




 之前写了一篇文章:《深入浅出KV-Cache》。
之前写了一篇文章:《深入浅出KV-Cache》。在大语言模型(LLM)的实际应用里,KV-Cache早就成了推理优化的标配。大家都知道它靠”缓存Key和Value”加速自回归生成,走的是”用空间换时间”的路子。但真想把它吃透,还得琢磨透这几个问题:
性能瓶颈的根儿在哪?KV-Cache到底把计算复杂度从哪个量级压
👍期待后续更多文章!
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章
没有相关内容!
之前写了一篇文章:《深入浅出KV-Cache》。性能瓶颈的根儿在哪?KV-Cache到底把计算复杂度从哪个量级压
👍期待后续更多文章!









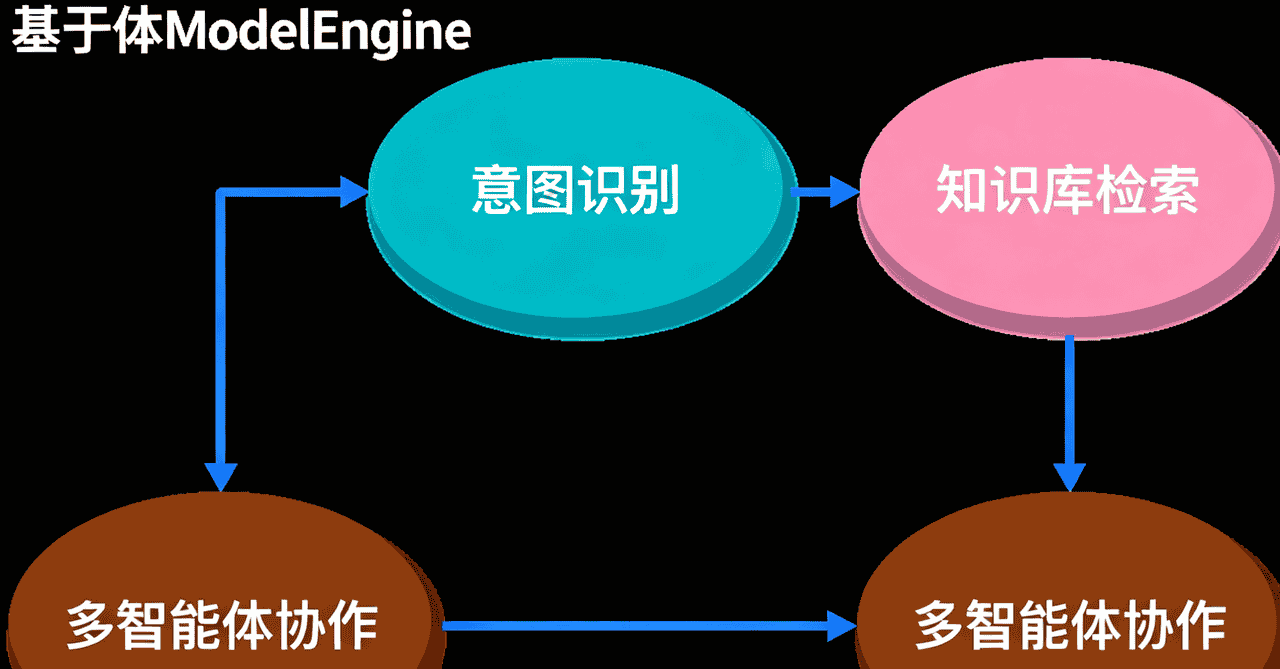
提议再深入些 列如如何筛选不重大的kvcshce