
如何通过提示工程构建LLM大模型应用
本篇讨论大语言模型(LLM)应用开发提示工程的作用,如果您是一位开发者或产品经理,希望利用GPT-5、Gemini、DeepSeek、QWEN、豆包等大模型的构建应用,那么您第一需要掌握的,不是复杂的算法,也不是海量的数据处理。
而是提示工程(Prompt Engineering)。

什么是提示工程?:
它不是简单的“向AI提问”。它是一门科学,研究的是如何设计和构造输入(提示词),以便能够稳定、可靠、高效地从LLM那里获得我们期望的、特定格式和内容的输出。一个好的提示词,如同一个优秀的指挥家,能让庞大的交响乐团(LLM)演奏出和谐、精准的乐章。
LangChain:让提示工程变得简单
直接与LLM的API交互,需要处理大量的HTTP请求、响应解析和流程控制。而LangChain,作为当今最火热的LLM应用开发框架,为我们提供了优雅、高层次的抽象。它将与LLM的交互、提示的管理、多步骤的链式调用等复杂操作,都封装成了简洁、易用的模块。
在本文中,将以LangChain和OpenAI API为工具,带您亲历从一个最简单的“Hello World”到构建一个动态、可复用的提示模板的全过程。
学习目标:
- 创建并执行您的第一个LLM调用。
- 掌握流式(Streaming)与批量(Batch)两种调用方式,并理解其性能差异。
- 体验迭代式提示开发,学习如何将一个粗糙的提示,打磨成一个可靠的“生产级”提示。
- 构建并使用您的第一个提示模板(Prompt Template),实现逻辑与数据的分离。
环境准备:
在开始之前,请确保您已安装Python,并执行以下命令安装我们需要的库:
pip install langchain langchain-openai同时,您需要一个OpenAI的API密钥,并将其设置为环境变量,以便LangChain能够自动读取。
export OPENAI_API_KEY="sk-..."第一章:你的第一个LLM响应——与AI的初次握手
万事开头难,但用LangChain,这个开头会异常简单。我们的第一个任务,就是向LLM提一个问题,并获取它的回答。
1.1 初始化模型
在LangChain中,与聊天模型(如gpt-3.5-turbo, gpt-4)的交互,是通过ChatOpenAI这个类来完成的。
# first_interaction.py
from langchain_openai import ChatOpenAI
# 初始化一个ChatOpenAI模型实例
# temperature=0.0 表明我们希望模型输出更具确定性、更少的随机性
llm = ChatOpenAI(model="gpt-3.5-turbo", temperature=0.0)只需一行代码,我们就拥有了一个连接到OpenAI gpt-3.5-turbo模型的“客户端”。
1.2 发起调用 (invoke)
invoke是LangChain中最基础、最直接的调用方法。它发送一个请求,然后等待模型生成完整的响应后,一次性返回。
# first_interaction.py (续)
from langchain_core.messages import HumanMessage
# 准备我们的提示
prompt = "请用一句话解释什么是LangChain?"
