

 #机器坏人 #机器学习 #人工智能 #AI新手村 #AI便利店 #scaling_law #深度学习 #原创漫画 #漫画科普 #AI科普
#机器坏人 #机器学习 #人工智能 #AI新手村 #AI便利店 #scaling_law #深度学习 #原创漫画 #漫画科普 #AI科普
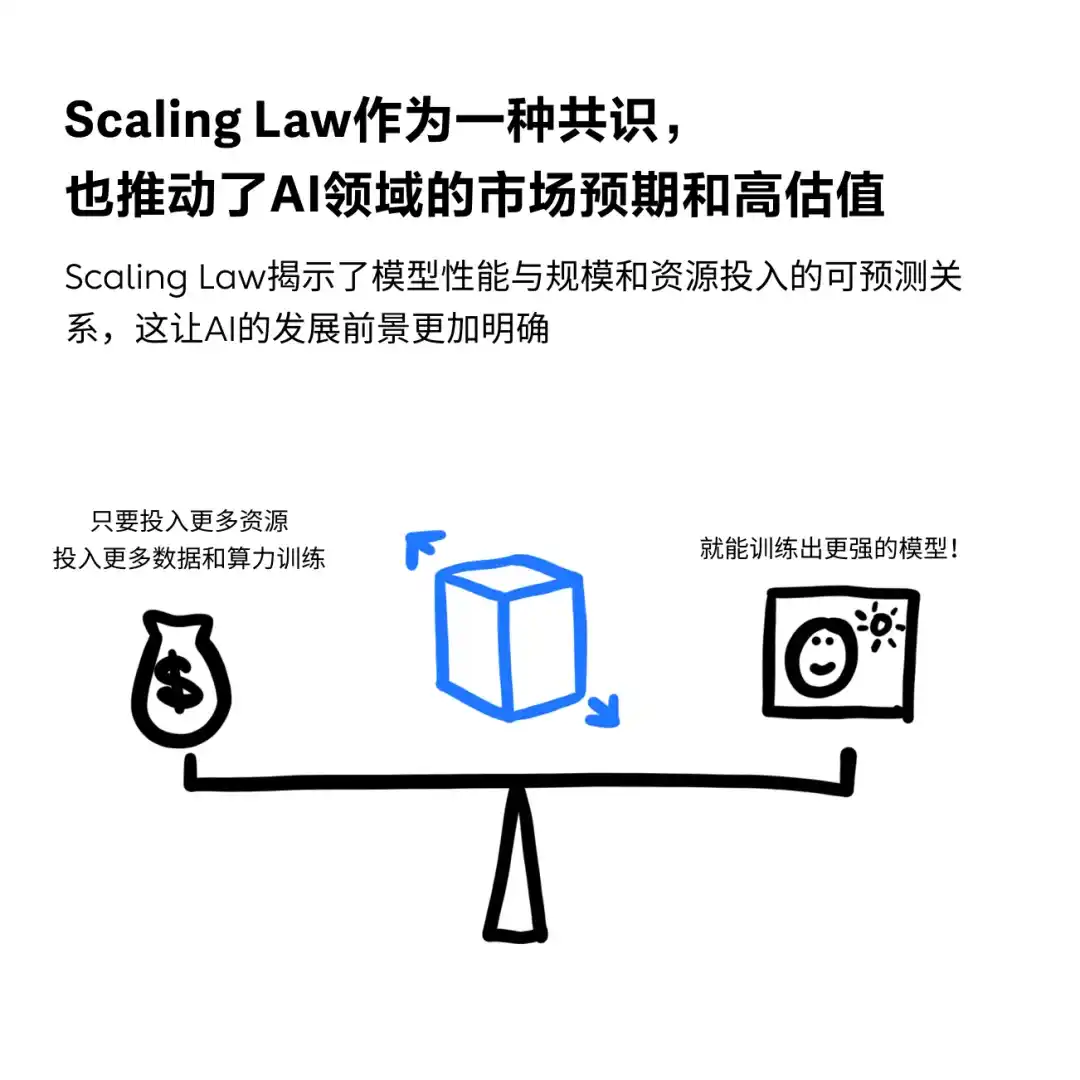
画的太好了,图二中的数据量,模型参数量,芯片的算力这三个让我想起几个数字。