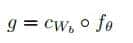29、修改移进 – 归约解析器,使其能够处理诸如 word(d, [all, the]) 这样的终结符列表。
要修改移进 – 归约解析器以处理诸如
word(d, [all, the])
这样的终结符列表,需要对
match_word/2
谓词进行修改,使其能够匹配列表中的任意一个单词。以下是修改后的代码:
% 原有的规则和词汇定义
rule(s, [np, vp]).
word(d, [all, the]).
word(v, [brought]).
rule(np, [d, n]).
word(n, [waiter]).
word(v, [slept]).
rule(vp, [v]).
word(n, [meal]).
rule(vp, [v, np]).
% shift_reduce(+Sentence, ?Category)
shift_reduce(Sentence, Category) :-
shift_reduce(Sentence, [], Category).
% shift_reduce(+Sentence, +Stack, ?Category)
shift_reduce([], Category, Category).
shift_reduce(Sentence, Stack, Category) :-
reduce(Stack, ReducedStack),
write('Reduce: '), write(ReducedStack), nl,
shift_reduce(Sentence, ReducedStack, Category).
shift_reduce(Sentence, Stack, Category) :-
shift(Sentence, Stack, NewSentence, NewStack),
write('Shift: '), write(NewStack), nl,
shift_reduce(NewSentence, NewStack, Category).
% shift(+Sentence, +Stack, -NewSentence, -NewStack)
shift([First | Rest], Stack, Rest, NewStack) :-
append(Stack, [First], NewStack).
% reduce(+Stack, -NewStack)
reduce(Stack, NewStack) :-
match_rule(Stack, NewStack).
reduce(Stack, NewStack) :-
match_word(Stack, NewStack).
% 修改后的 match_word/2 谓词
match_word([Word | Rest], [Category | Rest]) :-
word(Category, Words),
member(Word, Words).
在上述代码中,
match_word/2
谓词被修改为:当栈顶的单词是
word/2
谓词中某个列表的成员时,将该单词替换为对应的类别。这样,解析器就能够处理诸如
word(d, [all, the])
这样的终结符列表了。
30、如何改进使用D规则的尼弗解析器?
可以采用以下几种方法来改进使用 D-rules 的 Nivre’s Parser:
引入词汇化的 D 规则(introduce lexicalized D-rules);
约束解析器生成连通图(constrain the parser to produce connected graphs);
约束图只有一个根节点(constrain the graph to have only one root)。
31、Write facts to represent: Tony is a hedgehog. A hedgehog likes caterpillars. Tony likes caterpillars. All hedgehogs like caterpillars.
prologis_a(tony, hedgehog).
likes(hedgehog, caterpillars).
likes(tony, caterpillars).
forall(is_a(X, hedgehog), likes(X, caterpillars)).
32、编写DCG规则,以获得由一个名词和一个或多个形容词组成的名词短语(如The nice hedgehog、the nice little hedgehog)的语义表示。
以下是一个示例的DCG规则,用于处理由一个名词和一个或多个形容词组成的名词短语并构建其语义表示:
% 处理名词短语
np(Sem) --> det(DetSem), adj_list(AdjSems), noun(NounSem), {
% 合并语义表示
append([DetSem|AdjSems], [NounSem], Sem)
}.
% 处理限定词
det(det(the)) --> [the].
% 处理形容词列表
adj_list([AdjSem|RestSems]) --> adj(AdjSem), adj_list(RestSems).
adj_list([AdjSem]) --> adj(AdjSem).
% 处理单个形容词
adj(adj(nice)) --> [nice].
adj(adj(little)) --> [little].
% 处理名词
noun(noun(hedgehog)) --> [hedgehog].
这个DCG规则的工作原理如下:
np/1
规则是主要的规则,它处理整个名词短语。它首先匹配一个限定词,然后匹配一个或多个形容词,最后匹配一个名词。在匹配完成后,它将限定词、形容词和名词的语义表示合并到一个列表中。
det/1
规则处理限定词,这里只处理了
the
。
adj_list/1
规则处理形容词列表,它可以递归地匹配多个形容词。
adj/1
规则处理单个形容词,这里处理了
nice
和
little
。
noun/1
规则处理名词,这里处理了
hedgehog
。
你可以使用以下查询来测试这个规则:
?- np(Sem) --> [the, nice, little, hedgehog], [].
这个查询将尝试解析
the nice little hedgehog
这个名词短语,并返回其语义表示
Sem
。
33、编写规则,接受带有嵌入式关系从句的句子,例如 “The waiter that ran brought a meal”,并从中生成逻辑形式:the(X, (waiter(X), ran(X)), a(Y, meal(Y), brought(X, Y)))
以下是使用Prolog编写的规则,用于处理带有嵌入式关系从句的句子并生成相应的逻辑形式。以下代码假设我们已经定义了一些基本的词汇和语法规则,例如 `waiter`、`ran`、`meal` 和 `brought` 等谓词。
```prolog
% 定义基本的词汇和语法规则
lex(waiter, waiter).
lex(ran, ran).
lex(meal, meal).
lex(brought, brought).
lex(the, the).
lex(a, a).
lex(that, that).
