
作者:架构源启-12年OTA公司资深程序员
技术栈:Spring Boot 3.5.9 + Spring AI 1.1.4 + Chroma + SiliconFlow
前置知识:已完成前五篇博客

前言
在之前的文章中,我们学习了如何让 AI 聊天、生成图片、流式输出、调用函数。但这些都是基于 AI 模型训练时的知识,存在以下问题:
传统 AI 的局限性:
- ❌ 知识截止:只能回答训练数据之前的问题
- ❌ 无法访问最新信息:不知道昨天的新闻
- ❌ 容易产生”幻觉”:编造看似合理但错误的答案
- ❌ 缺乏企业私有知识:不了解公司内部文档
RAG 技术的优势:
- ✅ 实时知识:可以访问最新的企业文档
- ✅ 答案可追溯:能指出答案来源
- ✅ 减少幻觉:基于实际回答问题
- ✅ 保护隐私:敏感数据不必用于模型训练
- ✅ 成本低:无需重新训练模型
什么是 RAG?
RAG(Retrieval-Augmented Generation,检索增强生成)是一种结合信息检索和文本生成的技术架构。
工作原理:
用户提问 → 检索相关知识 → 组装 Prompt → LLM 生成答案
类比理解:
- 传统 AI = 闭卷考试(全靠记忆)
- RAG = 开卷考试(可以查资料)
显然,开卷考试的答案更准确!
本文你将学到
✅ RAG 架构原理与工作流程
✅ 向量数据库选型对比(pgvector vs Milvus vs Chroma)
✅ 文档加载与分割策略详解
✅ Embedding 模型配置与优化
✅ 类似度搜索算法深度解析
✅ 完整的 RAG 问答系统实现
✅ 性能优化技巧(索引、缓存、批处理)
✅ 生产环境最佳实践
✅ 实战:企业文档问答系统
准备好了吗?让我们开始构建智能问答系统吧!
一、RAG 架构原理深度解析
1.1 RAG 工作流程
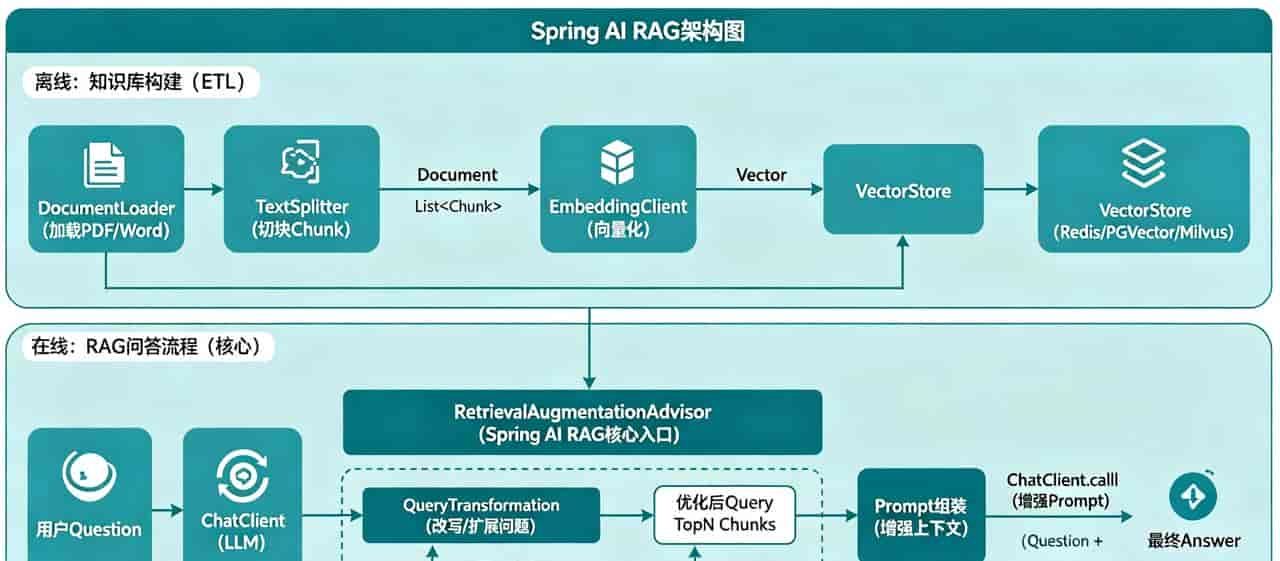
┌─────────────────────────────────────────────────────┐
│ 用户提出问题 │
│ "如何办理酒店退房手续?" │
└──────────────────┬──────────────────────────────────┘
↓
┌─────────────────────────────────────────────────────┐
│ Step 1: Query Embedding │
│ 将问题转换为向量(1536维) │
│ [0.1, -0.3, 0.5, ..., 0.2] │
└──────────────────┬──────────────────────────────────┘
↓
┌─────────────────────────────────────────────────────┐
│ Step 2: Vector Search │
│ 在向量数据库中类似度搜索 │
│ 返回 Top-K 最相关的文档片段 │
└──────────────────┬──────────────────────────────────┘
↓
┌─────────────────────────────────────────────────────┐
│ Step 3: Context Assembly │
│ 组装 Prompt: │
│ - 系统提示词 │
│ - 检索到的相关文档 │
│ - 用户问题 │
└──────────────────┬──────────────────────────────────┘
↓
┌─────────────────────────────────────────────────────┐
│ Step 4: LLM Generation │
│ 调用 LLM 生成答案 │
│ 基于提供的上下文回答问题 │
└──────────────────┬──────────────────────────────────┘
↓
┌─────────────────────────────────────────────────────┐
│ 返回答案给用户 │
│ "办理退房手续的步骤如下:..." │
└─────────────────────────────────────────────────────┘
1.2 核心组件详解
1. Embedding 模型(嵌入模型)
作用:将文本转换为向量表明,是 RAG 系统的“语义翻译官”。
1.1 主流 Embedding 模型对比选型表(中文RAG/知识库/检索专用)
一、中文文本Embedding 核心模型表
|
模型名称 |
向量维度 |
开源 |
优势亮点 |
适合场景 |
推荐指数 |
|
BGE-small-zh |
512 |
✅ |
轻量极速、中文适配好、占用显存低 |
中小型知识库、低配置服务器、高并发 |
⭐⭐⭐⭐ |
|
BGE-base-zh |
768 |
✅ |
均衡性能、检索精度高、工业级常用 |
企业RAG、文档检索、生产落地 |
⭐⭐⭐⭐⭐ |
|
BGE-large-zh |
1024 |
✅ |
中文语义最强、长文本匹配准 |
精准知识库、法律/政务/专业文档 |
⭐⭐⭐⭐⭐ |
|
M3E-small/base/large |
512/768/1024 |
✅ |
速度快、抗歧义、性价比极高 |
替代BGE、批量向量化 |
⭐⭐⭐⭐ |
|
E5-small/base/large |
384/768/1024 |
✅ |
中英双语强、检索SOTA |
中英文混合知识库 |
⭐⭐⭐⭐ |
|
千问 Qwen-Embedding |
1024 |
阿里API |
多语言强、代码+文档检索优秀 |
商用API、不想本地部署 |
⭐⭐⭐⭐ |
|
GLM-Embedding |
1024 |
智谱API |
中文理解顶级、长文本友善 |
国内企业RAG、合规私有化API |
⭐⭐⭐⭐⭐ |
|
文心 Ernie-Embedding |
1024 |
百度API |
中文场景适配强、领域微调成熟 |
政务、教育、企业知识库 |
⭐⭐⭐ |
|
all-MiniLM-L6-v2 |
384 |
✅ |
极小体积、推理飞快 |
低配机器、边缘服务、简易检索 |
⭐⭐⭐ |
二、国际通用 Embedding 模型
|
模型名称 |
向量维度 |
开源 |
特点 |
适用 |
|
text-embedding-ada-002 |
1536 |
❌ |
经典稳定、通用均衡 |
海外业务、英文文档 |
|
text-embedding-3-small |
1536 |
❌ |
性价比高、速度快 |
批量向量化 |
|
text-embedding-3-large |
3072 |
❌ |
精度拉满、复杂语义 |
高精度检索、专业知识库 |
|
Sentence-BERT(SBERT) |
768/384 |
✅ |
句向量标杆、类似度计算稳 |
通用句子匹配、聚类 |
三、多模态 Embedding(图文跨模态)
|
模型 |
能力 |
开源 |
用途 |
|
CLIP |
文本+图像统一向量 |
✅ |
图文检索、以图搜图、零样本分类 |
|
BLIP/ALBEF |
图文匹配、特征提取 |
✅ |
多模态RAG、图片知识库 |
|
ResNet/EfficientNet |
图像特征Embedding |
✅ |
图片分类、特征入库、类似图检索 |
四、极简选型推荐(直接照着选)
- 本地部署、中文RAG首选:BGE-large-zh > M3E-large > BGE-base-zh
- 服务器配置低、要快:BGE-small-zh / all-MiniLM-L6-v2
- 不想部署、直接调用API:国内推荐 GLM-Embedding、Qwen-Embedding
- 中英文混合文档:E5 系列
- 图片+文本知识库:CLIP 多模态Embedding
选择提议:
- 英文为主:OpenAI embeddings (text-embedding-3-large)
- 中文为主:BGE (BAAI) 或 M3E
- 多语言/混合:BGE-M3 或 E5
2. 向量数据库
作用:存储和检索向量数据,是 RAG 系统的“记忆中枢”。
关于主流向量数据库(Milvus, pgvector, Qdrant 等)的详细选型对比与深度解析,请参见本文 第二章:向量数据库选型与技术对比。
3. 文档分割器(Text Splitter)
作用:将长文档切分为小片段
为什么需要分割?
- LLM 上下文窗口有限(如 128K tokens)
- 小片段更容易找到相关部分
- 减少 token 使用量,降低成本
