在LLM领域,大家早就习惯用 scaling law 来预测性能了:给定算力(FLOPs)、数据量、模型大小,大概就能算出什么 batch size、多少 epoch 才是最优解。小实验的结果就能推测出大规模的表现,不用真的烧掉几百万 GPU 小时去试错。 但到了RL,情况要复杂的多。LLM 的训练数据是固定的,RL 原po github:scaling law for value based rl
 在LLM领域,大家早就习惯用 scaling law 来预测性能了:给定算力(FLOPs)、数据量、模型大小,大概就能算出什么 batch size、多少 epoch 才是最优解。小实验的结果就能推测出大规模的表现,不用真的烧掉几百万 GPU 小时去试错。
在LLM领域,大家早就习惯用 scaling law 来预测性能了:给定算力(FLOPs)、数据量、模型大小,大概就能算出什么 batch size、多少 epoch 才是最优解。小实验的结果就能推测出大规模的表现,不用真的烧掉几百万 GPU 小时去试错。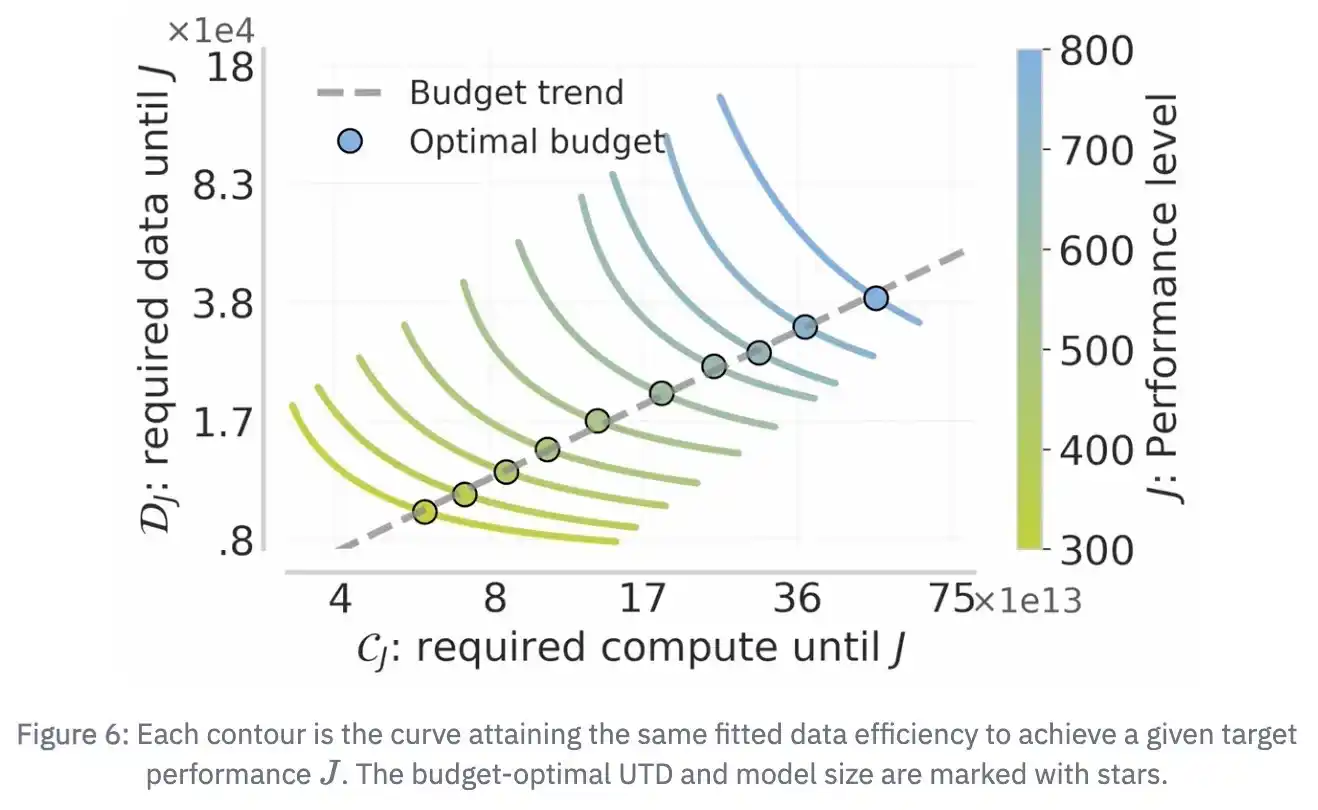
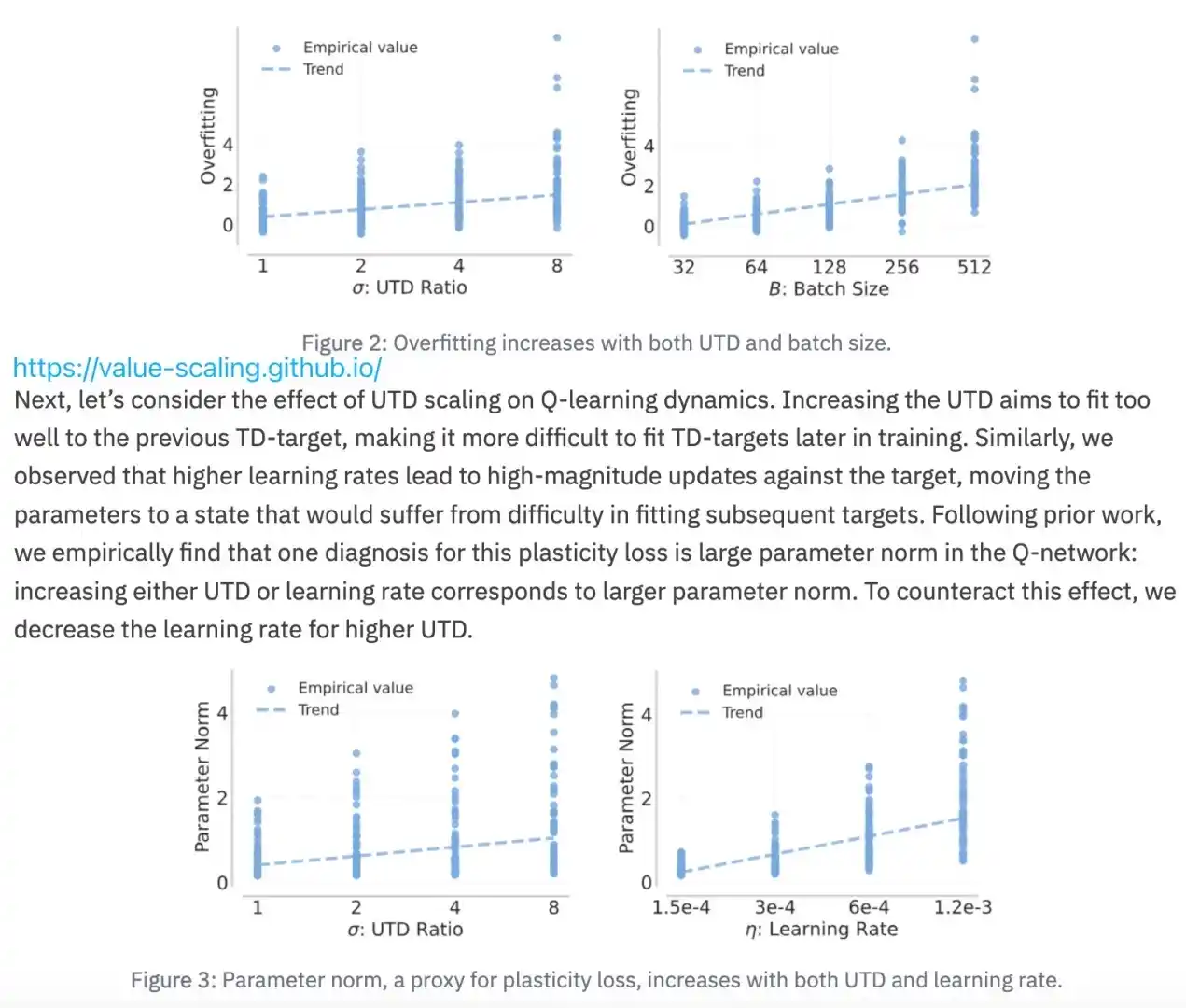
