DETR详细结构图如下:
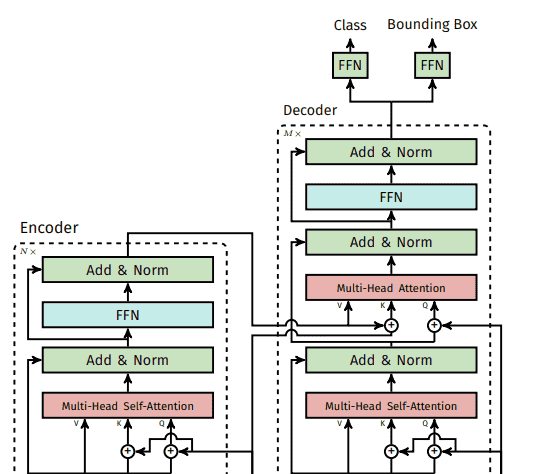
1、DETR 设计的点主要有两个:
1)提出了一种新的目标检测的损失函数。通过二分图匹配的方式,强制模型输出一个独特的预测,对图像中的每个物体只输出一个预测框;
2)使用了 Transformer Encoder-Decoder 的架构。相比于原始的 Transformer,为了适配目标检测任务,DETR 的 Decoder 还需要输入一个可学习的目标查询(learned object query),并且 DETR 的 Decoder 可以对每个类别进行并行预测。
2、DETR 的流程可以分为四个步骤:
1)通过 CNN 提取输入图像的特征;
2)将 CNN 特征拉直,送入 Transformer Encoder 中进一步通过自注意力学习全局的特征;
关于 Encoder 的作用,一个直观的理解是:Transformer Encoder 学习到的全局特征有利用移除对于同一个物体的多个冗余的框。具体来说,Transformer 中的自注意力机制,使得特征图中的每个位置都能 attend 到图中所有的其他特征,这样模型就能大致知道哪一个区域是一个物体,哪个区域又是另一个物体,从而能够尽量保证每个物体只出一个预测框;
3)通过 Transformer Decoder 生成输出框;
注意输入到 Decoder 的,除了 Encoder 提取的特征之外,还有 learned object query。图像特征与 learned object query 在 Decoder 中通过自注意力机制进行交互,输出预测框。输出的框的个数是由 learned object query 决定的,是一个固定的值 N,原文中设置的是 100;
4)计算生成的 N 个输出框与 Ground Truth 的损失函数;
输出的框是固定 N 个,实际数据集中的 GT 框一般只有几个且个数不定,计算 loss 时,论文提出通过二分图匹配来选出 N 个输出框中与 M 个 GT 框最匹配的 M 个,然后再像常规目标检测方法一样计算它们之间的损失,即分类损失和边框回归损失。
在推理时,直接对输出的 N 个框卡一个阈值,作为预测结果即可。
3、DETR的encoder-decoder结构和transformer的区别
1)spatial positional encoding:新提出的二维空间位置编码方法,输入维度为(H*W, C),其中H/W/C为CNN主干输出的维度信息,DETR源码中给出了两种位置编码方法:正弦位置编码(Sine Position Encoding)和可学习位置编码(Learnable Positional Encoding),默认使用正弦位置编码:通过正弦和余弦函数的组合,控制固定的频率,sin/cos周期从大到小,可以编码不同粒度的顺序信息;
位置编码具体原理:
https://www.bilibili.com/video/BV15AMXz6EGL
该位置编码分别被加入到了encoder的self attention的QK和decoder的cross attention的K,同时object queries也被加入到了decoder的两个attention(第一个加到了QK中,第二个加入了Q)中。而原版的Transformer将位置编码加到了input和output embedding中。
2)DETR在计算attention的时候没有使用masked attention,因为将特征图展开成一维以后,所有像素都可能是互相关联的,因此没必要规定mask。
3)object queries的转换过程:object queries是预定义的目标查询的个数,网络初始化时为随机生成的一组可学习的向量,代码中个数默认为100。它的意义是:根据Encoder编码的特征,Decoder将100个查询转化成100个目标,即最终预测这100个目标的类别和bbox位置。最终预测得到的shape应该为[N, 100, C],N为Batch Num,100个目标,C为预测的100个目标的类别数+1(背景类)以及bbox位置(4个值)。
4)得到预测结果以后,将object predictions和ground truth box之间通过匈牙利算法进行二分匹配:假如有K个目标,那么100个object predictions中就会有K个能够匹配到这K个ground truth,其他的都会和“no object”匹配成功,使其在理论上每个object query都有唯一匹配的目标,不会存在重叠,所以DETR不需要nms进行后处理。
5)分类loss采用的是交叉熵损失,针对所有predictions;bbox loss采用了L1 loss和giou loss,针对匹配成功的predictions。
transformer的结构详解如下:
Transformer模型原理细节解析_transflow-CSDN博客
二分图匈牙利匹配算法的解析如下:
DeepSort整体流程梳理及匈牙利算法解析_deepsort 匈牙利算法-CSDN博客
4、代码解读:
DETR源码细节全解读:关键模块与核心代码剖析-CSDN博客
DETR 模型结构源码 – 贝壳里的星海 – 博客园
5、训练测试
5.1、训练
借鉴链接:
【DETR】训练自己的数据集-实践笔记_detr训练量-CSDN博客
其中,yolo转coco脚本为:
1)yolo2json
import os
import glob
import numpy as np
import cv2
import json
# 可以将yolov8目标检测生成的txt格式的标注转为json,可以使用labelme查看标注
# 该方法可以用于辅助数据标注
def convert_txt_to_labelme_json(txt_path, image_path, output_dir, class_name, image_fmt='.png' ):
"""
将文本文件转换为LabelMe格式的JSON文件。
此函数处理文本文件中的数据,将其转换成LabelMe标注工具使用的JSON格式。包括读取图像,
解析文本文件中的标注信息,并生成相应的JSON文件。
:param txt_path: 文本文件所在的路径
:param image_path: 图像文件所在的路径
:param output_dir: 输出JSON文件的目录
:param class_name: 类别名称列表,索引对应类别ID
:param image_fmt: 图像文件格式,默认为'.jpg'
:return:
"""
# 获取所有文本文件路径
txts = glob.glob(os.path.join(txt_path, "*.txt"))
for txt in txts:
# 初始化LabelMe JSON结构
labelme_json = {
'version': '5.5.0',
'flags': {},
'shapes': [],
'imagePath': None,