分割策略:
- 固定长度分割
- Token 分割(推荐)
- 递归字符分割
- 语义分割(高级)
4. 类似度搜索算法
常用算法:
|
算法 |
公式 |
特点 |
|
余弦类似度 |
cos(θ) = (A·B)/( |
|
|
欧氏距离 |
d = √(Σ(ai-bi)²) |
衡量绝对距离 |
|
内积 |
IP = A·B |
计算最快,需归一化 |
1.3 RAG vs Fine-tuning 对比
|
维度 |
RAG |
Fine-tuning |
|
更新频率 |
实时更新 |
需重新训练 |
|
成本 |
低 |
高 |
|
可解释性 |
高(可追溯来源) |
低(黑盒) |
|
适用场景 |
动态知识、私有数据 |
领域专业化、风格统一 |
|
实施难度 |
低 |
高 |
|
幻觉风险 |
低 |
中 |
最佳实践:RAG + Fine-tuning 结合使用
- RAG 处理动态知识
- Fine-tuning 优化专业领域表现
二、向量数据库选型与技术对比
在开始实现之前,我们需要选择合适的向量数据库。这是 RAG 系统的核心组件之一。
2.1 主流向量数据库深度对比表
|
向量数据库 |
开发语言 |
最大向量规模 |
检索延迟 |
高并发 |
混合检索 (向量 + 标量) |
多模态 |
部署难度 |
最适合场景 |
|
Milvus |
C++/Go |
百亿级 |
低 |
极强 |
支持 |
支持图文音 |
中等 |
企业生产、海量知识库、分布式 RAG |
|
Qdrant |
Rust |
十亿级 |
极低 |
极强 |
强支持 |
支持 |
简单 |
中小生产、边缘部署、高过滤检索 |
|
Weaviate |
Go |
十亿级 |
低 |
强 |
原生 BM25 + 向量 |
原生多模态 |
中等 |
图文知识库、知识图谱、混合搜索 |
|
Chroma |
Python |
百万级 |
中 |
一般 |
基础支持 |
基础支持 |
极简 |
本地 Demo、原型开发、个人项目 |
|
FAISS |
C++/Python |
十亿级 (单机) |
极低 |
弱 |
不支持 |
可二次开发 |
中等 |
离线批量检索、算法实验、单机高性能 |
|
pgvector |
C (PG 插件) |
千万级 |
中低 |
中等 |
SQL + 向量强融合 |
弱 |
极简 |
已有 PostgreSQL、强事务、中小 RAG |
|
Redis Vector |
C |
千万级 |
亚毫秒 |
顶级 |
支持 |
弱 |
极简 |
对话记忆、实时 RAG、超高吞吐低延迟 |
|
Elasticsearch |
Java |
十亿级 |
中 |
强 |
BM25 + 向量双引擎 |
支持 |
偏高 |
文档检索、日志 RAG、关键词 + 语义混合 |
2.2 详细技术分析
PostgreSQL + pgvector
简介:PostgreSQL 的向量搜索扩展
优势:
- ✅ 与现有基础设施集成:如果已使用 PostgreSQL,无需新增组件
- ✅ ACID 事务支持:保证数据一致性
- ✅ SQL 查询能力:可以结合关系型数据进行复杂查询
- ✅ 成熟稳定:PostgreSQL 社区强劲,长期支持
- ✅ 成本低:开源免费
劣势:
- ❌ 性能不如专用向量库:大规模数据时查询较慢
- ❌ 索引构建慢:百万级向量索引需要较长时间
- ❌ 功能相对简单:缺少高级向量搜索功能
适用场景:
- 中小规模应用(< 100万向量)
- 已有 PostgreSQL 基础设施
- 需要关系型数据+向量混合查询
- 对成本敏感的项目
性能指标:
- 10万向量:查询延迟 ~10ms
- 100万向量:查询延迟 ~50ms
- 索引大小:约向量大小的 1.5倍
Milvus
简介:专为向量搜索设计的分布式数据库
优势:
- ✅ 高性能:专为向量搜索优化
- ✅ 高并发:支持数千 QPS
- ✅ 分布式架构:水平扩展能力强
- ✅ 丰富的索引类型:HNSW、IVF、SCANN 等
- ✅ 云原生:支持 Kubernetes 部署
劣势:
- ❌ 运维复杂度高:需要专业团队维护
- ❌ 资源占用大:内存和存储需求高
- ❌ 学习曲线陡:概念较多
适用场景:
- 大规模应用(> 1000万向量)
- 高并发查询需求(> 1000 QPS)
- 企业级生产环境
- 需要分布式部署
性能指标:
- 1000万向量:查询延迟 ~20ms
- 并发能力:5000+ QPS
- 支持 PB 级数据
Chroma
简介:轻量级向量数据库,Python 生态友善
优势:
- ✅ 极易部署:单文件即可运行
- ✅ Python 友善:原生 Python API
- ✅ 适合原型开发:快速验证想法
- ✅ 内置 Embedding:简化开发流程
劣势:
- ❌ Java 生态支持弱:主要通过 REST API
- ❌ 生产环境案例少:稳定性待验证
- ❌ 性能有限:不适合大规模应用
适用场景:
- 原型开发和 POC
- 小规模应用(< 10万向量)
- Python 技术栈团队
- 快速迭代项目
性能指标:
- 10万向量:查询延迟 ~30ms
- 最大推荐:< 50万向量
Pinecone(云服务)
简介:完全托管的向量数据库服务
优势:
- ✅ 零运维:完全托管,无需关心基础设施
- ✅ 自动扩展:根据负载自动调整
- ✅ 全球 CDN:低延迟访问
- ✅ 企业级 SLA:99.9% 可用性保证
劣势:
- ❌ 成本较高:按用量计费
- ❌ 数据出境问题:服务器在海外
- ❌ 供应商锁定:迁移成本高
适用场景:
- 快速上线的项目
- 无 DevOps 团队的初创公司
- 全球化应用
- 预算充足的 enterprise 项目
价格参考:
- Starter: $70/月(100万向量)
- Business: $450/月起
Elasticsearch
简介:搜索引擎,支持向量搜索
优势:
- ✅ 混合搜索:关键词 + 向量组合
- ✅ 已有基础设施:许多公司已部署 ES
- ✅ 强劲的全文搜索:成熟的文本搜索能力
- ✅ 生态系统完善:Kibana 可视化工具
劣势:
- ❌ 向量搜索性能一般:不如专用向量库
- ❌ 资源消耗大:JVM 内存占用高
- ❌ 配置复杂:需要调优多个参数
适用场景:
- 已有 Elasticsearch 基础设施
- 需要混合搜索(关键词+向量)
- 中等规模应用
- 已有 ES 运维经验
性能指标:
- 100万向量:查询延迟 ~40ms
- 支持混合查询
2.2 选型决策矩阵
|
维度 |
pgvector |
Milvus |
Chroma |
Pinecone |
ES |
|
性能 |
⭐⭐⭐ |
⭐⭐⭐⭐⭐ |
⭐⭐ |
⭐⭐⭐⭐ |
⭐⭐⭐ |
|
易用性 |
⭐⭐⭐⭐ |
⭐⭐ |
⭐⭐⭐⭐⭐ |
⭐⭐⭐⭐⭐ |
⭐⭐⭐ |
|
成本 |
⭐⭐⭐⭐⭐ |
⭐⭐⭐ |
⭐⭐⭐⭐⭐ |
⭐⭐ |
⭐⭐⭐ |
|
可扩展性 |
⭐⭐⭐ |
⭐⭐⭐⭐⭐ |
⭐⭐ |
⭐⭐⭐⭐⭐ |
⭐⭐⭐⭐ |
|
运维难度 |
⭐⭐⭐⭐ |
⭐⭐ |
⭐⭐⭐⭐⭐ |
⭐⭐⭐⭐⭐ |
⭐⭐⭐ |
|
社区支持 |
⭐⭐⭐⭐⭐ |
⭐⭐⭐⭐ |
⭐⭐⭐ |
⭐⭐⭐⭐ |
⭐⭐⭐⭐⭐ |
2.3 选型提议
场景1:初创公司/小团队
- 推荐:pgvector 或 Chroma
- 理由:成本低、易上手、足够应对早期需求
场景2:中大型企业
- 推荐:Milvus 或 Pinecone
- 理由:高性能、高可用、可扩展
场景3:已有 ES 基础设施
- 推荐:Elasticsearch
- 理由:复用现有资源,降低复杂度
场景4:快速验证 POC
- 推荐:Chroma 或 Pinecone
- 理由:部署快、开发效率高
场景5:混合搜索需求
- 推荐:Elasticsearch 或 pgvector
- 理由:支持关键词+向量组合查询
2.4 本文选择:Chroma
选择理由:
- ✅ 极易部署,单文件即可运行
- ✅ 学习成本低,API 简洁直观
- ✅ 足够应对中小规模应用(< 100万向量)
- ✅ 开源免费,无供应商锁定
- ✅ Spring AI 原生支持,通过 REST API 交互
注意事项:
- 当向量数量超过 100万时,思考迁移到 Milvus 或 Qdrant
- 生产环境提议启用 Chroma 的持久化存储
- 适合快速原型开发和中小型 RAG 系统
三、环境准备与配置
2.1 添加依赖
在 pom.xml 中添加 RAG 相关依赖:
<dependencies>
<!-- Spring AI Vector Store for Chroma -->
