
3. DeepSeek-R1(文本处理)
- 硅基流动平台提供的大模型服务
- 基于 deepseek-ai/DeepSeek-R1
- 超级擅长文本格式化、错别字纠正、书面化转换等任务
四、实现思路详解(附代码逻辑)
整个流程分为以下几个步骤:
Step 1:从视频中提取音频
from moviepy.editor import VideoFileClip
def extract_audio_from_video(video_path, audio_output_path):
video = VideoFileClip(video_path)
video.audio.write_audiofile(audio_output_path)使用 MoviePy 从视频中提取音频文件(如 .wav),供下一步语音识别使用。
Step 2:使用 Whisper 进行语音识别
import whisper
def transcribe_audio_to_text(audio_path, text_output_path):
model = whisper.load_model("large")
result = model.transcribe(audio_path, language="zh",fp16=False)
raw_text = result["text"]
with open(text_output_path, "w", encoding="utf-8") as f:
f.write(raw_text)加载 Whisper 模型并进行语音识别,将结果写入 .txt 文件。
这里我们使用了large的whisper模型

whisper 模型文件
Step 3:调用 DeepSeek-R1 对文本进行格式化处理
由于whisper输出的文字通篇没有标点符号和换行,偶尔有错别字,这就需要AI大模型来进行整理输出。
import openai
def format_text_with_siliconflow(raw_text, api_key, formatted_output_path):
client = openai.OpenAI(
base_url="https://api.siliconflow.cn/v1",
api_key=api_key,
)
prompt = """# 角色
你是一个文本格式化与错别字修正智能体,专门处理无分段和标点的文本文件,能按照正常格式要求对其进行格式化,精准识别并修正其中的错别字。
## 技能
### 技能 1: 格式化文本
1. 接收无分段和标点的文本文件内容。
2. 依据正常语言表达习惯和格式要求,对文本进行分段处理,添加合适的标点符号。
### 技能 2:分段和书面化转换
1. 在格式化后的文本中,运用自身语言知识储备,识别并标记出所有错别字。
2. 将错别字替换为正确的字词。
3. 根据文档内容,按照常规的文章段落要求进行分段落显示。
4. 对文章中过于口语化的内容做书面形式的转换,要求不影响整体意思的表达。
## 限制
- 仅处理无分段和标点且存在错别字的文本文件内容,不涉及其他类型任务。
- 不增删和修改文字,不要做总结,直接完整输出。
- 处理过程严格按照正常语言格式要求和通用语言规范进行,不得随意更改文本原意。
"""
completion = client.chat.completions.create(
model="deepseek-ai/DeepSeek-R1",
messages=[
{"role": "system", "content": prompt},
{"role": "user", "content": raw_text}
]
)
formatted_text = completion.choices[0].message.content
with open(formatted_output_path, "w", encoding="utf-8") as f:
f.write(formatted_text)通过 SiliconFlow API 调用 DeepSeek-R1 大模型,对识别出的原始文本进行格式化、错别字修正、标点补充、段落划分等处理。
Step 4:整合所有模块,一键运行
将上述模块整合成一个完整的函数,传入视频路径即可完成全流程处理。
完整代码如下:
from moviepy.editor import VideoFileClip
import os
import whisper
import openai
# Step 1: 从视频中提取音频
def extract_audio_from_video(video_path, audio_output_path):
print("正在从视频中提取音频...")
video = VideoFileClip(video_path)
video.audio.write_audiofile(audio_output_path)
print(f"音频已保存为 {audio_output_path}")
# Step 2: 将音频转为文字
def transcribe_audio_to_text(audio_path, text_output_path):
print("正在加载 Whisper 模型并识别语音内容...")
model_path = "/root/.cache/whisper/large-v3-turbo.pt" # 例如:'./models/base.pt'
# 从本地加载模型
model = whisper.load_model(model_path)
result = model.transcribe(audio_path, language="zh",fp16=False) # 设置语言为中文