'imageData': None,
'imageHeight': None,
'imageWidth': None,
}
# 获取文本文件名
txt_name = os.path.basename(txt)
# 根据文本文件名生成对应的图像文件名
image_name = txt_name.split(".")[0] + image_fmt
labelme_json['imagePath'] = image_name
# 构造完整图像路径
image_name = os.path.join(image_path, image_name)
# 检查图像文件是否存在,如果不存在则抛出异常
if not os.path.exists(image_name):
raise Exception('txt 文件={},找不到对应的图像={}'.format(txt, image_name))
# 读取图像
image = cv2.imdecode(np.fromfile(image_name, dtype=np.uint8), cv2.IMREAD_COLOR)
# 获取图像高度和宽度
h, w = image.shape[:2]
labelme_json['imageHeight'] = h
labelme_json['imageWidth'] = w
# 读取文本文件内容
with open(txt, 'r') as t:
lines = t.readlines()
for line in lines:
point_list = []
content = line.split(' ')
# 根据类别ID获取标签名称
label = class_name[int(content[0])] # 标签
# 解析点坐标
for index in range(1, len(content)):
if index == 1: # 中心点归一化的x坐标
cx = float(content[index])
if index == 2: # 中心点归一化的y坐标
cy = float(content[index])
if index == 3: # 归一化的目标框宽度
wi = float(content[index])
if index == 4: # 归一化的目标框高度
hi = float(content[index])
x1 = (2 * cx * w - w * wi) / 2
x2 = (w * wi + 2 * cx * w) / 2
y1 = (2 * cy * h - h * hi) / 2
y2 = (h * hi + 2 * cy * h) / 2
point_list.append(x1)
point_list.append(y1)
point_list.append(x2)
point_list.append(y2)
# 将点列表转换为二维列表,每两个值表示一个点
point_list = [point_list[i:i+2] for i in range(0, len(point_list), 2)]
# 构造shape字典
shape = {
'label': label,
'points': point_list,
'group_id': None,
'description': None,
'shape_type': 'rectangle',
'flags': {},
'mask': None
}
labelme_json['shapes'].append(shape)
# 生成JSON文件名
json_name = txt_name.split('.')[0] + '.json'
json_name_path = os.path.join(output_dir, json_name)
# 写入JSON文件
fd = open(json_name_path, 'w')
json.dump(labelme_json, fd, indent=2)
fd.close()
# 输出保存信息
print("save json={}".format(json_name_path))
if __name__ == '__main__':
txt_path = r'./labels'
image_path = r'./images'
output_dir = r'./json'
# 标签列表
class_name = ['pillar', 'wheel_chock'] # 标签类别名
convert_txt_to_labelme_json(txt_path, image_path, output_dir, class_name)2)json2coco
# 命令行执行: python labelme2coco.py --input_dir images --output_dir coco --labels labels.txt
# 输出文件夹必须为空文件夹
import argparse
import collections
import datetime
import glob
import json
import os
import os.path as osp
import sys
import uuid
import imgviz
import numpy as np
import labelme
from sklearn.model_selection import train_test_split
try:
from typing import Literal
except ImportError:
from typing_extensions import Literal
try:
import pycocotools.mask
except ImportError:
print("Please install pycocotools:
pip install pycocotools
")
sys.exit(1)
def to_coco(args,label_files,train):
# 创建 总标签data
now = datetime.datetime.now()
data = dict(
info=dict(
description=None,
url=None,
version=None,
year=now.year,
contributor=None,
date_created=now.strftime("%Y-%m-%d %H:%M:%S.%f"),
),
licenses=[dict(url=None, id=0, name=None,)],
images=[
# license, url, file_name, height, width, date_captured, id
],
type="instances",
annotations=[
# segmentation, area, iscrowd, image_id, bbox, category_id, id
],
categories=[
