如果你在会议上听到“LLM”“RAG”“Agentic”只能尴尬点头?那今天一次性让你搞懂所有核心概念,让你在AI浪潮中不再掉队。
AI的发展从未放慢脚步,2026年,人工智能已渗透到每个行业角落。从ChatGPT到Claude,从Gemini到DeepSeek,新概念层出不穷。面对纷繁复杂的术语,许多人会选择点头附和,假装自己听懂了。
今天,我为你梳理了15个构建现代AI知识体系的核心概念,从零开始,用最直白的方式,让你一次性掌握这个领域的90%。
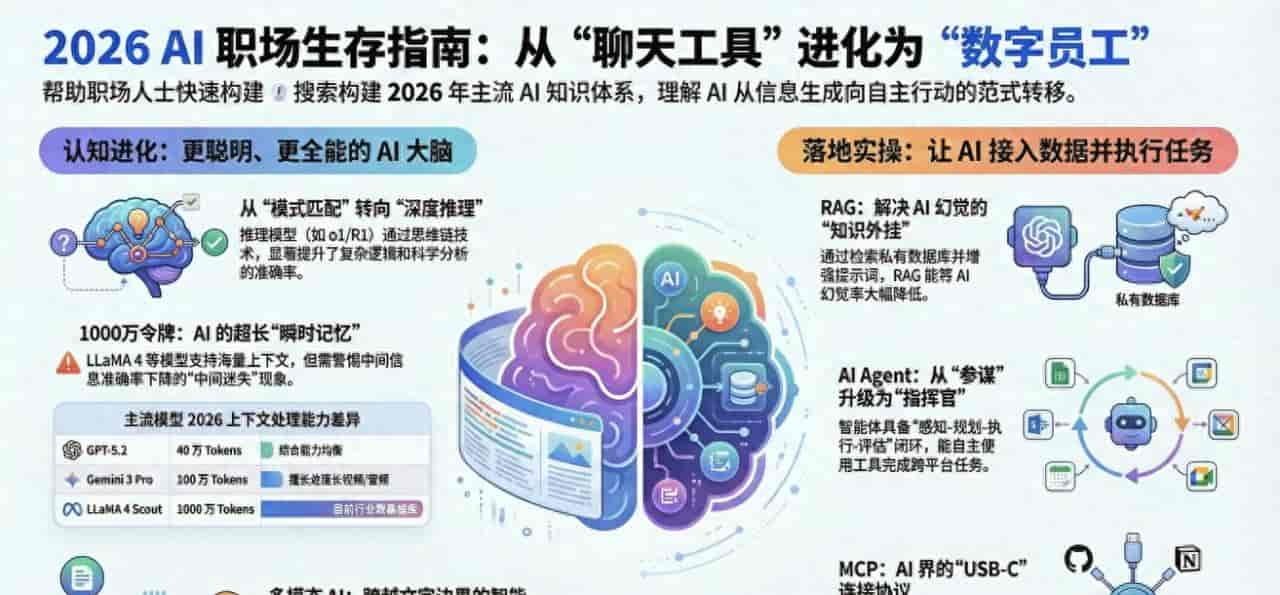
2026 AI 职场生存指南
文章有点长,提议收藏了慢慢看。
01 LLM(Large Language Model,大语言模型)
所有AI工具的幕后引擎
这是ChatGPT、Claude、Gemini和你最近接触的每个AI工具背后的动力源。
LLM在海量文本上训练——书籍、网站、代码、研究论文。它将一切分解成称为“令牌”的小块(大致相当于一个词),并学习预测下一个该出现什么令牌。
正是这种预测游戏,让它能够帮你写邮件、生成代码、总结报告,甚至回答你凌晨两点的古怪问题。
它不是思考,而是规模惊人的模式匹配。
主要玩家:
- OpenAI的GPT-5.2
- Anthropic的Claude Opus 4.6
- Google的Gemini 3 Pro
- Meta的LLaMA 4(开源)
- DeepSeek V3.2(训练成本仅为GPT-4的十分之一)
但有一点常被人误解:LLM不是搜索引擎。 Google能找到现有页面,而LLM基于学习到的模式生成全新文本。这很强劲,但也意味着它可能自信满满地胡编乱造。
02 模型上下文窗口(Context Window)
AI的单次对话工作记忆
想象一个窗口,里面装着模型在一次对话中能记住的所有内容——你的消息、它的回复、你粘贴的任何文档……全得塞进去。
一旦超出限制,最早的内容就会被无声无息地丢弃。你的指令就这样消失了。
当前规模:
- GPT-5.2:40万令牌
- Claude Opus 4.6:100万令牌
- Gemini 3 Pro:100万令牌
- LLaMA 4 Scout:1000万令牌(当前纪录)
20万令牌约等于15万词,相当于两到三本小说。
但窗口大不必定更好。 研究表明,模型对长输入中间部分的信息会丢失准确性。开头和结尾保持清晰,中间部分准确率下降30%以上。研究者称之为“中间迷失”问题。
03 推理(Inference)
AI真正为你工作的时刻
[ 输入 Tokens ]
↓
[ 预填充阶段 ]
↓
[ 解码阶段 ]
(token-by-token generation)
↓
[ 输出 Tokens ]训练是模型学习的过程,推理是它实际为你工作的时刻。
你发给AI工具的每条消息都是推理。模型读取你的输入(预填充阶段,速度很快),然后一个令牌一个令牌地生成输出(解码阶段,速度较慢)。
这就是为什么在API调用中,输出令牌的成本比输入令牌高3到5倍。读取便宜,写作昂贵。
推理有两种方式:
