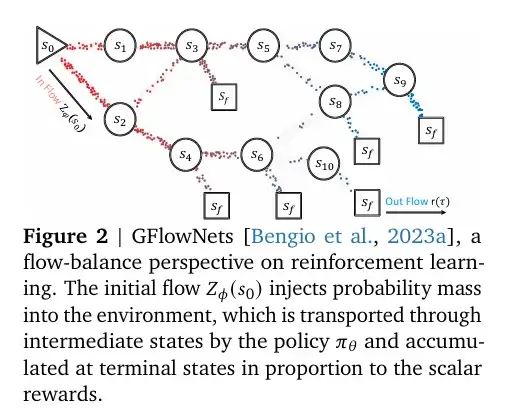
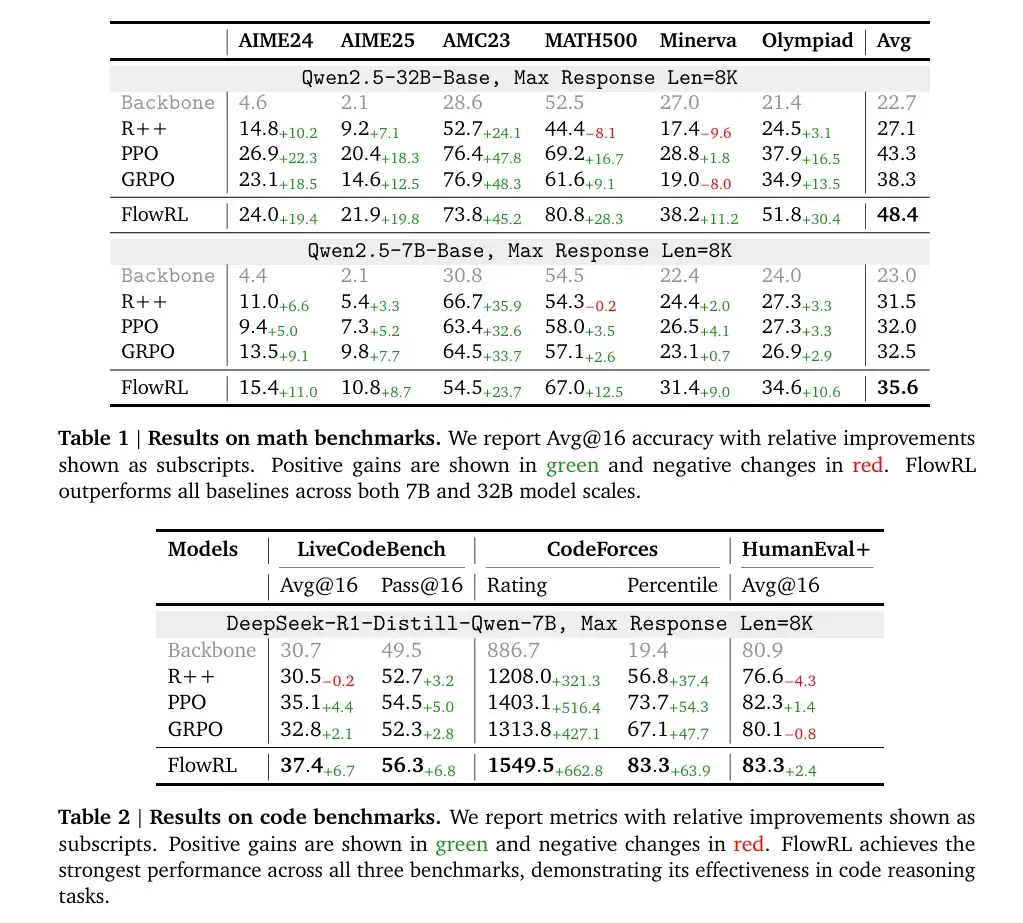
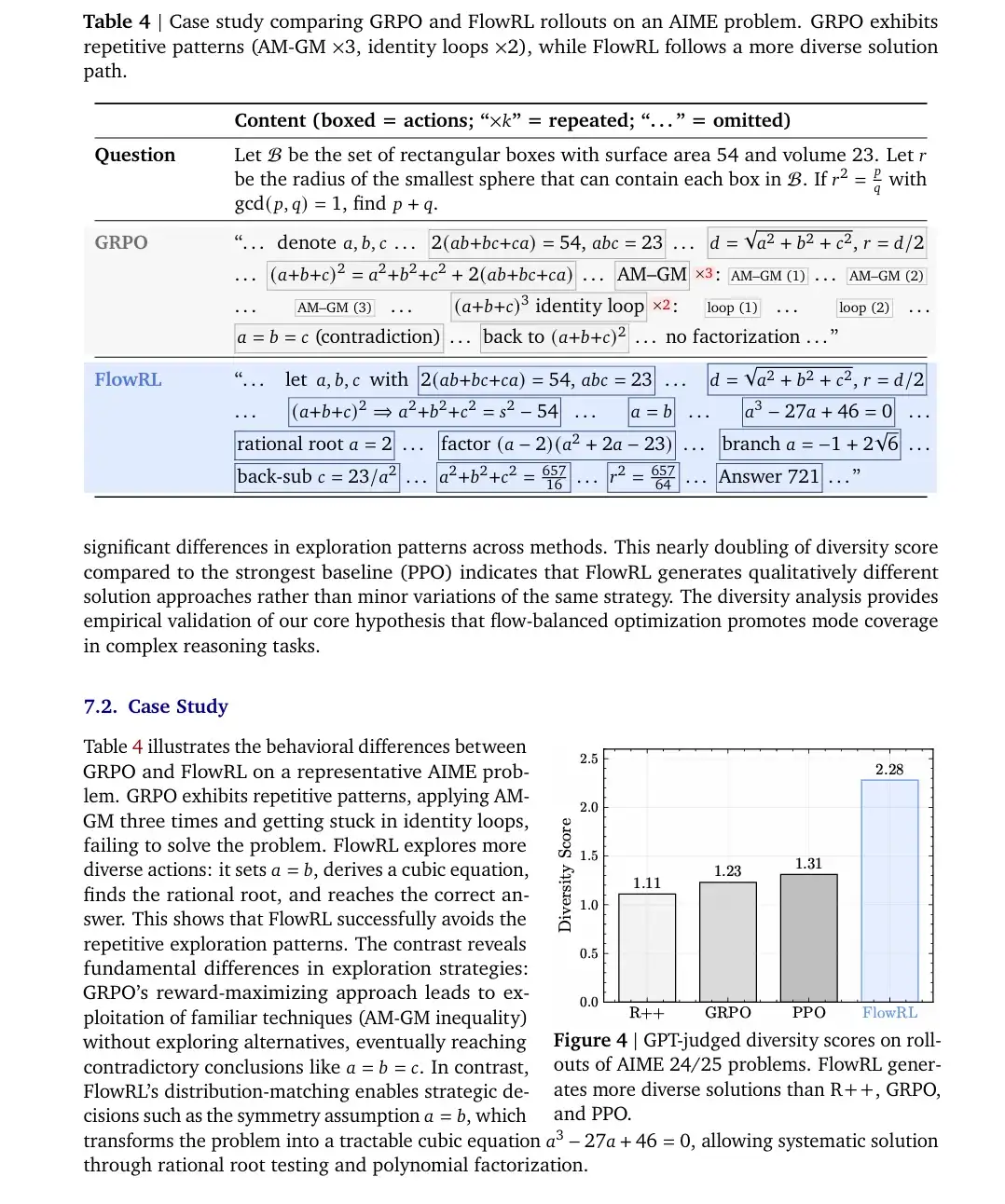


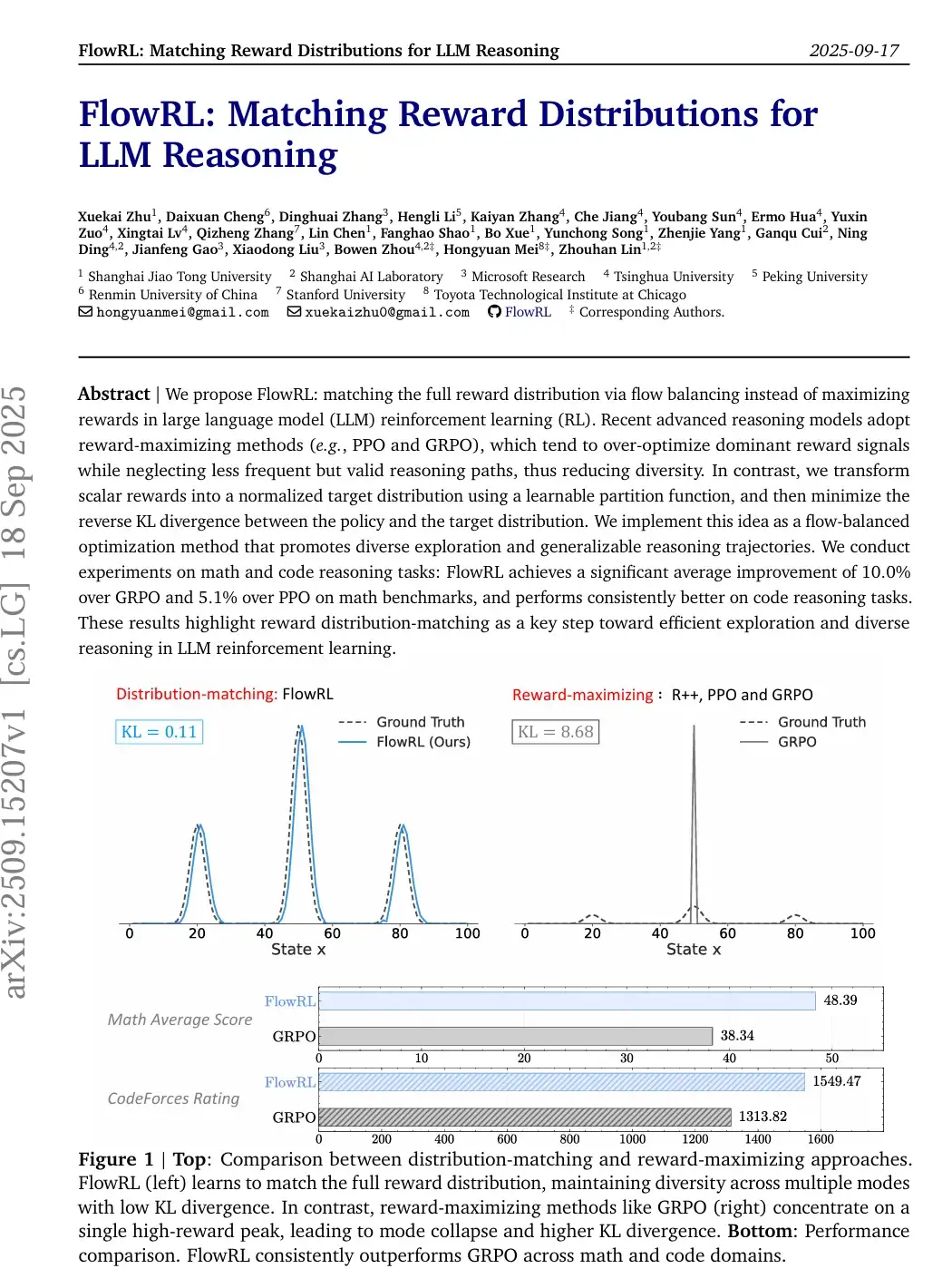
 FlowRL是一种RL方法,旨在解决传统的奖励最大化方法带来的多样性丧失问题。它通过将奖励转化为标准化的目标分布,并最小化策略和目标分布之间的逆KL散度,来促进多样化的推理路径。
FlowRL是一种RL方法,旨在解决传统的奖励最大化方法带来的多样性丧失问题。它通过将奖励转化为标准化的目标分布,并最小化策略和目标分布之间的逆KL散度,来促进多样化的推理路径。核心创新:
奖励分布匹配: FlowRL的关键技术创新之一是将标量奖励转换为标准化的目标分布。通过引入一个可学习的分区函数,它能够根据奖励信
这篇文章很有意思
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章
没有相关内容!

暂无评论...
FlowRL是一种RL方法,旨在解决传统的奖励最大化方法带来的多样性丧失问题。它通过将奖励转化为标准化的目标分布,并最小化策略和目标分布之间的逆KL散度,来促进多样化的推理路径。这篇文章很有意思