
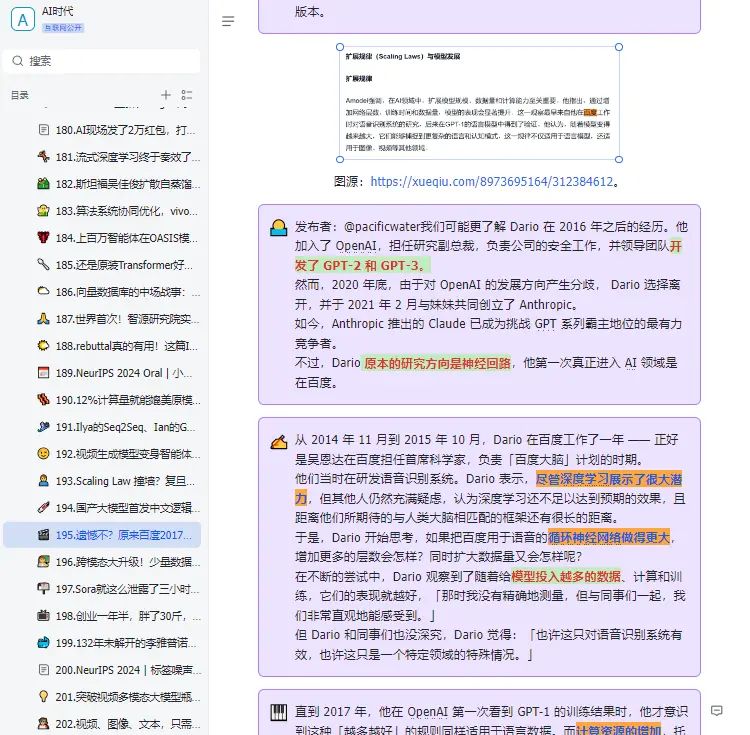
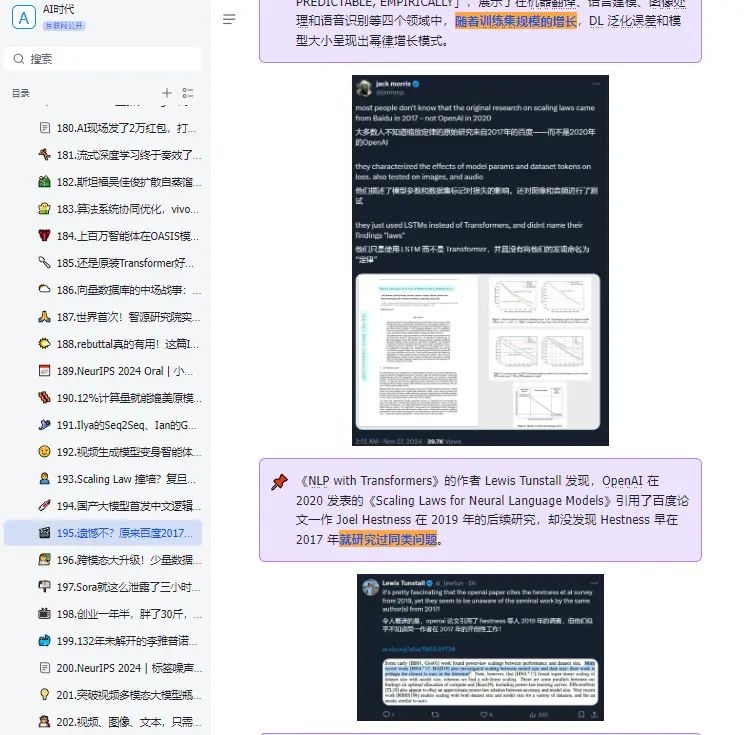
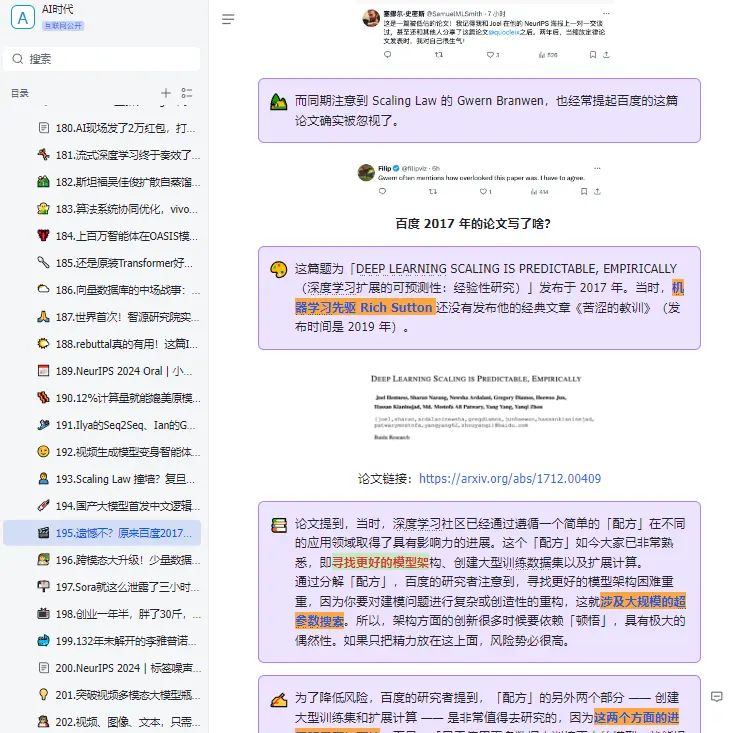
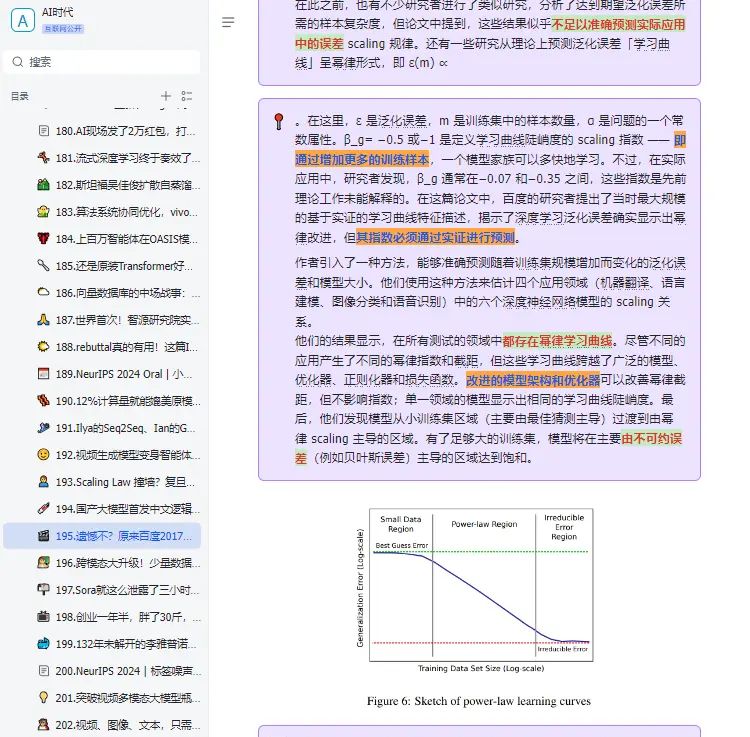
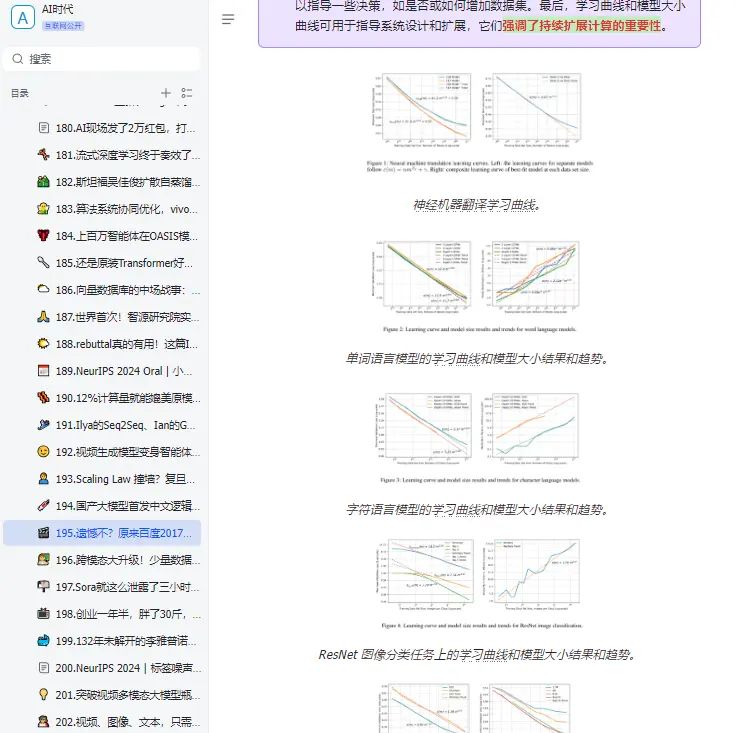
原来早在 2017 年,百度就进行过 Scaling Law 的相关研究,并且通过实证研究验证了深度学习模型的泛化误差和模型大小随着训练集规模的增长而呈现出可预测的幂律 scaling 关系。