摘要:在AI人工智能快速发展的今天,LMM多模态大模型正成为技术热点。它不但让机器能“听懂”和“看懂”人类的语言、图像等信息,还能生成跨类型的内容,列如根据图片生成文字或根据文本创作音乐。这类大模型通过大量数据训练而成,不仅能处理单一类型的信息,还能实现不同类型的转换与整合。
随着深度学习的进步,这些模型已经能完成从简单的图文描述到复杂的多模态对话等任务。文章第一介绍了多模态大模型的基本概念和发展历程,从早期处理单一信息类型的方法发展到目前利用深度神经网络整合多种信息的技术。大数据和计算能力的提升极大地推动了这一领域的发展。如今,多模态大模型不仅可以识别和回应多种形式的信息输入,还能创作图文内容、进行实时语音翻译及辅助医疗诊断等。
本文通过多模态智能助手实际案例,展示了多模态大模型在日常生活中如何使用,并展望了其充满潜力的未来。这不仅让读者了解这项技术的重大性,也激发了对未来可能性的期待。详细内容请参考下文。

一、AI大模型环境
1.访问Linux系统

2.通过Ollama平台启动DeepSeek大模型
二、大模型
1.大模型的定义
说明:DeepSeek对大模型的解释如下

2.如何有效的训练大模型
说明:DeepSeek对如何有效训练大模型的回答如下


三、LMM多模态大模型
1. LMM多模态大模型的定义
LMM多模态大模型是一种能让机器同时理解和处理文字、图像、声音等多种类型信息的智能技术。LMM多模态大模型的主要功能和作用如下

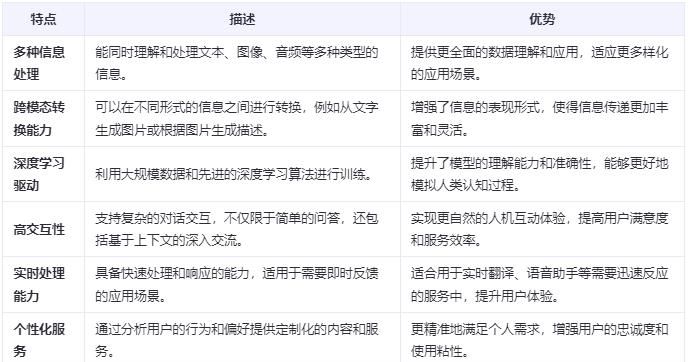
