
我们来一起探讨“提示词”、“提示词工程”和“上下文工程”这三个既相关又容易混淆的概念。
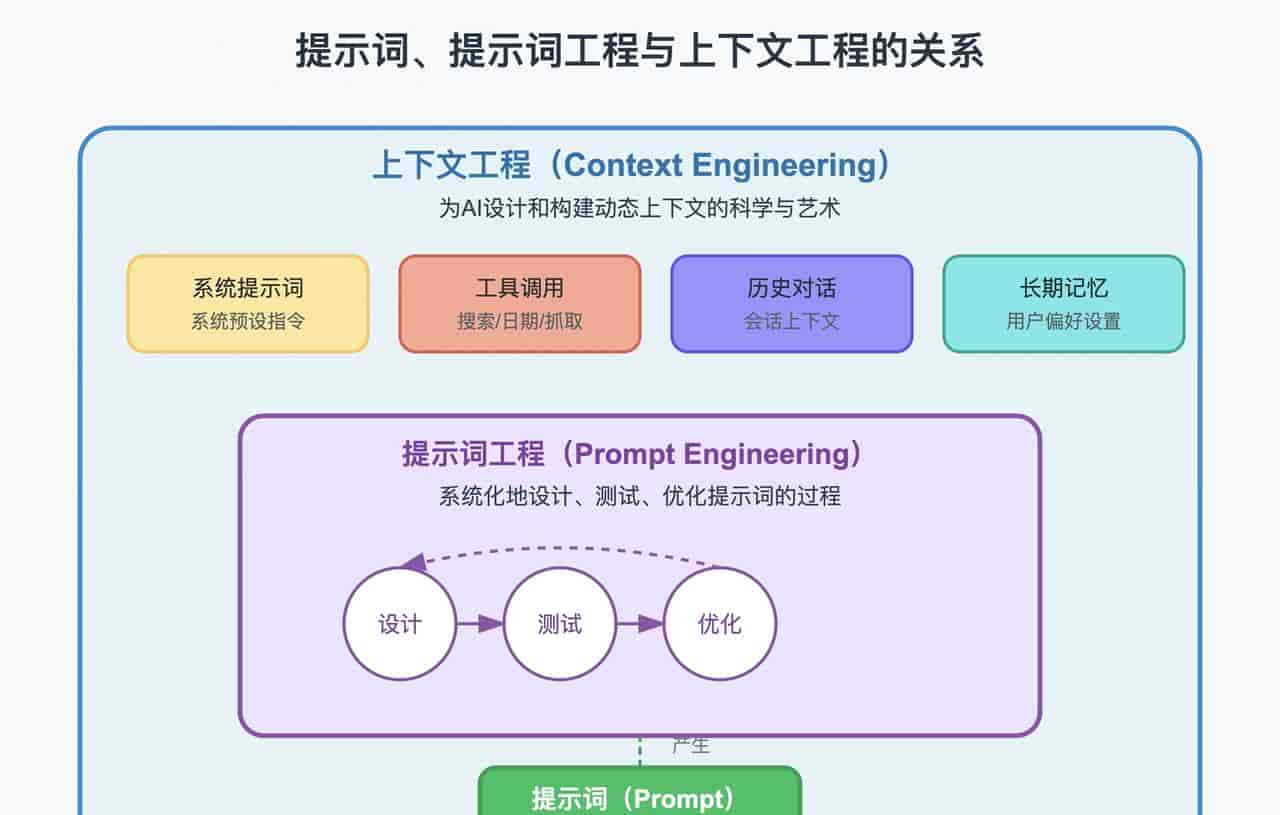
一文看懂“提示词” vs “提示词工程” vs “上下文工程”
许多人分不清楚什么是“提示词”(Prompt),什么是“提示词工程”(Prompt Engineering),目前又多了一个概念叫“上下文工程”(Context Engineering),它和“提示词工程”又有什么区别?