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-vector-store-chroma</artifactId>
</dependency>
<!-- Document Loaders -->
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-pdf-document-reader</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-markdown-document-reader</artifactId>
</dependency>
</dependencies>
2.2 安装 Chroma
方式一:Docker 快速启动(推荐)
# 拉取 Chroma 镜像并启动
docker run -d
--name chroma
-p 8000:8000
chromadb/chroma:latest
# 验证安装
curl http://localhost:8000/api/v1/heartbeat
预期输出:
{"nanosecond heartbeat": 1234567890}
方式二:Python pip 安装
# 安装 Chroma
pip install chromadb
# 启动 Chroma 服务器
chroma run --path /path/to/persist/directory --port 8000
持久化配置:
- Chroma 默认将数据存储在内存中
- 通过 –path 参数指定持久化目录
- 重启后数据不会丢失
2.3 配置文件详解
application.yml 完整配置
server:
port: 8080
spring:
# Spring AI 配置
ai:
# OpenAI 兼容配置(指向硅基流动)
openai:
api-key: ${SILICONFLOW_API_KEY}
base-url: https://api.siliconflow.cn/v1
# Chat 模型配置
chat:
options:
model: Qwen/Qwen2.5-7B-Instruct
temperature: 0.3 # RAG 场景用较低温度
# Embedding 模型配置
embedding:
options:
model: BAAI/bge-large-zh-v1.5
dimensions: 1024
# Vector Store 配置
vectorstore:
chroma:
client-host: http://localhost # Chroma 服务器地址
client-port: 8000 # Chroma 端口
collection-name: spring-ai-collection # 集合名称
initialize-schema: true # 自动初始化
关键配置说明:
|
配置项 |
说明 |
推荐值 |
|
client-host |
Chroma 服务器地址 |
http://localhost |
|
client-port |
Chroma 端口 |
8000 |
|
collection-name |
向量集合名称 |
自定义 |
|
dimensions |
向量维度 |
必须与 embedding 模型一致 |
|
temperature |
LLM 创造性 |
RAG 场景提议 0.2-0.4 |
2.4 Chroma 数据结构
Chroma 使用 Collection 来组织向量数据,无需手动创建表结构。
核心概念:
- Collection:类似于数据库中的表,存储一组相关的向量
- Document:包含文本内容、元数据和向量
- Metadata:键值对形式的附加信息,支持过滤查询
Spring AI 自动管理:
- 设置 initialize-schema: true 后,Spring AI 会自动创建 Collection
- 首次添加文档时,Chroma 会根据向量维度自动初始化
- 无需编写 SQL 或手动管理索引
四、RAG 核心服务实现
4.1 自定义 Embedding 模型(硅基流动)
为了实现更灵活的向量生成,我们直接调用硅基流动的 Embedding API:
package com.shun.springai.config;
import lombok.extern.slf4j.Slf4j;
import org.springframework.ai.embedding.AbstractEmbeddingModel;
import org.springframework.ai.embedding.Embedding;
import org.springframework.ai.embedding.EmbeddingRequest;
import org.springframework.ai.embedding.EmbeddingResponse;
import org.springframework.ai.document.Document;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Primary;
import org.springframework.http.HttpHeaders;
import org.springframework.http.MediaType;
import org.springframework.stereotype.Component;
import org.springframework.web.client.RestClient;
import java.util.List;
import java.util.Map;
import java.util.stream.Collectors;
@Slf4j
@Primary
@Component
public class SiliconFlowEmbeddingModel extends AbstractEmbeddingModel {
private final RestClient restClient;
private final String apiKey;
public SiliconFlowEmbeddingModel(@Value("${siliconflow.api.key}") String apiKey) {
this.apiKey = apiKey;
this.restClient = RestClient.builder()
.baseUrl("https://api.siliconflow.cn/v1")
.build();
}
@Override
public float[] embed(String text) {
log.debug("正在通过硅基流动生成向量: {}", text.substring(0, Math.min(20, text.length())));
Map<String, Object> requestBody = Map.of(
"model", "BAAI/bge-large-zh-v1.5",
"input", List.of(text),
"encoding_format", "float"
);
HttpHeaders headers = new HttpHeaders();
headers.setContentType(MediaType.APPLICATION_JSON);
headers.setBearerAuth(apiKey);
try {
Map<String, Object> response = restClient.post()
.uri("/embeddings")
.headers(h -> h.addAll(headers))
.body(requestBody)
.retrieve()
.body(Map.class);
if (response != null && response.containsKey("data")) {
List<Map<String, Object>> dataList = (List<Map<String, Object>>) response.get("data");
if (!dataList.isEmpty()) {
List<Double> vectorDoubles = (List<Double>) dataList.get(0).get("embedding");
float[] result = new float[vectorDoubles.size()];
