
Python Async OpenAI 流式编程
在大语言模型(LLM)应用爆发的今天,用户体验就是一切。想象一下,用户问了一个复杂问题,你的应用却卡住了 10 秒,最后才一次性“蹦”出大段文字。这种体验是很糟糕的。
用户希望感受到“即时反馈”,希望看到 AI 像打字机一样,一个字一个字地把想法呈现出来。这就是 Streaming(流式传输) 的魔力。
而为了让这种体验更加极致,我们需要 Python 的并发利器 —— asyncio。它能确保你的程序在等待 AI 生成下一个字的时候,还能腾出手来响应其他用户的操作,而不是傻傻地阻塞在那里。
今天这篇指南,我们将结合现代化的 Python 工具链,手把手带你掌握 Asyncio + OpenAI Streaming 的核心开发技巧。打造一个丝般顺滑的 AI 对话应用。
1. 核心概念速览
在动代码之前,我们先扫清两个关键概念:
1.1 Python 的 Asyncio (异步 I/O)
传统的 Python 代码是同步的(Blocking),就像排队在窗口办事,一个人没办完,后面的人都得等着。
asyncio 是 Python 处理并发的标准库。它允许你的程序在遇到耗时操作(列如等待网络请求返回)时,暂时“挂起”当前任务,去执行其他任务,等数据回来了再接着处理。
在 OpenAI 开发中,我们只需记住三个关键词:
- async def: 定义一个异步函数(协程)。
- await: 告知程序:“这里可能会卡住,你先去忙别的,好了叫我”。
- async for: 专门用于遍历那种“陆陆续续到达”的数据流。
1.2 OpenAI Streaming 原理
普通 API 请求是“全量返回”:你点菜,厨师做好全部菜品,一次性端上来。 Streaming 模式是基于 SSE (Server-Sent Events):你点菜,厨师做好一道菜就立刻端上来一道,源源不断,直到上完。
结合点:我们需要使用 OpenAI 的异步客户端发起一个流式请求,然后用一个异步循环 (async for) 去“接住”服务器抛过来的一个个数据包(Chunk)。
️ 2. 现代化环境初始化:使用 uv

基于uv的python虚拟开发环境
告别繁琐的 venv 和慢吞吞的 pip,我们将使用 Python 界的新宠 —— uv 来极速管理我们的项目环境。
2.1 安装 uv (如果还没安装)
# macOS / Linux
curl -LsSf https://astral.sh/uv/install.sh | sh
# Windows (PowerShell)
powershell -c "irm https://astral.sh/uv/install.ps1 | iex"
2.2 初始化项目
在终端执行以下命令,创建一个新项目并进入目录:
uv init async-streaming-demo
cd async-streaming-demo2.3 添加依赖
我们需要 openai 官方库,以及用于方便加载环境变量的 python-dotenv。
# uv 会自动创建虚拟环境并飞速安装依赖
uv add openai python-dotenv
注:asyncio 和 os 是 Python 标准库,无需安装。