三者的比例曾经发生过一些变化,列如scaling law的开篇论文提到数据量是参数量的20倍,效果会最好,但后来发现这个这个比例依旧可以上升,目前的比例可能是上百倍,千倍,列如 2023 年 7 月中旬,llama2 发布,其中 7B 版本的小模型训练数据有 2T,是参数量的 285 倍。
不过算力和参数量的比例是可以通过理论计算出来的,一般情况下是计算量是参数量的20倍。
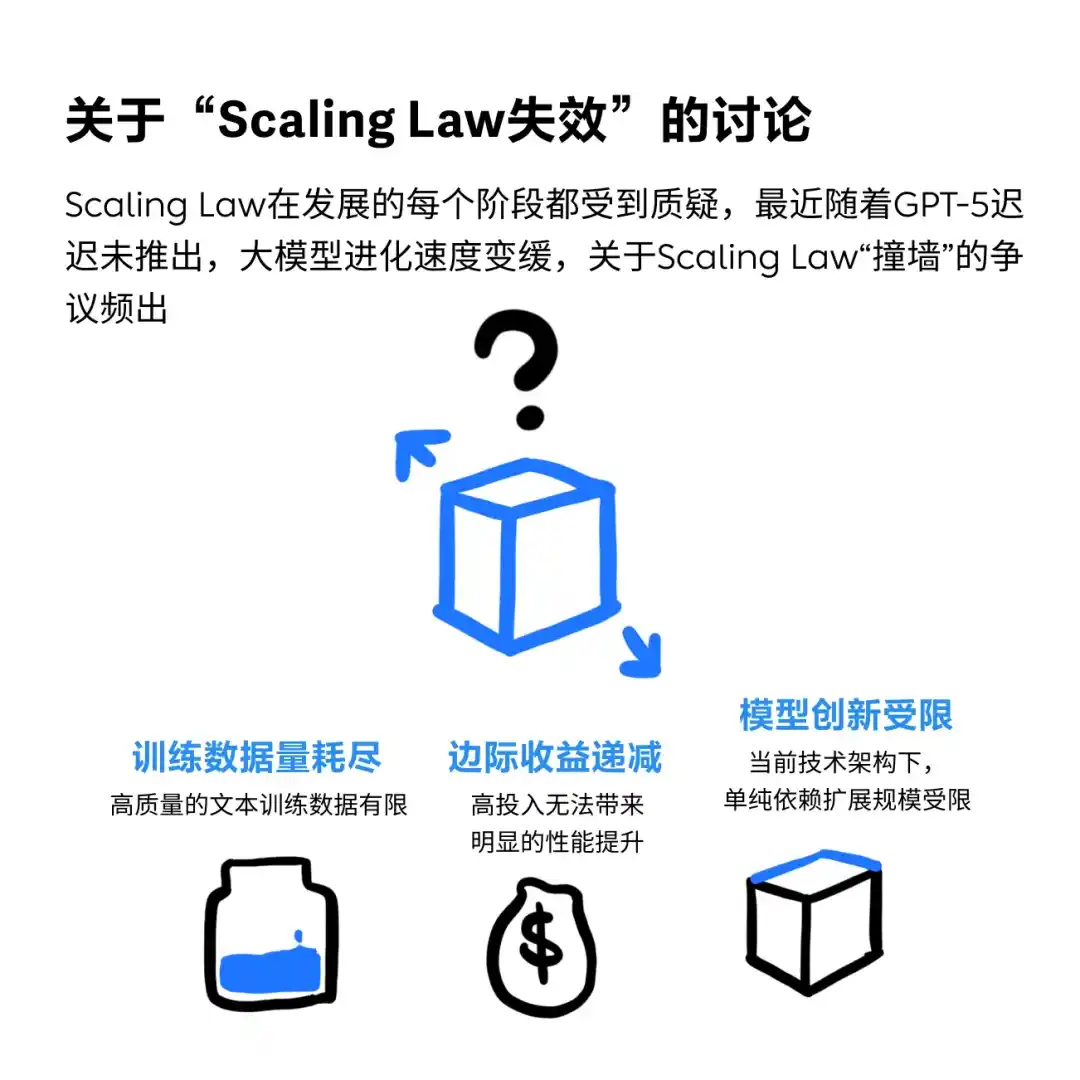