for (int i = 0; i < vectorDoubles.size(); i++) {
result[i] = vectorDoubles.get(i).floatValue();
}
return result;
}
}
} catch (Exception e) {
log.error("调用硅基流动 Embedding API 失败", e);
throw new RuntimeException("向量生成失败", e);
}
return new float[1024];
}
@Override
public float[] embed(Document document) {
return embed(document.getText());
}
@Override
public EmbeddingResponse call(EmbeddingRequest request) {
List<Embedding> embeddings = request.getInstructions().stream()
.map(text -> new Embedding(embed(text), 0))
.collect(Collectors.toList());
return new EmbeddingResponse(embeddings);
}
}
优势:
- ✅ 完全控制向量化过程
- ✅ 可以选择任意支持的 Embedding 模型
- ✅ 避免默认配置的兼容性问题
4.2 RAG 问答服务
@Service
@Slf4j
public class ChromaRagService {
private final VectorStore vectorStore;
private final ChatClient chatClient;
public ChromaRagService(VectorStore vectorStore, ChatClient.Builder chatClientBuilder) {
this.vectorStore = vectorStore;
this.chatClient = chatClientBuilder.build();
}
/**
* 导入文档到 Chroma
*/
public void ingestDocuments(List<Document> documents) {
log.info("正在向 Chroma 导入 {} 个文档片段...", documents.size());
// Spring AI 会自动调用 SiliconFlowEmbeddingModel 来生成向量
vectorStore.add(documents);
log.info("文档导入成功!");
}
/**
* 执行 RAG 问答
*/
public String query(String question) {
log.info("收到问题: {}", question);
// 1. 类似度搜索 (Retrieval)
List<Document> similarDocs = vectorStore.similaritySearch(
SearchRequest.builder()
.query(question)
.topK(5)
.similarityThreshold(0.7)
.build()
);
if (similarDocs.isEmpty()) {
return "抱歉,我在知识库中没有找到相关信息。";
}
// 2. 组装上下文
String context = similarDocs.stream()
.map(Document::getText)
.collect(Collectors.joining("
"));
log.info("检索到 {} 个相关文档", similarDocs.size());
// 3. 构建 Prompt
String prompt = buildPrompt(question, context);
// 4. 调用 LLM 生成答案
String answer = chatClient.prompt()
.user(prompt)
.call()
.content();
log.info("回答生成完成");
return answer;
}
/**
* 构建 Prompt
*/
private String buildPrompt(String question, String context) {
return String.format("""
你是一个专业的智能问答助手。请基于以下上下文信息回答问题。
【上下文信息】
%s
【用户问题】
%s
【回答要求】
1. 严格基于上下文信息回答
2. 如果上下文中没有相关信息,请说"抱歉,我在知识库中没有找到相关信息"
3. 回答要准确、简洁、有条理
4. 可以引用上下文中的具体内容作为依据
5. 使用 Markdown 格式组织答案
请开始回答:
""", context, question);
}
}
4.3 高级检索技巧
curl -X 'POST'
'http://localhost:8080/api/rag/ingest'
-H 'accept: */*'
-H 'Content-Type: application/json'
-d '{
"content": "Spring AI是 Spring 官方推出的面向 Java 和 Spring 生态的原生人工智能应用开发框架,提供模型无关的抽象层,让开发者能以熟悉的 Spring 编程模型快速集成大语言模型、向量数据库、RAG 等 AI 能力 。官方项目页面可访问 spring.io/projects/spring-ai,阿里云扩展版本见 sca.aliyun.com 。核心特性与优势统一抽象接口:通过一套接口支持多种 AI 模型供应商,开发者可无缝切换 OpenAI、Anthropic、Bedrock、Hugging Face、Vertex AI、Ollama、DashScope 等主流服务,无需修改核心业务代码 。原生 Spring 生态集成:完全传承 Spring 设计哲学,支持依赖注入、POJO 编程、模块化架构与可配置性,无缝集成 Spring Boot、Spring Cloud、Spring Data 等组件 。高级功能支持:ChatClient API:提供流畅链式调用接口,简化对话交互开发。Function Calling:完整支持工具调用,与 Java 方法签名打通,通过@Tool 注解注册自定义函数。RAG 检索增强生成:内置向量数据库支持,提供 15+ 种主流向量库官方 Starter,支持文档拆分、嵌入、检索全流程。可观测性:集成 Micrometer Metrics + OpenTelemetry 全链路追踪,支持 Token 统计与日志记录。版本要求:Spring AI 2.0 需 Spring Boot 3.5+、Java 17+(推荐 Java 21)、Maven 3.9+ 或 Gradle 8+ ",
"source": "spring-ai",
"author": "架构源启",
"createTime": "2026-05-05 16:16:16",
"version":"1.0.0"
}'
元数据过滤
在实际应用中,我们往往需要限制搜索范围:
// 只搜索特定来源的文档
SearchRequest request = SearchRequest.builder()
.query(question)
.filterExpression("metadata.source == 'spring-ai'")
.topK(5)
.build();
List<Document> results = vectorStore.similaritySearch(request);
常用过滤表达式:
// 时间范围过滤
.filterExpression("metadata.createTime >= '2026-05-01'")
// 多条件组合
.filterExpression("metadata.author == '架构源启' AND metadata.source == 'spring-ai'")
// IN 查询
.filterExpression("metadata.source IN ['spring', 'ai', 'it']")
// 数值范围
.filterExpression("metadata.version >= 1.0.0")
混合搜索(Hybrid Search)
1. 为什么需要混合搜索?