# supercategory, id, name
],
)
# 创建一个 {类名 : id} 的字典,并保存到 总标签data 字典中。
class_name_to_id = {}
for i, line in enumerate(open(args.labels).readlines()):
class_id = i - 1 # starts with -1
class_name = line.strip() # strip() 方法用于移除字符串头尾指定的字符(默认为空格或换行符)或字符序列。
if class_id == -1:
assert class_name == "__ignore__" # background:0, class1:1, ,,
continue
class_name_to_id[class_name] = class_id
data["categories"].append(
dict(supercategory=None, id=class_id, name=class_name,)
)
if train:
out_ann_file = osp.join(args.output_dir, "annotations","instances_train2017.json")
else:
out_ann_file = osp.join(args.output_dir, "annotations","instances_val2017.json")
for image_id, filename in enumerate(label_files):
label_file = labelme.LabelFile(filename=filename)
base = osp.splitext(osp.basename(filename))[0] # 文件名不带后缀
if train:
out_img_file = osp.join(args.output_dir, "train2017", base + ".png")
else:
out_img_file = osp.join(args.output_dir, "val2017", base + ".png")
print("| ",out_img_file)
# ************************** 对图片的处理开始 *******************************************
# 将标签文件对应的图片进行保存到对应的 文件夹。train保存到 train2017/ test保存到 val2017/
img = labelme.utils.img_data_to_arr(label_file.imageData) # .json文件中包含图像,用函数提出来
imgviz.io.imsave(out_img_file, img) # 将图像保存到输出路径
# ************************** 对图片的处理结束 *******************************************
# ************************** 对标签的处理开始 *******************************************
data["images"].append(
dict(
license=0,
url=None,
file_name=osp.relpath(out_img_file, osp.dirname(out_ann_file)),
# out_img_file = "/coco/train2017/1.png"
# out_ann_file = "/coco/annotations/annotations_train2017.json"
# osp.dirname(out_ann_file) = "/coco/annotations"
# file_name = .. rain20171.png out_ann_file文件所在目录下 找 out_img_file 的相对路径
height=img.shape[0],
width=img.shape[1],
date_captured=None,
id=image_id,
)
)
masks = {} # for area
segmentations = collections.defaultdict(list) # for segmentation
for shape in label_file.shapes:
points = shape["points"]
label = shape["label"]
group_id = shape.get("group_id")
shape_type = shape.get("shape_type", "polygon")
mask = labelme.utils.shape_to_mask(
img.shape[:2], points, shape_type
)
if group_id is None:
group_id = uuid.uuid1()
instance = (label, group_id)
if instance in masks:
masks[instance] = masks[instance] | mask
else:
masks[instance] = mask
if shape_type == "rectangle":
(x1, y1), (x2, y2) = points
x1, x2 = sorted([x1, x2])
y1, y2 = sorted([y1, y2])
points = [x1, y1, x2, y1, x2, y2, x1, y2]
else:
points = np.asarray(points).flatten().tolist()
segmentations[instance].append(points)
segmentations = dict(segmentations)
for instance, mask in masks.items():
cls_name, group_id = instance
if cls_name not in class_name_to_id:
continue
cls_id = class_name_to_id[cls_name]
mask = np.asfortranarray(mask.astype(np.uint8))
mask = pycocotools.mask.encode(mask)
area = float(pycocotools.mask.area(mask))
bbox = pycocotools.mask.toBbox(mask).flatten().tolist()
data["annotations"].append(
dict(
id=len(data["annotations"]),
image_id=image_id,
