
GPT-5.5是高效通用的“任务执行者”,Claude Opus 4.7是专业深度的“复杂问题解决者”,两者形成明确的差异化互补格局。
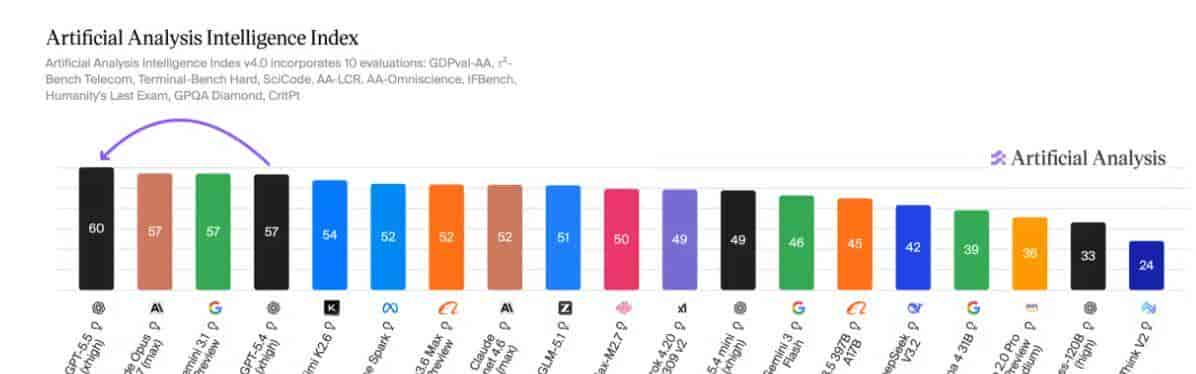
这个结论不是空话,而是由一系列关键数据和实际支撑的。简单来说,如果你需要快速完成大量基础工作,选GPT-5.5;如果你要攻坚高价值、高风险的复杂任务,选Claude 4.7。
编程场景:GPT负责“快”,Claude负责“稳”
在编程领域,两者的分工已经超级清晰。
- GPT-5.5:擅长小型脚本与命令行自动化
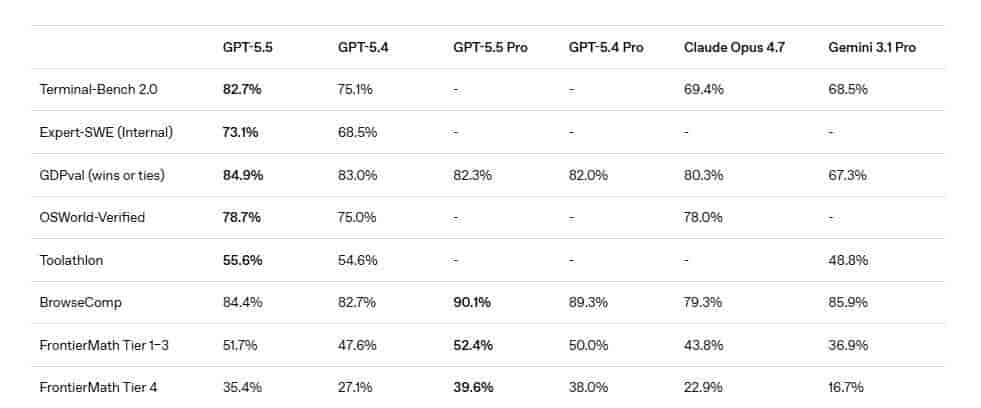
- 它在Terminal-Bench 2.0(考察复杂命令行工作流)中得分82.7%,领先Claude 4.7(69.4%)约13个百分点。这意味着它能更高效地帮你处理装依赖、跑脚本、看报错、继续改的“短循环”任务。
- 它的优势是“自主规划”,能把一个模糊指令拆解成多步骤并调用工具执行,减少你当“搬运工”的麻烦。例如,NVIDIA部署后,工程师通过自然语言指令就能完成端到端功能交付,将代码调试周期从数天压缩至数小时。
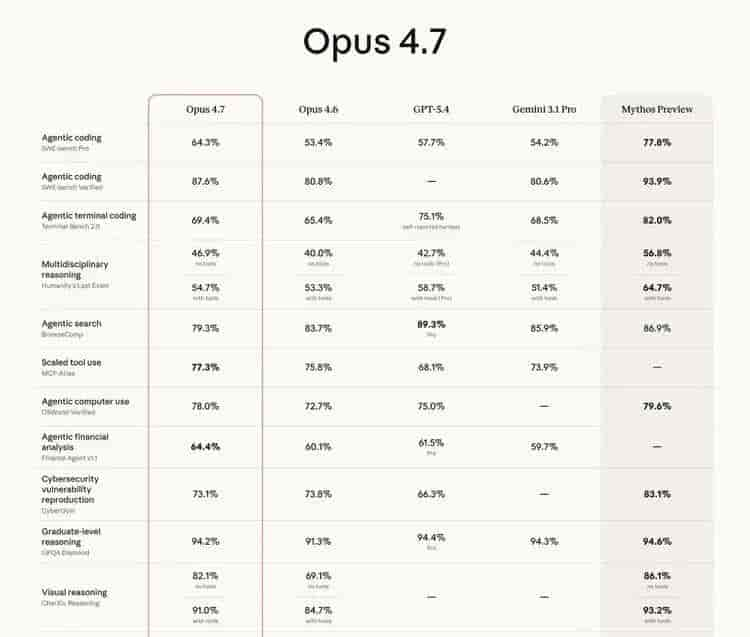
- Claude Opus 4.7:专攻大型项目与复杂修复
- 在SWE-bench Pro(修复真实GitHub Issue)测试中,Claude 4.7成功率为64.3%,领先GPT-5.5(58.6%)5.7个百分点。这说明在处理真实、复杂的代码库问题时,Claude更可靠。
- 开发者实测反馈,Claude 4.7在修改代码时更“克制”,会严格遵循“Minimal Diff”原则,只改需要改的地方,避免擅自重构引入新问题。在B站爬虫代码生成测试中,Claude一次成功率高达95%,而GPT一般需要2-3次迭代。
知识工作:GPT快速生成,Claude深度分析
在办公、写作、分析等白领工作中,两者的侧重点截然不同。
- GPT-5.5:高效的“办公助手”
- 在覆盖44个职业的GDPval测试中,GPT-5.5取得**84.9%**的胜率,超过了83%的真实职场人员水平。它擅长快速生成会议纪要、市场调研初稿,并跨工具(文档、表格、数据)自动化完成任务。
- OpenAI内部财务团队用它审核了24771份K-1税表、总计71637页文件,流程比上一年提前两周完成。这证明了它处理大规模、格式化信息整合的能力。
