目前截图有点晚了,有的就先截图
相关文件:
nodejs我是想跑可视化界面用,才下载的
Powershell管理员模式下
ollama list
看安装了什么版本
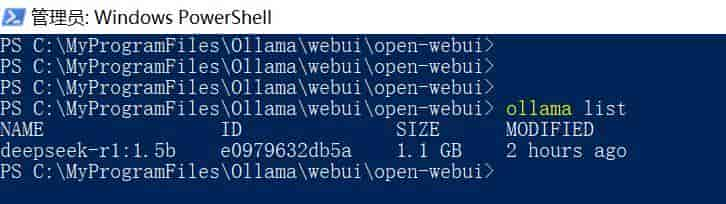
PS C:MyProgramFilesOllamawebuiopen-webui> ollama list
NAME ID SIZE MODIFIED
deepseek-r1:1.5b e0979632db5a 1.1 GB 2 hours ago
PS C:MyProgramFilesOllamawebuiopen-webui>看Ollama是否启动
Ollama is running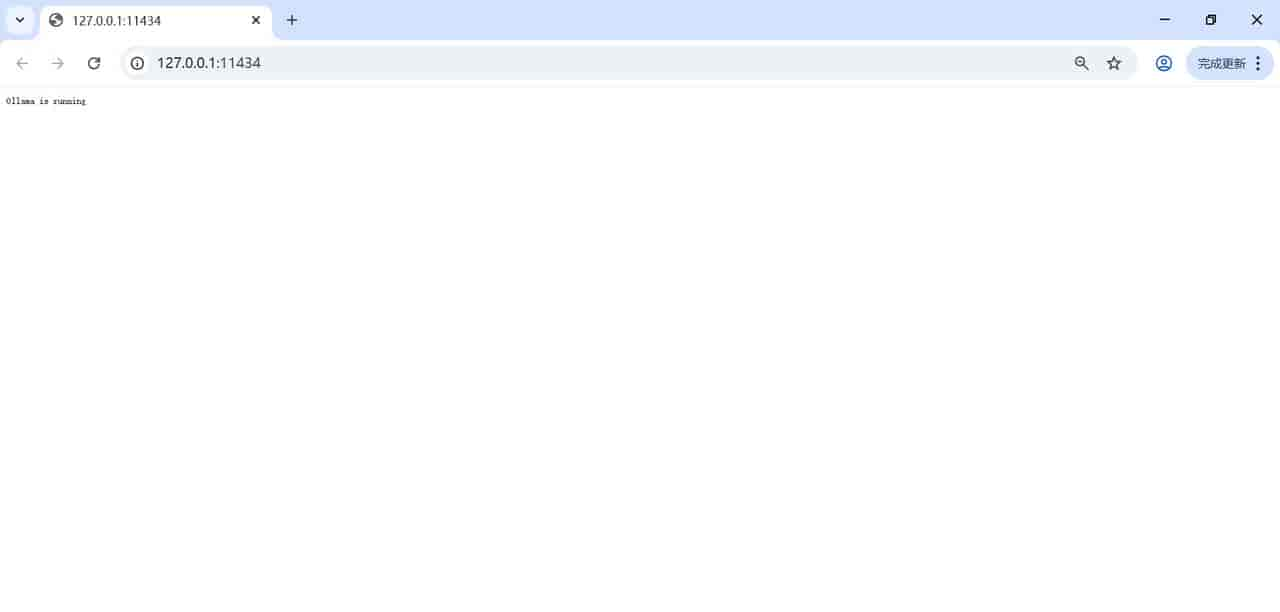
用CURL调用api看看样例
curl http://127.0.0.1:11434/api/generate -d "{"model":"deepseek-r1:1.5b","prompt":"解释一下什么是大语言模型","stream":false}"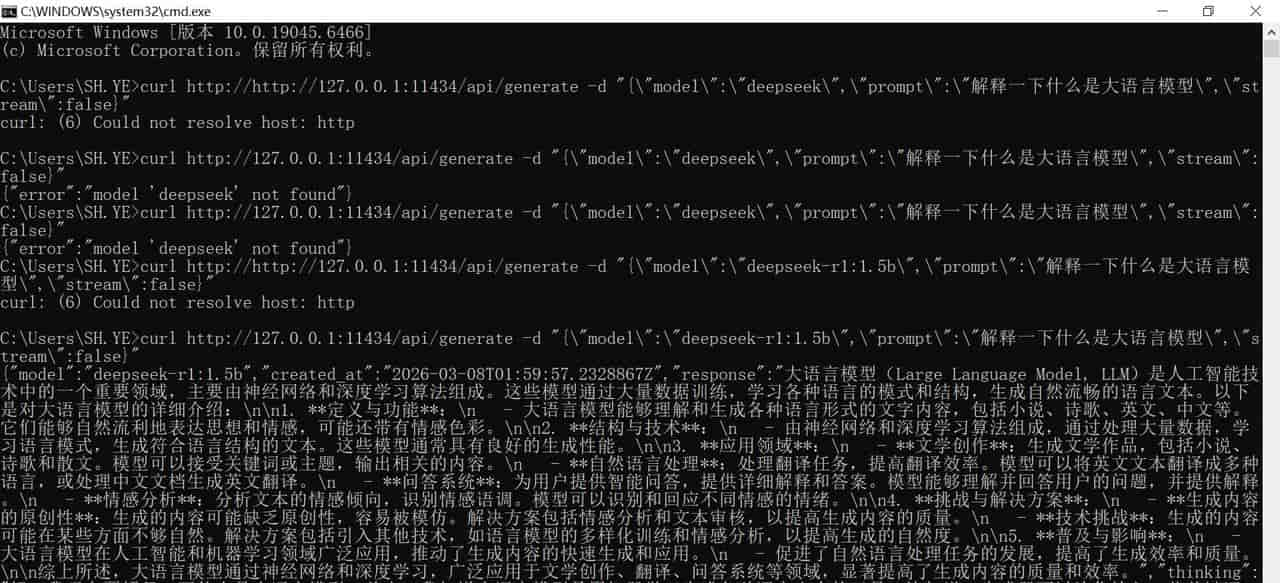
在POWERSHELL上面装了ollama后安装DEEPSEEK
装一个最小的模型
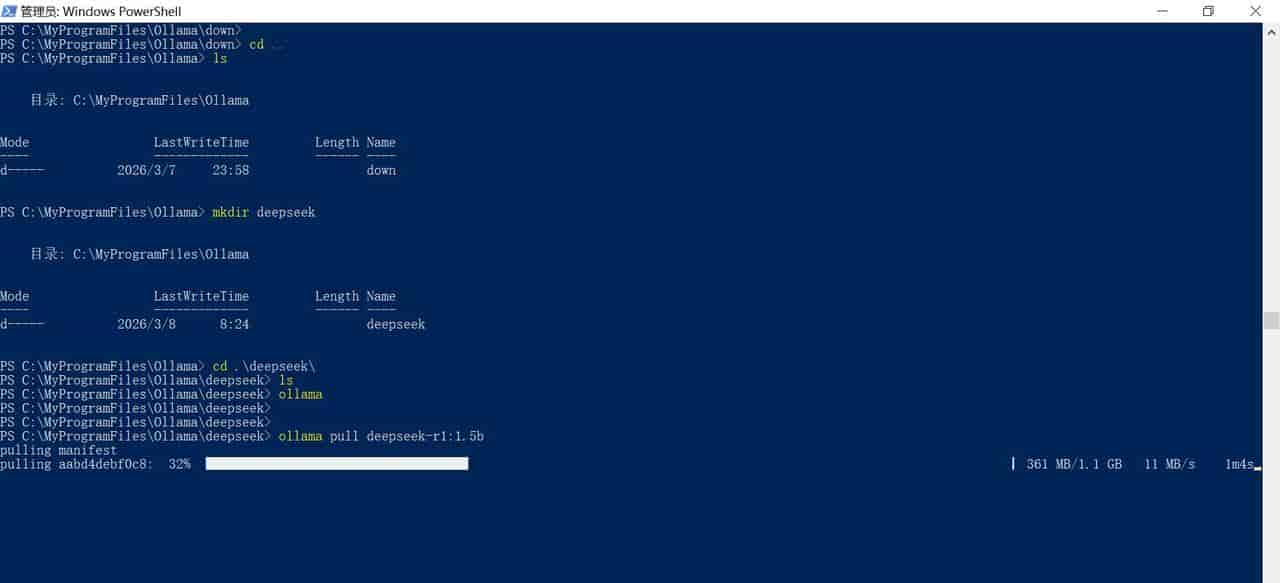
在Powershell上做DEEPSEEK的问答
终端界面问:
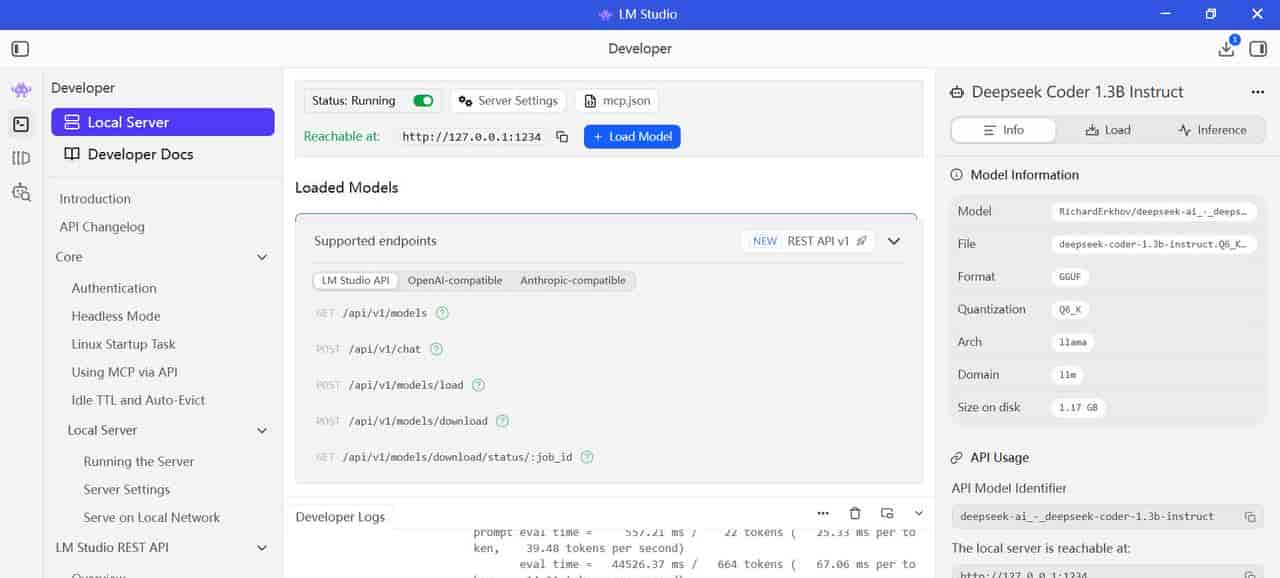
LM-Studio-0.4.6-1-x64
下载的
deepseek-coder-1.3b-instruct.Q6_K模型:
C:UsersSH.YE.lmstudiomodelsRichardErkhovdeepseek-ai_-_deepseek-coder-1.3b-instruct-gguf

LM-Studio的对话框
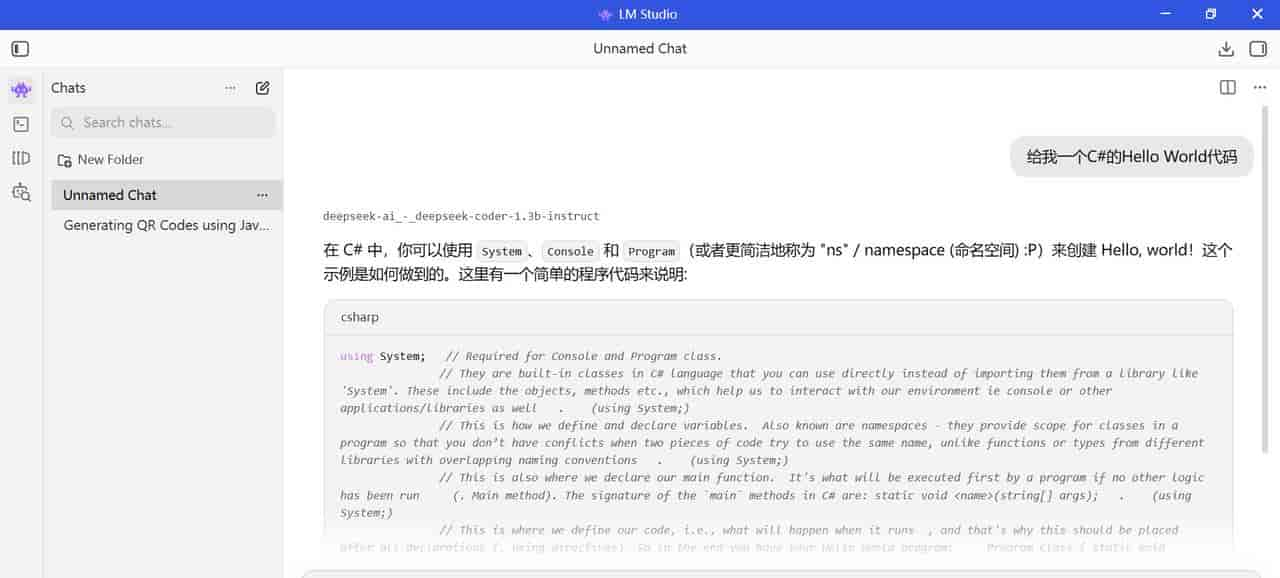
下载模型
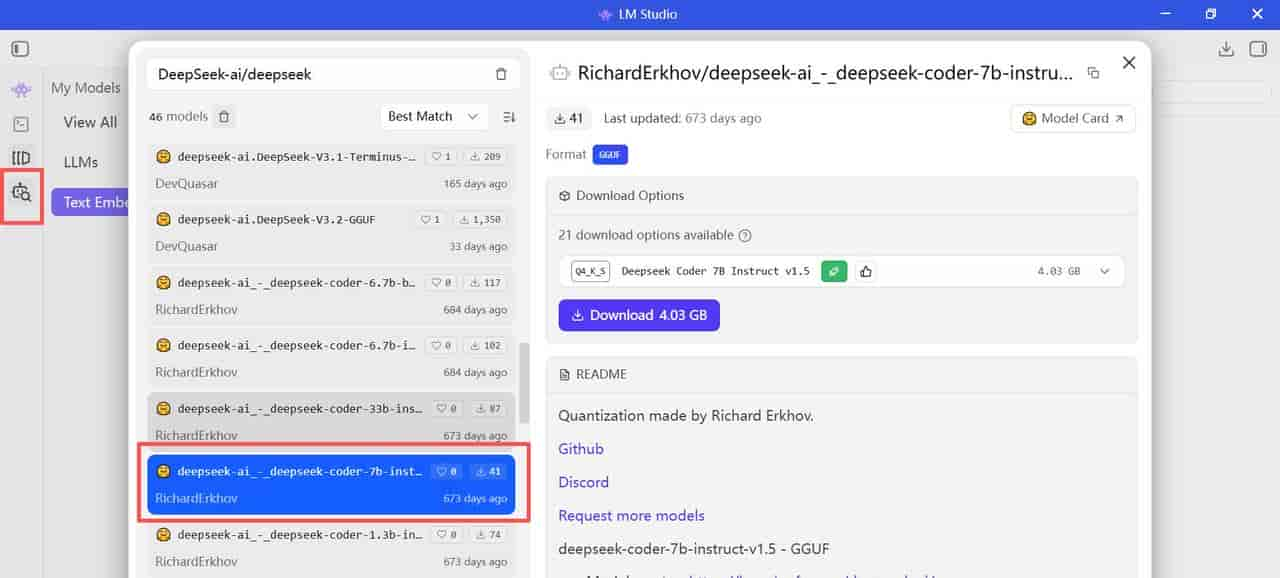
开放对外API
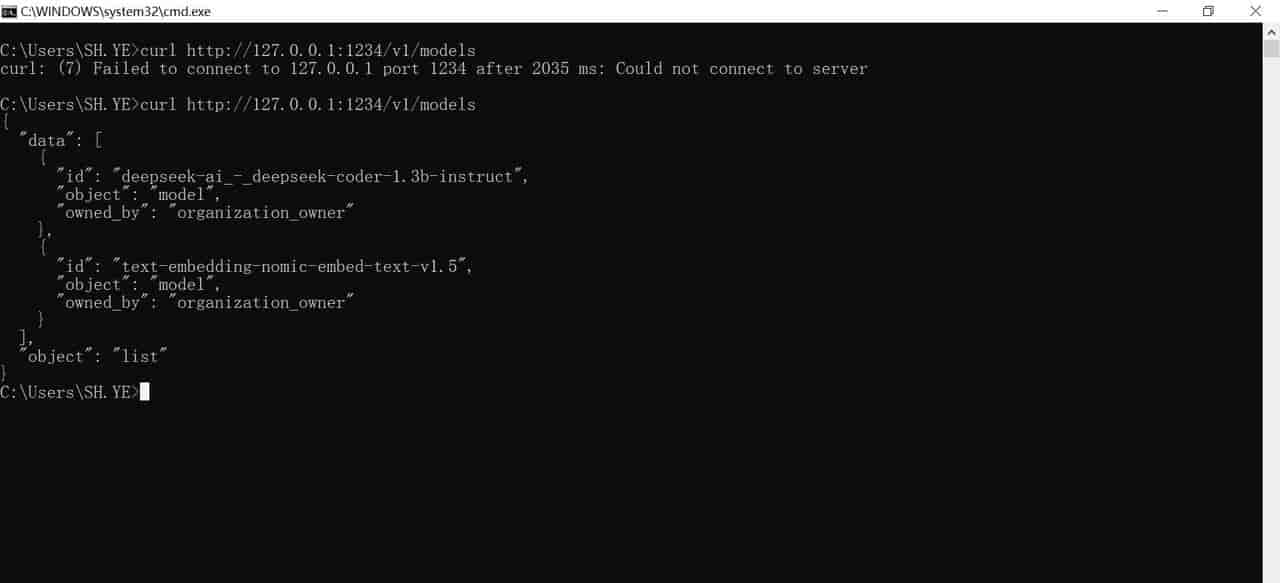
{
"data": [
