
网上最近刷到好多张图,看得我血压有点高。

什么”AI大模型王座榜”——Claude坐最高位,ChatGPT坐第二,Gemini坐第三,下面跪着一堆国产大模型,DeepSeek、文心、豆包、Qwen,一个个俯首称臣。
还有更过分的——把Claude、ChatGPT、Gemini画成三尊神,豆包和DeepSeek是两个仰望巨人的小孩。

我就想问一句:中国的大模型,真的就这么弱吗?
先别急着下结论,看看数据。
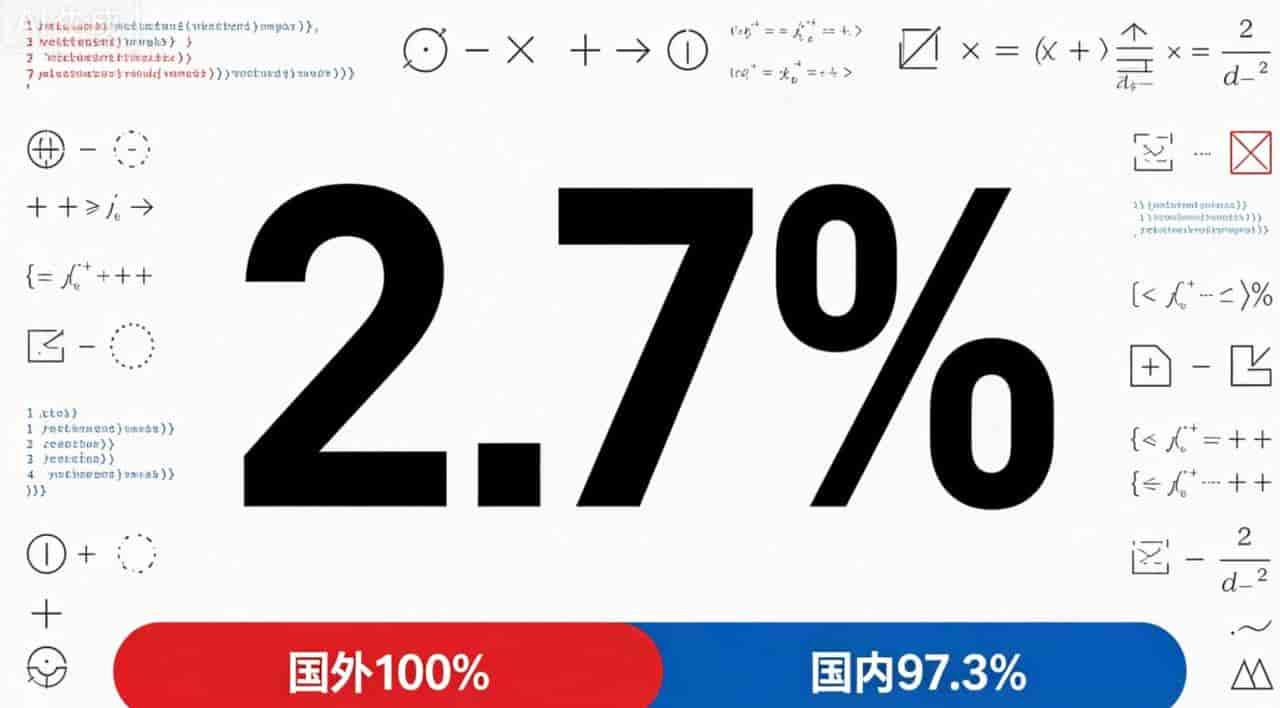
斯坦福大学2026年4月发布了最新的《AI指数报告》,423页,里面有一句话:
“中美AI模型性能差距已几乎消失,差距仅剩2.7%。”
2.7%什么概念?你考100分,我考97.3分,这叫俯首称臣吗?
再看具体评测。
DeepSeek V4,今年4月24日刚发布,1.6万亿参数,开源。
跟GPT-5.5正面硬刚——
编程能力:DeepSeek 88.5%,GPT 86.2%,我们赢了。
逻辑推理:DeepSeek 89.2%,GPT 90.5%,只差1.3个百分点。
数学推理:DeepSeek 90%,GPT 93%,差距在缩小。
价格呢?DeepSeek输入成本大约1元人民币每百万token,GPT-5.5是30美元,折合210元。
价格是他们的百分之一。
你说国外比我们强吗?我承认,的确 强一些,某些领域的确 领先。
但强到那个程度了吗?强到我们要跪着、要俯首称臣、要仰望他们的程度了吗?
没有。
而且最近你可能注意到一个现象——国外的大模型一直在疯狂更新,但国内的好像慢下来了。
有人就在说:你看,我们不行了吧?
但真相是什么?
国内许多大模型,都在适配我们自己的芯片。
否则黄仁勋也不会着急赶那一趟飞机。
DeepSeek推迟发布,不是技术不行,是在适配华为昇腾芯片。
为什么?由于如果我们的大模型跑在别人的芯片上,人家随时可以卡你脖子。
但一旦跑通了呢?
自己的模型,跑在自己的芯片上,成本会更低,能力会更强,而且再也不怕被卡脖子。
这才是真正的长期优势。

所以我承认,国外的确 很强。
但请你别把他们画成神,也别把我们画成跪着的。
我看是网上有些人跪得太久了,站不起来。
我们没有那么弱,他们也没有那么神。
2.7%的差距,不是鸿沟,是时间问题。
你觉得呢?评论区聊聊。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...