1. 什么是提示词(Prompt)?
提示词是这三个概念中最基础、最直接的。它就是你发送给 AI 模型的具体指令或问题。
你可以把提示词想象成一行行的代码,是你与 AI 沟通的语言。无论是让 ChatGPT 总结一段文本,还是在程序中调用模型的 API 翻译一篇文章,你输入的那段指令文本,就是提示词。
例子:
“请把下面的英文内容翻译为中文:”
这是一个简单直接的提示词。
2. 什么是提示词工程(Prompt Engineering)?
如果说提示词是“代码”,那么提示词工程就是“软件工程”。它不是一次性的指令,而是一个系统化地设计、测试、迭代和优化提示词的完整过程。
就像软件工程需要遵循科学方法论(如灵敏开发)、使用工具、保证质量、持续迭代一样,提示词工程的目标也是为了交付高质量的“代码”——也就是高效、稳定的提示词。
举个例子:
我们想得到一个高质量的翻译提示词。
- 初始版本 (V1):
- “请把下面的英文内容翻译为中文:”
- 结果:能翻译,但效果平平。
- 加入角色扮演 (V2):
- “你是一位专业的翻译专家,请把下面的英文内容翻译为中文。”
- 结果:效果有所提升,但翻译腔依然存在。
- 引入思维链 (Chain-of-Thought, CoT) (V3):
- “你是一位专业的翻译专家,请遵循以下步骤,将英文内容翻译为中文:
- 直译:先逐字逐句地直译原文。
- 意译:在直译的基础上,结合语境和中文表达习惯,进行意译,使其更自然流畅。”
- 结果:翻译质量显著提高。为了验证这点,你找了10篇文章,分别用 V2 和 V3 提示词进行测试,并邀请多人盲评。结果显示,绝大多数人认为 V3 的效果更好。这证明了 CoT 在这个场景下的有效性。
- 持续迭代与权衡 (V4):
- 受到鼓舞,你尝试增加更多步骤,列如“评估直译质量”、“润色意译稿”等。你发现虽然在测试集上效果略有提升,但 Token 消耗剧增,响应时间变长,甚至偶尔会偏离原意。你意识到,CoT 并非步骤越多越好,需要权衡成本与效益。
- 适应新模型 (V5):
- 更新、更强的模型发布了,它本身就具备了强劲的推理和语言能力。你发现,原来繁琐的步骤已不再必要。经过再次测试,你将提示词简化为:
- “你是一位专业的翻译专家,请用自然流畅的中文重写以下英文内容,保留其核心信息和风格。”
- 结果:效果同样出色,且效率更高。
整个对翻译提示词进行“设计 → 测试 → 优化 → 迭代”的循环,就是提示词工程。 它的最终产出是一系列经过验证、不断演进的高质量提示词版本。
精炼总结:提示词工程是系统化产出高质量提示词的过程。
3. 什么是上下文工程(Context Engineering)?
要理解上下文工程,第一要清楚什么是上下文(Context)。
上下文远不止是用户输入的那一句提示词。它是模型在生成回答之前所能看到的一切信息的总和。这包括:
- 系统级指令 (System Prompt): 对模型角色的预设,如“你是一个有用的助手”。
- 用户当前输入 (User Input): 用户提出的最新问题。
- 可用工具 (Tools): 模型可以调用的外部工具,如搜索、计算器、代码执行器。
- 长期记忆 (Long-term Memory): 关于用户的个性化信息,如“用户偏好使用中文”。
- 对话历史 (Conversation History): 当前会话中的所有过往消息。
- 工具返回信息 (Tool Outputs): 调用工具后返回的数据。
上下文窗口的大小是有限的,过长的上下文会影响模型性能并增加成本。因此,如何高效、动态地管理上下文至关重大——既要包含所有必要信息,又要剔除无关内容,控制其体积。
上下文工程正是在 AI Agent(智能体)崛起的背景下诞生的。当 AI 需要自主决策、调用工具来完成复杂任务时,单纯优化提示词已远远不够。
举个例子:
你问 ChatGPT:“今天都有什么重大的 AI 新闻?”
