
一、介绍
VOSK是由Alpha Cephei公司开发的开源语音识别工具库,其名称源自俄语”ВОСК”(蜡),寓意能像蜡一样完美贴合各种应用场景。作为一款完全离线的语音识别解决方案,VOSK基于深度神经网络(DNN)和循环神经网络(RNN)构建,能够将音频流实时或批量转换为结构化文本。VOSK 凭借其离线、跨平台、高效和开源的特性,在语音识别领域占据了独特而重大的地位。它并非要完全取代谷歌、微软等提供的强劲云端语音服务,而是为那些对隐私、延迟、网络条件和成本有严格要求的应用场景提供了一个绝佳的解决方案。
VOSK的核心优势包括:
1、跨平台支持:兼容
Windows/Linux/macOS/Android/iOS/Raspberry Pi等平台。
2、多语言识别:支持20+种语言,包括中文、英语、法语、德语等。
3、轻量高效:小型模型仅42MB左右,内存占用低。
4、流式识别:支持实时音频流处理,响应速度快。
二、官方地址及模型下载
VOSK 官方网站:
https://alphacephei.com/vosk/
GitHub 仓库:
https://github.com/alphacep/vosk-api
模型下载:
https://alphacephei.com/vosk/models

模型下载,找到中文的
三、工具实践
在python10-11等环境中,安装VOSK。
pip install vosk
从 VOSK 官网下载所需语言模型(如
vosk-model-small-en-us-0.15),并解压放到指定的目录。如果条件允许,一般提议下载vosk-model-cn-0.22,识别相对更加准确。
如果做例子我们可以先准备一个有人说话的声音文件。如a.wav,可以从网上下载。
为提高识别准确率,提议对音频进行以下处理:转换为单声道;采样率设为16kHz;16位深度。一般的a.wav应该没事。
四、代码例子
import json
from vosk import Model, KaldiRecognizer
import wave
# 1. 加载离线模型
model = Model(“./vosk-model-cn-0.22”)
# 2. 打开要识别的音频文件
wf = wave.open(“a.wav”, “rb”)
# 检查音频格式是否符合要求(单声道,16kHz采样率,16位深)
if wf.getnchannels() != 1 or wf.getsampwidth() != 2 or wf.getcomptype() != “NONE”:
print(“格式不符合要求.”)
exit(1)
# 3. 创建识别器
rec = KaldiRecognizer(model, wf.getframerate())
# 4. 逐块读取音频并进行识别
results = []
while True:
data = wf.readframes(4000)
if len(data) == 0:
break
if rec.AcceptWaveform(data):
part_result = json.loads(rec.Result())
results.append(part_result.get(‘text’, ”))
# 获取最终结果
final_result = json.loads(rec.FinalResult())
results.append(final_result.get(‘text’, ”))
# 5. 输出所有识别文本
full_text = ” “.join(results)
print(f”识别结果: {full_text}”)
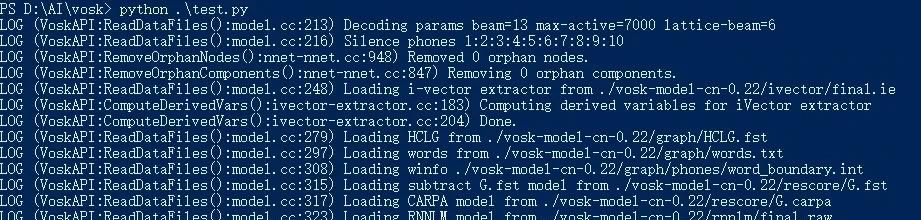
运行及结果
五、其他
高级一点的,可以读取流式语音。
还可以增加谐音词的处理。由于有时候发音带口音需要处理。
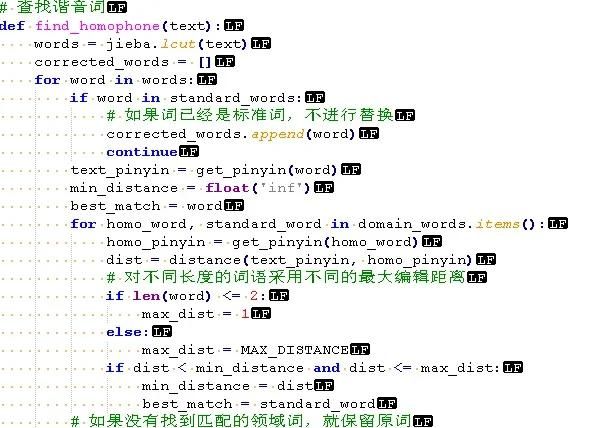
谐音词处理
© 版权声明
文章版权归作者所有,未经允许请勿转载。













好用吗
语音转文字大模型
收藏了,感谢分享
识别率还是不够好,不能添加词库
如果是实时语音输入的建议提高麦克的音量,保持口齿清晰,如果是文件语音口音较重的,可建立谐音库处理。