2. LMM多模态大模型的特点
LMM多模态大模型的特点是能够像一个全能翻译官一样,不仅理解文字、图像和声音中的信息,还能把这些不同形式的信息相互转换和整合。
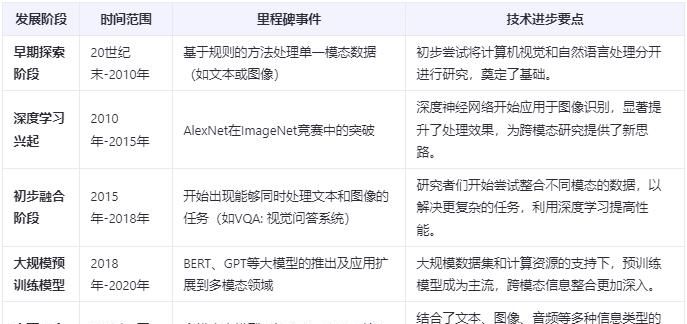
3. LMM多模态大模型的发展历程
LMM多模态大模型的发展历程是从处理单一类型数据的简单模型起步,逐步发展到能够整合文本、图像、音频等多种信息的复杂系统,其中关键的里程碑包括深度学习技术的应用和大规模数据集的引入,这些进步极大地提升了模型的理解与生成能力。
4. LMM多模态大模型的工作流程
LMM多模态大模型的工作流程是先接收各种类型的数据(如文字、图片、声音),然后将这些数据转换成机器能理解的形式,接着分析并整合这些信息,最后根据需求输出相应的结果,列如生成描述、回答问题或创作内容。
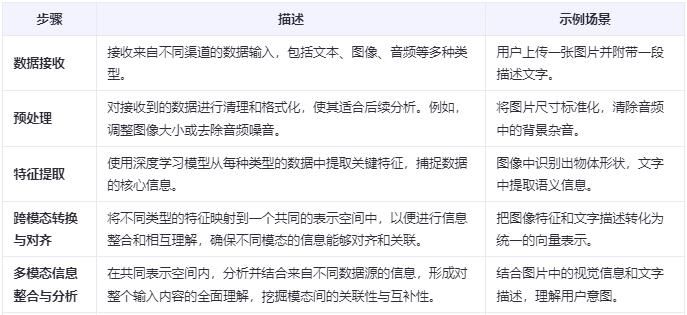
5. LMM多模态大模型的关键技术
LMM多模态大模型的关键技术在于利用深度学习将不同形式的信息(如文字、图片、声音)转化为统一的数字表明,从而让机器能够理解和整合这些信息,实现跨类型的智能处理和交互。
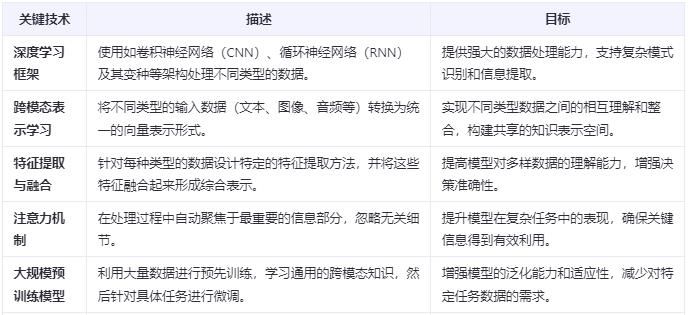
6. LMM多模态大模型的应用领域
LMM多模态大模型的应用领域涵盖了从智能客服、图像识别、语音助手到内容创作等多个方面,它让机器能够处理和整合文本、图像、声音等多种信息,从而提供更加丰富和智能的服务。