category_id=cls_id,
segmentation=segmentations[instance],
area=area,
bbox=bbox,
iscrowd=0,
)
)
# ************************** 对标签的处理结束 *******************************************
# # ************************** 可视化的处理开始 *******************************************
# if not args.noviz:
# labels, captions, masks = zip(
# *[
# (class_name_to_id[cnm], cnm, msk)
# for (cnm, gid), msk in masks.items()
# if cnm in class_name_to_id
# ]
# )
# viz = imgviz.instances2rgb(
# image=img,
# labels=labels,
# masks=masks,
# captions=captions,
# font_size=15,
# line_width=2,
# )
# out_viz_file = osp.join(
# args.output_dir, "visualization", base + ".png"
# )
# imgviz.io.imsave(out_viz_file, viz)
# # ************************** 可视化的处理结束 *******************************************
with open(out_ann_file, "w") as f: # 将每个标签文件汇总成data后,保存总标签data文件
json.dump(data, f)
# 主程序执行
def main():
parser = argparse.ArgumentParser(
formatter_class=argparse.ArgumentDefaultsHelpFormatter
)
parser.add_argument("--input_dir", default="images", help="input annotated directory")
parser.add_argument("--output_dir", default="coco", help="output dataset directory")
parser.add_argument("--labels", default="labels.txt", help="labels file", required=True)
parser.add_argument("--noviz", help="no visualization", action="store_true")
args = parser.parse_args()
if osp.exists(args.output_dir):
print("Output directory already exists:", args.output_dir)
sys.exit(1)
os.makedirs(args.output_dir)
print("| Creating dataset dir:", args.output_dir)
if not args.noviz:
os.makedirs(osp.join(args.output_dir, "visualization"))
# 创建保存的文件夹
if not os.path.exists(osp.join(args.output_dir, "annotations")):
os.makedirs(osp.join(args.output_dir, "annotations"))
if not os.path.exists(osp.join(args.output_dir, "train2017")):
os.makedirs(osp.join(args.output_dir, "train2017"))
if not os.path.exists(osp.join(args.output_dir, "val2017")):
os.makedirs(osp.join(args.output_dir, "val2017"))
# 获取目录下所有的.png文件列表
feature_files = glob.glob(osp.join(args.input_dir, "*.png"))
print('| Image number: ', len(feature_files))
# 获取目录下所有的joson文件列表
label_files = glob.glob(osp.join(args.input_dir, "*.json"))
print('| Json number: ', len(label_files))
# feature_files:待划分的样本特征集合 label_files:待划分的样本标签集合 test_size:测试集所占比例
# x_train:划分出的训练集特征 x_test:划分出的测试集特征 y_train:划分出的训练集标签 y_test:划分出的测试集标签
x_train, x_test, y_train, y_test = train_test_split(feature_files, label_files, test_size=0.3)
print("| Train number:", len(y_train), ' Value number:', len(y_test))
# 把训练集标签转化为COCO的格式,并将标签对应的图片保存到目录 /train2017/
print("—"*20)
print("| Train images:")
to_coco(args,y_train,train=True)
# 把测试集标签转化为COCO的格式,并将标签对应的图片保存到目录 /val2017/
print("—"*20)
print("| Test images:")
to_coco(args,y_test,train=False)
if __name__ == "__main__":
print("—"*20)
main()
print("—"*20)5.2 测试
import argparse
import random
import time
from pathlib import Path
import numpy as np
import torch
from models import build_model
from PIL import Image
import os
import torchvision
from torchvision.ops.boxes import batched_nms
