
一张图看懂 AI Agent 第6篇:RAG 检索增强 — 让 Agent 拥有私有知识库
你花了两周写完 100 页产品手册,然后问 AI:”我们的退款政策是什么?”
它一本正经地编了一个从没存在过的答案。
问题不在于 AI 不机智,而在于它根本没读过你的文档。
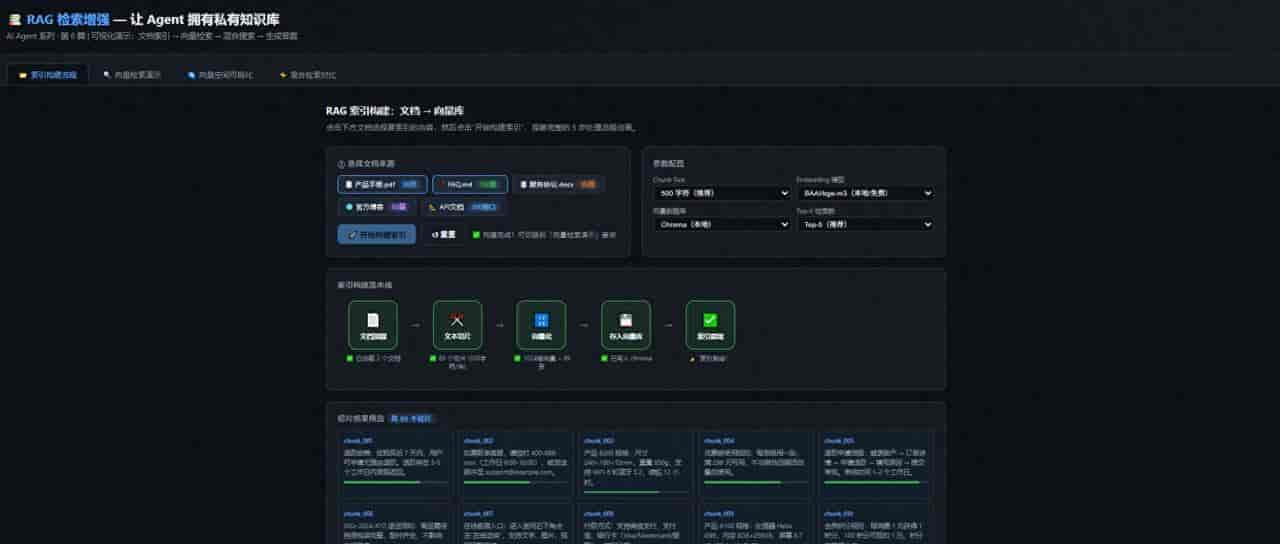
私有知识库
看完这篇,你会学到:
- RAG(检索增强生成)的完整原理——为什么它比直接”喂文档”更高效
- 从文档切片 → 向量化 → 存储 → 检索 → 生成,5 步完整代码
- 生产级 RAG 的关键优化:混合检索、重排序、上下文压缩
- 向量数据库选型对比:FAISS / Chroma / Milvus / Pinecone
一、为什么需要 RAG?
先讲一个尖锐的问题。
如果你想让 AI 回答基于你自己文档的问题,有两种直觉方案:
方案 A:把文档全塞进 Prompt
用户:退款政策是什么?
Prompt = "以下是公司全部文档(100页):... + 请回答:退款政策是什么?"- ❌ Token 消耗爆炸(每次都要传 100 页,费用飞天)
- ❌ 模型有上下文窗口限制(GPT-4o 最多 128K,超了直接报错)
- ❌ 文档太长时,答案质量反而下降(大海捞针问题)
方案 B:让 AI 记住文档(Fine-tuning)
- ❌ 训练成本高(数万元起步)
- ❌ 文档更新就要重训(耗时耗力)
- ❌ 无法精准引用来源
RAG = 检索 + 生成,两全其美:
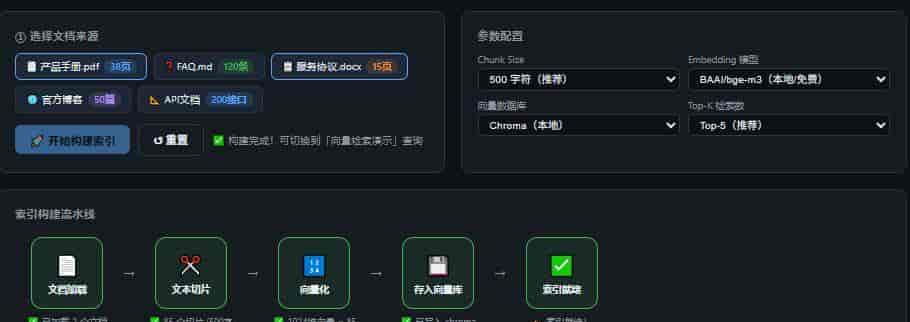
加载文档并向量化
用户:退款政策是什么?
