
大语言模型(LLM)因其强劲的语言理解和生成能力而备受关注,不过在实际应用中,这些模型一般需要针对特定任务或领域进行微调,才能够实际应用于特定领域。LLaMA-Factory是一个开源的低代码大模型训练框架,为开发者提供了一个高效、便捷的微调平台。本文将介绍LLaMA-Factory的核心功能、使用方法以及实际应用案例。
一、LLaMA-Factory简介
LLaMA-Factory是由零隙智能(SeamLessAI)开源的一款低代码大模型训练框架,通过提供可视化训练、推理平台及一键配置模型训练,LLaMA-Factory极大地简化了模型微调的复杂性,使得不懂大模型的用户也能够轻松上手。
Meta公司的开源大模型用Llama命名,像ChatGPT一样,超越名字本身成为大模型的一个代名词,Llama-Factory的命名不知道是否有此缘由?

二、LLaMA-Factory的核心功能
LLaMA-Factory集成了多种业界广泛使用的微调方法和优化技术:
1.可视化训练:提供直观易用的可视化训练界面,用户可以通过简单的拖拽、配置等操作,快速完成模型训练。
2.一键配置模型训练:内置了多种微调方法和优化技术,用户可以轻松选择适合的训练方法和参数。
`3.丰富的数据集支持:支持使用私域数据进行微调,并提供了内置的中文数据集。
4.高效的微调技术:支持LoRA和QLoRA等高效微调技术,可以在单张GPU上完成千亿参数的微调训练。
5. Web界面:提供Web界面,使得非开发人员也能方便地进行模型微调。
三、环境搭建
以下操作都是在Windows11家庭中文版系统,Anaconda3(64-bit)环境。

1.创建虚拟环境:
conda create –name llama_factory python=3.1 #llama_factory,虚拟环境名字可以自定义
2.激活虚拟环境
conda activate llama_factory
3. 安装依赖:
pip install -r requirements.txt
四、模型微调
1.下载LLaMA-Factory:
git clone https://github.com/hiyouga/LLaMA-Factory.git
2..本地微调
在config.json文件中配置模型路径、训练数据路径、微调阶段等参数,即可使用MA-Factory提供的工具启动微调过程。Llama-Factory提供了可视化训练界面。
设置本地环境:
et CUDA_VISIBLE_DEVICES=0
set GRADIO_SERVER_PORT=7860 #web访问端口
#启动web可视化模型训练页面LLaMA Board,即可选择和设置自己训练微调模型的各种参数,开始模型训练和微调。
python src/train_web.py
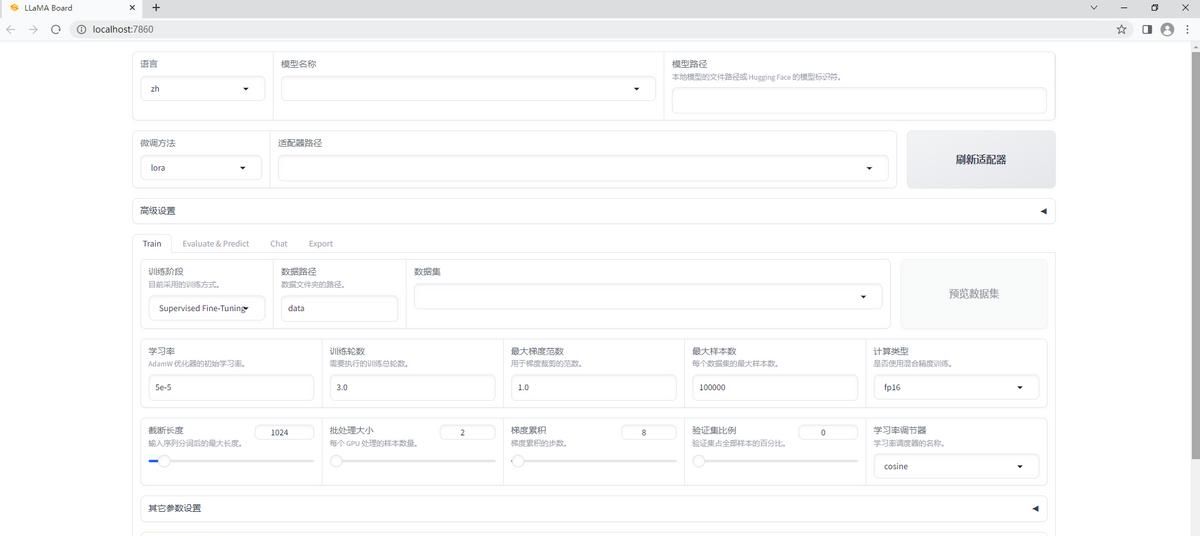
LLama-Factory极大的降低了大模型训练和微调的门槛,个人笔记本的计算能力毕竟有限,可以选择一些比较小一点的模型,在自己的机器上动手试试,定制一个自己的“大模型”,近距离体验一下大模型技术。
© 版权声明
文章版权归作者所有,未经允许请勿转载。








![[理论篇-10]AI 工作流(AI Workflow)—— 让 AI 像流水线一样干活](https://www.dunling.com/img/6.jpg)




只要流行,都会成为白菜,大模型也不例外
收藏了,感谢分享