- 初始上下文: 模型只知道你的问题、它的系统角色和可用的工具。这些信息不足以回答。
- 动态构建上下文: AI Agent 启动。
- 决策1: “我需要知道今天的日期。” → 调用日期工具。
- 工具返回: 2025-07-01
- 决策2: “我需要用今天的日期去搜索 AI 新闻。” → 调用搜索工具。
- 工具返回:
- Hollywood Confronts AI Copyright Chaos…
- Mark Zuckerberg Announces New Meta ‘Superintelligence Labs’…
- 最终上下文: 目前,模型的上下文中包含了所有必要信息:你的问题、它的角色、工具、记忆,以及通过调用工具获取到的日期和新闻标题。
- 生成回答: 基于这个完整的上下文,模型生成了你看到的答案。
如果用户追问:“帮我看看第二条新闻的详情。” AI Agent 会再次启动,从历史会话中定位“第二条新闻”,调用网页抓取工具获取内容,并最终生成回答。
这个为 AI 动态地识别信息缺口、自主调用工具、组织并填充上下文的过程,就是上下文工程的核心。 它为 AI Agent 设计了完成任务所需的信息环境和工具箱。
正如 AI 领域的思想家 Andrej Karpathy所言:
“上下文工程”是一门精妙的科学与艺术:你要精准地将任务描述、少量样例、检索信息(RAG)、工具、状态历史等巧妙组合,填充到模型的上下文窗口中,引导它准确地迈出下一步。