在 RAG 系统中,单一的检索方式往往存在局限性:
- 纯向量搜索(Semantic Search):擅长理解语义和意图(例如知道“苹果”和“水果”有关联),但在处理专有名词、准确匹配或最新术语时容易“幻觉”或召回不相关内容。
- 纯关键词搜索(Keyword Search):擅长准确匹配(如产品型号、人名),但无法理解同义词或 paraphrasing(改述)。
混合搜索通过结合两者的优势,先通过向量搜索保证语义相关性,再通过关键词匹配进行重排序(Rerank),从而显著提升检索的召回率(Recall)和准确率(Precision)。
2. 工作原理:RRF 融合算法
在本项目中,我们采用了一种轻量级的混合策略:
- 向量召回:从 Chroma 中检索 Top-K(如 10 个)语义相关的文档片段。
- 关键词提取:从用户问题中提取核心关键词。
- RRF 重排序:使用 Reciprocal Rank Fusion (RRF) 算法计算综合得分。公式:Score = 1 / (60 + Vector_Rank) + Keyword_Match_CountVector_Rank:文档在向量搜索结果中的排名。Keyword_Match_Count:文档内容中包含关键词的次数。
3. 代码实现
/**
* 执行混合搜索 (Hybrid Search)
*/
public String hybridSearchQuery(String question, Map<String, String> metadataFilters) {
// 1. 向量类似度搜索 - 降低阈值以获取更多候选项
List<Document> vectorResults = performVectorSearch(question, metadataFilters, 10);
// 2. 关键词匹配重排序 (Keyword Re-ranking)
List<Document> rankedResults = rerankByKeywords(vectorResults, question);
// 3. 组装上下文并生成答案
String context = rankedResults.stream()
.map(doc -> String.format("[来源: %s]
%s",
doc.getMetadata().getOrDefault("source", "未知"), doc.getText()))
.collect(Collectors.joining("
---
"));
// ... 调用 LLM 生成答案
}
private List<Document> rerankByKeywords(List<Document> docs, String query) {
Set<String> keywords = extractKeywords(query);
Map<Document, Double> scores = new HashMap<>();
for (int i = 0; i < docs.size(); i++) {
Document doc = docs.get(i);
double vectorScore = 1.0 / (60 + i); // RRF 向量得分
double keywordScore = 0;
for (String keyword : keywords) {
if (doc.getText().toLowerCase().contains(keyword.toLowerCase())) {
keywordScore += 1.0;
}
}
scores.put(doc, vectorScore + keywordScore);
}
return scores.entrySet().stream()
.sorted(Map.Entry.<Document, Double>comparingByValue().reversed())
.limit(5)
.map(Map.Entry::getKey)
.collect(Collectors.toList());
}
4. API 调用示例
curl -X POST http://localhost:8080/api/rag/hybrid-query
-H "Content-Type: application/json"
-d '{
"question": "Spring AI 的核心特性有哪些?",
"filters": {
"source": "spring-ai"
}
}'
通过这种方式,即使向量搜索召回了一些语义相近但关键词不匹配的文档,混合搜索也能通过关键词权重将它们排在后面,确保最终给到 LLM 的上下文是最精准的。
4.5 REST API 控制器
提供文件上传接口,支持前端直接上传文档进行入库:
@RestController
@RequestMapping("/api/rag")
@RequiredArgsConstructor
public class ChromaRagController {
private final ChromaRagService ragService;
private final DocumentLoaderService documentLoaderService;
/**
* 文件上传并入库接口 (支持 PDF, Word, Markdown)
*/
@PostMapping("/upload")
public String uploadFile(@RequestParam("file") MultipartFile file,
@RequestParam(value = "category", required = false, defaultValue = "general") String category) {
Map<String, String> metadata = Map.of(
"category", category,
"uploadTime", java.time.LocalDateTime.now().toString()
);
return documentLoaderService.processAndIngestFile(file, metadata);
}
/**
* RAG 问答接口 (支持多条件元数据过滤)
*/
@PostMapping("/query")
public String query(@RequestBody Map<String, Object> request) {
String question = (String) request.get("question");
@SuppressWarnings("unchecked")
Map<String, String> filters = (Map<String, String>) request.get("filters");
return ragService.queryWithMetadataFilters(question, filters);
}
/**
* 混合搜索问答接口 (Hybrid Search)
*/
@PostMapping("/hybrid-query")
public String hybridQuery(@RequestBody Map<String, Object> request) {
String question = (String) request.get("question");
@SuppressWarnings("unchecked")
Map<String, String> filters = (Map<String, String>) request.get("filters");
return ragService.hybridSearchQuery(question, filters);
}
}
测试示例:
# 1. 上传 PDF 文件
curl -X POST http://localhost:8080/api/rag/upload
-F "file=@/path/to/spring-ai-guide.pdf"
-F "category=technical-docs"
# 2. 上传 Word 文档
curl -X POST http://localhost:8080/api/rag/upload
-F "file=@/path/to/report.docx"
-F "category=reports"
# 3. 查询问题
curl -X POST http://localhost:8080/api/rag/query
-H "Content-Type: application/json"
-d '{
"question": "什么是spring ai?",
"filters": {
"category": "technical-docs"
}
}'

4.3 多格式文档加载器(Document Loader)
Spring AI 提供了丰富的文档加载器,支持 PDF、Word、Markdown 等多种格式。
完整文档加载服务实现
package com.shun.springai.service;
import lombok.extern.slf4j.Slf4j;
import org.springframework.ai.document.Document;
import org.springframework.ai.reader.markdown.MarkdownDocumentReader;
import org.springframework.ai.reader.pdf.PagePdfDocumentReader;
import org.springframework.ai.reader.tika.TikaDocumentReader;
import org.springframework.ai.transformer.splitter.TokenTextSplitter;
import org.springframework.core.io.InputStreamResource;
import org.springframework.stereotype.Service;
import org.springframework.web.multipart.MultipartFile;
import java.util.ArrayList;
import java.util.List;
import java.util.Map;
@Slf4j
@Service
public class DocumentLoaderService {
private final ChromaRagService ragService;
private final TokenTextSplitter textSplitter;
public DocumentLoaderService(ChromaRagService ragService) {
this.ragService = ragService;