# LangChain的输入一般是遵循特定模式的消息列表
# 这里我们使用HumanMessage来表明用户的输入
messages = [HumanMessage(content=prompt)]
# 使用invoke方法发起调用
response = llm.invoke(messages)
# 打印响应
print("------ 响应对象 ------")
print(response)
print("
------ 响应内容 ------")
print(response.content)运行与输出:
执行 python first_interaction.py,您可能会看到类似以下的输出:
------ 响应对象 ------
AIMessage(content='LangChain是一个开源框架,旨在通过提供一套通用接口和可组合的构建块,来简化和加速基于大型语言模型(LLM)的应用开发。', response_metadata={'token_usage': {'completion_tokens': 68, 'prompt_tokens': 20, 'total_tokens': 88}, 'model_name': 'gpt-3.5-turbo-0125', 'system_fingerprint': None, 'finish_reason': 'stop', 'logprobs': None}, id='run-a1b2c3d4-e5f6-g7h8-i9j0-k1l2m3n4o5p6')
------ 响应内容 ------
LangChain是一个开源框架,旨在通过提供一套通用接口和可组合的构建块,来简化和加速基于大型语言模型(LLM)的应用开发。解读:
- invoke方法返回的是一个AIMessage对象,这是LangChain中代表AI回复的标准格式。
- content属性包含了我们最关心的、AI生成的文本内容。
- response_metadata则包含了此次API调用的元数据,如消耗的token数量、使用的模型名称等,这对于成本控制和调试超级有用。
祝贺!您已经成功地完成了与LLM的第一次交互。但这只是开始。
第二章:效率与体验——流式(Streaming) VS 批量(Batch)
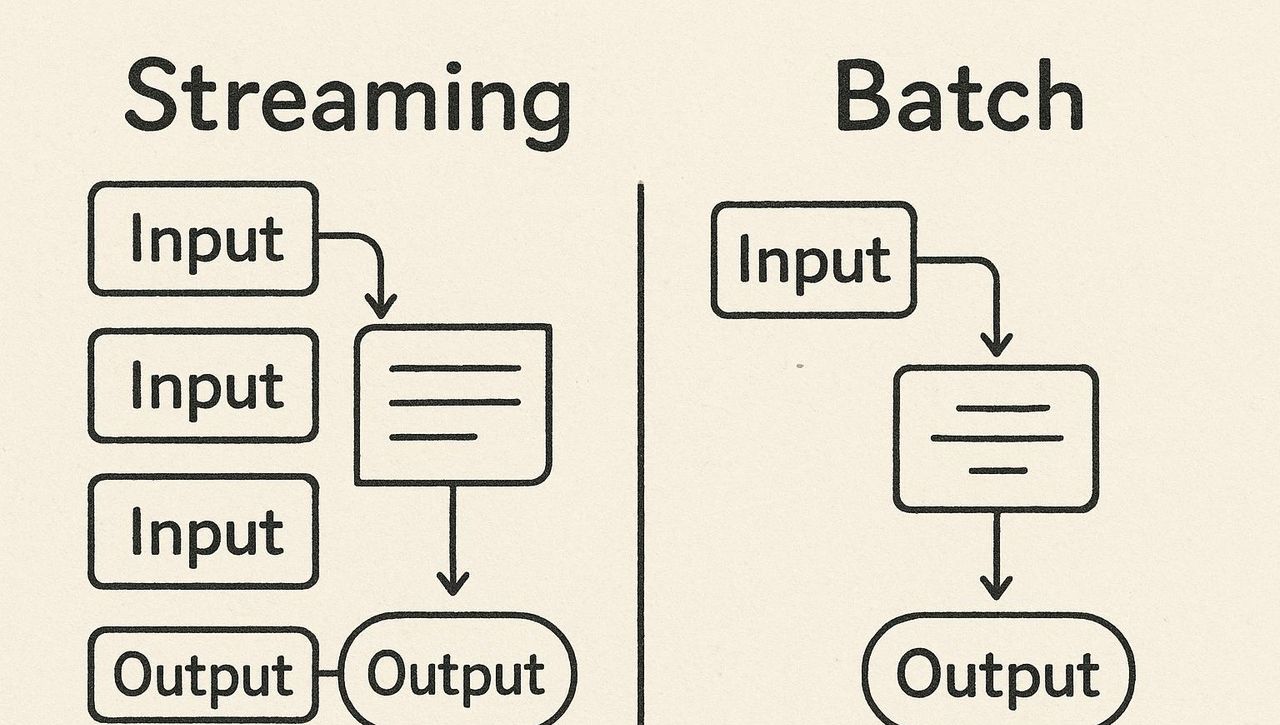
invoke方法虽然简单,但它有两个缺点:
- 用户体验不佳:如果LLM需要思考较长时间(例如生成一篇长文),用户界面会一直处于“等待”状态,直到所有内容生成完毕。
- 处理多个提示时效率低下:如果你有100个独立的提示需要处理,用for循环调用100次invoke,会产生100次网络往返,效率极低。
LangChain为此提供了两种强劲的解决方案:stream和batch。
2.1 流式响应 (stream):提升用户体验的利器
流式传输,就像观看在线视频一样,内容是“边加载边播放”的。LLM会将其生成的响应,一个词一个词(或一个token一个token)地实时发送回来。
# streaming_example.py
import time
from langchain_openai import ChatOpenAI
from langchain_core.messages import HumanMessage
llm = ChatOpenAI(model="gpt-3.5-turbo", temperature=0.0)
prompt = "请写一首关于程序员的五言绝句。"
messages = [HumanMessage(content=prompt)]
print("------ 流式响应开始 ------")
start_time = time.time()
# 使用stream方法,它会返回一个生成器
response_stream = llm.stream(messages)
full_response = ""
for chunk in response_stream:
# chunk也是一个AIMessage对象,但其content只包含一小部分内容
content_part = chunk.content
print(content_part, end="", flush=True) # flush=True确保内容被立即打印
