今天带来一个非常有意思的blog,作者是Utkarsh Kanwat。他在在开发、运维和数据运营领域构建了超过12个AI agent系统,是有一定代表性的开发者。文章说的也很真实,直指自主agent存在的问题,以及在实际生产中真正有效的是什么。 也是关于AI Agent,最深刻、最现实的讨论。 满世界都在说,202错误率的叠加这个逻辑就是扯蛋 agent 不是一股脑的往下执行,它完全能够 re-plan 和调整执行方案











 今天带来一个非常有意思的blog,作者是Utkarsh Kanwat。他在在开发、运维和数据运营领域构建了超过12个AI agent系统,是有一定代表性的开发者。文章说的也很真实,直指自主agent存在的问题,以及在实际生产中真正有效的是什么。
今天带来一个非常有意思的blog,作者是Utkarsh Kanwat。他在在开发、运维和数据运营领域构建了超过12个AI agent系统,是有一定代表性的开发者。文章说的也很真实,直指自主agent存在的问题,以及在实际生产中真正有效的是什么。








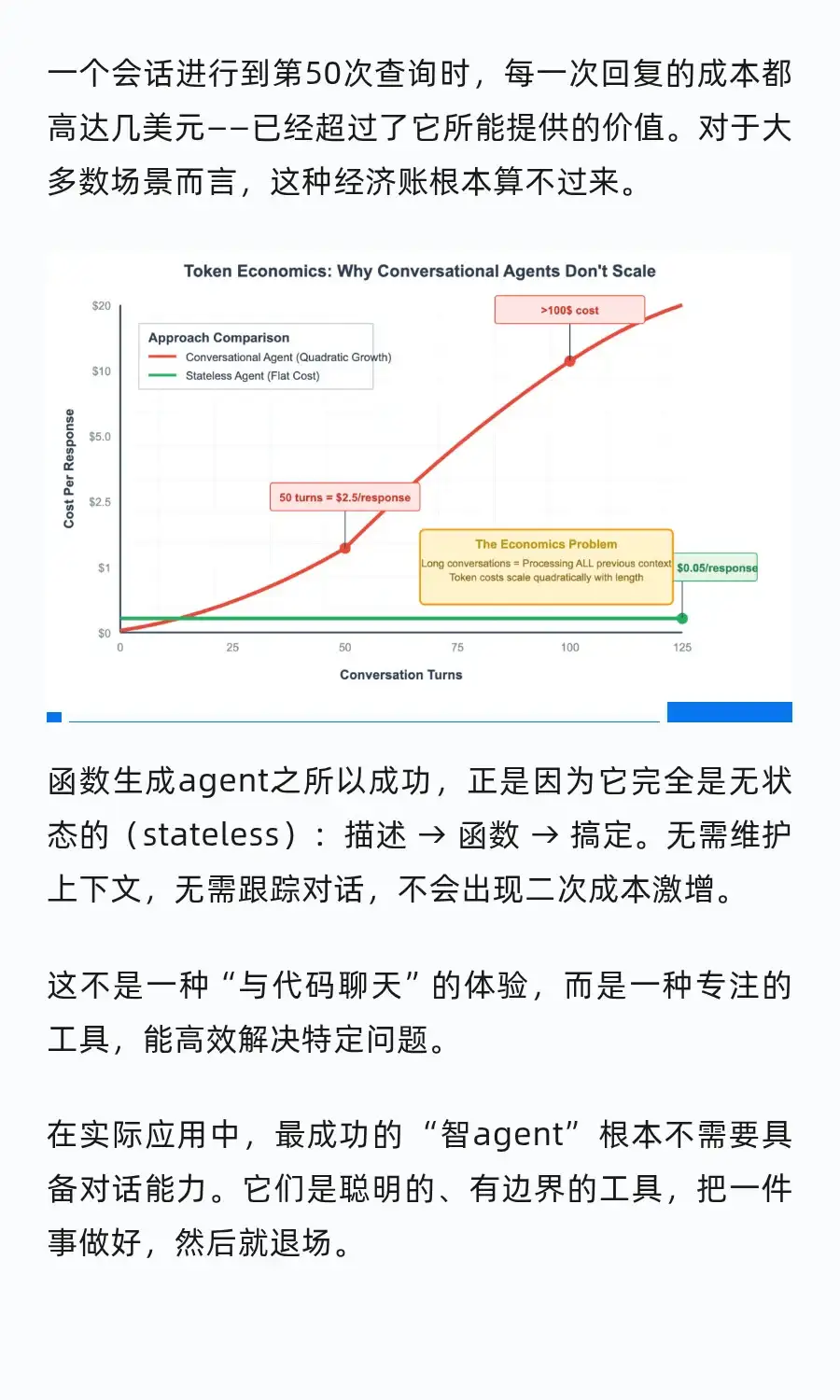
但是能够完成5个步骤对许多企业来说已经可以提供价值了吧 许多限制是模型能力和记忆还不够好,只能靠prompt来硬补 所以才有了最近大火的context prompting, model capabilities 跟上了 就不是问题了
[g=xiaoyanger] 企业场景,智能体里ai甚至占不到10%,全是工具开发的工作量
(๑˃̵ᴗ˂̵)👍
👍
继续错误结果的replan也是错误的,所以这个理论没问题,只不过有些步骤下可以识别并修改原本的错误,可不可靠就是不可靠,环节越多越不可靠。就像一个实习生可以解决50%的问题,2个实习生可以解决60%的问题,但你想着增加实习生来解决所有问题,结果将会由于人数变多,出现更大的问题,导致还不如一两个实习生效果更好。ai需要知道什么是对的,什么是错的,而不是什么可能是正确的
嗯嗯,更长远的眼光,同意的!