- 云端推理:运行在远程服务器上,更强劲,需要联网
- 设备端推理:运行在你的手机或笔记本上(如苹果智能、Gemini Nano),更快更私密,但限于较小模型
速度很关键。标准GPU每秒处理60到100个令牌,而Groq的定制芯片超过1600个——这就是长时间等待和即时回复的差距。
04 幻觉(Hallucination)
让你细思极恐的AI特性
(LLM)——思考-->“这听起来没错……”-->[虚假数据或故事]
(自信满满地说道)幻觉是指AI生成听起来完全真实但纯属虚构的内容。虚假统计、虚假法律案例、虚假研究引用,而且自信满满地呈现给你。
为什么会发生? 由于LLM不查证实际,它们预测最可能的下一个词。有时最“可能”的序列会导向毫无实际依据的地方。
最著名的案例:2023年,一位律师用ChatGPT准备法庭简报。它编造了六个虚假案例,包括虚构的法官和裁决。律师提交了这份简报,被罚款5000美元,成为国际新闻。
幻觉vs偏见:两者不同。 幻觉编造可验证的实际,偏见则基于训练数据模式产生有倾向性的输出。你需要不同方法来识别它们。
如何发现幻觉:
- 对你未提供的具体数字或引文保持怀疑
- 交叉核对任何影响真实决策的声称
- 留意在冷门话题上过于自信的语气
顶级模型在简单接地任务上幻觉率已低于1%,但在复杂推理上仍超过30%。
05 Prompt Engineering(提示工程)
写出更好AI指令的艺术
// 场景 1:基础“零样本”提示
[你] --> “写一篇关于人工智能的文章”
|
v
[LLM] --> [一篇通用、高层次、可能没什么实际用处的文章]
// 场景 2:精心设计的“少样本”或“思维导图”提示
[你] --> “你是一名科技记者。请为非技术型管理者撰写一篇 300 字的博客文章。解释‘人工智能代理’的概念。从类比入手。写作前,请一步一步地思考。”
|
v
[LLM] --> (内部思考:1. 代理的类比?个人助理。2. 定义。3. 举例。4. 撰写文章草稿。)
|
v
[一篇具体、目标明确、结构清晰的博客文章]这是编写更好AI指令的技能,它的威力远超多数人想象。
三种核心技术:
- 零样本(Zero-shot):直接提问,不给例子
- 少样本(Few-shot):提供2-3个你想要示例
- 思维链(Chain-of-Thought):要求它一步步思考再回答
糟糕提示和优秀提示之间的差距巨大。一个好提示词,比换模型更重大。
糟糕的:“写写营销”
优秀的:“你是B2B SaaS策略师。写一篇200字的LinkedIn帖子,宣布新AI功能。专业但温暖。结尾加上预约演示的行动号召。”
角色、受众、格式、长度、语气、约束——这些让输出真正可用。
与微调相比:提示成本为零,耗时几分钟;微调耗资数千,耗时数周。从提示开始,永远如此。
06 多模态 AI(Multimodal)
跨越文字边界的智能:文本 + 图片 + 音频 + 视频 一起处理。
[用户单次提示]
|
+--> [图片:一张半空冰箱的照片]
|
+--> [文本:“我可以用这些食材做什么健康晚餐?”]