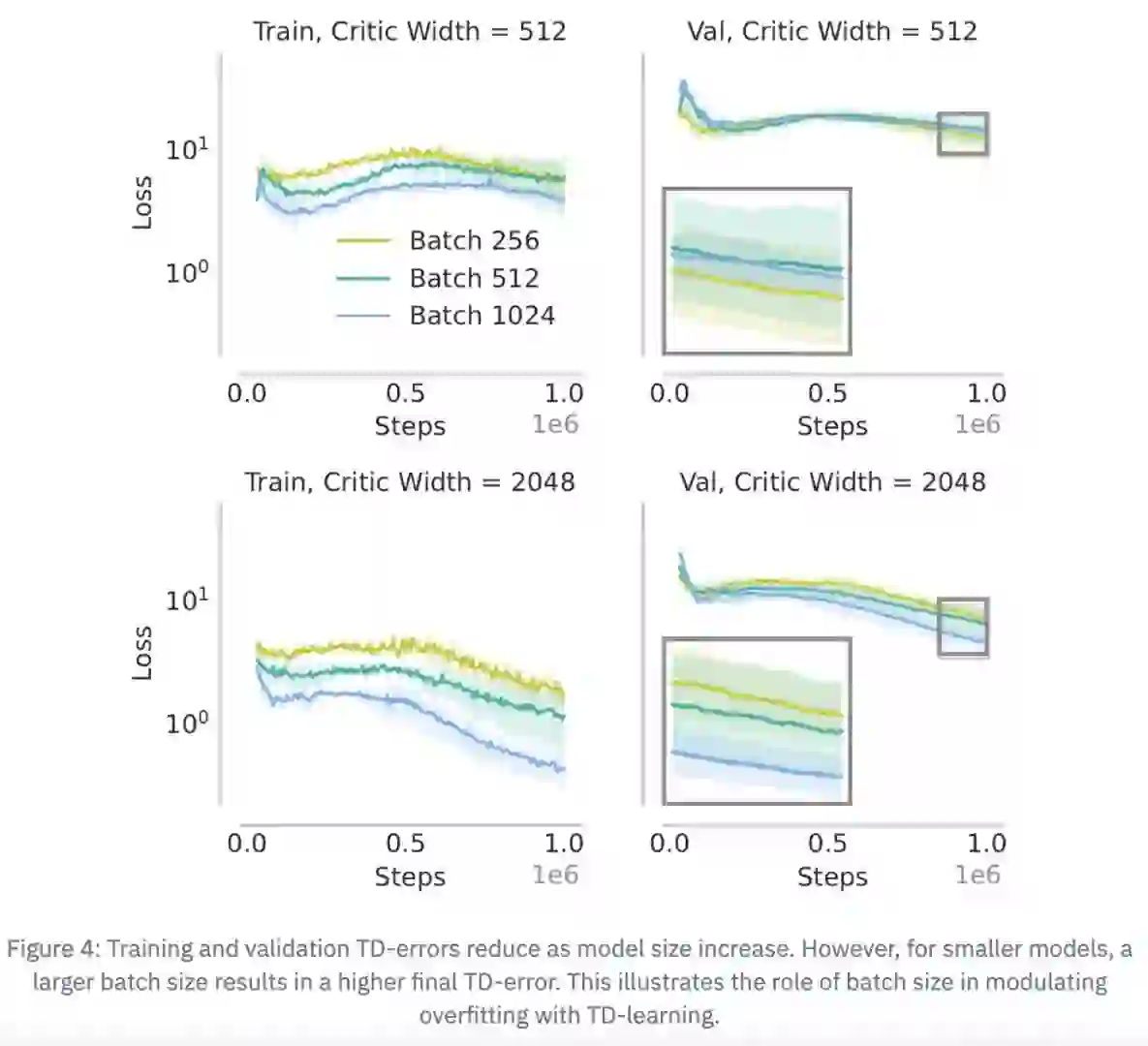 在LLM领域,大家早就习惯用 scaling law 来预测性能了:给定算力(FLOPs)、数据量、模型大小,大概就能算出什么 batch size、多少 epoch 才是最优解。小实验的结果就能推测出大规模的表现,不用真的烧掉几百万 GPU 小时去试错。
在LLM领域,大家早就习惯用 scaling law 来预测性能了:给定算力(FLOPs)、数据量、模型大小,大概就能算出什么 batch size、多少 epoch 才是最优解。小实验的结果就能推测出大规模的表现,不用真的烧掉几百万 GPU 小时去试错。