// 配置分块器:每块 500 tokens,重叠 50 tokens
this.textSplitter = new TokenTextSplitter(500, 50, 5, 1000, true);
}
/**
* 处理上传的文件并入库
*/
public String processAndIngestFile(MultipartFile file, Map<String, String> metadata) {
if (file.isEmpty()) {
return "文件为空";
}
String originalFilename = file.getOriginalFilename();
if (originalFilename == null) {
return "文件名无效";
}
log.info("开始处理文件: {}, 大小: {} bytes", originalFilename, file.getSize());
try {
List<Document> documents = new ArrayList<>();
String lowerCaseName = originalFilename.toLowerCase();
// 1. 根据文件类型选择加载器
if (lowerCaseName.endsWith(".pdf")) {
documents = loadPdf(file);
} else if (lowerCaseName.endsWith(".doc") || lowerCaseName.endsWith(".docx")) {
documents = loadWord(file);
} else if (lowerCaseName.endsWith(".md") || lowerCaseName.endsWith(".markdown")) {
documents = loadMarkdown(file);
} else {
return "不支持的文件格式: " + originalFilename;
}
// 2. 添加元数据
String sourceName = originalFilename;
for (Document doc : documents) {
doc.getMetadata().putAll(metadata);
doc.getMetadata().put("source", sourceName);
doc.getMetadata().put("type", getFileType(lowerCaseName));
}
// 3. 文本分块 (Splitting)
List<Document> splitDocuments = textSplitter.apply(documents);
log.info("文件 {} 被分割为 {} 个片段", originalFilename, splitDocuments.size());
// 4. 向量化入库 (Ingestion)
ragService.ingestDocuments(splitDocuments);
return String.format("文件 %s 处理成功!共导入 %d 个片段。", originalFilename, splitDocuments.size());
} catch (Exception e) {
log.error("处理文件失败", e);
return "处理失败: " + e.getMessage();
}
}
private List<Document> loadPdf(MultipartFile file) throws Exception {
PagePdfDocumentReader reader = new PagePdfDocumentReader(new InputStreamResource(file.getInputStream()));
return reader.read();
}
private List<Document> loadWord(MultipartFile file) throws Exception {
TikaDocumentReader reader = new TikaDocumentReader(new InputStreamResource(file.getInputStream()));
return reader.read();
}
private List<Document> loadMarkdown(MultipartFile file) throws Exception {
MarkdownDocumentReader reader = new MarkdownDocumentReader(new InputStreamResource(file.getInputStream()));
return reader.read();
}
private String getFileType(String filename) {
if (filename.endsWith(".pdf")) return "pdf";
if (filename.endsWith(".doc") || filename.endsWith(".docx")) return "word";
if (filename.endsWith(".md")) return "markdown";
return "unknown";
}
}
核心流程说明:
- 格式识别:根据文件扩展名自动选择合适的加载器
- 文档解析:使用 Spring AI 提供的 Reader 提取文本内容
- 元数据注入:为每个文档片段添加来源、类型等元信息
- 智能分块:通过 TokenTextSplitter 将长文档切分为语义完整的片段
- 向量化入库:调用 ChromaRagService 完成 Embedding 生成和 Chroma 存储
4.4 文档分割策略深度解析
为什么需要文档分割?
- 上下文窗口限制:LLM 只能处理有限长度(如 128K tokens)
- 检索精度:小片段更容易找到相关部分
- 成本控制:减少 token 使用量
- 提高相关性:避免无关内容干扰
分割策略对比
1. 固定字符分割
TextSplitter splitter = new CharacterTextSplitter(
500, // 每块 500 字符
50 // 重叠 50 字符
);
List<Document> chunks = splitter.apply(documents);
优点:简单快速
缺点:可能切断句子或段落
适用:对语义完整性要求不高的场景
2. Token 分割(推荐)
TextSplitter splitter = new TokenTextSplitter(
500, // 每块 500 tokens
50, // 重叠 50 tokens
true, // 保持段落完整
10000 // 最大 chunk 大小
);
List<Document> chunks = splitter.apply(documents);
优点:
- ✅ 思考语义完整性
- ✅ 与 LLM 的 token 计算一致
- ✅ 可配置段落保持
缺点:
- ❌ 需要 tokenizer,稍慢
- ❌ 不同模型的 tokenizer 不同
适用:大多数 RAG 场景(推荐默认选择)
3. 递归字符分割
TextSplitter splitter = RecursiveCharacterTextSplitter.builder()
.chunkSize(500)
.chunkOverlap(50)
.separators(List.of(
"
", // 段落分隔
"
", // 换行
"。", // 中文句号
"!", // 中文感叹号
"?", // 中文问号
",", // 中文逗号
" ", // 空格
"" // 字符
))
.keepSeparator(false)
.build();
List<Document> chunks = splitter.apply(documents);
优点:
- ✅ 智能识别自然边界
- ✅ 优先在段落处分割
- ✅ 支持多语言
缺点:
- ❌ 配置复杂
- ❌ 需要调优 separators
适用:长文档、结构化文档
4. 语义分割(高级)
使用 NLP 模型识别语义边界:
// 需要额外依赖:spring-ai-nlp
SemanticTextSplitter splitter = SemanticTextSplitter.builder()
.model("bert-base-chinese")
.chunkSize(500)
.threshold(0.8) // 语义类似度阈值
.build();
优点:最准确的语义分割
缺点:计算开销大
适用:高精度要求的场景
分割参数调优指南
|
参数 |
说明 |
推荐值 |
影响 |
|
chunkSize |
每块大小 |
300-800 tokens |
越大信息越完整,但检索精度降低 |
|
chunkOverlap |
重叠大小 |
chunkSize 的 10-20% |
保持上下文连贯性 |
|
keepSeparator |
保留分隔符 |
true |
保留标点符号 |
不同场景切块参数推荐表:
|
场景 |
块大小 (Tokens) |
重叠大小 (Tokens) |
推荐分割器 |
理由 |
|
普通文档 RAG |
700~1000 |
80~150 |
递归字符分割 |
平衡语义完整性与检索精度,适合大多数业务文档 |
|
技术文档 / 代码 |
500~800 |
50~100 |
代码专用分割 |
避免切断函数或类定义,保持逻辑块完整 |
|
客服 FAQ 短句 |
200~400 |
30~50 |
按句子分割 |
问答一般较短,小块能提高匹配精准度 |
|
长文章摘要 |
800~1200 |
100~200 |
段落分割 |
保持长文本的逻辑连贯,减少碎片化干扰 |
经验法则:
- 短问答/FAQ:chunkSize=300, overlap=30(追求高精准度)
- 中等长度文档:chunkSize=500, overlap=50(通用推荐配置)
- 长篇深度报告:chunkSize=800, overlap=80(追求信息完整性)
3.3 文档入库流程
完整的文档导入服务:
@Service
@Slf4j
public class DocumentIngestionService {
@Autowired
private VectorStore vectorStore;
@Autowired
private EmbeddingModel embeddingModel;
/**
* 导入单个 PDF 文件
*/
@Transactional
public IngestionResult ingestPdf(String filePath) {
long startTime = System.currentTimeMillis();