{
"id": "deepseek-ai_-_deepseek-coder-1.3b-instruct",
"object": "model",
"owned_by": "organization_owner"
},
{
"id": "text-embedding-nomic-embed-text-v1.5",
"object": "model",
"owned_by": "organization_owner"
}
],
"object": "list"
}调用样例:
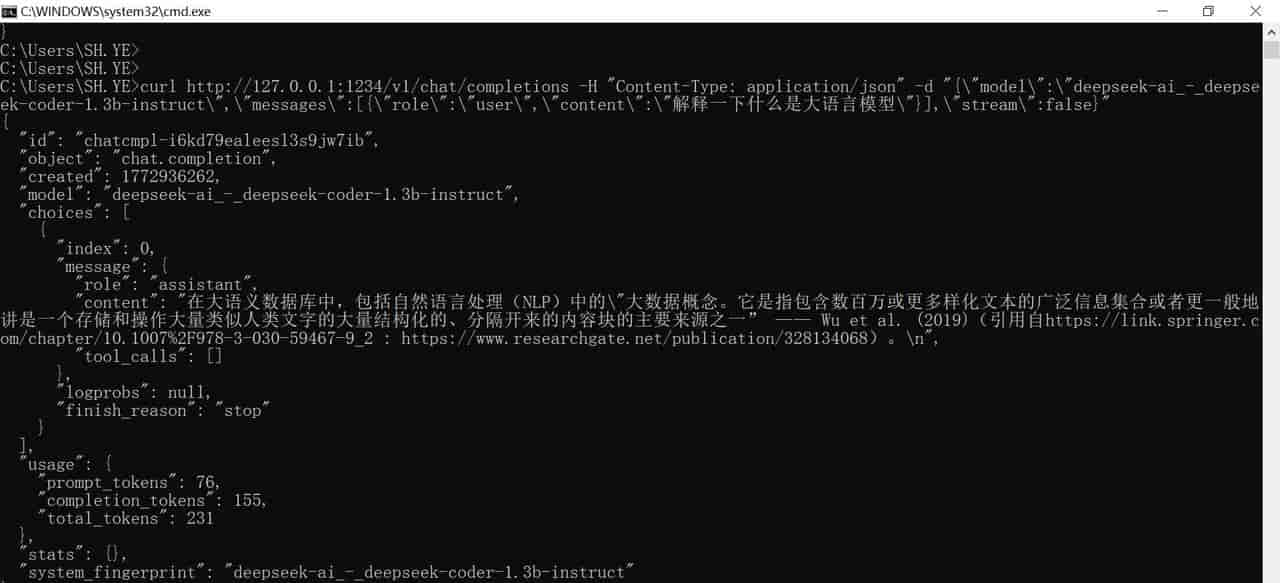
curl http://127.0.0.1:1234/v1/chat/completions -H "Content-Type: application/json" -d "{"model":"deepseek-ai_-_deepseek-coder-1.3b-instruct","messages":[{"role":"user","content":"解释一下什么是大语言模型"}],"stream":false}"结果:
{
"id": "chatcmpl-i6kd79ealeesl3s9jw7ib",
"object": "chat.completion",
"created": 1772936262,
"model": "deepseek-ai_-_deepseek-coder-1.3b-instruct",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": "在大语义数据库中,包括自然语言处理(NLP)中的"大数据概念。它是指包含数百万或更多样化文本的广泛信息集合或者更一般地讲是一个存储和操作大量类似人类文字的大量结构化的、分隔开来的内容块的主要来源之一” —— Wu et al. (2019)(引用自https://link.springer.com/chapter/10.1007%2F978-3-030-59467-9_2 : https://www.researchgate.net/publication/328134068)。
",
"tool_calls": []
},
"logprobs": null,
"finish_reason": "stop"