四、LMM多模态大模型应用实例
1. LMM多模态大模型实际应用案例
说明:LMM多模态大模型在实际应用中展现了巨大的潜力,下面列举几个通俗易懂的实际案例分别介绍:
(1)智能客服:假设你正在使用一款在线购物应用,遇到问题时不需要再等待人工客服的回复。LMM多模态大模型可以协助智能客服理解你的文字提问、语音留言,甚至分析你上传的问题截图,然后快速给出准确的回答或解决方案。这样不仅提高了效率,也提升了用户体验。
(2)内容创作助手:对于创作者来说,LMM多模态大模型可以成为得力助手。列如,输入一段描述性的文字,模型就能根据这段文字自动生成一张图片,或者将一段音频转化为文字稿。这对于写作者、设计师和视频制作者等创意工作者来说,极大地节省了时间和精力。
(3)医疗健康助手:在医疗领域,这种模型能够协助医生更准确地诊断疾病。例如,通过分析X光片、CT扫描图像以及病人的症状描述,模型可以提供辅助诊断提议。此外,还能通过监控患者的日常健康数据(如心率、血压等),及时提醒患者及其家属注意潜在的健康风险。
(4)智能家居控制:在家用智能设备方面,LMM多模态大模型使得家庭生活更加便捷。可以通过语音命令控制家中的灯光、温度甚至是安防系统。而且,如果家中安装了摄像头,该模型还可以识别异常活动,及时发警示信息。
(5)教育辅导工具:就学生来说,LMM多模态大模型可以作为个性化的学习伙伴。能根据学生的作业表现、课堂参与情况(视频、音频记录)以及在线测试成绩,为每个学生量身定制学习计划,并提供即时反馈和指导。
2. LMM多模态大模型简单应用案例
说明:由于本地已经通过Ollama运行了qwq:32b大模型,这里不需要使用远程大模型的API,直接使用本地大模型。
(1)执行指令# vim myLMM.py编写多模态智能助手程序
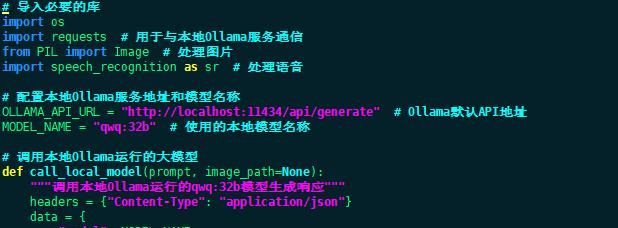
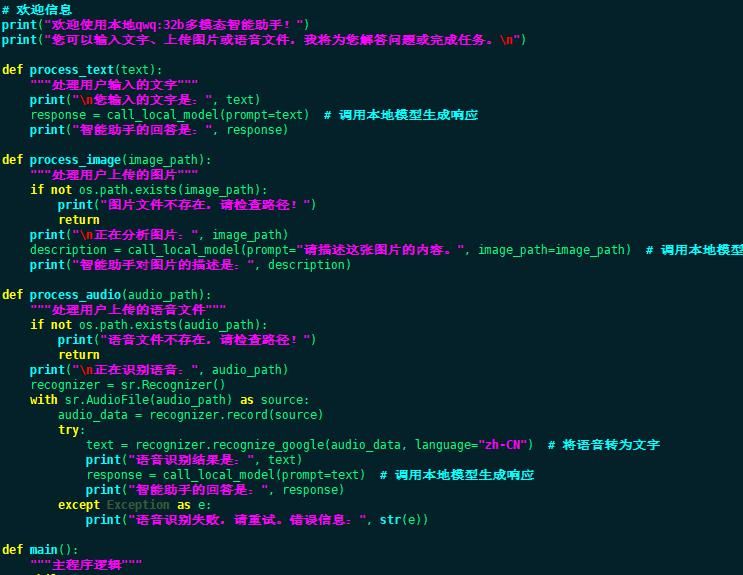
备注:上述程序代码说明事项如下
- 本地Ollama服务:假设 Ollama 已经在本地运行,并且可以通过 http://localhost:11434/api/generate 访问。替换 MODEL_NAME 为你实际使用的模型名称(如 qwq:32b)。
- 调用本地模型:使用 requests 库向 Ollama 的 API 发送 HTTP 请求。支持文本输入和图片输入(假设 Ollama 支持多模态功能)。
- 语音处理:使用 speech_recognition 将语音转为文字后,再调用本地模型生成响应。
- 依赖库:requests用于与本地Ollama服务通信,Pillow用于处理图片文件,SpeechRecognition用于语音识别。
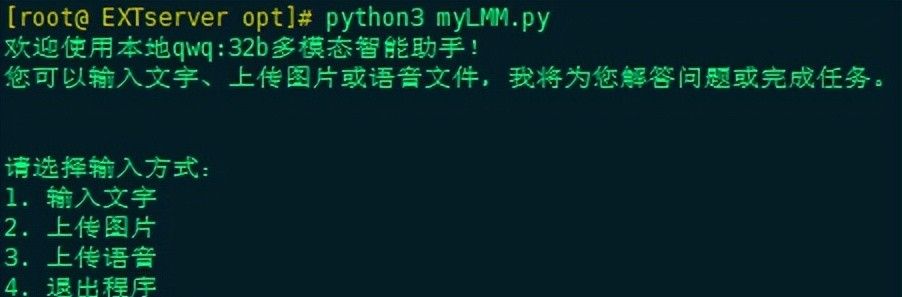
(2)运行myLMM.py多模态智能助手程序
© 版权声明
文章版权归作者所有,未经允许请勿转载。













收藏了,感谢分享
知识共享
厉害厉害👍