|
v
(多模态人工智能大脑)
(处理视觉数据:“我看到了鸡蛋、菠菜和柠檬。”)
(处理文本数据:“用户想要一份健康晚餐食谱。”)
|
v
[生成输出:“你可以做一份健康的菠菜柠檬煎蛋卷。这里有一个简单的食谱……”]标准AI只能处理文字,多模态AI则能在同一对话中处理文字、图像、音频、视频和代码。
给它看你白板的照片,让它整理成结构化笔记。上传一段视频,获得一份摘要。发送错误截图,得到修复方案。这就是多模态。
代表模型:
- GPT-4o:文本、图像、音频、实时语音对话
- Gemini 3 Pro:单次提示处理长达2小时视频或19小时音频
- Claude 4.5 Sonnet:擅长从截图读取文档和代码
实际影响已显现。医疗模型结合医学影像和患者笔记,发现单一数据类型可能遗漏的问题。内容团队用文字指令生成和编辑图像。设计师在纸上画界面草图,AI将其转化为可工作代码。
07 推理模型(Reasoning Model)
会“思考”的AI
[复杂问题:“如果我的服务器每小时成本为 0.02 美元,并且第三季度流量增加了 30%,那么我的新季度成本是多少?”]
|
+--> (标准逻辑推理模型)-->【直接答案:“65.52 美元”】(可能正确,也可能错误。谁知道呢?)
|
+--> (推理模型)
|
v
[内心独白/“思维链”]
“步骤 1:计算一个季度的小时数。92 天 * 24 小时/天 = 2208 小时。”
“步骤 2:计算基本季度成本。2208 小时 * 0.02 美元/小时 = 44.16 美元。”
“步骤 3:计算增加的成本。44.16 美元 * 1.30 = 57.41 美元。”
“等等,不对。流量增长只针对第三季度……啊,题目问的是新的季度成本。我的计算是正确的。”
|
v
[最终答案:“第三季度新的季度成本为 57.41 美元。以下是我的计算方法……”]常规逻辑线性模型反应迅速。推理模型则会先停下来思考。
普通LLM回答很快,推理模型则会先停下来思考。
它们将问题分解成步骤,尝试不同方法,检查自己的工作,发现不合理就退回重来,然后给出最终答案。
可以这样理解:标准LLM脱口而出想到的第一件事,推理模型则展示思考过程。
- OpenAI o3:竞赛级数学准确率91.6%
- DeepSeek R1:通过纯强化学习推理,比o1便宜96%
- Claude扩展思维:可控制“思考预算”
- Gemini深度思考:在博士级科学问题上超越人类专家
代价是速度。o1需要近20秒才开始回应,而GPT-4o不到一秒。思考令牌按输出计费,成本增加3到10倍。
何时使用:复杂数学、多步编程、科学分析、战略规划。
何时跳过:简单查询、创意写作、实时聊天。用推理模型回答基础问题,就像雇博士回答常识题,既过度又昂贵。
08 代理型AI(Agentic AI)
从参谋到指挥官
[用户目标:“查找第三季度销售报告,进行总结,并将总结内容通过电子邮件发送给市场团队。”]
|
v
// 聊天机器人的回复:
[“要查找该报告,您应该查看公司共享云盘。然后,使用总结工具……”](告知您如何操作)
// 智能体 AI 的工作流程:
(1. 计划) -> (2. 使用工具:搜索云盘 API,查找“第三季度销售报告”)
|
v
(3. 找到文件。使用工具:读取文档) -> (4. 使用工具:LLM 总结器)
|
v
(5. 使用工具:电子邮件 API。收件人:marketing@...,主题:“第三季度销售总结”,正文:[总结内容]) -> (6. 报告完成)(自动完成)这是AI停止回答问题、开始采取行动的转折点。
代理型AI意味着系统能够规划任务、使用工具、执行多步骤工作流,并根据实际情况调整——几乎不需要你手把手指导。
聊天机器人等你的下一条消息,代理型系统则主动完成工作。
聊天机器人:“这是如何预订去东京的航班”
代理型AI:搜索航班、比较价格、预订最佳选项、添加到你的日历
真实案例:Anthropic的计算机使用功能让Claude查看你的屏幕并点击操作。CrewAI每天处理超过10万次代理执行。LangGraph将工作流构建为具有分支逻辑的图表。