try {
// Step 1: 加载文档
log.info("Step 1: Loading PDF...");
List<Document> documents = pdfLoader.loadFromPath(filePath);
log.info("Loaded {} pages", documents.size());
// Step 2: 文档分割
log.info("Step 2: Splitting documents...");
TextSplitter splitter = new TokenTextSplitter(500, 50, true);
List<Document> chunks = splitter.apply(documents);
log.info("Split into {} chunks", chunks.size());
// Step 3: 添加元数据
log.info("Step 3: Adding metadata...");
chunks.forEach(chunk -> {
chunk.getMetadata().put("source", filePath);
chunk.getMetadata().put("ingestedAt", LocalDateTime.now().toString());
chunk.getMetadata().put("type", "pdf");
});
// Step 4: 生成 embeddings 并存储
log.info("Step 4: Generating embeddings and storing...");
vectorStore.add(chunks);
long duration = System.currentTimeMillis() - startTime;
IngestionResult result = new IngestionResult();
result.setSuccess(true);
result.setDocumentCount(documents.size());
result.setChunkCount(chunks.size());
result.setDurationMs(duration);
log.info("Ingestion completed: {} chunks in {}ms",
chunks.size(), duration);
return result;
} catch (Exception e) {
log.error("Document ingestion failed", e);
IngestionResult result = new IngestionResult();
result.setSuccess(false);
result.setErrorMessage(e.getMessage());
return result;
}
}
/**
* 批量导入目录下的所有 PDF
*/
@Transactional
public BatchIngestionResult ingestDirectory(String directoryPath) {
log.info("Starting batch ingestion from: {}", directoryPath);
File dir = new File(directoryPath);
if (!dir.exists() || !dir.isDirectory()) {
throw new IllegalArgumentException("无效目录: " + directoryPath);
}
File[] pdfFiles = dir.listFiles((d, name) -> name.endsWith(".pdf"));
if (pdfFiles == null || pdfFiles.length == 0) {
throw new IllegalArgumentException("目录下没有 PDF 文件");
}
log.info("Found {} PDF files", pdfFiles.length);
BatchIngestionResult batchResult = new BatchIngestionResult();
int successCount = 0;
int failCount = 0;
for (File pdfFile : pdfFiles) {
try {
IngestionResult result = ingestPdf(pdfFile.getAbsolutePath());
if (result.isSuccess()) {
successCount++;
batchResult.getTotalChunks().addAndGet(result.getChunkCount());
} else {
failCount++;
log.error("Failed to ingest: {}", pdfFile.getName());
}
} catch (Exception e) {
failCount++;
log.error("Error ingesting {}", pdfFile.getName(), e);
}
}
batchResult.setTotalFiles(pdfFiles.length);
batchResult.setSuccessCount(successCount);
batchResult.setFailCount(failCount);
log.info("Batch ingestion completed: {} success, {} fail",
successCount, failCount);
return batchResult;
}
/**
* 删除文档
*/
public void deleteDocumentsBySource(String source) {
log.info("Deleting documents from source: {}", source);
// 查询该来源的所有文档
List<Document> documents = vectorStore.similaritySearch(
SearchRequest.builder()
.query("*") // 通配符查询
.filterExpression("metadata.source == '" + source + "'")
.topK(10000)
.build()
);
// 删除
List<String> ids = documents.stream()
.map(doc -> doc.getId())
.collect(Collectors.toList());
vectorStore.delete(ids);
log.info("Deleted {} documents", ids.size());
}
}
结果类定义:
@Data
public class IngestionResult {
private boolean success;
private int documentCount;
private int chunkCount;
private long durationMs;
private String errorMessage;
}
@Data
public class BatchIngestionResult {
private int totalFiles;
private int successCount;
private int failCount;
private AtomicInteger totalChunks = new AtomicInteger(0);
}
---
## 五、Chroma 性能优化与最佳实践
### 5.1 Chroma 持久化配置
默认情况下,Docker 启动的 Chroma 数据存储在容器内部。为了生产环境使用,提议挂载卷:
```bash
docker run -d
--name chroma
-p 8000:8000
-v /path/to/data:/chroma/chroma
chromadb/chroma:latest
5.2 类似度阈值调优
// 提高阈值,只返回高度相关的文档
SearchRequest request = SearchRequest.builder()
.query(question)
.similarityThreshold(0.8) // 从 0.7 提高到 0.8
.topK(5)
.build();
阈值选择:
- 0.5-0.6:宽松,召回率高,但可能有噪声
- 0.7-0.8:平衡,推荐使用
- 0.9+:严格,准确率高,但可能漏掉相关信息
5.3 元数据过滤
在实际应用中,我们往往需要限制搜索范围:
// 只搜索特定来源的文档
SearchRequest request = SearchRequest.builder()
.query(question)
.filterExpression("metadata.source == 'hotel-manual'")
.topK(5)
.build();
List<Document> results = vectorStore.similaritySearch(request);
5.4 监控与维护
检查 Collection 状态:
curl http://localhost:8000/api/v1/collections/spring-ai-collection/count
清理无用数据:
// 删除指定来源的所有文档
List<Document> docs = vectorStore.similaritySearch(
SearchRequest.builder()
.query("*")
.filterExpression("metadata.source == 'old-docs'")
.topK(10000)
.build()
);
vectorStore.delete(docs.stream().map(Document::getId).collect(Collectors.toList()));
六、生产环境最佳实践
6.1 监控与告警
Micrometer 指标收集
@Component
public class RagMetrics {
private final MeterRegistry meterRegistry;
private final Timer queryTimer;
private final Counter queryCounter;
private final Counter errorCounter;
private final Gauge vectorStoreSize;
public RagMetrics(MeterRegistry meterRegistry, VectorStore vectorStore) {