full_response += content_part
time.sleep(0.05) # 模拟网络延迟,让效果更明显
end_time = time.time()
print(f"
------ 流式响应结束 (耗时: {end_time - start_time:.2f}秒) ------")
print(f"完整响应:
{full_response}")运行与输出:
您会看到诗句不是一次性出现的,而是一个字一个字地“蹦”出来,极大地提升了交互感。
为何选择 stream?
核心优势:显著降低用户的“感知延迟”。对于任何需要与用户进行实时对话的应用(如聊天机器人、AI助手),流式响应几乎是必须的选择。
2.2 批量处理 (batch):提升吞吐量的核心
当你需要处理大量独立的提示时(例如,对1000条用户评论进行情感分类),batch方法是你的不二之选。它将多个提示打包成一个请求,一次性发送给LLM服务提供商,由其进行并行处理。
# batch_example.py
import time
from langchain_openai import ChatOpenAI
from langchain_core.messages import HumanMessage
llm = ChatOpenAI(model="gpt-3.5-turbo", temperature=0.0)
# 准备一个包含多个独立提示的列表
prompts = [
"苹果公司是做什么的?",
"特斯拉的CEO是谁?",
"NVIDIA的主要业务是什么?",
"亚马逊的创始人是谁?",
"微软的总部在哪里?"
]
# 将提示列表转换为LangChain的消息格式列表
messages_list = [[HumanMessage(content=p)] for p in prompts]
print("------ 开始批量处理 ------")
start_time = time.time()
# 使用batch方法
batch_responses = llm.batch(messages_list)
end_time = time.time()
print(f"------ 批量处理结束 (耗时: {end_time - start_time:.2f}秒) ------")
# 打印结果
for i, response in enumerate(batch_responses):
print(f"提示 {i+1}: {prompts[i]}")
print(f"回答 {i+1}: {response.content}
")2.3 性能对比:invokevs.batch
让我们用实验数据来证明batch的威力。
# performance_comparison.py
import time
from langchain_openai import ChatOpenAI
from langchain_core.messages import HumanMessage
llm = ChatOpenAI(model="gpt-3.5-turbo", temperature=0.0)
prompts = [f"写一句关于数字{i}的有趣实际。" for i in range(10)]
messages_list = [[HumanMessage(content=p)] for p in prompts]
# --- 测试 sequential invoke ---
print("开始 sequential invoke 测试...")
start_invoke = time.time()
invoke_results = []
for msg in messages_list:
invoke_results.append(llm.invoke(msg))
end_invoke = time.time()
invoke_time = end_invoke - start_invoke
print(f"Sequential invoke 耗时: {invoke_time:.2f} 秒
")
# --- 测试 batch ---
print("开始 batch 测试...")