% 解析带有嵌入式关系从句的句子
sentence(Sem) --> det(Det), noun(N), rel_clause(Rel), verb(V), det(Det2), noun(N2), { build_logical_form(Det, N, Rel, V, Det2, N2, Sem)}.
det(Det) --> [Word], {lex(Word, Det)}.
noun(N) --> [Word], {lex(Word, N)}.
verb(V) --> [Word], {lex(Word, V)}.
% 解析关系从句
rel_clause(Rel) --> [that], verb(Rel).
% 构建逻辑形式
build_logical_form(Det, N, Rel, V, Det2, N2, Sem) :-
Det = the,
Det2 = a,
Sem =.. [Det, X, (..([N, X], [Rel, X])), ..([Det2, Y, N2, Y], [V, X, Y])].
代码解释:
词汇和语法规则
:
lex
谓词用于定义基本的词汇和它们的语义表示。
句子解析规则
:
sentence(Sem)
规则用于解析带有嵌入式关系从句的句子。它首先解析限定词、名词、关系从句、动词、另一个限定词和名词,然后调用
build_logical_form
谓词来构建逻辑形式。
关系从句解析规则
:
rel_clause(Rel)
规则用于解析关系从句,它期望一个
that
单词,然后是一个动词。
逻辑形式构建规则
:
build_logical_form
谓词根据输入的限定词、名词、关系从句、动词等信息构建逻辑形式。在这个例子中,我们假设限定词是
the
和
a
,并构建相应的逻辑形式。
示例查询:
最后,我们可以使用
phrase
谓词来测试这个规则,输入句子 “the waiter that ran brought a meal”,并得到相应的逻辑形式。
?- sentence(Sem), phrase(sentence(Sem), [the, waiter, that, ran, brought, a, meal]).
##34、编写规则来解析以关系代词“who”和“what”开头的疑问句,例如“Who brought the meal?”和“What did the waiter bring?”,并从中构建逻辑形式。
以下是一个可能的解决方案,我们使用 Prolog 语言来编写规则。首先,我们需要定义一些基本的语法规则,然后构建能够解析以 “who” 和 “what” 开头的疑问句并生成逻辑形式的规则。以下是示例代码:
```prolog
% 基本的词汇规则
word(det, the).
word(noun, waiter).
word(noun, meal).
word(verb, brought).
% 名词短语规则
np(In, Out) --> ngroup(In, Out1), relative(Out1, Out).
ngroup(In, Out) --> [Det], {word(det, Det)}, [Noun], {word(noun, Noun)}, {Out = In}.
relative(In, Out) --> [that], s([that | In], Out).
relative(In, Out) --> [who], s([who | In], Out).
% 句子规则
s(In, Out) --> np(In, Out1), vp(Out1, Out).
vp(In, Out) --> [Verb], {word(verb, Verb)}, np(In, Out).
% 解析以 who 开头的问题
question_who(LogicalForm) --> [who], s([who], []), {build_who_logical_form(LogicalForm)}.
% 构建以 who 开头问题的逻辑形式
build_who_logical_form(LogicalForm) :-
% 这里需要根据具体的语义和解析结果构建逻辑形式
% 简单示例,假设我们只是记录谁做了某事
LogicalForm = who_did_something.
% 解析以 what 开头的问题
question_what(LogicalForm) --> [what], s([what], []), {build_what_logical_form(LogicalForm)}.
% 构建以 what 开头问题的逻辑形式
build_what_logical_form(LogicalForm) :-
% 这里需要根据具体的语义和解析结果构建逻辑形式
% 简单示例,假设我们只是记录做了什么事
LogicalForm = what_was_done.
