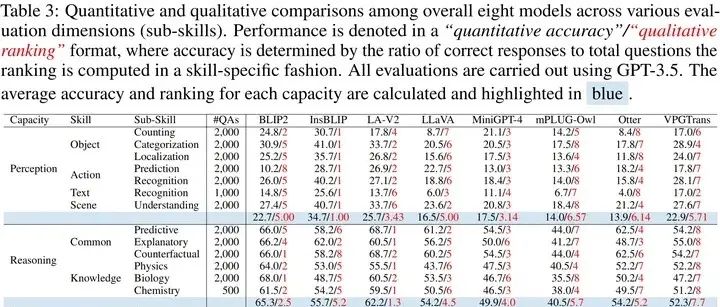
。随着大型语言模型(Large Language model,LLMs)的发展,视觉语言模型(Vision-Language model, VLMs)已经达到了一个新的复杂程度,在执行复杂的认知和推理任务方面表现出了显著的能力。不过,现有的评估基准主要依赖于严格的、手工制作的数据集来衡量特定任务的性能,在评估这些日益拟人化的模型与人类智能的匹配方面面临重大限制。在这项工作中,我们通过Auto-Bench解决了这些限制,它深入探索了作为熟练校准器的LLMs,并通过自动数据管理和评估测量了VLMs与人类智能和价值之间的一致性。具体来说,对于数据管理,Auto-Bench利用LLMs(例如,gps -4)通过在可视化符号表明(例如,标题、对象位置、实例关系等)上的提示自动生成大量的问答推理三元组。由于LLMs中嵌入了广泛的世界知识,这些数据与人类的意图超级吻合。通过这个管道,总共有28.5K人验证和3504k未过滤的问题-答案-推理三联体被策划,涵盖4种主要能力和16种子能力。随后,我们聘请了像GPT-3.5这样的LLMs来担任评委,实施定量和定性的自动化评估,以促进对VLMs的全面评估。我们的验证结果显示,LLMs在评估数据管理和模型评估两方面都很精通,平均一致性达到85%。我们设想Auto-Bench是一个灵活的、可伸缩的、全面的基准,用于评估不断发展的复杂的VLMs。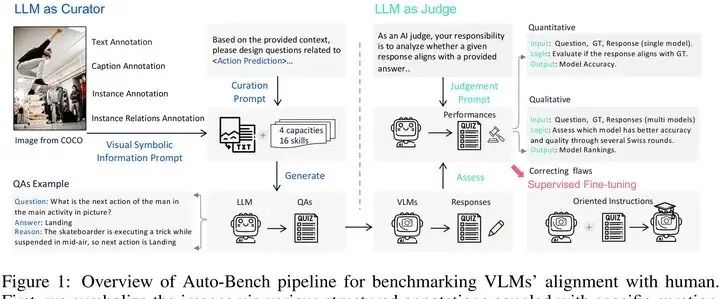



© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...