这像烹饪一道精致菜肴:配料太少,模型信息不足;配料太多或无关,则会增加成本、降低表现。这不仅需要专业技巧,更需要一种洞察 LLM 与人类互动的直觉。
精炼总结:上下文工程是为大语言模型设计和构建动态上下文,以协助其高效完成复杂任务的科学与艺术。
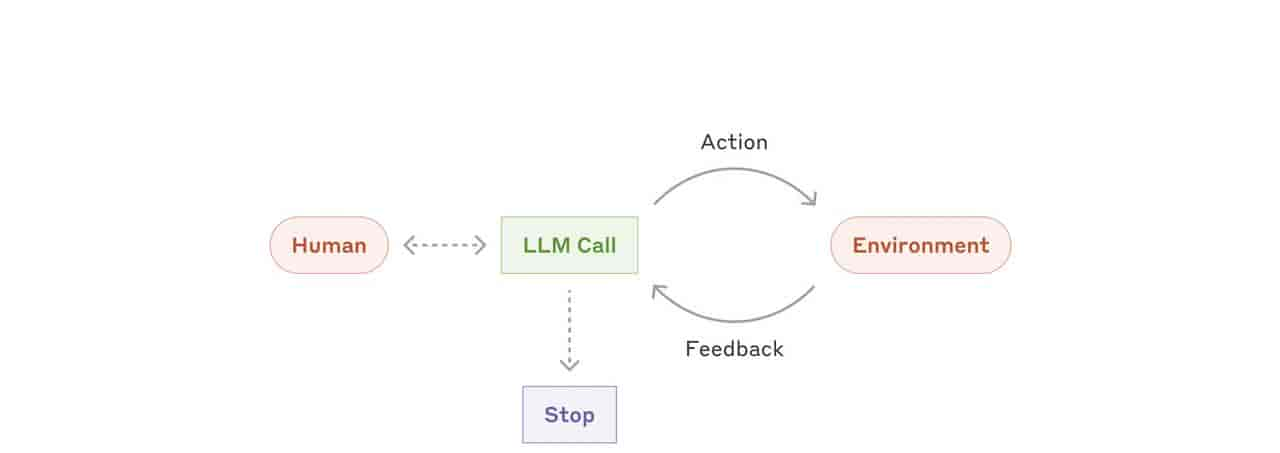
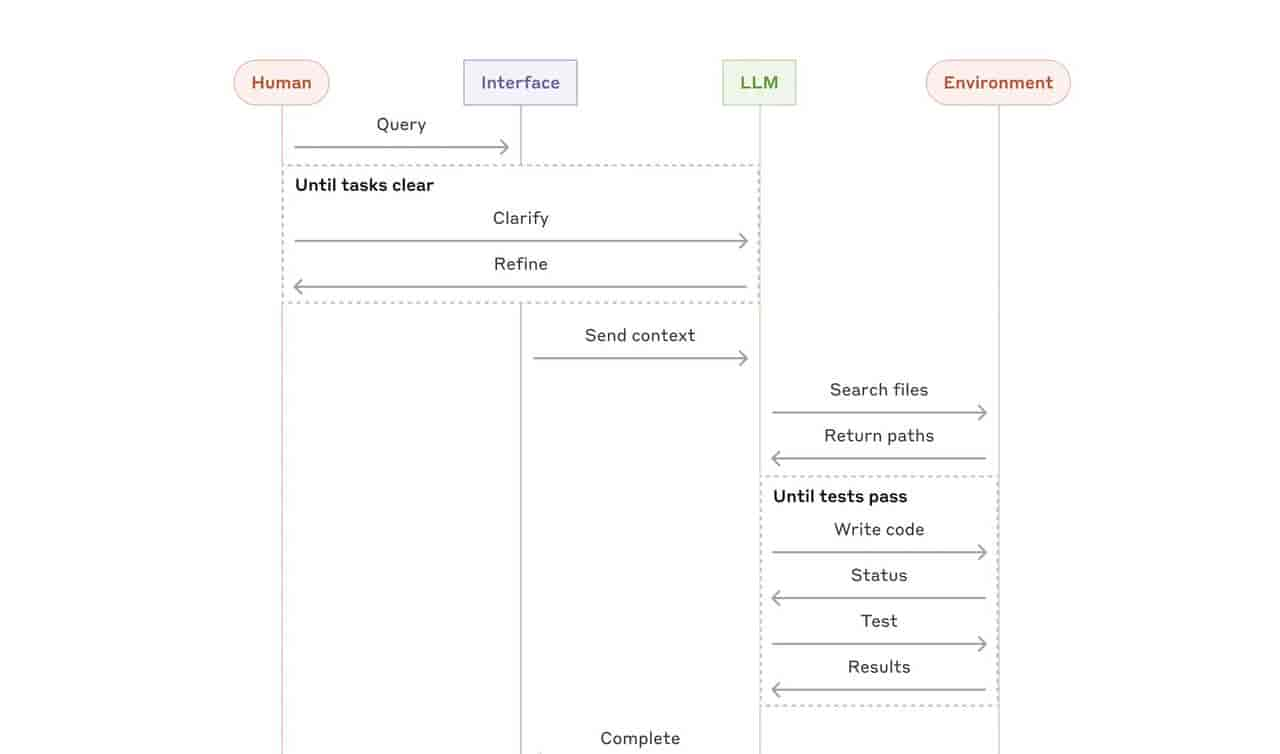
最后的总结
- 提示词 (Prompt): 发送给 AI 的指令文本。
- 提示词工程 (Prompt Engineering): 系统化地产出高质量提示词的过程。
- 上下文工程 (Context Engineering): 为 AI 设计和构建完成任务所需动态上下文的科学与艺术。
对于普通用户来说,能写好提示词就足够了。当你需要为应用开发稳定、高效的AI功能时,就需要进行提示词工程。而当你致力于构建能够自主规划和行动的 AI Agent 时,你就踏入了上下文工程的领域。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章
![JS面试题:[1, 2, 3].map(parseInt)](https://www.dunling.com/img/2.jpg)












[db:评论]