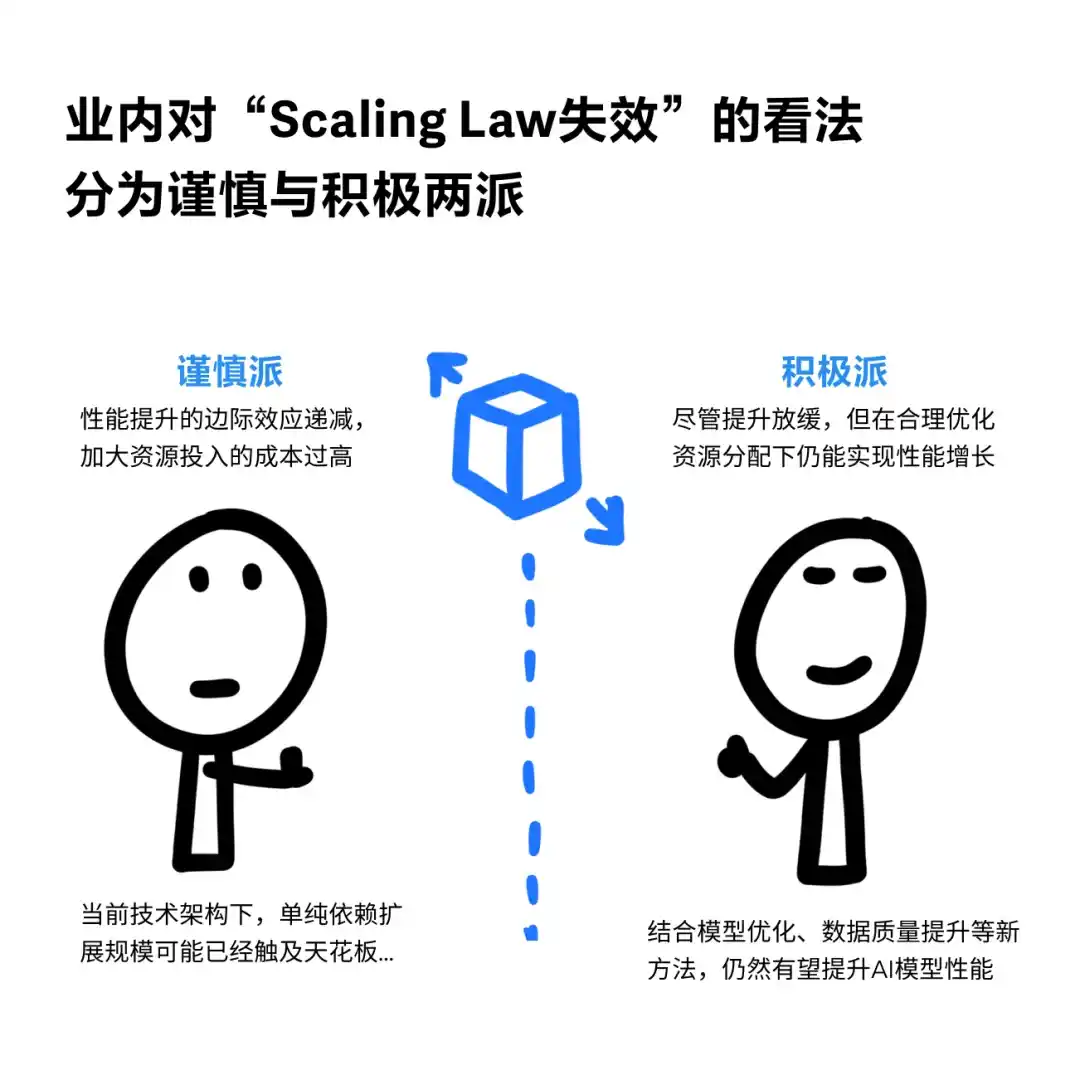
目前的scaling law的确 有点难以持续前进了,不过即使撞墙,感觉模型能力已经很强了。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章
没有相关内容!









你真棒 博主 夸夸你 内容很好 [g=shuai]
最sb的翻译就是所谓“缩放定理”。楼主用原名挺好
[g=huaixiao][g=huaixiao] 大力出奇迹~
二姐果然专业!