import cv2
#-------------------------------------------------------------------------设置参数
def get_args_parser():
parser = argparse.ArgumentParser('Set transformer detector', add_help=False)
parser.add_argument('--lr', default=1e-4, type=float)
parser.add_argument('--lr_backbone', default=1e-5, type=float)
parser.add_argument('--batch_size', default=2, type=int)
parser.add_argument('--weight_decay', default=1e-4, type=float)
parser.add_argument('--epochs', default=300, type=int)
parser.add_argument('--lr_drop', default=200, type=int)
parser.add_argument('--clip_max_norm', default=0.1, type=float,
help='gradient clipping max norm')
# Model parameters
parser.add_argument('--frozen_weights', type=str, default=None,
help="Path to the pretrained model. If set, only the mask head will be trained")
# * Backbone
parser.add_argument('--backbone', default='resnet50', type=str,
help="Name of the convolutional backbone to use")
parser.add_argument('--dilation', action='store_true',
help="If true, we replace stride with dilation in the last convolutional block (DC5)")
parser.add_argument('--position_embedding', default='sine', type=str, choices=('sine', 'learned'),
help="Type of positional embedding to use on top of the image features")
# * Transformer
parser.add_argument('--enc_layers', default=6, type=int,
help="Number of encoding layers in the transformer")
parser.add_argument('--dec_layers', default=6, type=int,
help="Number of decoding layers in the transformer")
parser.add_argument('--dim_feedforward', default=2048, type=int,
help="Intermediate size of the feedforward layers in the transformer blocks")
parser.add_argument('--hidden_dim', default=256, type=int,
help="Size of the embeddings (dimension of the transformer)")
parser.add_argument('--dropout', default=0.1, type=float,
help="Dropout applied in the transformer")
parser.add_argument('--nheads', default=8, type=int,
help="Number of attention heads inside the transformer's attentions")
parser.add_argument('--num_queries', default=100, type=int,
help="Number of query slots")
parser.add_argument('--pre_norm', action='store_true')
# * Segmentation
parser.add_argument('--masks', action='store_true',
help="Train segmentation head if the flag is provided")
# Loss
parser.add_argument('--no_aux_loss', dest='aux_loss', default='False',
help="Disables auxiliary decoding losses (loss at each layer)")
# * Matcher
parser.add_argument('--set_cost_class', default=1, type=float,
help="Class coefficient in the matching cost")
parser.add_argument('--set_cost_bbox', default=5, type=float,
help="L1 box coefficient in the matching cost")
parser.add_argument('--set_cost_giou', default=2, type=float,
help="giou box coefficient in the matching cost")
# * Loss coefficients
parser.add_argument('--mask_loss_coef', default=1, type=float)
parser.add_argument('--dice_loss_coef', default=1, type=float)
parser.add_argument('--bbox_loss_coef', default=5, type=float)
parser.add_argument('--giou_loss_coef', default=2, type=float)