⚙️ 3. 灵活的配置:环境变量与客户端初始化

OpenAI兼容的模型服务
在实际开发中,为了安全和灵活性(列如切换到 Azure OpenAI、DeepSeek 或本地的 Ollama 等兼容服务),我们绝不能把 API Key 和地址硬编码在代码里。
我们将遵循最佳实践,通过环境变量来配置客户端。我们需要以下三个变量:
- OPENAPI_ENDPOINT: API 的基础地址(Base URL)。
- OPENAPI_API_KEY: 你的 API 密钥。
- OPENAPI_MODEL: 你想调用的模型名称。
3.1 创建配置文件 .env
在项目根目录下创建一个名为 .env 的文件,填入你的实际配置。
示例 1:使用官方 OpenAI(绝大多数国内模型服务都OpenAI兼容)
OPENAPI_ENDPOINT="https://api.openai.com/v1"
OPENAPI_API_KEY="sk-你的OpenAI密钥"
OPENAPI_MODEL="gpt-3.5-turbo"示例 2:使用本地 Ollama (举例)
OPENAPI_ENDPOINT="http://localhost:11434/v1"
OPENAPI_API_KEY="ollama" # 本地服务一般随意填一个非空值即可
OPENAPI_MODEL="llama3"3.2 代码中的初始化
在代码中,我们会使用 dotenv 加载这些变量,并初始化 AsyncOpenAI 客户端。注意要使用 AsyncOpenAI 而不是同步的 OpenAI。
Python
# (代码片段,完整代码在最后)
import os
from dotenv import load_dotenv
from openai import AsyncOpenAI
# 加载 .env 文件
load_dotenv()
# 初始化异步客户端,传入自定义的 endpoint 和 key
client = AsyncOpenAI(
api_key=os.getenv("OPENAPI_API_KEY"),
base_url=os.getenv("OPENAPI_ENDPOINT")
)
# 获取模型名称
target_model = os.getenv("OPENAPI_MODEL")
4. 解构 Streaming Message
当你设置 stream=True 后,API 返回的不再是一个巨大的 JSON,而是一系列微小的 Chunk(数据块)。
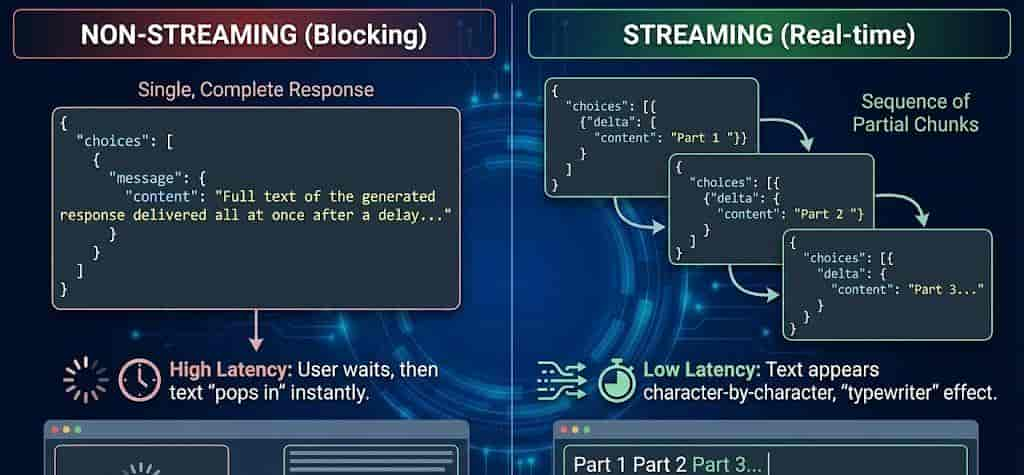
流式 vs 非流式
我们需要重点关注结构上的差异:
- 非流式:完整的回复内容在 message.content 里。
- 流式:每次返回的增量内容在 delta.content 里。
一个典型的 Chunk 结构示例:
{
"id": "chatcmpl-xyz",
"object": "chat.completion.chunk",
"created": 123456789,
"model": "gpt-3.5-turbo",
"choices": [
{
"index": 0,
"delta": {
"content": "好" // <-- 我们要的就是这个!