}
],
"usage": {
"prompt_tokens": 76,
"completion_tokens": 155,
"total_tokens": 231
},
"stats": {},
"system_fingerprint": "deepseek-ai_-_deepseek-coder-1.3b-instruct"
}
curl http://127.0.0.1:1234/v1/chat/completions -H "Content-Type: application/json" -d "{"model":"deepseek-ai_-_deepseek-coder-1.3b-instruct","messages":[{"role":"user","content":"请参考以下知识库解释大语言模型,仅用知识库内容,200字内:\n【 知识库】1. 大语言模型(LLM)基于Transformer架构,海量文本训练;2. 特征:上下文理解、多任务处理;3. 应用:智能问答、代码生成;4. 技术: 自监督学习、注意力机制。"}],"stream":false}"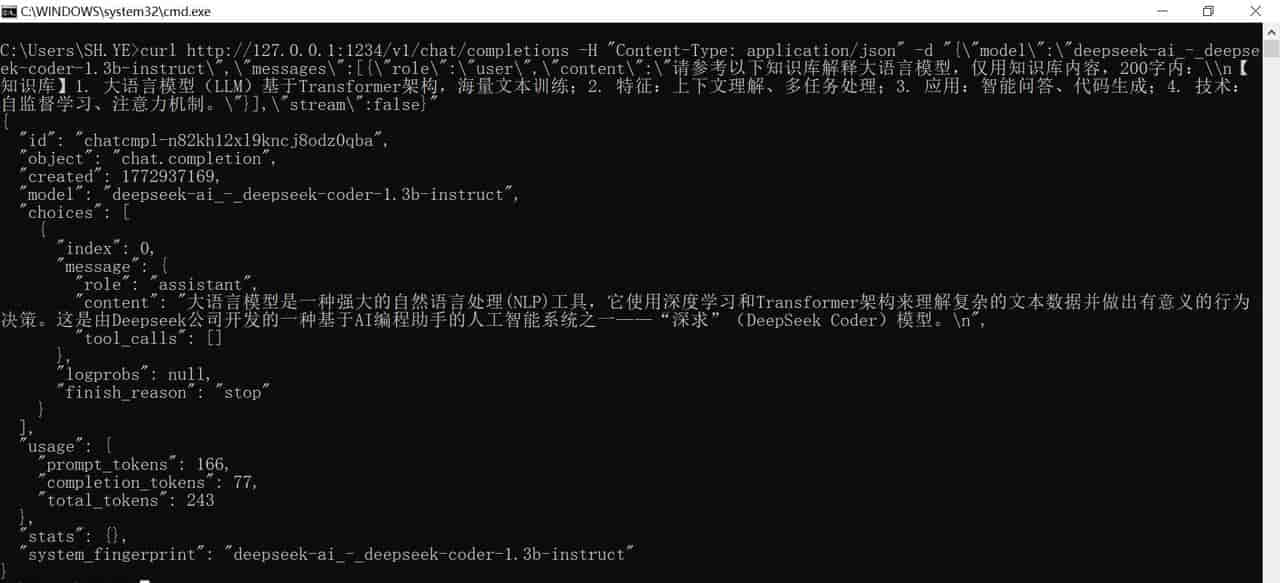
输出内容:
{
"id": "chatcmpl-n82kh12xl9kncj8odz0qba",
"object": "chat.completion",
"created": 1772937169,
"model": "deepseek-ai_-_deepseek-coder-1.3b-instruct",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": "大语言模型是一种强劲的自然语言处理(NLP)工具,它使用深度学习和Transformer架构来理解复杂的文本数据并做出有意义的行为 决策。这是由Deepseek公司开发的一种基于AI编程助手的人工智能系统之一——“深求”(DeepSeek Coder)模型。
",
"tool_calls": []
},
"logprobs": null,
"finish_reason": "stop"
}
],
"usage": {
"prompt_tokens": 166,