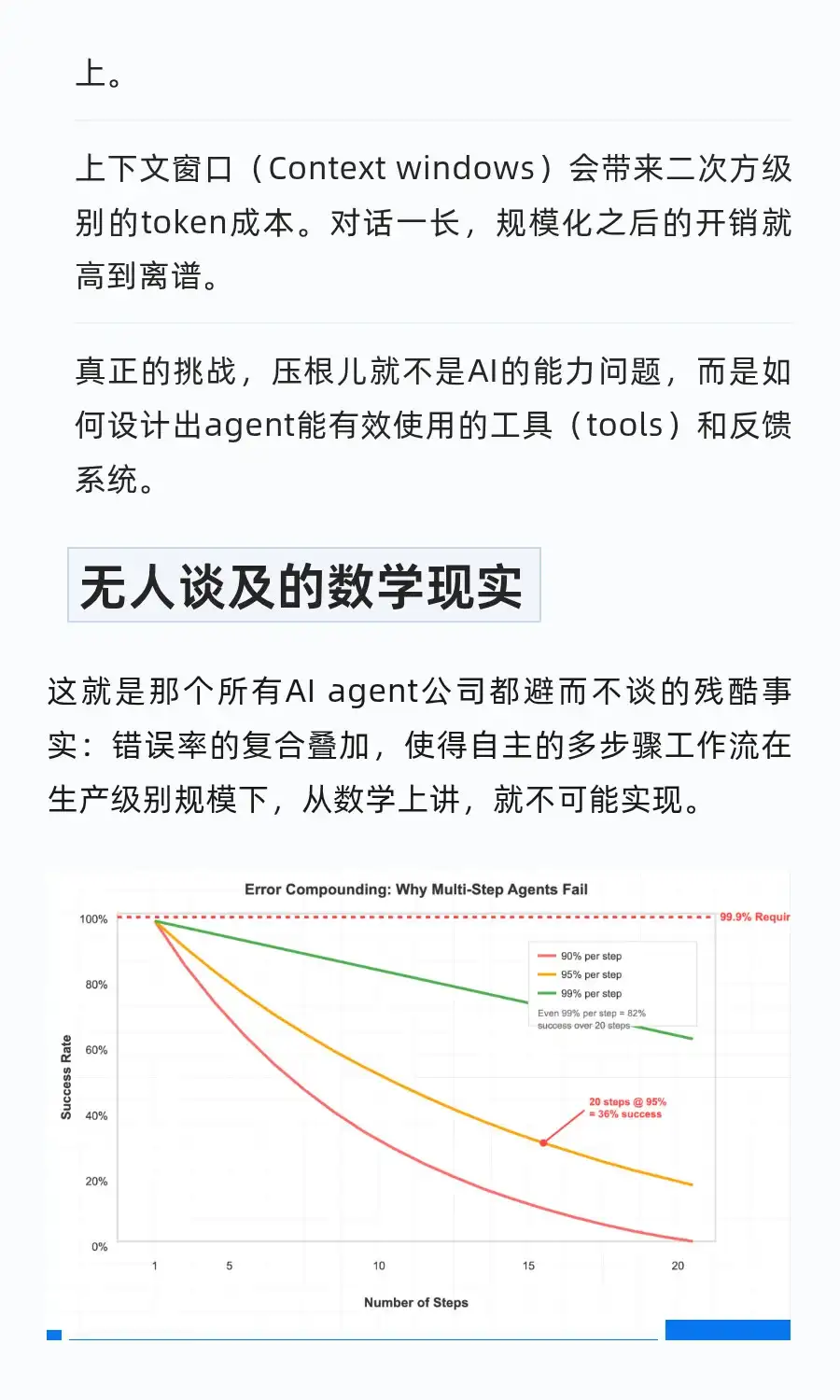
这篇的质量不太行啊 这三个实际里边第一个说多步骤工作流,它的错误率会有一个叠加,线性串联的工作流是有一个误差传播的问题,但是工作流不是agent。第二个,在不思考前缀缓存和线性注意力/稀疏注意力的情况下成立,但在做长上下文的时候至少会用到1个feature。第3个tools和反馈系统是挑战,但模型的能力也是挑战,同样是react多轮工具调用,claude能轻松跑几十轮,许多模型跑不到10轮
一些良性的讨论
的确 ,claude和其他人在真正执行任务时候差的不是一点半点。不过你说的线性注意力,是在模型训练时候就已经思考进去了,不影响使用时候用长文的成本。不过linear attention目前效果还不太好
你在美国连原文都找不到,也是挺可悲的
简单的道理往往不被热烈的人类接受
agent革命终将到来。只是它看起来,和2025年大家所鼓吹的样子,不会有任何关系。而恰恰由于如此,它才会最终成功。
是的
[g=xiaoku] 不客气地说 这篇文章看着就像AI写的lol
后面几点问题都是短期的,将来token价格唯一挂钩的是能源,肯定会压下去。系统也很正常,移动互联网刚开始也和pc协同的不好,毕竟是一整个新的生态,基建肯定要重新做,这个长期能解决。
[g=jingxi] 感谢补充👍
先谢谢博主的推荐,自己对这个方向的问题超级感兴趣。再抛一点自己的理解,用户要的不是agent,而是问题被解决。agent是做工具的人,关注的技术解决方案,这套方案在当下,并不能解决许多实际问题。数字世界和物理世界有巨大鸿沟,导致llm在两者之间来回跳,不能闭环解决。智能家居,可以被视为某种早期agent,可惜它并没有那么大规模被普及,只由于收益没那么大(或尝试成本太高)
看衰2025年的Agent是对的,但是目前所有的Agent都是瞄准后来,看一下模型的进化速度,所以这样的悲观并没有意义