start_batch = time.time()
batch_results = llm.batch(messages_list)
end_batch = time.time()
batch_time = end_batch - start_batch
print(f"Batch 耗时: {batch_time:.2f} 秒
")
# --- 结论 ---
print("------ 性能对比结论 ------")
print(f"处理 {len(prompts)} 个提示:")
print(f"循环调用 invoke: {invoke_time:.2f} 秒")
print(f"单次调用 batch: {batch_time:.2f} 秒")
print(f"性能提升: {((invoke_time - batch_time) / invoke_time) * 100:.2f}%")预期结果:
你会发现,batch的处理时间远小于循环调用invoke的总时间。在我的测试中,处理10个提示,batch的耗时可能只有invoke循环的1/3到1/4。
为何选择 batch?
核心优势:大幅减少网络通信的开销。它将N次HTTP请求合并为1次,极大地提高了吞吐量(Throughput)。对于任何需要进行离线、大规模数据处理的场景,batch是提升效率、降低成本的关键。
第三章:迭代式开发——将提示从“能用”到“好用”
提示工程的核心,在于“工程”二字。它不是一蹴而就的灵感迸发,而是一个**“构思 -> 实验 -> 分析 -> 改善”**的循环过程。
我们的任务场景:从一段非结构化的职位描述(Job Description)文本中,提取出关键信息,并以结构化的JSON格式输出。
原始文本:
job_description_text = """
我们正在寻找一名高级Python工程师加入我们位于北京海淀的创新团队。
该职位要求至少5年Python开发经验,并熟练掌握Django框架。
成功的候选人将负责设计和实现可扩展的Web服务,并与我们的前端团队紧密合作。
熟悉Docker和Kubernetes者优先。
公司:Stark Industries
职位:Senior Python Developer
"""迭代一:天真的初版提示
最直接的想法,就是直接让LLM去提取。
- Prompt 1: f”请从以下职位描述中提取公司名称、职位名称和所需技能:
{job_description_text}”
可能的结果:公司名称:Stark Industries
职位名称:Senior Python Developer
所需技能:Python, Django, Docker, Kubernetes- 问题分析: 结果是非结构化的纯文本。在程序中,我们需要用复杂的正则表达式去解析它,超级脆弱。
迭代二:明确输出格式
我们需要“指导”LLM,告知它我们想要的格式。
- Prompt 2: f”请从以下职位描述中提取公司名称、职位名称和所需技能,并以严格的JSON格式输出。JSON应包含三个键:’company’, ‘title’, ‘skills’。
{job_description_text}”
可能的结果:{
"company": "Stark Industries",
"title": "Senior Python Developer",
"skills": ["Python", "Django", "Docker", "Kubernetes"]
}- 问题分析: 好多了!目前我们得到了可以在程序中直接解析的JSON。但如果遇到更复杂的文本,它能处理好吗?
迭代三:提供示例 (Few-Shot Prompting)
为了让LLM更好地理解我们的意图,我们可以给它一个或多个“范例”,这种方法称为Few-Shot Prompting。
Prompt 3:请从给定的职位描述中提取关键信息,并以严格的JSON格式输出。
示例输入:
"Data Scientist at Wayne Enterprises in Gotham. Requires expertise in machine learning and statistics."
示例输出:
{
"company": "Wayne Enterprises",
"title": "Data Scientist",
"skills": ["machine learning", "statistics"]
}
正式输入:
"我们正在寻找一名高级Python工程师加入我们位于加州山景城的创新团队。该职位要求至少5年Python开发经验,并熟练掌握Django框架。成功的候选人将负责设计和实现可扩展的Web服务,并与我们的前端团队紧密合作。熟悉Docker和Kubernetes者优先。公司:Stark Industries。职位:Senior Python Developer。"- 结果: 更加稳定和可靠。通过示例,LLM不仅知道了要提取什么,更学会了如何提取。
迭代四:处理边界情况与增加约束
如果文本中没有明确列出技能怎么办?