↓
① 向量检索:从知识库找到最相关的 3 段文字
↓
② 只把这 3 段 + 问题 传给 LLM
↓
③ LLM 基于这 3 段生成精准答案(附来源引用)每次只传最相关的 500~2000 个 Token,成本降低 90%+,答案准确率大幅提升。
二、RAG 的完整架构
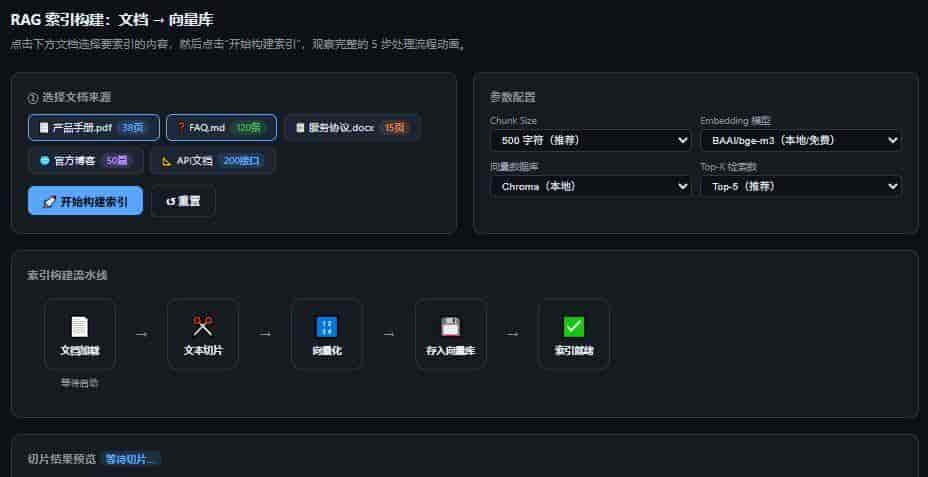
RAG 分为两个阶段:索引阶段(离线)和查询阶段(在线)。
【索引阶段(一次性)】
原始文档(PDF/Word/网页)
↓ 文档加载
文本内容
↓ 文本切片(Chunking)
小段文本 chunks
↓ Embedding 向量化
向量 + 原始文本
↓ 存入向量数据库
向量索引(FAISS / Chroma / Milvus)
【查询阶段(每次请求)】
用户提问
↓ Embedding 向量化
查询向量
↓ 类似度搜索
Top-K 相关 chunks
↓ 构造 Prompt
"参考资料:xxx
问题:xxx"
↓ LLM 生成
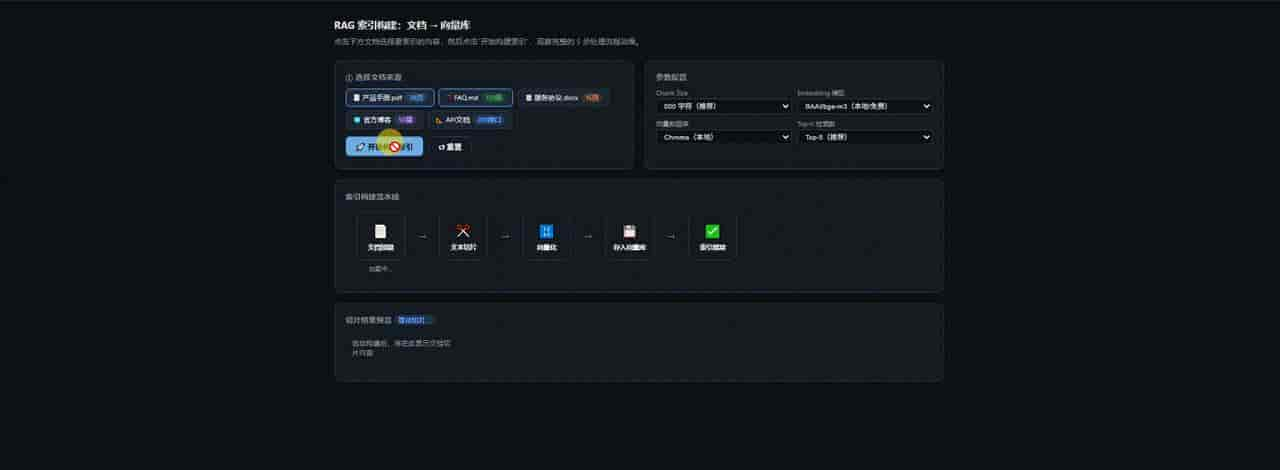
最终答案(含引用来源)三、索引阶段:文档 → 向量库
3.1 文档加载
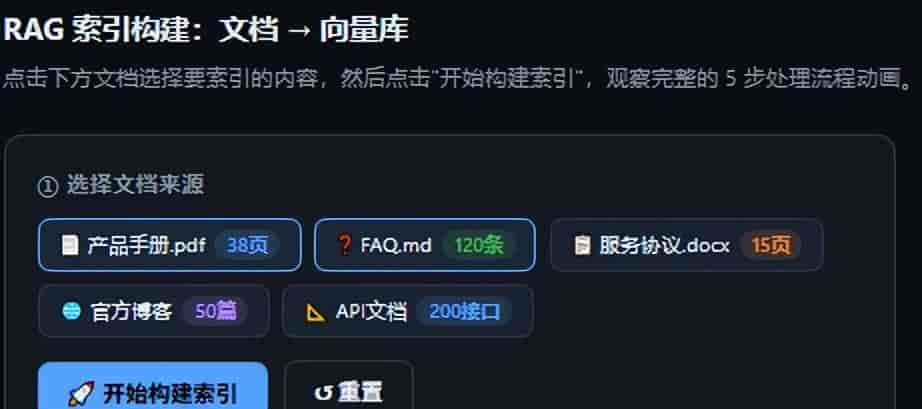
文档加载
LangChain 提供了几十种文档加载器,几乎覆盖所有常用格式:
from langchain_community.document_loaders import (
PyPDFLoader, # PDF
TextLoader, # TXT / MD
WebBaseLoader, # 网页
CSVLoader, # CSV
UnstructuredWordDocumentLoader, # Word
)
# 加载 PDF
loader = PyPDFLoader("product_manual.pdf")
docs = loader.load()
print(f"加载了 {len(docs)} 页")
# 加载网页
web_loader = WebBaseLoader("https://example.com/docs/faq")
web_docs = web_loader.load()
# 批量加载目录
from langchain_community.document_loaders import DirectoryLoader
dir_loader = DirectoryLoader("./docs/", glob="**/*.md")
all_docs = dir_loader.load()
print(f"共加载 {len(all_docs)} 个文档")3.2 文本切片(Chunking)— 最关键的一步
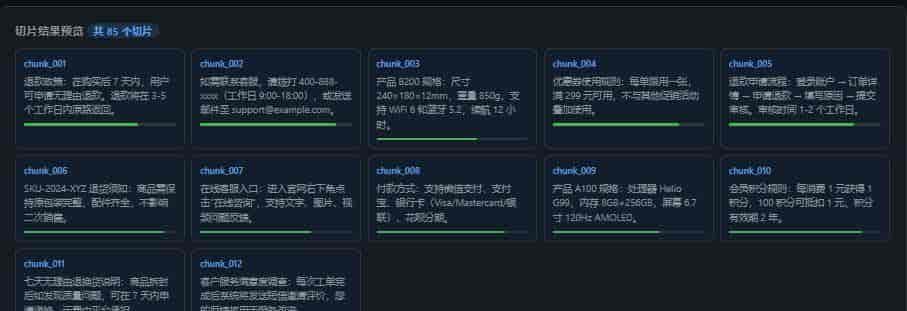
切片策略直接决定检索质量。切太大浪费 Token,切太小丢失上下文。
from langchain.text_splitter import (
RecursiveCharacterTextSplitter,
MarkdownHeaderTextSplitter,
TokenTextSplitter,
)
# ✅ 推荐:RecursiveCharacterTextSplitter
# 按
→
→ 空格 优先级递归切分,尽量保留段落完整性
splitter = RecursiveCharacterTextSplitter(
chunk_size=500, # 每块最大字符数