它能自动化的任务:跨来源研究、数据录入、代码审查、支持分流、日程安排——任何步骤清晰的工作。
09 AI Agent(具体产品)
代理型AI的产品化身:Agent = 具备感知 → 计划 → 执行 → 评估循环的产品。
+-------------------------------------------------+
| |
| (开始) --> [感知环境] |
| ((例如:收到新邮件) |
| | |
| v |
| [计划后续步骤] |
| (例如:“目标:处理发票。 |
| 1. 打开邮件。2. 查找金额。3. 记录金额。”) |
| | |
| v |
| [使用工具操作] |
| (例如:点击“打开”,运行代码查找“$”) |
| | |
| v |
| [[评估结果] <--------------------------------+
| (例如:“成功!金额已记录。”) |
| (例如:“失败。未找到金额。制定新计划……”) |
| | |
+-------------------------------------------------+AI代理是基于代理原则构建的具体产品。它遵循一个循环:
感知→规划→行动→评估→(回到感知)
感知:获取信息(文本、截图、API数据)
规划:将目标分解为子任务
行动:执行任务(点击按钮、写代码、发送消息)
评估:检查是否成功,然后循环
“代理型AI”和“AI代理”的区别,就像“电动车技术”和“特斯拉”的关系——一个是范式,一个是产品。
当前主要代理:
- Devin:AI软件工程师,67%拉取请求合并率,已部署在高盛
- OpenAI Operator:通过截图和点击浏览网站
- Salesforce Agentforce:自动化70%的一级支持查询
- Manus:通用代理,被Meta以约20亿美元收购
区别:
- Agentic 是范式
- Agent 是产品
风险不同:代理执行真实行动,影响真实系统和真实资金。
市场在2025年已达76亿美元,79%组织正在尝试,但仅11%投入生产。仍处早期。
10 RAG(Retrieval-Augmented Generation 检索增强生成)
可能是当下最重大的AI模式
// 步骤 1:检索
[您的问题:“我们第四季度的收入是多少?”]
|
v
[搜索您的私有公司报告向量数据库]
|
v
[找到相关文本片段:“2025 年第四季度,总收入达到 420 万美元……”]
// 步骤 2:增强
[系统为 LLM 构建一个新的隐藏提示]
“上下文:‘2025 年第四季度,总收入达到 420 万美元……’
基于此上下文,回答用户的问题:我们第四季度的收入是多少?”
// 步骤 3:生成
|
v
(LLM 仅根据提供的上下文生成答案)
|
v
[最终答案:“我们第四季度的收入为 420 万美元。[引用:Q4_report.pdf]”]说实话,这可能是目前人工智能领域最重大的模式
LLM只知道训练时学到的内容,看不到你的公司文档或昨天的报告。RAG解决了这个问题。
三步流程:
- 检索:搜索与问题相关的知识库文档
- 增强(插入上下文):将这些文档连同查询一起插入提示
- 生成:模型基于真实上下文回答
代表产品:
- Perplexity就是RAG产品,每条回答都引用来源。
- Google NotebookLM只从你上传的文档中回答,不涉及外部知识。
RAG vs 微调:
- RAG:数据频繁变化、需要引文、要求接地时最佳
- 微调:需要深度领域专业、一致风格、永久行为时最佳
RAG将幻觉减少40%到71%。一项医学研究将RAG与精选数据结合,达到了0%幻觉率。
局限: 如果检索抓错文档,答案依旧错误。你的检索质量决定了你的上限。
11 向量数据库(Vector Database)
RAG真正工作的基石
向量数据库将内容存储为称为“嵌入”的数值表明,这些表明捕捉的是意义,而不仅是关键词。