- Claude Opus 4.7:专业的“分析伙伴”
- 在OfficeQA Pro测试(解析近9万页历史文件)中,Claude 4.7得分80.6%,大幅领先GPT-5.4的51.1%。它在长文深度分析、复杂逻辑推理上优势明显。
- 它的长上下文(1M token)真正“可用”了,在BFS 1M(百万token图遍历)测试中,准确率从4.6的41.2%提升至58.6%。这让它能够稳定分析超长法律合同、技术规范或多卷财报。
专业领域:GPT覆盖通用,Claude深耕垂直
在特定行业,两者的优势划分明确。
- GPT-5.5:通用知识覆盖与网络安全
- 在CyberZoo网络安全测试中,GPT-5.5得分81.8%,展现出在通用技术领域的分析能力。它适合跨行业知识查询和早期科研探索。
- Claude Opus 4.7:金融、法律与高精度视觉
- 金融法律:它在法律AI平台Harvey的BigLaw基准上拿下90.9%的高分。Anthropic还推出了Claude for Word插件,专为法律审查、财务备忘录起草设计,支持在Word中直接编辑并保留格式。
- 视觉处理:图像分辨率上限提升至2576像素长边(约3.75百万像素),是前代的3倍以上。这使其能精准识别密集型图表、财务报表截图中的细节,无需预处理。
怎么选?看任务、成本和风险
选择的关键不是谁“更强”,而是谁“更合适”。
- 看任务类型:
- 选GPT-5.5:日常办公自动化、快速写脚本、处理零散数据分析。它像一个反应快、能跑腿的助手。
- 选Claude 4.7:维护大型代码库、起草法律合同、深度解读行业报告。它像一个严谨、有经验的专家。
- 看成本预算:
- GPT-5.5的成本约为Claude 4.7的1/4。对于需要大规模、高频次使用的场景,GPT-5.5的性价比优势巨大。
- 看风险承受能力:
- 金融、法律等低容错场景,应优先思考Claude 4.7,因其在专业领域工具链更完善,且以“低幻觉”和输出严谨著称。
- 创意原型、内部工具开发等容错率较高的场景,GPT-5.5的灵活性和速度更有吸引力。
所以,别再问“谁更强”。理想的工作流是:用GPT-5.5处理掉80%的日常重复性工作,解放出来的精力,再用Claude 4.7去攻克那20%决定性的复杂难题。这才是当下最明智的AI使用策略。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