chunk_overlap=50, # 相邻块重叠,避免答案被截断
length_function=len,
)
chunks = splitter.split_documents(docs)
print(f"切分为 {len(chunks)} 块")
# Markdown 文档按标题层级切分(更适合结构化文档)
headers = [("#", "标题1"), ("##", "标题2"), ("###", "标题3")]
md_splitter = MarkdownHeaderTextSplitter(headers_to_split_on=headers)
md_chunks = md_splitter.split_text(markdown_content)
# Token 级切分(准确控制 Token 数,适合严格限制上下文的场景)
token_splitter = TokenTextSplitter(chunk_size=200, chunk_overlap=20)
token_chunks = token_splitter.split_documents(docs)切片参数经验值:
|
文档类型 |
chunk_size |
chunk_overlap |
推荐切片器 |
|
通用文档/手册 |
400~600 字符 |
50~100 |
RecursiveCharacter |
|
Markdown/Wiki |
按标题层级 |
— |
MarkdownHeader |
|
法律/合同 |
800~1200 字符 |
100~200 |
RecursiveCharacter |
|
代码文件 |
按函数/类 |
— |
Language |
3.3 向量化(Embedding)
from langchain_openai import OpenAIEmbeddings
from langchain_community.embeddings import HuggingFaceEmbeddings
# 方案 A:OpenAI Embedding(高质量,收费)
embeddings = OpenAIEmbeddings(model="text-embedding-3-small")
# 方案 B:本地 Embedding(免费,支持中文)
# 推荐模型:BAAI/bge-m3 (多语言) 或 moka-ai/m3e-base (中文优化)
local_embeddings = HuggingFaceEmbeddings(
model_name="BAAI/bge-m3",
model_kwargs={"device": "cpu"}, # 没有 GPU 也能跑
encode_kwargs={"normalize_embeddings": True},
)
# 测试 Embedding
test_vec = embeddings.embed_query("退款政策")
print(f"向量维度:{len(test_vec)}") # OpenAI small: 1536 维3.4 存入向量数据库
from langchain_community.vectorstores import Chroma, FAISS
from langchain_pinecone import PineconeVectorStore
# 方案 A:Chroma(本地持久化,开发阶段首选)
vectordb = Chroma.from_documents(
documents=chunks,
embedding=embeddings,