传统数据库:搜索“狗”只能找到“狗”这个词。
向量数据库:搜索“狗”还能找到“小狗”和“金毛”,由于它们在嵌入空间中数学上接近。
这就是语义搜索——意义优于准确匹配。
主要玩家:
- Pinecone:完全托管,快速,微软和Shopify使用
- Weaviate:开源,内置RAG流程
- Chroma:轻量级,适合原型开发
- Qdrant:Rust编写,过滤能力强
这些也驱动着代理的记忆。当代理需要回忆过去行动时,它会查询向量数据库寻找最相关的片段。
挑战:嵌入在压缩过程中会丢失细微差别。随着源数据变化保持其新鲜度是持续难题。
但如果你的AI应用需要搜索或记住当前提示之外的任何内容,你需要向量数据库。
12 微调(Fine-Tuning)
让模型变成“专家”
// Before:
[Generalist LLM Brain]
(略懂一些:历史、编程、科学、法律……)
|
+--- [您的自定义数据集] ---+
| (来自贵公司的 500 个法律问题 |
| 示例以及专家 |
| 解答) |
+-----------------------------+
|
v
// After:
[Fine-Tuned Specialist LLM Brain]
(Neural pathways for "legal analysis" are now much stronger. General knowledge is still there, but it excels at its specialized task.)微调是拿预训练模型,用你的特定数据进一步训练它。基础模型是机智的通才,微调将其变成你的专家。
你向它输入你想要的输入输出示例,模型调整其权重以匹配这些模式——永久性的改变。
真实案例:
- 在临床数据上微调的医疗模型,执照考试得分85%
- Harvey AI在合同语言上训练,用于法律文档审阅
- 公司训练模型以其准确品牌风格写作
对比:
- 提示工程:免费,耗时数小时,应对大多数用例
- RAG:每月70到1000美元,实时知识最佳
- 微调:数千美元加数周,深度专业最佳
得益于LoRA(只训练1%的参数),你可以在单个消费级GPU上微调70亿参数的模型。2023年耗资10万美元的操作,如今在游戏电脑上就能完成。
风险: 过拟合(记忆示例而非学习)、灾难性遗忘(擅长特定任务但失去通用能力)、不良数据污染一切。
只在提示和RAG不够用时思考微调。
13 蒸馏(Distillation)
大模型教小模型,将庞然大物塞进口袋
// 步骤 1:教师模型
[庞大、缓慢、昂贵的前沿模型]
|
v
(生成海量、高质量的提示和完美答案数据集,包括其推理背后的微妙概率)
// 步骤 2:学生模型
[小型、快速、廉价的学生模型]
|
v
(完全基于教师模型的输出进行训练,学习模仿其模式和“思维过程”,但规模仅为教师模型的几分之一)
|
v
[精简模型:可在手机上运行,针对特定任务,其性能达到教师模型的 97%]蒸馏技术将庞大的模型压缩成更小、更快的模型,同时保留大部分功能。
蒸馏将庞大模型压缩成更小、更快的版本,同时保留大部分能力。
师生设置:
- 大“老师”模型生成海量高质量响应数据集
- 小“学生”模型在这些输出上训练
- 学生学习老师的模式,体积却小得多
学生不仅学习正确答案,还学习这些答案背后的概率模式——哪些错误答案“更错”。研究者称之为“暗知识”。
这与微调不同(微调是为领域调整模型,而非压缩),与量化也不同(量化降低数值精度,但不改变模型知识)。
DeepSeek R1将其6710亿参数模型蒸馏到小至15亿参数的版本。在数学和编程上,70亿参数版本几乎达到4到5倍大小模型的水平。
例子:
- DistilBERT:体积小40%,速度快60%,能力保留97%
- Gemini Nano:运行在Pixel手机上
- Phi-3 Mini:38亿参数,运行在移动端
目标:
- 更快
- 更便宜
- 可在手机运行
损失: 复杂推理受影响最大,安全对齐可能减弱。