parser.add_argument('--eos_coef', default=0.1, type=float,
help="Relative classification weight of the no-object class")
# dataset parameters
parser.add_argument('--dataset_file', default='coco')
parser.add_argument('--coco_path', type=str,default="G:/RT-DETR/detr-main/datasets/train-data/coco")
parser.add_argument('--coco_panoptic_path', type=str)
parser.add_argument('--remove_difficult', action='store_true')
parser.add_argument('--output_dir', default='G:/RT-DETR/detr-main/inference',
help='path where to save, empty for no saving')
parser.add_argument('--device', default='cuda',
help='device to use for training / testing')
parser.add_argument('--seed', default=42, type=int)
parser.add_argument('--resume', default='G:/RT-DETR/detr-main/output/checkpoint.pth', help='resume from checkpoint')
parser.add_argument('--start_epoch', default=0, type=int, metavar='N',
help='start epoch')
parser.add_argument('--eval', default="True")
parser.add_argument('--num_workers', default=2, type=int)
# distributed training parameters
parser.add_argument('--world_size', default=1, type=int,
help='number of distributed processes')
parser.add_argument('--dist_url', default='env://', help='url used to set up distributed training')
return parser
def box_cxcywh_to_xyxy(x):
#将DETR的检测框坐标(x_center,y_cengter,w,h)转化成coco数据集的检测框坐标(x0,y0,x1,y1)
x_c, y_c, w, h = x.unbind(1)
b = [(x_c - 0.5 * w), (y_c - 0.5 * h),
(x_c + 0.5 * w), (y_c + 0.5 * h)]
return torch.stack(b, dim=1)
def rescale_bboxes(out_bbox, size):
#把比例坐标乘以图像的宽和高,变成真实坐标
img_w, img_h = size
b = box_cxcywh_to_xyxy(out_bbox)
b = b * torch.tensor([img_w, img_h, img_w, img_h], dtype=torch.float32)
return b
def filter_boxes(scores, boxes, confidence=0.7, apply_nms=True, iou=0.5):
#筛选出真正的置信度高的框
keep = scores.max(-1).values > confidence
scores, boxes = scores[keep], boxes[keep]
if apply_nms:
top_scores, labels = scores.max(-1)
keep = batched_nms(boxes, top_scores, labels, iou)
scores, boxes = scores[keep], boxes[keep]
return scores, boxes
# COCO classes
# CLASSES = [
# 'N/A', 'person', 'bicycle', 'car', 'motorcycle', 'airplane', 'bus',
# 'train', 'truck', 'boat', 'traffic light', 'fire hydrant', 'N/A',
# 'stop sign', 'parking meter', 'bench', 'bird', 'cat', 'dog', 'horse',
# 'sheep', 'cow', 'elephant', 'bear', 'zebra', 'giraffe', 'N/A', 'backpack',
# 'umbrella', 'N/A', 'N/A', 'handbag', 'tie', 'suitcase', 'frisbee', 'skis',
# 'snowboard', 'sports ball', 'kite', 'baseball bat', 'baseball glove',
# 'skateboard', 'surfboard', 'tennis racket', 'bottle', 'N/A', 'wine glass',
# 'cup', 'fork', 'knife', 'spoon', 'bowl', 'banana', 'apple', 'sandwich',
# 'orange', 'broccoli', 'carrot', 'hot dog', 'pizza', 'donut', 'cake',
# 'chair', 'couch', 'potted plant', 'bed', 'N/A', 'dining table', 'N/A',
# 'N/A', 'toilet', 'N/A', 'tv', 'laptop', 'mouse', 'remote', 'keyboard',
# 'cell phone', 'microwave', 'oven', 'toaster', 'sink', 'refrigerator', 'N/A',
# 'book', 'clock', 'vase', 'scissors', 'teddy bear', 'hair drier',
# 'toothbrush'
# ]
CLASSES = ['N/A','pillar','wheel_chock']