• Prompt 4:... (同Prompt 3的示例部分) ...
--
正式输入:
"Pym-Tech正在招聘一名初级产品经理,负责我们的粒子缩小项目。你将与工程团队一起定义产品路线图,并撰写需求文档。无需编程背景,但需要有极强的沟通能力和项目管理经验。"
请注意:如果技能没有被明确列出,请根据职责描述进行推断。技能列表(skills)必须是一个包含至少3个字符串的数组。
结果:{
"company": "Pym-Tech",
"title": "Junior Product Manager",
"skills": ["product roadmap", "communication", "project management"]
}
分析: 通过增加更精细的指令和约束,我们让提示能够处理更模糊和复杂的边界情况。总结:迭代式提示开发,是一个不断通过增加约束、明确格式、提供示例、处理边界来提升提示可靠性和稳定性的工程过程。
第四章:动态与复用——你的第一个提示模板
在上面的迭代中,我们每次都是用Python的f-string来手动拼接提示。这种方式在应用复杂后,会变得难以维护。LangChain为此提供了强劲的**提示模板(Prompt Templates)**功能。
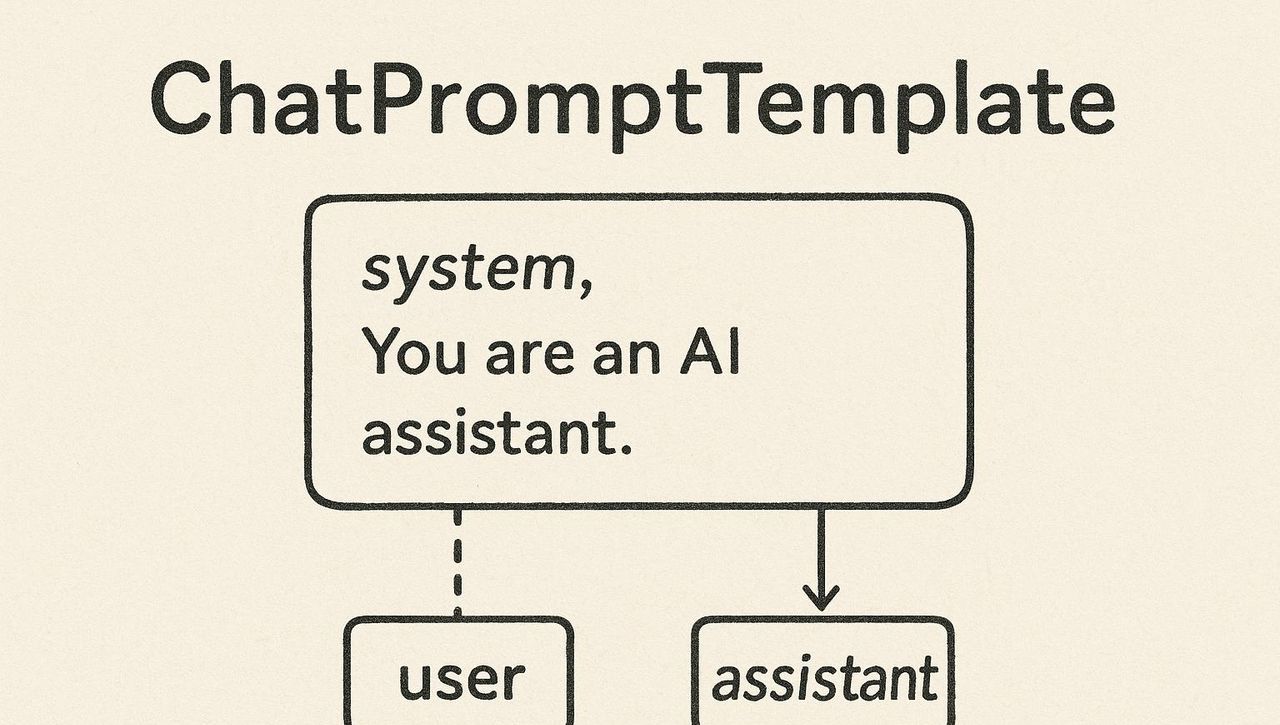
提示模板允许我们定义一个包含“变量”的、可复用的提示结构。
4.1 创建模板
ChatPromptTemplate是LangChain中用于创建聊天提示模板的核心工具。
# prompt_template_example.py
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
# 1. 定义一个包含占位符(变量)的模板字符串
template_string = """
请你扮演一名专业的翻译官。将以下由三个反引号包裹的文本,从{source_language}翻译成{target_language}。
文本:
```{text}```
"""
# 2. 从模板字符串创建ChatPromptTemplate实例
prompt_template = ChatPromptTemplate.from_template(template_string)4.2 使用模板和链 (Chains)
在LangChain中,我们将不同的组件(如提示模板、模型、输出解析器)通过一个管道符|(在LangChain中称为LCEL – LangChain Expression Language)连接起来,形成一个“链(Chain)”。
# prompt_template_example.py (续)
# 3. 初始化模型和输出解析器
llm = ChatOpenAI(model="gpt-3.5-turbo", temperature=0.0)
# StrOutputParser会将AIMessage的输出,简化为只包含内容的字符串
output_parser = StrOutputParser()