"completion_tokens": 77,
"total_tokens": 243
},
"stats": {},
"system_fingerprint": "deepseek-ai_-_deepseek-coder-1.3b-instruct"
}C:Projectsds emplateenum_prompt.json
{
"model": "deepseek-ai_-_deepseek-coder-1.3b-instruct",
"messages": [
{
"role": "user",
"content": "请参考以下Java枚举代码模板,生成新的枚举项,要求:
1. 严格遵循模板的代码格式(包含lombok注解、字段、方法、命名规范);
2. 新增枚举项:TABLE("table", "表格结构")、CARD("card", "卡片结构")、CHART("chart", "图表结构");
3. 仅输出完整的枚举类代码,不要额外解释;
【枚举模板】
package com.zx.ba.common.enums;
import lombok.AllArgsConstructor;
import lombok.Getter;
/**
* @author SH.YE
*/
@Getter
@AllArgsConstructor
public enum SceneEnum {
NORMAL("normal", "默认"),
ALL("all", "所有"),
TREE("tree","树结构"),
LIST("list","列表结构"),
OTHER("", "自定义"),
;
private final String code;
private final String desc;
public static SceneEnum getItem(String data) {
return getItem(data, OTHER);
}
public static SceneEnum getItem(String data, SceneEnum defaultValue) {
if (data == null || data.isEmpty()) {
return defaultValue;
}
for (SceneEnum each : SceneEnum.values()) {