但在手机运行AI、降低成本、将模型放入全尺寸版本无法到达的地方时,蒸馏是王道。
14 MCP(Model Context Protocol 模型上下文协议)
AI的通用连接器,
MCP正成为AI界的USB-C。
由Anthropic于2024年11月创建,源于开发者对在Claude和IDE之间复制代码的挫败感。MCP是一个开放标准,为AI模型提供连接外部工具和数据的统一方式。
MCP之前: 5个AI模型连接5个工具,需要25个独立定制集成——每个组合都是独立项目。
MCP之后:
- 每个工具构建一个服务器
- 每个AI模型构建一个客户端
- 它们自动协同工作
采用速度惊人。OpenAI于2025年3月添加支持,Google在4月跟进。到2025年底,生态系统已有5800多个服务器。2025年12月,Anthropic将MCP捐赠给Linux基金会,现已成为开放行业标准。
真实案例:
- Claude连接GitHub创建拉取请求
- AI读写Notion页面
- 模型直接查询你的数据库
对开发者来说意义重大:一个集成标准,无需为每个模型和工具定制连接器。
安全是主要关切,43%被分析的服务器存在漏洞。规范仍在快速演进中。
15 AI Guardrails(AI 安全护栏)
控制AI的边界系统
护栏是控制AI能做什么、不能做什么的安全系统。
它们分层工作:
- 输入过滤器:在模型看到之前捕获有害提示
- 输出过滤器:在你看到之前扫描生成内容
- 内容分类器:标记越狱尝试、有毒内容、数据泄露
- RLHF:基于人类反馈训练模型偏好安全输出
- 宪法式AI:Anthropic的方法,模型根据一组原则自我评判
工作方式:分层防御
输入 → [门卫 1:输入过滤]
(挡有害提示) → X
↓ (提示 OK)
[LLM 大脑生成回复]
↓
输出 → [门卫 2:Constitutional AI 检查]
(自我纠正) → (修订输出)
↓ (回复 OK)
[门卫 3:输出过滤/分类器]
(标记有毒内容、PII) → X
↓ (安全合规)
[最终回复送达用户]谁在构建?模型公司本身(OpenAI、Anthropic、Google)加上第三方工具如NVIDIA NeMo护栏和Amazon Bedrock护栏。
Anthropic的宪法式分类器将成功越狱从86%降至4.4%——相当令人印象深刻。
但护栏并非坚不可摧。平均而言,突破一个需要约42秒和5次尝试。
当它们失效时,真正的伤害随之而来。AI生成的错误信息激增。欧盟AI法案目前对违规者处以高达全球收入7%的罚款。
审查之争真实存在。研究敏感话题的学者称AI直接拒绝参与。日益壮大的“无审查AI”运动反击。其他人指出有记录的危害,认为限制还远远不够。双方都有道理。
业界已达成“深度防御”——多层重叠替代单一魔法过滤器。输入筛选加上宪法式AI加上输出审核加上人工审查加上持续红队测试。
87%的企业仍缺乏全面的AI安全框架——今年必须改变。
结语
这15个术语如同积木般相互连接,哪15 个术语如何拼成一张地图?
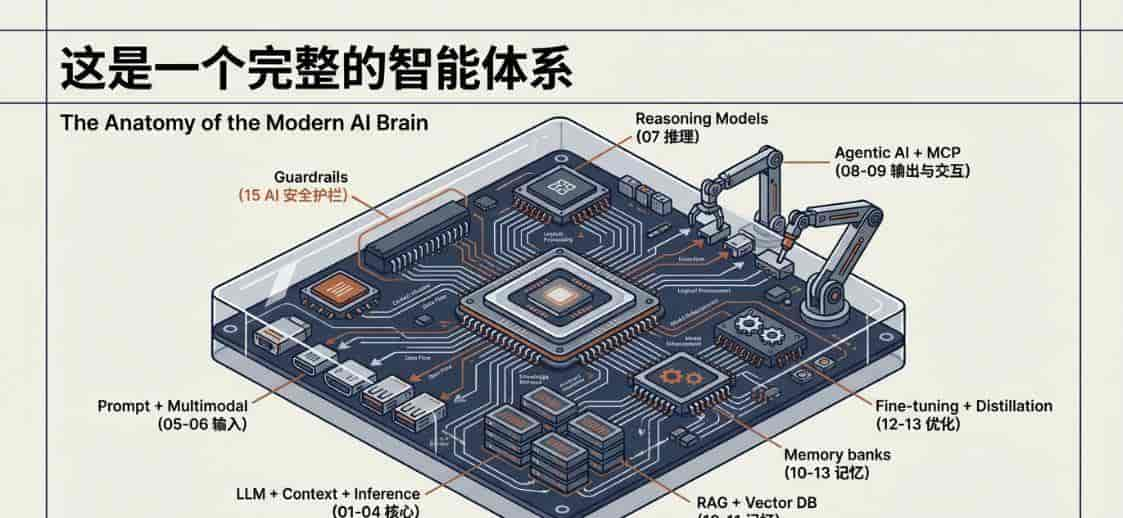
这是一个完整的体系
LLM 是基础
Context & Inference 决定能力,可能性边界
Prompt 提升输出质量
RAG + 向量数据库连接你的数据,用你的数据定制AI
Fine-tuning + 蒸馏打造专用模型
MCP 连接工具,连接一切
Agent 执行任务,让AI真正工作
Guardrails 确保安全可控
这是一整套体系。
掌握这些概念,你不仅能听懂会议讨论,还能在AI浪潮中找到自己的方向。不要只是阅读。分享这篇文章。讨论这些概念。在你的工作中应用它们。
由于在接下来的 12 个月里,掌握 AI 语言的人将塑造他们的行业。
你会是其中之一吗?
#ai##ai学习##让AI触手可及##ai编程##程序员#
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