this.meterRegistry = meterRegistry;
this.queryTimer = Timer.builder("rag.query.duration")
.description("RAG 查询耗时")
.tag("application", "hotel-assistant")
.register(meterRegistry);
this.queryCounter = Counter.builder("rag.queries.total")
.description("RAG 查询总数")
.register(meterRegistry);
this.errorCounter = Counter.builder("rag.errors.total")
.description("RAG 查询错误数")
.register(meterRegistry);
this.vectorStoreSize = Gauge.builder("rag.vectorstore.size",
() -> getVectorStoreSize(vectorStore))
.description("向量数据库大小")
.register(meterRegistry);
}
public void recordQuery(Duration duration, boolean success) {
queryTimer.record(duration);
queryCounter.increment();
if (!success) {
errorCounter.increment();
}
}
private double getVectorStoreSize(VectorStore vectorStore) {
// 实现获取向量数量的逻辑
return 0.0;
}
}
在查询服务中使用:
@Service
public class RagQueryService {
@Autowired
private RagMetrics metrics;
public RagResponse query(String question) {
long startTime = System.currentTimeMillis();
boolean success = false;
try {
RagResponse response = executeQuery(question);
success = true;
return response;
} finally {
long duration = System.currentTimeMillis() - startTime;
metrics.recordQuery(Duration.ofMillis(duration), success);
}
}
}
Prometheus 配置:
management:
endpoints:
web:
exposure:
include: prometheus,health,metrics
metrics:
export:
prometheus:
enabled: true
Grafana 看板关键指标:
- rag_query_duration_seconds:平均响应时间
- rag_queries_total:总查询量
- rag_errors_total:错误率
- rag_vectorstore_size:向量数据库大小
- http_requests_total:QPS
6.2 健康检查
@Component
public class RagHealthIndicator implements HealthIndicator {
@Autowired
private VectorStore vectorStore;
@Autowired
private DataSource dataSource;
@Override
public Health health() {
Map<String, Object> details = new HashMap<>();
try {
// 检查数据库连接
dataSource.getConnection().close();
details.put("database", "OK");
// 检查向量数据库
vectorStore.similaritySearch(
SearchRequest.query("health check").topK(1)
);
details.put("vectorStore", "OK");
return Health.up()
.withDetails(details)
.build();
} catch (Exception e) {
details.put("error", e.getMessage());
return Health.down(e)
.withDetails(details)
.build();
}
}
}
访问
http://localhost:8080/actuator/health 查看健康状态。
6.3 日志规范
logging:
level:
root: INFO
com.yourcompany.rag: DEBUG
org.springframework.ai: INFO
pattern:
console: "%d{yyyy-MM-dd HH:mm:ss} [%thread] %-5level %logger{36} - %msg%n"
file:
name: logs/rag-application.log
max-size: 100MB
max-history: 30
结构化日志示例:
log.info("RAG_QUERY_STARTED question={} userId={}",
sanitize(question), userId);
log.debug("RETRIEVED_DOCUMENTS count={} similarities={}",
docs.size(), similarities);
log.info("RAG_QUERY_COMPLETED question={} duration={}ms answer_length={}",
sanitize(question), duration, answer.length());
6.4 安全注意事项
Prompt 注入防护
@Component
public class PromptSecurityFilter {
/**
* 检测并阻止 Prompt 注入攻击
*/
public String sanitizeInput(String input) {
if (input == null) return "";
// 移除潜在的指令
input = input.replaceAll("(?i)(ignore previous|系统提示|忽略以上)", "");
// 限制长度
if (input.length() > 1000) {
input = input.substring(0, 1000);
}
return input.trim();
}
}
敏感信息脱敏
@Component
public class DataMasker {
public String maskSensitiveData(String text) {
// 隐藏手机号
text = text.replaceAll("\b1[3-9]\d{9}\b", "***");
// 隐藏身份证
text = text.replaceAll("\b\d{6}(19|20)\d{2}(0[1-9]|1[0-2])(0[1-9]|[12]\d|3[01])\d{3}[\dXx]\b", "***");
// 隐藏邮箱
text = text.replaceAll("\b[\w.-]+@[\w.-]+\.\w+\b", "***");
return text;
}
}
6.5 备份与恢复
对于 Chroma 数据库,备份超级简单,只需备份持久化目录即可:
#!/bin/bash
# backup_chroma.sh
BACKUP_DIR="/backups/chroma"
TIMESTAMP=$(date +%Y%m%d_%H%M%S)
CHROMA_DATA_PATH="/path/to/chroma/data" # 对应 Docker 挂载的卷路径
mkdir -p $BACKUP_DIR
# 压缩备份数据目录
tar -czf "$BACKUP_DIR/chroma_backup_$TIMESTAMP.tar.gz" -C "$(dirname $CHROMA_DATA_PATH)" "$(basename $CHROMA_DATA_PATH)"
# 删除 7 天前的备份
find $BACKUP_DIR -name "*.tar.gz" -mtime +7 -delete
echo "Chroma backup completed: $BACKUP_DIR/chroma_backup_$TIMESTAMP.tar.gz"
定时任务:
# 每天凌晨2点备份
0 2 * * * /path/to/backup_vector_db.sh
6.6 容量规划
存储需求估算:
每个向量占用空间 = 维度 × 4字节 + 元数据
例如:1536维向量 ≈ 6KB
100万向量 ≈ 6GB
1000万向量 ≈ 60GB
内存需求:
HNSW索引内存 ≈ 向量数据 × 1.5倍
100万向量 ≈ 9GB RAM
提议配置:
|
向量数量 |
CPU |
内存 |
存储 |
|
< 10万 |
2核 |
4GB |
50GB SSD |
|
10-100万 |
4核 |
8GB |
200GB SSD |
|
100-1000万 |
8核 |
16GB |
2TB SSD |
|
> 1000万 |
16核+ |
32GB+ |
分布式 |
七、总结
RAG 让 AI 能够访问最新的企业知识,是构建智能问答系统的核心技术。
关键要点回顾
✅ 向量数据库选型:Chroma 是快速原型开发和中小型 RAG 系统的理想选择
✅ 文档分割策略:Token 分割配合 10-20% 的重叠率能兼顾语义与精度
✅ 混合搜索技巧:向量召回 + 关键词重排序(RRF)是提升精准度的利器
✅ 缓存策略:Redis 缓存可将重复查询提速 200 倍
✅ 监控告警:实时监控确保系统稳定运行
✅ 安全防护:防止 Prompt 注入和数据泄露
祝你构建出强劲的 RAG 系统! ✨
关注账号,后续持续更新内容
- [第8篇] Spring AI 多模型路由 – 动态切换多个模型
- [第9篇] Spring AI 微服务架构 – 生产级架构设计
- [第10篇] Spring AI 完整项目实战 – 酒店智能助手从0到1
互动环节
有问题?
欢迎在评论区留言!
觉得有用?
- ⭐ 点赞支持
- 收藏备用
- 分享给朋友

© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