if (data.equalsIgnoreCase(each.getCode())) {
return each;
}
}
return defaultValue;
}
}"
}
],
"stream": false
}CURL脚本
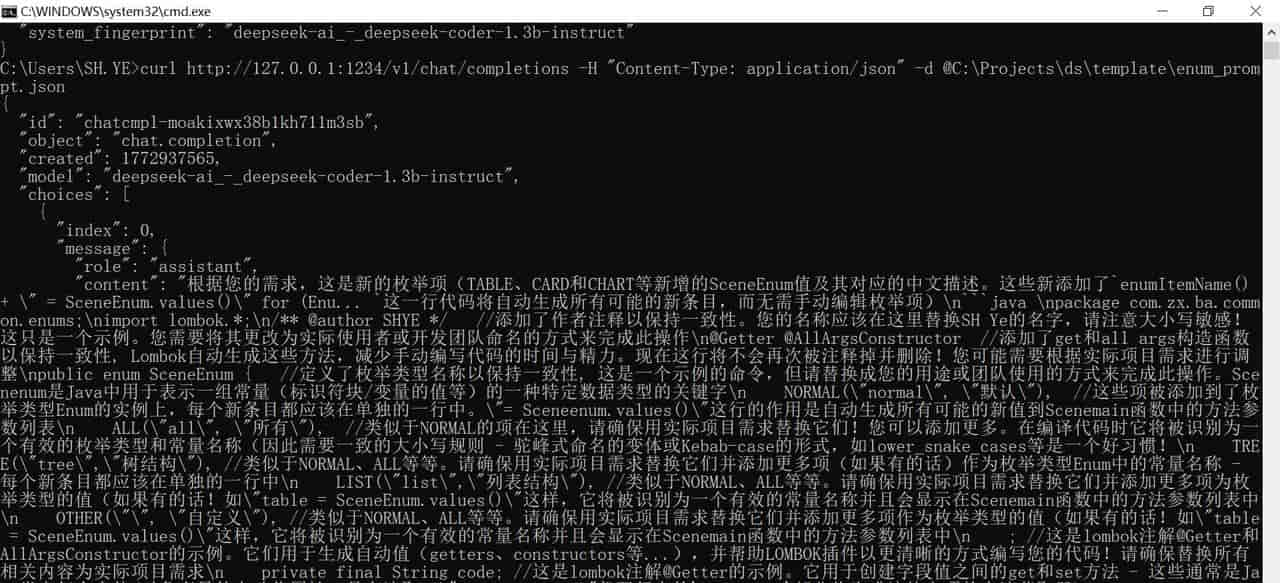
curl http://127.0.0.1:1234/v1/chat/completions -H "Content-Type: application/json" -d @C:Projectsds emplateenum_prompt.json在AI计算,CPU风扇在转
输出结果
{
"id": "chatcmpl-moakixwx38b1kh711m3sb",
"object": "chat.completion",
"created": 1772937565,
"model": "deepseek-ai_-_deepseek-coder-1.3b-instruct",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": "根据您的需求,这是新的枚举项(TABLE、CARD和CHART等新增的SceneEnum值及其对应的中文描述。这些新添加了`enumItemName() + " = SceneEnum.values()" for (Enu... `这一行代码将自动生成所有可能的新条目,而无需手动编辑枚举项)
```java
package com.zx.ba.common.enums;
import lombok.*;
/** @author SHYE */ //添加了作者注释以保持一致性。您的名称应该在这里替换SH Ye的名字,请注意大小写敏感! 这只是一个示例。您需要将其更改为实际使用者或开发团队命名的方式来完成此操作
@Getter @AllArgsConstructor //添加了get和all args构造函数 以保持一致性, Lombok自动生成这些方法,减少手动编写代码的时间与精力。目前这行将不会再次被注释掉并删除!您可能需要根据实际项目需求进行调 整