目前呢
@小罗睡不醒
数据质量提升和场景模型优化或许可以缓解SL失效问题,感觉还是挺有道理的。对于多模态模型而言,实则本来数据集就没有文本数据那么多(列如3D资产的数据就超级有限,完全没法大力出奇迹)。但是还是狠狠担忧呀,基座模型到止步这里,垂类模型的天花板还能多高呢?如果未来模型将会足够成熟的假设不能成立,下游这些应用的发展空间和成熟度是否也隐隐能看到天花板,ai产品经理机会或许也并不会那么乐观
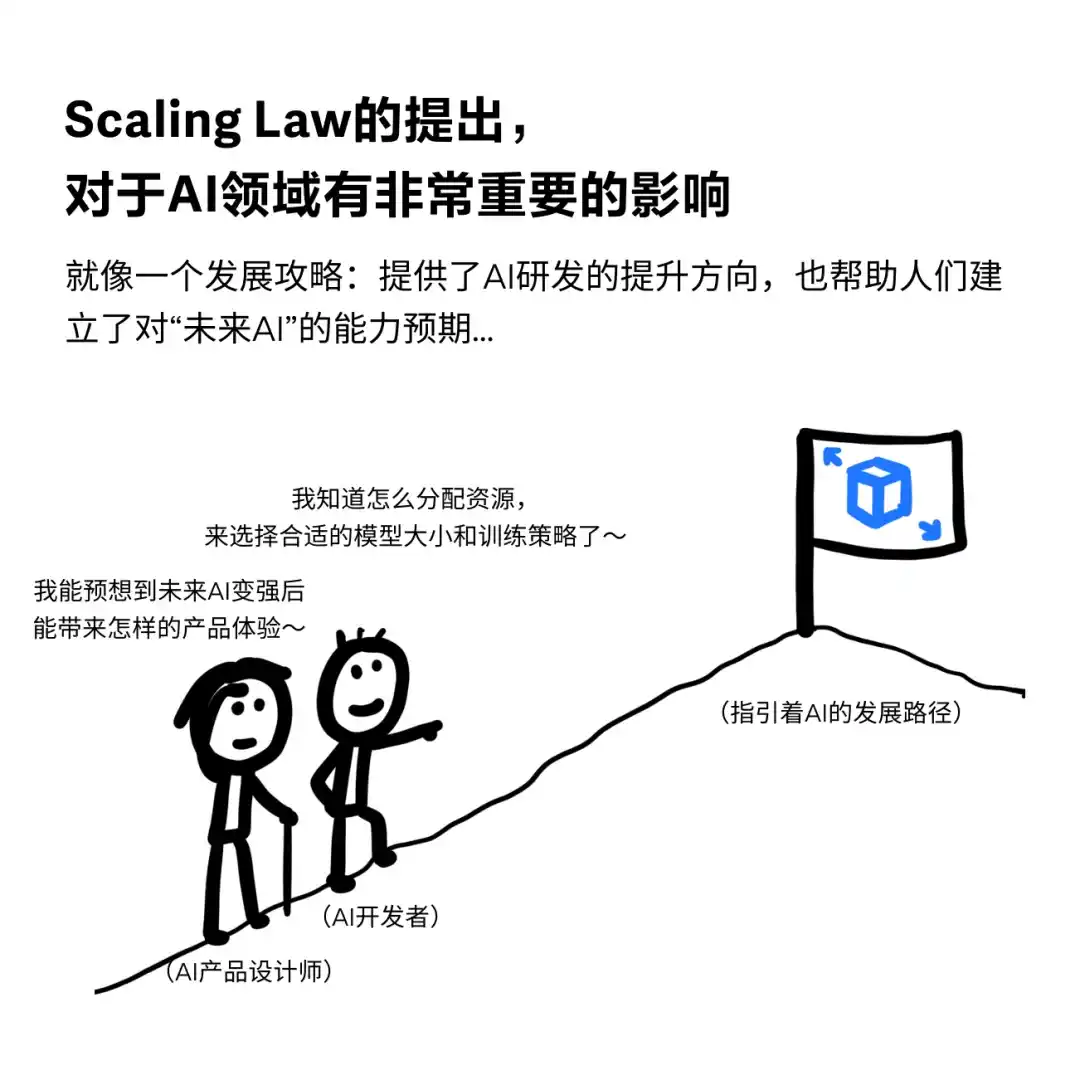
Scaling Law 缩放定律
省流:力大砖飞
不是百度2017年提出的么
?
谢谢
大计科号令天下,谁与争锋!