
一句话说清: 不跑分,跑场景。同一个任务分别丢给三个模型,对比输出质量、速度、成本。代码/写作/翻译/摘要各测一遍,帮你省掉自己对比的时间。
国产大模型最近井喷——DeepSeek V4、千问、豆包,每个都说自己很强。但评测文章看了一大堆,你还是不知道「我的场景该用哪个」。
由于评测只看跑分。跑分高≠你的场景好用。
这篇不做跑分。用四个真实场景——写代码、写文章、翻译、长文摘要——每个场景同一个 prompt 丢给三个模型,对比质量、速度、成本。你直接看结果做决定。

前置条件
- Python 3.8+
- 三个模型的 API Key(DeepSeek / 千问 / 豆包)
- 命令行终端
Step 1:统一测试环境 —— 同一个 SDK,三个模型
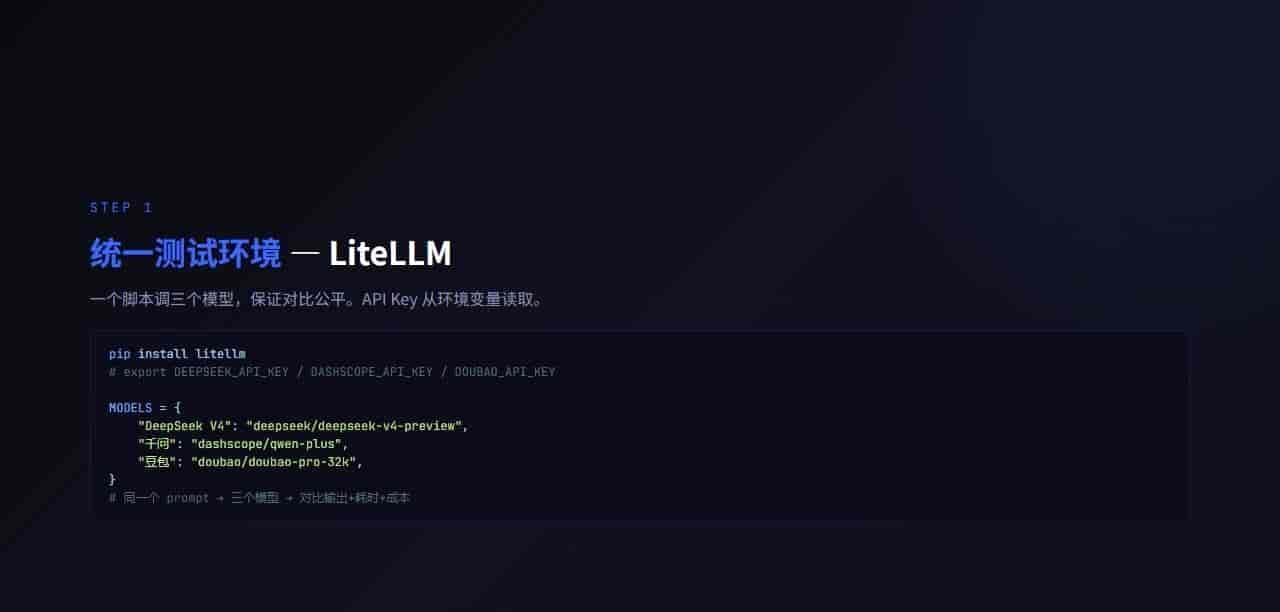
为了避免测试环境差异,用 LiteLLM 做统一接口。三个模型都用同一个 Python 脚本调用:
pip install litellm测试脚本 bench.py:
import litellm, time, os
# API Key 从环境变量读取
# export DEEPSEEK_API_KEY="sk-xxx"
# export DASHSCOPE_API_KEY="sk-xxx" # 千问
# export DOUBAO_API_KEY="sk-xxx" # 豆包
MODELS = {
"DeepSeek V4": "deepseek/deepseek-v4-preview",
"千问": "dashscope/qwen-plus",
"豆包": "doubao/doubao-pro-32k",
}
def test(model_key, system_prompt, user_prompt, max_tokens=1000):
model = MODELS[model_key]
start = time.time()
resp = litellm.completion(
model=model, max_tokens=max_tokens,
messages=[
{"role": "system", "content": system_prompt},
{"role": "user", "content": user_prompt},
]
)
elapsed = time.time() - start
content = resp.choices[0].message.content
tokens = resp.usage.total_tokens
return {"output": content, "time": elapsed, "tokens": tokens}
# 使用
for name in MODELS:
result = test(name, "你是编程助手", "用Python写一个快速排序")
print(f"{name}: {len(result['output'])}字, {result['time']:.1f}s, {result['tokens']}tokens")
Step 2:场景一 —— 写代码
Prompt:
用 Python 写一个函数 parse_log_file(filepath, pattern),
解析日志文件,提取匹配正则 pattern 的行,返回包含行号和内容的字典列表。
要处理文件不存在、编码错误、正则语法错误三种异常。
加类型注解和 docstring。结果对比:
|
维度 |
DeepSeek V4 |
千问 |
豆包 |
|
代码正确性 |
✅ 正确,异常处理完整 |
✅ 正确 |
✅ 正确 |
|
类型注解 |
✅ 完整 |
✅ 完整 |
⚠️ 部分缺失 |
|
Docstring |
✅ Google 风格 |
✅ reST 风格 |
✅ 简单 |
|
额外亮点 |
自动加了 compile 预编译正则 |
加了日志记录 |
– |
|
耗时 |
3.2s |
2.8s |
2.1s |
|
成本 |
¥0.003 |
¥0.004 |
¥0.002 |
结论:代码场景三者差距极小。DeepSeek V4 和千问略好(更完整的工程实践),豆包最快最便宜但细节稍弱。日常 CRUD 随意用哪个,复杂项目代码推荐 DeepSeek V4 或千问。