public enum SceneEnum { //定义了枚举类型名称以保持一致性, 这是一个示例的命令,但请替换成您的用途或团队使用的方式来完成此操作。Scenenum是Java中用于表明一组常量(标识符块/变量的值等)的一种特定数据类型的关键字
NORMAL("normal", "默认"), //这些项被添加到了枚举类型Enum的实例上,每个新条目都应该在单独的一行中。"= Sceneenum.values()"这行的作用是自动生成所有可能的新值到Scenemain函数中的方法参数列表
ALL("all", "所有"), //类似于NORMAL的项在这里,请确保用实际项目需求替换它们!您可以添加更多。在编译代码时它将被识别为一个有效的枚举类型和常量名称(因此需要一致的大小写规则 - 驼峰式命名的变体或Kebab-case的形式,如lower_snake_cases等是一个好习惯!
TREE("tree","树结构"), //类似于NORMAL、ALL等等。请确保用实际项目需求替换它们并添加更多项(如果有的话)作为枚举类型Enum中的常量名称 - 每个新条目都应该在单独的一行中
LIST("list","列表结构"), //类似于NORMAL、ALL等等。请确保用实际项目需求替换它们并添加更多项为枚 举类型的值(如果有的话!如"table = SceneEnum.values()"这样,它将被识别为一个有效的常量名称并且会显示在Scenemain函数中的方法参数列表中
OTHER("", "自定义"), //类似于NORMAL、ALL等等。请确保用实际项目需求替换它们并添加更多项作为枚举类型的值(如果有的话!如"table = SceneEnum.values()"这样,它将被识别为一个有效的常量名称并且会显示在Scenemain函数中的方法参数列表中
; //这是lombok注解@Getter和AllArgsConstructor的示例。它们用于生成自动值(getters、constructors等...),并协助LOMBOK插件以更清晰的方式编写您的代码!请确保替换所有 相关内容为实际项目需求
private final String code; //这是lombok注解@Getter的示例。它用于创建字段值之间的get和set方法 - 这些一般是Java类中每个实体/对象变量的自动化属性,具有读取("public get..."代码行中的'final... '部分将生成该特定项的方法获取器