上述代码中,我们首先定义了基本的词汇规则,然后定义了名词短语和句子的规则。接着,我们定义了
question_who
和
question_what
规则来解析以 “who” 和 “what” 开头的问题,并通过
build_who_logical_form
和
build_what_logical_form
来构建逻辑形式。这里的逻辑形式构建只是简单示例,实际应用中需要根据具体的语义和解析结果进行更复杂的构建。
35、编写一个小型对话系统,该系统能够接受断言和问题并进行回答。以下是一个会话记录示例:用户输入“the patron ordered the meal”,系统回复“OK”;用户输入“who brought the meal”,系统回复“I don’t know”;用户输入“who ordered the meal”,系统回复“the patron”;用户输入“the waiter brought the meal”,系统回复“OK”;用户输入“who brought the meal”,系统回复“the waiter”。
以下是一个使用 Python 实现的简单对话系统示例代码:
# 存储已知信息的字典
knowledge = {}
# 处理用户输入的函数
36、像“所有顾客都点了一顿饭”这样的句子可能有多种理解。请列举该句子的两种可能解释并详细说明。
以下是“所有顾客都点了一顿饭”这句话的两种可能解释:
集体理解
:所有顾客作为一个整体,共同点了一顿饭。
这意味着顾客们可能是一起用餐,并且只点了一份餐食供大家分享。
例如,一群朋友去餐厅聚餐,他们决定一起点一份大餐大家一起吃。
个体理解
:每一位顾客都各自点了一顿饭。
也就是说,餐厅里的每一个顾客都单独进行了点餐的动作,每个人都有自己的一份餐食。
例如,餐厅里的顾客们各自根据自己的口味和需求点了一份餐。
37、根据WordNet,‘bring’蕴含‘come’,‘come up’表示朝着某物、某人移动或靠近某物、某人。将这种蕴含关系归类为共扩展性、真包含性、反向预设或因果关系。
由于
bring
意味着带着某物来到某个地方,必然包含了
come
(移动到某个地方)这个动作,所以
bring
的动作包含了
come
的动作,这种蕴含关系属于真包含性(proper inclusion)。
38、编写一个语法来识别英语、法语或德语中的名称(专有名词)。你要考虑名称由一个头衔后面跟着一个首字母大写的姓氏组成。
以下是一个使用Prolog编写的简单示例,用于识别符合要求的名称(由头衔后面跟着首字母大写的姓氏组成)。这里以英语为例,对于法语和德语,只需根据相应语言的头衔进行扩展即可。
% 定义常见的英文头衔
title('Mr.').
title('Mrs.').
title('Ms.').
title('Dr.').
title('Sir').
% 检查字符串是否首字母大写
is_capitalized([H|_]) :- char_type(H, upper).
% 识别名称的规则
name([Title, Surname]) :- title(Title), atom_chars(Surname, Chars), is_capitalized(Chars).
你可以使用以下方式测试这个程序:
?- name([Title, Surname]).
它会输出所有符合规则的头衔和姓氏组合。如果要具体检查某个名称是否符合规则,可以这样使用:
?- name(['Mr.', 'Smith']).
如果名称符合规则,会返回
true
,否则返回
false
。
对于法语和德语,你可以添加相应语言的头衔谓词,例如:
% 法语头衔
french_title('M.').
french_title('Mme.').
french_title('Mlle.').
% 德语头衔
german_title('Herr').
german_title('Frau').
% 扩展识别名称的规则以支持法语和德语
french_name([Title, Surname]) :- french_title(Title), atom_chars(Surname, Chars), is_capitalized(Chars).
german_name([Title, Surname]) :- german_title(Title), atom_chars(Surname, Chars), is_capitalized(Chars).
这样就可以分别识别法语和德语的名称了。
39、使用Prolog子句(不使用DCG规则)编写一个对话程序,提出几个问题并仅接受“是”或“否”的回答。收集所有回答并在会话结束时将它们打印出来。
# 对话程序的 Prolog 实现
以下是一个使用 Prolog 子句实现的对话程序,它会提出几个问题,仅接受“是”或“否”的回答,收集所有回答并在会话结束时将它们打印出来:
```prolog
% 定义问题列表
questions([
'你喜欢阅读吗?',
'你喜欢运动吗?',
'你喜欢音乐吗?'
]).
% 主程序,开始对话
start_dialogue :-
questions(Qs),
ask_questions(Qs, []).
% 递归询问问题并收集回答
ask_questions([], Answers) :-
% 当问题列表为空时,打印所有回答
write('所有回答如下:'), nl,
print_answers(Answers).
ask_questions([Q|Qs], Answers) :-
% 询问当前问题
write(Q), nl,
read(Answer),
% 验证回答是否为“是”或“否”
validate_answer(Answer, ValidAnswer),
% 递归询问下一个问题并更新回答列表
ask_questions(Qs, [ValidAnswer|Answers]).
% 验证回答是否为“是”或“否”,如果不是则提示重新输入
validate_answer(Answer, ValidAnswer) :-
(Answer = 是 ; Answer = 否), !,
ValidAnswer = Answer.
validate_answer(_, ValidAnswer) :-
write('请输入“是”或“否”。'), nl,
read(NewAnswer),
validate_answer(NewAnswer, ValidAnswer).
% 打印所有回答
print_answers([]).
print_answers([A|As]) :-
write(A), nl,
print_answers(As).