persist_directory="./chroma_db", # 本地持久化路径
collection_name="product_docs",
)
print(f"已存入 {vectordb._collection.count()} 条向量")
# 方案 B:FAISS(纯内存,超快,适合中小型知识库)
vectordb = FAISS.from_documents(chunks, embeddings)
vectordb.save_local("./faiss_index") # 保存到本地
# 下次加载:
vectordb = FAISS.load_local("./faiss_index", embeddings,
allow_dangerous_deserialization=True)
# 向量库加载(已有数据,追加新文档)
existing_db = Chroma(
persist_directory="./chroma_db",
embedding_function=embeddings,
)
existing_db.add_documents(new_chunks) # 追加,不覆盖四、查询阶段:检索 + 生成
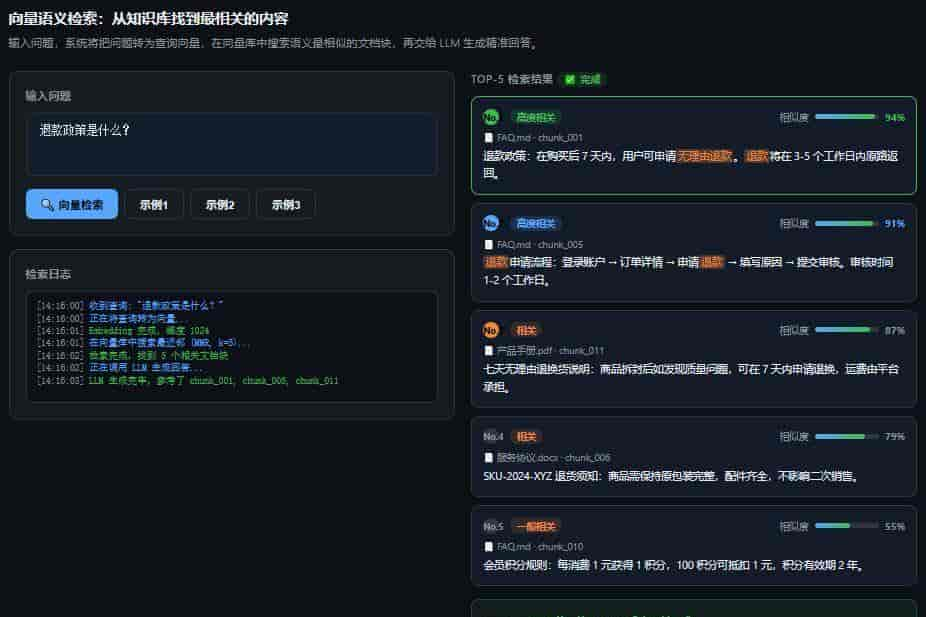
4.1 最基础的 RAG 链
from langchain.chains import RetrievalQA
from langchain_openai import ChatOpenAI
from langchain_core.prompts import PromptTemplate
llm = ChatOpenAI(model="gpt-4o-mini", temperature=0)
# 创建检索器(默认 Top-4 类似度搜索)
retriever = vectordb.as_retriever(
search_type="similarity", # 类似度搜索
search_kwargs={"k": 4}, # 返回最相关的 4 块
)
# 自定义 Prompt,防止 LLM 乱编答案
RAG_PROMPT = PromptTemplate(
input_variables=["context", "question"],
template="""你是一个专业的知识库助手。请严格根据以下参考资料回答问题。
如果参考资料中没有相关信息,请直接说"参考资料中未找到相关内容",不要编造答案。
参考资料:
{context}
用户问题:{question}
回答:""",
)
# 构建 RAG 链
rag_chain = RetrievalQA.from_chain_type(
llm=llm,
chain_type="stuff", # 把所有 chunks 合并后一次性传给 LLM
retriever=retriever,
return_source_documents=True, # 返回引用来源
chain_type_kwargs={"prompt": RAG_PROMPT},
)
# 运行
result = rag_chain.invoke({"query": "退款政策是什么?"})
print("答案:", result["result"])
print("
引用来源:")
for doc in result["source_documents"]:
src = doc.metadata.get("source", "未知来源")