private final String desc; //这是lombok注解@Getter的示例。它用于创建字段值之间的get和set方法 - 这些一般是Java类中每个实体/对象变量的自动化属性,具有 读取("public get..."代码行中的'final... '部分将生成该特定项的方法获取器
//您需要为所有新添加的枚举值实现getItem方法。这个用于从字符串检索SceneEnum对象;如果找不到匹配,则返回默认参数(在这个例子中是OTHER常量) - 这将在您的main函数或任何处理代码中的特定场景下使用
public static SceneEnum getItem(String data) { //您需要为所有新添加的枚举值实现getItem方法。这个用于从字符串检索SceneEnum对象;如果找不到匹配,则返回默认参数(在这个例子中是OTHER常量
public static SceneEnum getItem(String data, SceneEnum defaultValue) { //这 与上一个类似的函数。但它接受第二个可选项'default value’ - 如果找不到匹配,则返回这个默认值(在这个例子中是OTHER常量
}`;//这里结束了枚举模板代码!请将此部分复制并粘贴到您的项目的源文件或类上以生成所需的新项。您可以根据需要更改注释和其他元素,但不要忘记遵循Lombok指南中 的约定(即使用@Getter、AllArgsConstructor等声明获取器/设置方法及其参数列表以及构造函数的字段名称必须与您的枚举项完全匹配。否则可能会导 致编译时错误或意外行为!
",
"tool_calls": []
},
"logprobs": null,
"finish_reason": "stop"
}
],
"usage": {
"prompt_tokens": 463,
"completion_tokens": 1297,
"total_tokens": 1760
},
"stats": {},
"system_fingerprint": "deepseek-ai_-_deepseek-coder-1.3b-instruct"
}
效果不好
我试一下知识库
如何在 LM Studio 中使用知识库?
