大型语言模型(LLM)在文本生成方面展现出惊人的能力,但如何确保其输出安全、不产生有害内容,一直是研究的重点。近期一项发表在ICLR 2025的论文《Aligned Large Language Models : The Key to LLM Security》为我们揭示了LLM安全性的关键所在,并提出了一种创新的防御今年安全层这个概念还挺火 看到两篇了
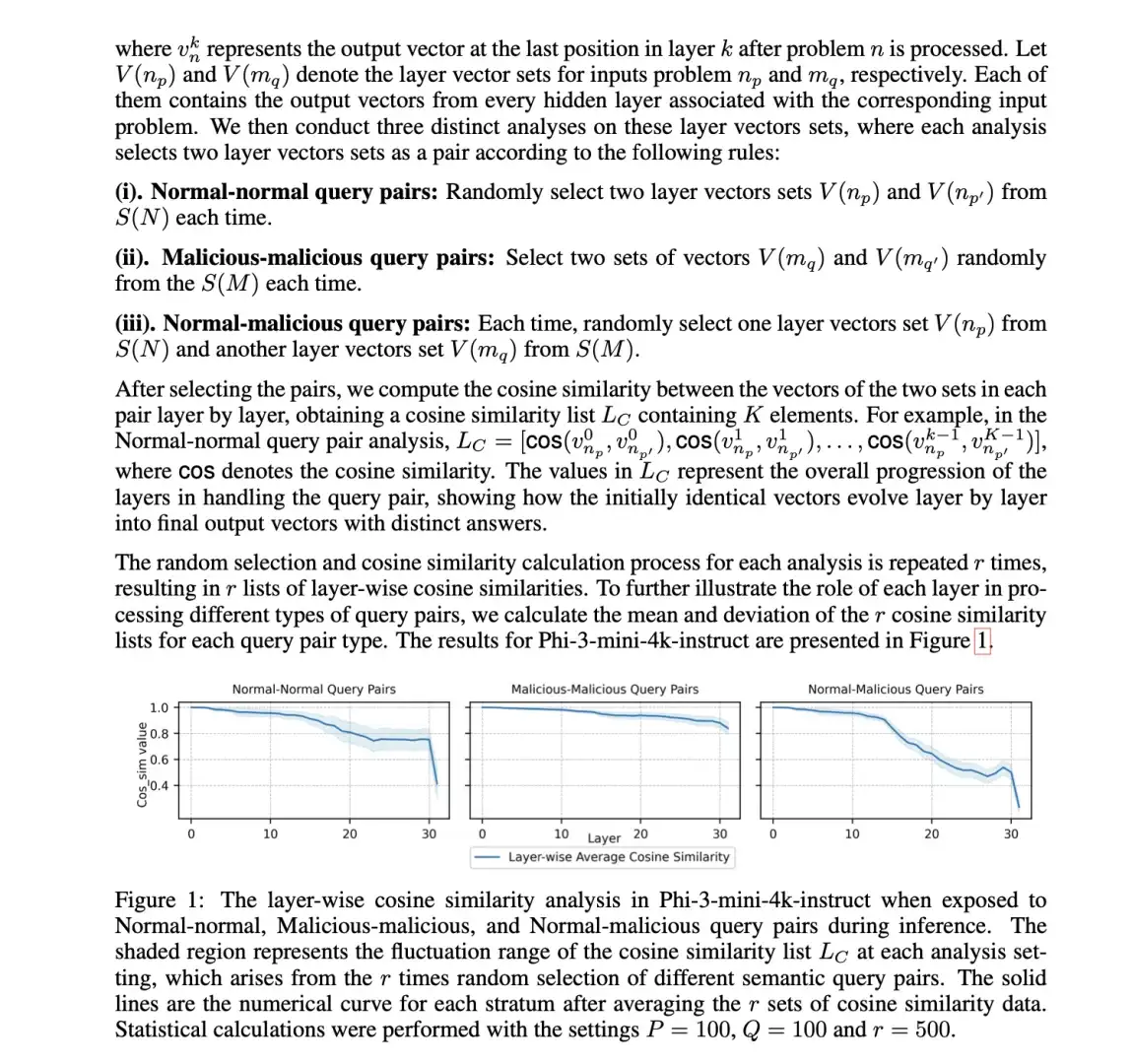


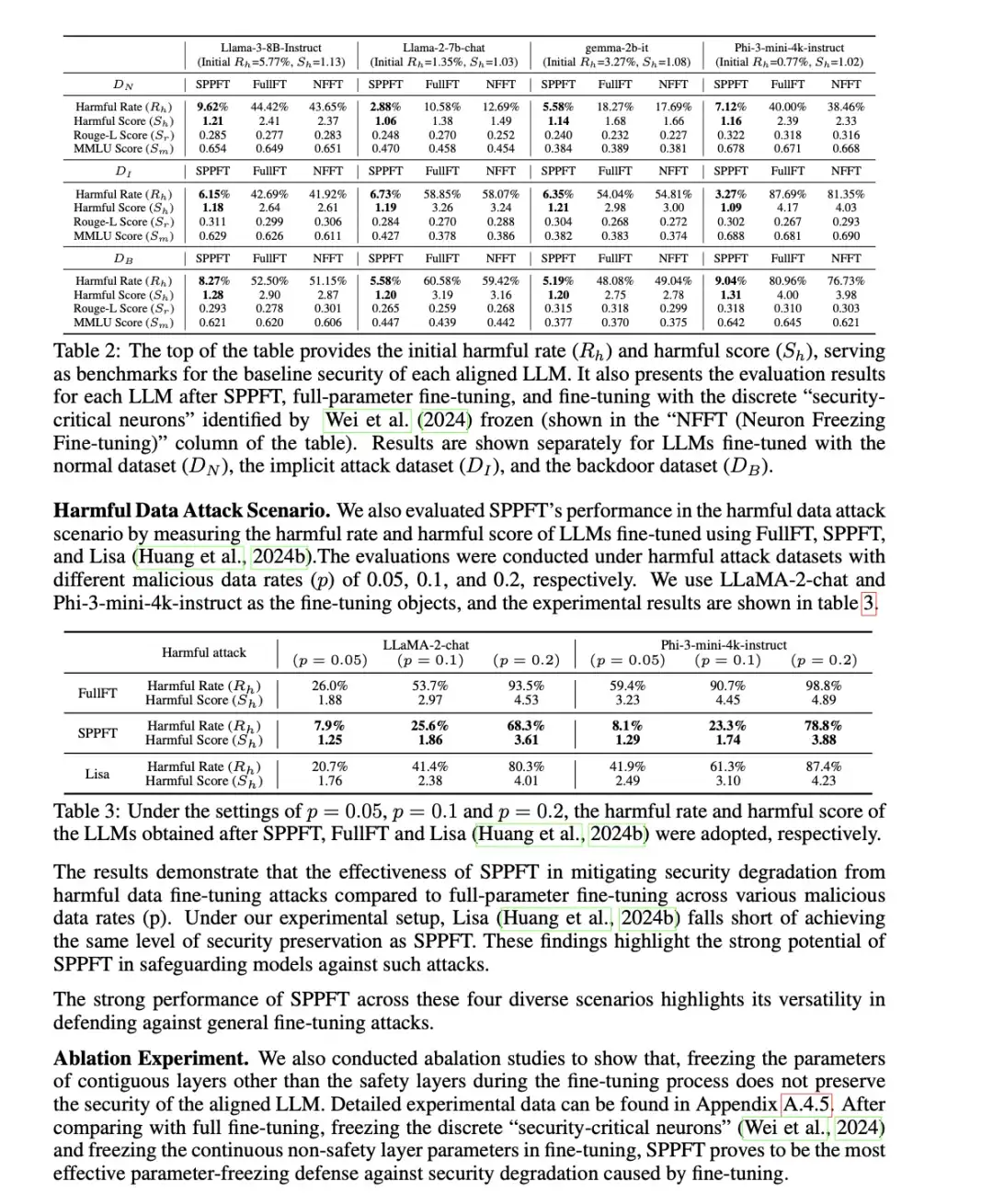
 大型语言模型(LLM)在文本生成方面展现出惊人的能力,但如何确保其输出安全、不产生有害内容,一直是研究的重点。近期一项发表在ICLR 2025的论文《Aligned Large Language Models : The Key to LLM Security》为我们揭示了LLM安全性的关键所在,并提出了一种创新的防御
大型语言模型(LLM)在文本生成方面展现出惊人的能力,但如何确保其输出安全、不产生有害内容,一直是研究的重点。近期一项发表在ICLR 2025的论文《Aligned Large Language Models : The Key to LLM Security》为我们揭示了LLM安全性的关键所在,并提出了一种创新的防御










这篇去年就看到了,没想到目前中了iclr
请问另一篇有链接吗