},
"finish_reason": null
}
]
}
处理关键点:
- 使用 async for chunk in stream: 遍历数据流。
- 提取 chunk.choices[0].delta.content。
- 务必判断 content 是否为空。由于流的开头(角色信息)和结尾(结束标志)的数据包里,content 往往是 None。
- 打印时使用 flush=True,确保内容立即显示,不要被终端缓存,否则就没“打字机”效果了。
5. 完整实战 Demo
好了,万事俱备。将下面的代码复制到你的 hello.py (或 main.py) 文件中。确保你已经配置好了 .env 文件。
然后在终端运行:uv run hello.py
import asyncio
import os
import sys
from dotenv import load_dotenv
from openai import AsyncOpenAI
# --- 1. 配置加载 ---
# 加载项目根目录下的 .env 文件中的环境变量
load_dotenv()
# 读取必要的配置项
api_endpoint = os.getenv("OPENAPI_ENDPOINT")
api_key = os.getenv("OPENAPI_API_KEY")
target_model = os.getenv("OPENAPI_MODEL")
# 简单的健壮性检查:确保环境变量已设置
if not all([api_endpoint, api_key, target_model]):
print("❌ 错误: 缺少必要的环境变量。")
print("请确保在 .env 文件中设置了 OPENAPI_ENDPOINT, OPENAPI_API_KEY, 和 OPENAPI_MODEL。")
sys.exit(1)
print(f" 配置已加载:")
print(f" - Endpoint: {api_endpoint}")
print(f" - Model: {target_model}")
print("-" * 40)
# --- 2. 初始化异步客户端 ---
# 关键点:
# 1. 使用 AsyncOpenAI 而不是同步的 OpenAI
# 2. 显式传入 base_url,使其能连接到自定义的服务端点 (官方或第三方)
client = AsyncOpenAI(
api_key=api_key,
base_url=api_endpoint
)
async def stream_chat(prompt: str):
"""
异步发送 prompt 并以流式打印回复的核心协程。
"""
print(f" User: {prompt}
")
print(f" AI ({target_model}): ", end="", flush=True) # 准备开始输出,提示当前模型
try:
# --- 3. 发起流式请求 ---
# 使用 await 等待连接建立
stream = await client.chat.completions.create(
model=target_model, # 使用环境变量中指定的模型
messages=[
{"role": "system", "content": "你是一个思维灵敏、回答简洁的AI助手。"},
{"role": "user", "content": prompt},
],
stream=True, # <--- 【核心】开启流式模式
)
# --- 4. 异步迭代处理响应流 ---
# stream 是一个异步迭代器,必须用 async for 来遍历
# 程序会在等待下一个 chunk 时释放控制权,不会阻塞
async for chunk in stream:
# 提取增量内容。注意:流式模式下内容在 'delta' 中,而不是 'message' 中
content = chunk.choices[0].delta.content
# 必须检查 content 是否存在,由于第一个和最后一个 chunk 的 content 可能是 None
if content:
# 实时打印出来
# end="" 防止print自动换行
# flush=True 强制刷新缓冲区,确保立刻看到字符跳出,实现打字机效果
print(content, end="", flush=True)
print("
✅ 回复结束")
except Exception as e:
# 捕获网络错误、认证错误等
print(f"
❌ 发生错误: {e}")
print("请检查你的网络连接、API Key 以及 Endpoint 设置是否正确。")
async def main():
"""
主入口协程
"""
print(" 程序启动 (Async Mode)...")
# 这里可以放入你想测试的问题
test_prompt = "请用 Python 写一个斐波那契数列生成器,并简单解释原理。"
# 等待流式对话任务完成
await stream_chat(test_prompt)
print(" 程序退出")
if __name__ == "__main__":
# --- 5. 启动异步事件循环 ---
# asyncio.run 是运行最高层级入口点的标准方法
asyncio.run(main())
总结
运行上面的代码,你将看到 AI 的回复像变魔术一样逐字显现。
通过这篇教程,你已经掌握了构建现代高性能 LLM 应用的基石:
- 使用 uv 管理环境。
- 使用 .env 灵活配置服务地址和模型。
- 使用 AsyncOpenAI 和 async for 实现非阻塞的流式输出。
6. 核心参考文档 (Reference Links)
在深入代码之前,提议将这些官方文档加入书签,遇到问题时随时查阅:
- OpenAI 官方 API 文档 (Streaming 部分)
- OpenAI API Reference – Chat Completion
- 说明:官方对 stream 参数的解释以及返回数据的结构定义。
- OpenAI Python SDK (GitHub)
- openai-python Library
- 说明:SDK 的源码和官方示例。特别是 Async usage 部分的说明。
- Python Asyncio 官方文档
- Python asyncio — Asynchronous I/O
- 说明:Python 标准库文档。重点看 Coroutines and Tasks (协程与任务) 和 Asynchronous Iterators (异步迭代器) 章节。
© 版权声明
文章版权归作者所有,未经允许请勿转载。













[db:评论]