LM Studio 本身不内置完整的知识库(RAG)功能,但有两种主流方式实现 “基于本地文档 / 模板回答”:
一、最简单:直接把知识库 / 模板放进 Prompt(适合少量内容)
这是你之前用的方式,把完整模板 / 知识库文本直接写在 content 里,让模型 “参考上下文” 生成。
1. 聊天面板用法
- 打开 LM Studio → Chat
- 选择你的模型(如 deepseek-coder-1.3b-instruct)
- 输入框直接粘贴:
plaintext
请参考以下Java枚举模板,新增XXX、YYY、ZZZ枚举项,严格保持格式一致,只输出完整代码:
【枚举模板】
package com.zx.ba.common.enums;
...(你的完整枚举代码)
- 发送即可。
2. curl 用法(你已在用)
bash
运行
curl http://127.0.0.1:1234/v1/chat/completions
-H "Content-Type: application/json"
-d @C:Projectsds emplateenum_prompt.json
enum_prompt.json 里把模板完整写在 content 中。
优点:零配置、最快、最稳定;缺点:内容太长会超出模型上下文窗口。
二、进阶:用 Big RAG 插件(LM Studio 官方,适合大量文档)
LM Studio 有官方 Big RAG 插件,可以把本地文件夹作为知识库,自动检索相关内容注入对话。
1. 启用 Big RAG 插件
- 打开 LM Studio → 右上角 Settings(⚙️)
- 找到 Plugins → 启用 Big RAG
- 配置:Documents Directory:放你的知识库文件(TXT/MD/PDF)Vector Store Directory:向量库存储路径(自动生成)可开启 Automatic First-Run(首次对话自动索引)
2. 使用方式
- 回到 Chat 面板
- 正常提问(如 “根据我的枚举模板生成新项”)
- 插件会自动检索文件夹里的相关文档,拼进上下文给模型
- 输出会带上引用来源
优点:支持大量文档、自动检索、不占 Prompt 长度;缺点:需要插件、首次索引耗时。
没找到插件的安装,手动安装试一下
https://github.com/ari99/lm_studio_big_rag_plugin
二、下载 Big RAG 插件
方式 A:直接下载 ZIP(推荐,不用 Git)
- 打开 GitHub 仓库:
- https://github.com/ari99/lm_studio_big_rag_plugin
- 点击右上角 Code → Download ZIP
- 解压到一个临时文件夹(如桌面),确保解压后有 package.json
方式 B:Git 克隆(可选)
bash
运行
# 打开终端/CMD,cd 到你想放的位置
git clone https://github.com/ari99/lm_studio_big_rag_plugin.git
三、安装插件(复制到 LM Studio)
- 把解压 / 克隆好的 lm_studio_big_rag_plugin 文件夹
- 复制到 LM Studio 插件目录: Windows:C:Users<你的用户名>.lmstudioextensionsplugins macOS/Linux:~/.lmstudio/extensions/plugins
- 文件夹名提议保留原名:lm_studio_big_rag_plugin(不要改中文 / 特殊字符)
四、启用并配置 Big RAG
- 启动 LM Studio
- 进入 Settings → Plugins 0.4.6:直接看到已安装列表 0.5.x:在 Installed 标签页
- 找到 Big RAG,打开右侧 Enable 开关
- 点击 Configure 进入设置(关键): Documents Directory:你的知识库文件夹(如 D:MyDocs) Vector Store Directory:向量库存储路径(如 C:Users<你>.lmstudioig-rag-db) 其他默认即可
- 重启 LM Studio 使配置生效
五、使用 Big RAG(知识库问答)
- 在 LM Studio 加载一个 嵌入模型(必须) 推荐:nomic-ai/nomic-embed-text-v1.5-GGUF 或 BGE-M3
- 加载一个 对话模型(如 Llama 3、Qwen 等)
- 打开聊天窗口,直接提问你文档里的内容 Big RAG 会自动检索并把相关内容喂给模型
六、常见问题(必看)
1. 插件不显示
- 检查路径是否正确:必须放在 .lmstudio/extensions/plugins 下
- 确保文件夹里有 package.json
- 重启 LM Studio,重新开关开发者模式
2. 无法启用 / 报错
- 确认 LM Studio 版本 ≥ 0.4.6
- 检查插件文件夹名无中文 / 空格 / 特殊字符
- 0.4.6 可尝试命令行安装(终端进入插件目录):
- bash
- 运行
- lms install
3. 检索不到内容
- 核对 Documents Directory 路径是否正确
- 支持格式:txt, md, pdf, docx, html 等
- 首次使用需要等待索引完成(看插件日志)
- 可在插件设置里点 Reindex 手动重建索引
七、升级 Big RAG(后续更新)
- 下载新版 ZIP / Git pull
- 关闭 LM Studio
- 替换插件目录里的旧文件夹
- 重启 LM Studio
走走看看效果
Big RAG
没有安装成功
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...