def plot_one_box(x, img, color=None, label=None, line_thickness=1):
#把检测框画到图片上
tl = line_thickness or round(0.002 * (img.shape[0] + img.shape[1]) / 2) + 1 # line/font thickness
color = color or [random.randint(0, 255) for _ in range(3)]
c1, c2 = (int(x[0]), int(x[1])), (int(x[2]), int(x[3]))
cv2.rectangle(img, c1, c2, color, thickness=tl, lineType=cv2.LINE_AA)
if label:
tf = max(tl - 1, 1) # font thickness
t_size = cv2.getTextSize(label, 0, fontScale=tl / 3, thickness=tf)[0]
c2 = c1[0] + t_size[0], c1[1] - t_size[1] - 3
cv2.rectangle(img, c1, c2, color, -1, cv2.LINE_AA) # filled
cv2.putText(img, label, (c1[0], c1[1] - 2), 0, tl / 3, [225, 255, 255], thickness=tf, lineType=cv2.LINE_AA)
def main(args):
print(args)
device = torch.device(args.device)
#------------------------------------导入网络
#下面的criterion是算损失函数要用的,推理用不到,postprocessors是解码用的,这里也没有用,用的是自己的。
model, criterion, postprocessors = build_model(args)
#------------------------------------加载权重
checkpoint = torch.load(args.resume, map_location='cuda')
model.load_state_dict(checkpoint['model'])
#------------------------------------把权重加载到gpu或cpu上
model.to(device)
#------------------------------------打印出网络的参数大小
n_parameters = sum(p.numel() for p in model.parameters() if p.requires_grad)
print("parameters:",n_parameters)
#------------------------------------设置好存储输出结果的文件夹
output_dir = Path(args.output_dir)
#-----------------------------------读取数据集,进行推理
image_Totensor=torchvision.transforms.ToTensor()
image_file_path = os.listdir("G:/RT-DETR/detr-main/inference/test-demo")
image_set = []
for image_item in image_file_path:
print("inference_image:",image_item)
image_path = os.path.join("G:/RT-DETR/detr-main/inference/test-demo",image_item)
image = Image.open(image_path)
image_tensor = image_Totensor(image)
image_tensor = torch.reshape(image_tensor,[-1,image_tensor.shape[0],image_tensor.shape[1],image_tensor.shape[2]])
image_tensor=image_tensor.to(device)
time1 = time.time()
inference_result = model(image_tensor)
time2 = time.time()
print("inference_time:",time2-time1)
probas = inference_result['pred_logits'].softmax(-1)[0, :, :-1].cpu()
bboxes_scaled = rescale_bboxes(inference_result['pred_boxes'][0, ].cpu(),(image_tensor.shape[3],image_tensor.shape[2]))
scores, boxes = filter_boxes(probas,bboxes_scaled)
scores = scores.data.numpy()
boxes = boxes.data.numpy()
for i in range(boxes.shape[0]):
class_id = scores[i].argmax()
label = CLASSES[class_id]
confidence = scores[i].max()
text = f"{label} {confidence:.3f}"
image = np.array(image)
plot_one_box(boxes[i],image,label=text)
# cv2.imshow("images",image)
cv2.waitKey(1)
image=Image.fromarray(np.uint8(image))
image.save(os.path.join(args.output_dir,image_item),format="JPEG")
if __name__ == '__main__':
parser = argparse.ArgumentParser('DETR training and evaluation script', parents=[get_args_parser()])
args = parser.parse_args()
if args.output_dir:
Path(args.output_dir).mkdir(parents=True, exist_ok=True)
main(args)因训练时间短,数据集少,效果如下:

© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...