page = doc.metadata.get("page", "?")
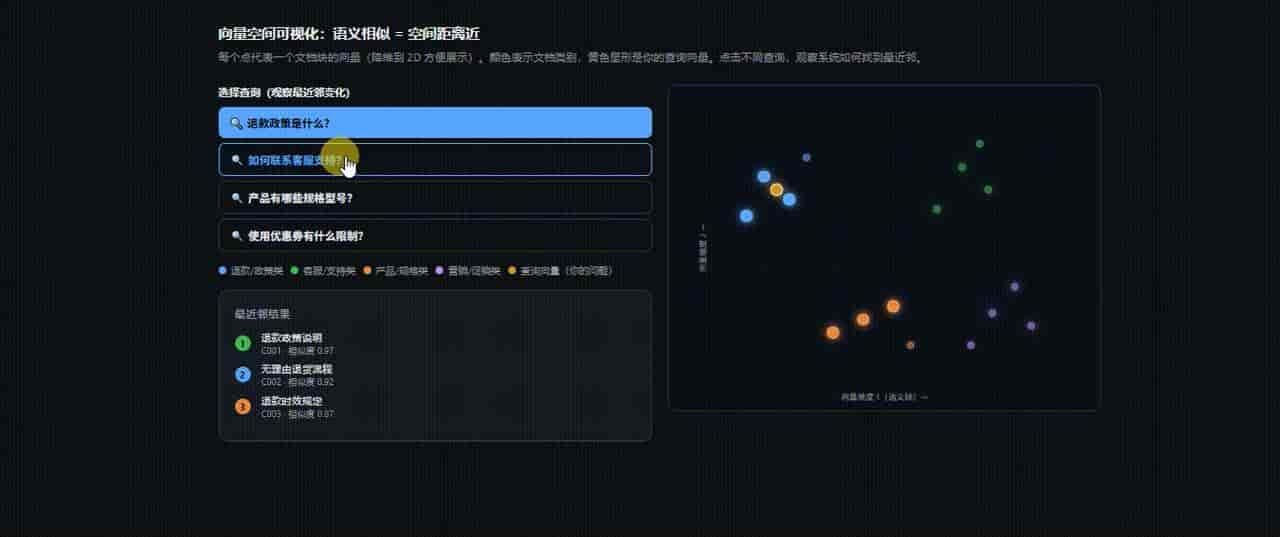
print(f" - {src} 第 {page} 页:{doc.page_content[:100]}...")向量检索代码效果:
向量检索
4.2 LCEL 写法(更现代,更灵活)
from langchain_core.runnables import RunnablePassthrough
from langchain_core.output_parsers import StrOutputParser
def format_docs(docs):
"""把检索到的 docs 格式化为带编号的参考资料字符串"""
return "
".join(
f"[{i+1}] 来源:{doc.metadata.get('source', '未知')}
{doc.page_content}"
for i, doc in enumerate(docs)
)
# LCEL 链式写法
rag_chain = (
{
"context": retriever | format_docs,
"question": RunnablePassthrough(),
}
| RAG_PROMPT
| llm
| StrOutputParser()
)
# 流式输出
for chunk in rag_chain.stream("我们支持哪些支付方式?"):
print(chunk, end="", flush=True)五、生产级优化
基础 RAG 够用,但在真实项目中容易出现检索不准的问题。这里介绍三个关键优化。
5.1 混合检索(Hybrid Search)
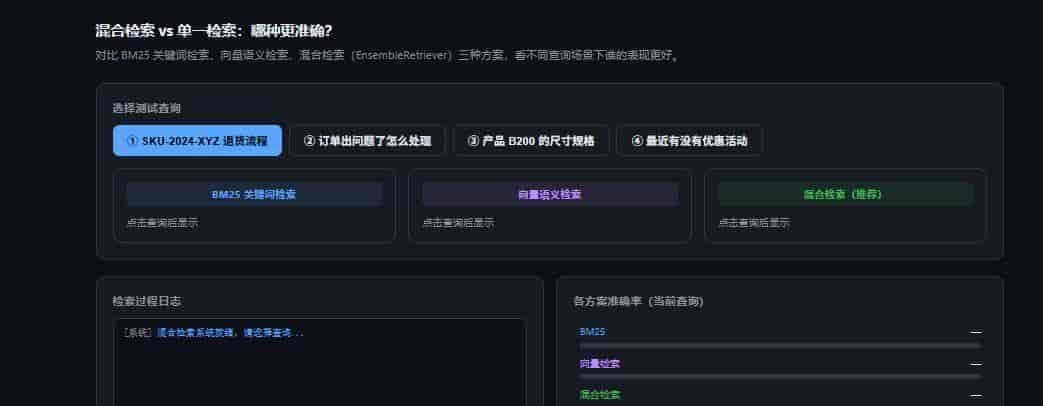
向量检索擅长语义匹配,但对准确关键词(如型号、人名)表现差。BM25 擅长关键词匹配但不懂语义。两者结合,取长补短:
from langchain.retrievers import EnsembleRetriever
from langchain_community.retrievers import BM25Retriever
# BM25 关键词检索
bm25_retriever = BM25Retriever.from_documents(chunks)
bm25_retriever.k = 4
# 向量语义检索
vector_retriever = vectordb.as_retriever(search_kwargs={"k": 4})
# 混合检索(加权融合)
ensemble_retriever = EnsembleRetriever(
retrievers=[bm25_retriever, vector_retriever],
weights=[0.4, 0.6], # BM25 40% + 向量 60%
)
results = ensemble_retriever.invoke("SKU-2024-XYZ 的退货流程")
# BM25 能准确命中 SKU 编号,向量能理解"退货流程"语义5.2 重排序(Reranking)
向量检索返回的 Top-K 结果,排序不必定最优。用 CrossEncoder 重排,把最相关的结果提到最前面:
from langchain.retrievers import ContextualCompressionRetriever