只是,他们当时用的是 LSTM,而非 Transformer,也没有将相关发现命名为「Scaling Law」。在追求 AGI 的道路上,Scaling Law 是绕不开的一环。如果 Scaling Law 撞到了天花板,扩大模型规模,增加算力不能大幅提升模型的能力,那么就需要探索新的架构创新、算法优化或跨领域的技术突破。作为一个学术概念,Scaling Law 为人所熟知,一般归功于 OpenAI 在 2020 年发的这篇论文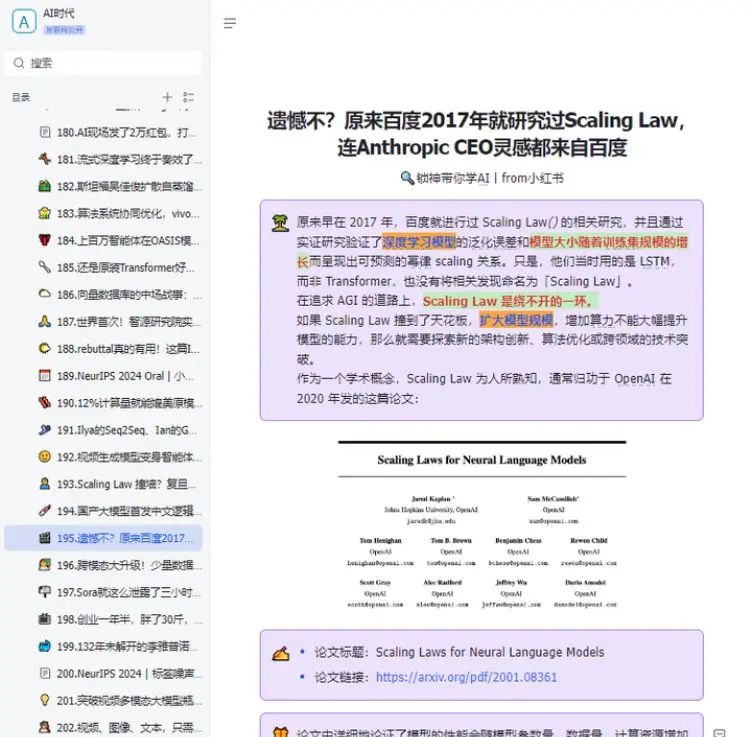
© 版权声明
文章版权归作者所有,未经允许请勿转载。











这东西还是看谁先做出来
Scaling law?原来早在 2017 年,百度就进行过 Scaling Law 的相关研究,并且通过实证研究验证了深度学习模型的泛化误差和模型大小随着训练集规模的增长而呈现出可预测的幂律 scaling 关系。只是,他们当时用的是 LSTM,而非 Transformer,也没有将相关发现命名为「Scaling Law」。在追求 AGI 的道路上,Scaling Law 是绕不开的一环。如果 Scaling Law 撞到了天花板,扩大模型规模,增加算力不能大幅提升模型的能力,那么就需要探索新的架构创新、算法优化或跨领域的技术突破。作为一个学术概念,Scaling Law 为人所熟知,通常归功于 OpenAI 在 2020 年发的这篇论文#AI顶会#深度学习模型#提升模型的能力#语言数据 #ai顶会