# 4. 使用LCEL将组件链接起来
# 流程: 字典输入 -> 填充提示模板 -> 调用LLM -> 解析输出为字符串
translation_chain = prompt_template | llm | output_parser
# 5. 调用链,并传入变量
input_vars = {
"source_language": "中文",
"target_language": "英文",
"text": "生命在于运动。"
}
result = translation_chain.invoke(input_vars)
print(f"翻译结果: {result}")
# 我们可以轻松地复用这个链,完成不同的翻译任务
input_vars_2 = {
"source_language": "英文",
"target_language": "法文",
"text": "Hello, world!"
}
result_2 = translation_chain.invoke(input_vars_2)
print(f"第二次翻译结果: {result_2}")运行与输出:
翻译结果: Life lies in movement.
第二次翻译结果: Bonjour, le monde !优势总结:
- 可复用性:同一个模板和链,可以通过传入不同的变量,完成不同的任务。
- 逻辑清晰:将提示的“结构”与待填充的“数据”分离开来,代码更易读、更易维护。
- 模块化:LCEL的管道设计,让我们能像搭乐高积木一样,轻松地组合和替换不同的组件。
总结:LangChain之旅才刚刚开始
祝贺你,完成了本次的实战教程!
我们一起走过了从一个简单的invoke调用,到体验stream和batch带来的变革,再到亲历一个提示从“粗糙”到“精良”的迭代过程,最后掌握了使用ChatPromptTemplate和LCEL构建动态、可复用应用的核心技能。
这些,正是构建任何复杂LLM应用的基石。你目前已经不再是一个门外汉,而是一位手持LangChain利器,懂得如何与LLM高效沟通的“LangChain工程师”。
下一步学习方向:
- 输出解析器 (Output Parsers):学习如何让LLM的输出自动解析成Pydantic对象、JSON或其他自定义格式。
- 检索增强生成 (RAG):探索如何将你自己的私有数据(如PDF、数据库)与LLM结合,构建一个能回答特定领域问题的知识库机器人。
- 智能体 (Agents):迈向终极目标,构建一个能调用外部工具(如搜索引擎、计算器、API)来完成复杂任务的AI智能体。
提示工程和LangChain的世界广阔无垠,充满了无限的创造可能。希望这篇能成为您探索AI新世界的一张坚实的地图!!
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...







![[理论篇-10]AI 工作流(AI Workflow)—— 让 AI 像流水线一样干活](https://www.dunling.com/img/7.jpg)