from langchain.retrievers.document_compressors import CrossEncoderReranker
from langchain_community.cross_encoders import HuggingFaceCrossEncoder
# 加载 CrossEncoder 重排模型(支持中文:BAAI/bge-reranker-v2-m3)
reranker_model = HuggingFaceCrossEncoder(model_name="BAAI/bge-reranker-v2-m3")
reranker = CrossEncoderReranker(model=reranker_model, top_n=3)
# 先向量检索 10 个,再重排取 Top-3(精度大幅提升)
compression_retriever = ContextualCompressionRetriever(
base_compressor=reranker,
base_retriever=vectordb.as_retriever(search_kwargs={"k": 10}),
)
reranked_docs = compression_retriever.invoke("退款政策")5.3 查询改写(Query Rewriting)
用户的问题往往口语化、不完整。用 LLM 先把问题改写成更适合检索的形式:
from langchain_core.prompts import ChatPromptTemplate
REWRITE_PROMPT = ChatPromptTemplate.from_template(
"""你是一个检索优化专家。请将用户的问题改写为更适合在文档知识库中搜索的形式。
要求:
1. 保持核心意思不变
2. 扩展相关关键词
3. 去除口语化表达
4. 输出 3 个不同角度的改写版本,换行分隔
原始问题:{question}
改写结果:"""
)
rewrite_chain = REWRITE_PROMPT | llm | StrOutputParser()
def multi_query_retrieval(question: str) -> list:
"""多查询检索:改写 3 个版本分别检索,合并去重"""
rewritten = rewrite_chain.invoke({"question": question})
queries = [question] + rewritten.strip().split("
")
all_docs = []
seen_ids = set()
for q in queries:
docs = retriever.invoke(q)
for doc in docs:
doc_id = hash(doc.page_content)
if doc_id not in seen_ids:
all_docs.append(doc)
seen_ids.add(doc_id)
return all_docs[:6] # 最多返回 6 块
docs = multi_query_retrieval("我买的东西坏了能退吗?")六、向量数据库选型
不同规模的项目适合不同的向量数据库:
|
数据库 |
部署方式 |
数据量上限 |
持久化 |
推荐场景 |
|
FAISS |
纯内存/本地文件 |
百万级(内存限制) |
手动 save/load |
原型开发、单机部署 |
|
Chroma |
本地/Docker |
千万级 |
自动持久化 |
中小项目生产环境 |