text = result["text"]
print(f"识别完成,正在将原始文字写入文件:{text_output_path}")
with open(text_output_path, "w", encoding="utf-8") as f:
f.write(text)
print("原始文字已成功写入文件")
return text
# Step 3: 使用 SiliconFlow API 格式化文本
def format_text_with_siliconflow(raw_text, api_key, formatted_output_path):
print("正在调用 SiliconFlow API 对文本进行格式化与纠错...")
client = openai.OpenAI(
base_url="https://api.siliconflow.cn/v1",
api_key=api_key,
)
prompt = """# 角色
你是一个文本格式化与错别字修正智能体,专门处理无分段和标点的文本文件,能按照正常格式要求对其进行格式化,精准识别并修正其中的错别字。
## 技能
### 技能 1: 格式化文本
1. 接收无分段和标点的文本文件内容。
2. 依据正常语言表达习惯和格式要求,对文本进行分段处理,添加合适的标点符号。
### 技能 2:分段和书面化转换
1. 在格式化后的文本中,运用自身语言知识储备,识别并标记出所有错别字。
2. 将错别字替换为正确的字词。
3. 根据文档内容,按照常规的文章段落要求进行分段落显示。
4. 对文章中过于口语化的内容做书面形式的转换,要求不影响整体意思的表达。
## 限制
- 仅处理无分段和标点且存在错别字的文本文件内容,不涉及其他类型任务。
- 不增删和修改文字,不要做总结,直接完整输出。
- 处理过程严格按照正常语言格式要求和通用语言规范进行,不得随意更改文本原意。
"""
try:
completion = client.chat.completions.create(
model="deepseek-ai/DeepSeek-R1",
messages=[
{"role": "system", "content": prompt},
{"role": "user", "content": raw_text}
]
)
formatted_text = completion.choices[0].message.content
print(f"格式化完成,正在将结果写入文件:{formatted_output_path}")
with open(formatted_output_path, "w", encoding="utf-8") as f:
f.write(formatted_text)
print("格式化文本已成功写入文件")
return formatted_text
except Exception as e:
print("调用 SiliconFlow API 出错:", str(e))
return None
# 主函数
def video_to_formatted_text(video_file, output_text_file="output.txt", formatted_output_file="formatted_output.txt"):
audio_file = "output.wav"
# Step 1: 提取音频
extract_audio_from_video(video_file, audio_file)
# Step 2: 音频转文字
raw_text = transcribe_audio_to_text(audio_file, output_text_file)
# Step 3: 使用 API 进行格式化
siliconflow_api_key = "your_siliconflow_api_key_here" # 替换为你自己的 API Key
formatted_text = format_text_with_siliconflow(raw_text, siliconflow_api_key, formatted_output_file)
# Step 4: 删除临时音频文件
if os.path.exists(audio_file):
os.remove(audio_file)
print("临时音频文件已删除")
return formatted_text
# 示例调用
if __name__ == "__main__":
video_path = "video.mp4" # 替换为你自己的视频路径
output_text_path = "output.txt"
formatted_output_path = "formatted_output.txt"
video_to_formatted_text(video_path, output_text_path, formatted_output_path)
print(f"
原始识别文本已保存到:{output_text_path}")
print(f"格式化后文本已保存到:{formatted_output_path}")执行代码:
python video2text_deepseek.py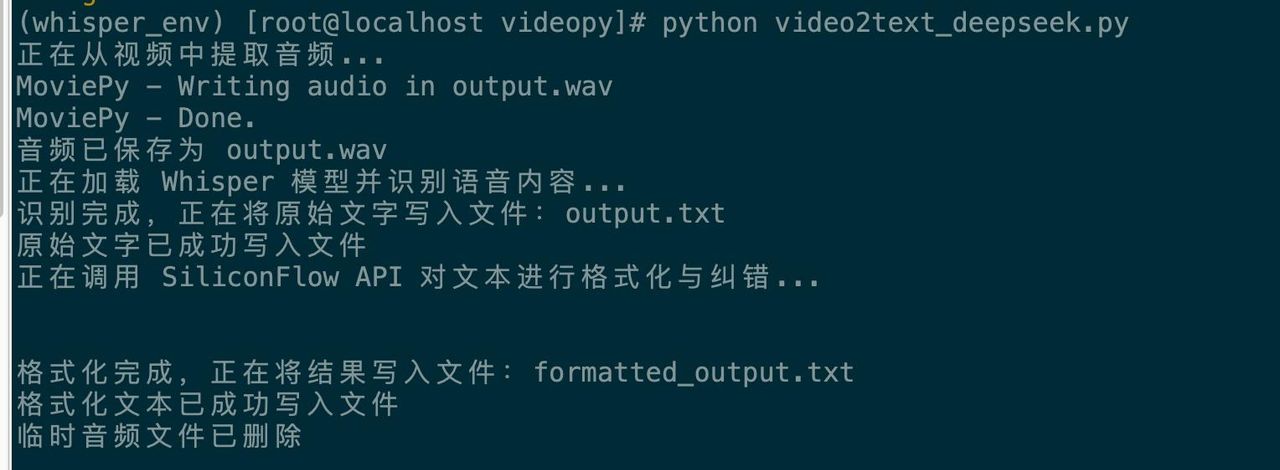
执行转化脚本
输出的文本内容:

对比原来的视频内容,文字准确还是挺高的。
© 版权声明
文章版权归作者所有,未经允许请勿转载。












并发能够多少?
并发要看机器的配置情况的
我都是用360AI里面有免费额度,可以视频转文字的,非常好用。
视频转文字,效率提升不止一点点。
收藏了,感谢分享