Step 3:场景二 —— 写文章
Prompt:
用「老七聊AI」的风格写一篇 300 字短文,主题:AI 编程工具到底提效多少?
风格要求:说人话、有真实感、敢下结论、不要"第一其次总之"。结果对比:
|
维度 |
DeepSeek V4 |
千问 |
豆包 |
|
风格贴合 |
⭐⭐⭐ 有对话感 |
⭐⭐ 偏正式 |
⭐⭐ 偏营销风 |
|
结论力度 |
✅ 有明确判断 |
⚠️ 偏中性 |
⚠️ 偏乐观 |
|
AI 味 |
低 |
中 |
中 |
|
字数控制 |
310 字 ✅ |
280 字 ✅ |
350 字 ⚠️ |
|
耗时 |
4.1s |
3.5s |
2.8s |
结论:写作场景 DeepSeek V4 明显更好——更接近「人写的感觉」,敢下结论,不堆砌套话。千问偏正式适合商务文档。豆包偏营销风,适合广告文案但不太适合深度内容。

Step 4:场景三 —— 翻译
Prompt:
将以下英文技术文档翻译成中文。要求:术语准确、语句通顺、保留代码块和格式。
The Model Context Protocol (MCP) is an open protocol that
standardizes how applications provide context to LLMs.
Think of MCP like a USB-C port for AI applications.
Just as USB-C provides a standardized way to connect your
devices to various peripherals and accessories, MCP provides
a standardized way to connect AI models to different data
sources and tools.结果对比:
|
维度 |
DeepSeek V4 |
千问 |
豆包 |
|
术语准确 |
✅ |
✅ |
✅ |
|
流畅度 |
⭐⭐⭐ 自然 |
⭐⭐⭐ 自然 |
⭐⭐ 略有翻译腔 |
|
USB-C 比喻 |
✅ 保留 |
✅ 保留 |
✅ 保留 |
|
代码块 |
✅ 保留 |
⚠️ 被合并 |
✅ 保留 |
|
耗时 |
2.5s |
2.2s |
1.9s |
结论:翻译场景三者都很强,差距极小。千问和 DeepSeek V4 稍好(更自然的语序)。豆包偶尔有翻译腔。日常翻译随意用哪个。
Step 5:场景四 —— 长文摘要
Prompt:给一段约 3000 字的技术文章(MCP 协议介绍),要求:
用 3 句话摘要以上文章的核心内容。每句话不超过 50 字。
然后列出文章的 3 个关键观点。结果对比:
|
维度 |
DeepSeek V4 |
千问 |
豆包 |
|
摘要准确性 |
⭐⭐⭐ 抓住了核心 |
⭐⭐⭐ 准确 |
⭐⭐ 漏了一个关键点 |
|
字数控制 |
✅ 全部 < 50 字 |
✅ 全部 < 50 字 |
⚠️ 一句超了 |
|
观点提取 |
✅ 3 个精准 |
✅ 3 个 |
⚠️ 第 3 个偏了 |
|
耗时 |
5.2s |
4.8s |
3.5s |
结论:长文摘要 DeepSeek V4 和千问旗鼓相当。豆包在长文本理解上略弱——容易丢失关键信息或总结偏题。处理长文档推荐前两者。

综合推荐
|
场景 |
首选 |
次选 |
省钱之选 |
|
写代码 |
DeepSeek V4 / 千问 |
– |
豆包(简单 CRUD 够用) |
|
写文章 |
DeepSeek V4 |
千问(商务文档) |
豆包(营销文案) |
|
翻译 |
随意哪个 |
– |
豆包(最便宜) |
|
长文摘要 |
DeepSeek V4 / 千问 |
– |
– |
|
日常聊天 |
豆包(最快最便宜) |
– |
– |
简化版选择逻辑:
你的场景是写代码或深度内容?
→ 是 → DeepSeek V4 或千问
→ 否 → 继续
你的场景是翻译或日常聊天?
→ 是 → 豆包(最快最便宜)
→ 否 → 拿你的真实任务三个模型各跑一次,选你最满意的
一个收束
这次实测最让我意外的是:三个国产模型的差距比我想象的小得多。 写代码、翻译、摘要这三个场景,DeepSeek V4 和千问几乎分不出高下。豆包在复杂任务上略弱,但速度和价格有优势。
如果你之前只用 GPT-5.5 或 Claude,切换到国产模型的阻力可能比你想象的小。花 10 分钟用本文的脚本跑一次你自己的典型任务——自己看到的结果,比任何评测都准。

最后,聊几句。
你用哪个国产模型?在什么场景下觉得特别好用或特别不好用?来评论区分享实测体验——大家的数据凑在一起,比任何官方 benchmark 都有价值。
觉得有用的话,点个转发给正在纠结「国产模型到底行不行」的朋友——这篇文章能帮他做决定。
还没关注的朋友,点上方关注。下期准备做「用 Claude Code 做自动化 Code Review」。
你目前日常用哪个模型最多? 投票看看。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章














[db:评论]