|
Milvus |
Docker/K8s集群 |
十亿级 |
✅ |
大规模企业级部署 |
|
Pinecone |
云服务(SaaS) |
无上限 |
✅(云端) |
不想运维、快速上线 |
|
Weaviate |
Docker/云 |
十亿级 |
✅ |
需要混合搜索+GraphQL |
实际选型提议:
- 学习/Demo → FAISS(零配置,pip install faiss-cpu 即可)
- 正式项目 → Chroma(本地 Docker,一行命令启动)
- 团队共用/高并发 → Milvus 或 Pinecone
七、完整项目实战:为自己的文档建知识库
把上面所有步骤串起来,一个生产可用的 RAG 系统:
"""
完整 RAG 系统示例
功能:加载 docs/ 目录下所有 Markdown 文档,构建知识库,提供问答接口
"""
import os
from pathlib import Path
from langchain_community.document_loaders import DirectoryLoader, TextLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_openai import OpenAIEmbeddings, ChatOpenAI
from langchain_community.vectorstores import Chroma
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.runnables import RunnablePassthrough
from langchain_core.output_parsers import StrOutputParser
class RAGSystem:
def __init__(self, docs_path: str = "./my_docs", db_path: str = "./chroma_db"):
self.docs_path = docs_path
self.db_path = db_path
self.embeddings = OpenAIEmbeddings(model="text-embedding-3-small")
self.llm = ChatOpenAI(model="gpt-4o-mini", temperature=0)
self.vectordb = None
self.chain = None
def build_index(self):
"""建立索引(首次运行或文档更新后调用)"""
print(" 加载文档...")
loader = DirectoryLoader(
self.docs_path,
glob="**/*.md",
loader_cls=TextLoader,
loader_kwargs={"encoding": "utf-8"},
)
docs = loader.load()
print(f" 加载了 {len(docs)} 个文档")
print("✂️ 切分文本...")
splitter = RecursiveCharacterTextSplitter(
chunk_size=500, chunk_overlap=50
)
chunks = splitter.split_documents(docs)
print(f" 切分为 {len(chunks)} 块")
print(" 向量化并存入数据库...")