代码说明
questions/1
:定义了一个问题列表,包含了要询问的问题。
start_dialogue/0
:主程序,调用
ask_questions/2
开始对话。
ask_questions/2
:递归地询问问题并收集回答。当问题列表为空时,调用
print_answers/1
打印所有回答。
validate_answer/2
:验证用户的回答是否为“是”或“否”,如果不是则提示用户重新输入。
print_answers/1
:递归地打印所有回答。
使用方法
将上述代码保存为一个
.pl
文件,例如
dialogue.pl
,然后在 Prolog 解释器中加载该文件并调用
start_dialogue.
即可开始对话。例如:
?- [dialogue].
% dialogue compiled 0.00 sec, 1,120 bytes
true.
?- start_dialogue.
你喜欢阅读吗?
是
你喜欢运动吗?
否
你喜欢音乐吗?
是
所有回答如下:
是
否
是
true.
##40、DCG对话规则并不健壮。将其与句子解析进行类比,给出它们可能失败的例子并说明原因。
### 与句子解析的类比
句子解析旨在将输入的句子按照语法规则分解成不同的成分,以理解句子的结构和语义。而DCG对话规则则是根据输入的话语模式生成相应的回复,类似于根据特定规则对输入进行转换和处理。在这两种情况下,规则的健壮性都至关重要,因为它们都需要处理各种可能的输入。
### 可能失败的例子及原因
#### 例子1:输入超出规则覆盖范围
- **输入**:`I love playing football.`
- **失败原因**:现有的DCG对话规则中,没有针对 `I love` 这种输入模式的规则。在句子解析中,如果输入的句子不符合任何预定义的语法规则,解析就会失败;同样,在DCG对话规则中,当输入的话语模式不在规则的覆盖范围内时,就无法生成相应的回复。
#### 例子2:输入包含复杂或不规则的表达
- **输入**:`I'm not really into it, but sometimes I do like it a little bit.`
- **失败原因**:该输入虽然包含了 `I'm not` 和 `I like` 等可能匹配规则的片段,但整体表达较为复杂和不规则。DCG对话规则通常是基于简单的模式匹配,难以处理这种复杂的输入。就像句子解析中,如果句子存在复杂的嵌套结构、不规则的词序或省略等情况,可能会导致解析失败。在这个例子中,规则无法准确识别出可以匹配的模式,从而无法生成合适的回复。
#### 例子3:输入的关键词位置不符合规则
- **输入**:`Playing football, I like it.`
- **失败原因**:规则中 `I like` 是连续出现的,而在这个输入中,`I like` 被其他词语分隔开了。DCG对话规则是按照固定的顺序和模式进行匹配的,当关键词的位置不符合规则时,就无法匹配成功。这类似于句子解析中,如果词语的顺序不符合语法规则,解析就会失败。
##41、修改一个EVAR自动机,并使用SUNDIAL言语行为,让系统运行起来以实现或多或少逼真的对话。
要完成该任务,可按以下步骤进行:
1. 回顾用于模拟EVAR接受合法言语行为序列(如 `[S_GREETING, U_REQ_INFO, ...]` )的主要阶段的Prolog自动机。
2. 对该自动机进行交互性修改,即设计系统的问题和消息以及用户可能的回答,并替换用户和系统的轮次。
3. 引入SUNDIAL言语行为,将其中的言语行为类型融入到自动机中。
4. 调整自动机的状态转换逻辑,使其能根据SUNDIAL言语行为实现更逼真的对话流程。例如,当系统检测到用户表达预订需求(如 `'Je veux une réservation de Londres à Paris'` )时,自动机应进入询问日期的状态,并输出相应的问题(如 `'Londres Paris à quelle date voulez-vous voyager?'` )。
5. 确保自动机能够处理用户的各种回答,并根据回答合理地推进对话。例如,当用户回答日期后,自动机应接着询问时间。
以下是一个简单的Prolog代码示例,展示如何开始修改自动机以纳入SUNDIAL言语行为:
```prolog
% 定义SUNDIAL言语行为及对应的状态转换
% 初始状态,系统问候
state(S1, [S_GREETING], S2) :- write('Bonjour puis-je vous aider?'), nl.
% 状态S2,用户提出预订需求,系统询问日期
state(S2, [U_REQ_INFO], S3) :- write('Londres Paris à quelle date voulez-vous voyager?'), nl.
% 状态S3,用户回答日期,系统询问时间
state(S3, [U_DATE_INFO], S4) :- write('Le 20 juin à quelle heure?'), nl.
% 其他状态转换规则可按此模式继续添加
% 模拟对话流程
simulate_dialogue(State, [Act|Acts]) :- state(State, Act, NextState), simulate_dialogue(NextState, Acts).
simulate_dialogue(_, []).
% 启动对话
start_dialogue :- simulate_dialogue(S1, [S_GREETING, U_REQ_INFO, U_DATE_INFO]).
这个示例只是一个基础框架,实际应用中需要根据具体需求进一步完善状态转换规则和处理更多的言语行为情况。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...