self.vectordb = Chroma.from_documents(
documents=chunks,
embedding=self.embeddings,
persist_directory=self.db_path,
)
print(f"✅ 索引建立完成,共 {self.vectordb._collection.count()} 条向量")
self._build_chain()
def load_index(self):
"""加载已有索引(程序重启后调用,无需重新向量化)"""
self.vectordb = Chroma(
persist_directory=self.db_path,
embedding_function=self.embeddings,
)
print(f"✅ 已加载索引,共 {self.vectordb._collection.count()} 条向量")
self._build_chain()
def _build_chain(self):
retriever = self.vectordb.as_retriever(
search_type="mmr", # MMR 算法:兼顾相关性和多样性
search_kwargs={"k": 5, "fetch_k": 20},
)
prompt = ChatPromptTemplate.from_template(
"""你是专业的知识库助手,只基于以下参考资料回答问题。
若资料中无相关信息,明确说明"参考资料中未找到相关内容"。
参考资料:
{context}
问题:{question}
回答:"""
)
def format_docs(docs):
return "
---
".join(
f"来源:{doc.metadata.get('source', '未知')}
{doc.page_content}"
for doc in docs
)
self.chain = (
{"context": retriever | format_docs, "question": RunnablePassthrough()}
| prompt
| self.llm
| StrOutputParser()
)
def ask(self, question: str) -> str:
"""提问接口"""
if not self.chain:
raise RuntimeError("请先调用 build_index() 或 load_index()")
return self.chain.invoke(question)
def ask_stream(self, question: str):
"""流式提问接口"""
if not self.chain:
raise RuntimeError("请先调用 build_index() 或 load_index()")
for chunk in self.chain.stream(question):
yield chunk
# 使用示例
if __name__ == "__main__":
rag = RAGSystem(docs_path="./my_docs", db_path="./chroma_db")
# 首次运行:建立索引
if not Path("./chroma_db").exists():
rag.build_index()
else:
rag.load_index() # 已有索引直接加载,省时省钱
# 问答
questions = [
"退款政策是什么?",
"如何联系客服?",
"支持哪些支付方式?",
]
for q in questions:
print(f"
❓ {q}")
print(f" {rag.ask(q)}")八、踩坑提示
这些都是真实项目里最常踩的坑,提前看能省好几天时间
1. 中文文档 Embedding 必定要选支持中文的模型
text-embedding-ada-002 对中文支持有限,长句语义理解差。中文文档推荐:
- 免费:BAAI/bge-m3(多语言,效果顶)或 moka-ai/m3e-base
- 付费:OpenAI text-embedding-3-large(贵但准)
2. 不要用太大的 chunk_size
chunk_size=2000 看起来”信息更完整”,实际上检索时相关段落被无关内容稀释,答案质量反而更差。500~800 字符是经验甜区。
3. 向量数据库和 Embedding 模型要绑定
建库时用 A 模型,查询时换 B 模型 → 向量空间不一样 → 结果全错。切换模型必须重建索引。
4. 给 Prompt 加上”不知道就说不知道”的约束
不加约束时 LLM 会”幻觉”——在参考资料没说的情况下,依旧用置信的语气给出错误答案。加上 “如果参考资料中没有,请说不知道” 这句话,能大幅降低幻觉率。
总结
|
步骤 |
工具 |
关键参数 |
|
文档加载 |
DirectoryLoader / PyPDFLoader |
glob 匹配规则 |
|
文本切片 |
RecursiveCharacterTextSplitter |
chunk_size=500, overlap=50 |
|
向量化 |
OpenAIEmbeddings / bge-m3 |
中文选 bge-m3 |
|
向量存储 |
Chroma(开发)/ Milvus(生产) |
persist_directory |
|
检索 |
as_retriever(search_type=”mmr”) |
k=5 |
|
生成 |
ChatOpenAI + RAG Prompt |
temperature=0 |
|
优化 |
混合检索 / 重排序 / 查询改写 |
按需叠加 |
RAG 是 Agent 拥有私有知识的标配方案。
演示向量化:
演示向量空间可视化:
下一篇预告:我们把 RAG 和之前学的工具层、规划层整合在一起,构建一个完整的多轮问答 Agent。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











