
#探寻人工智能#
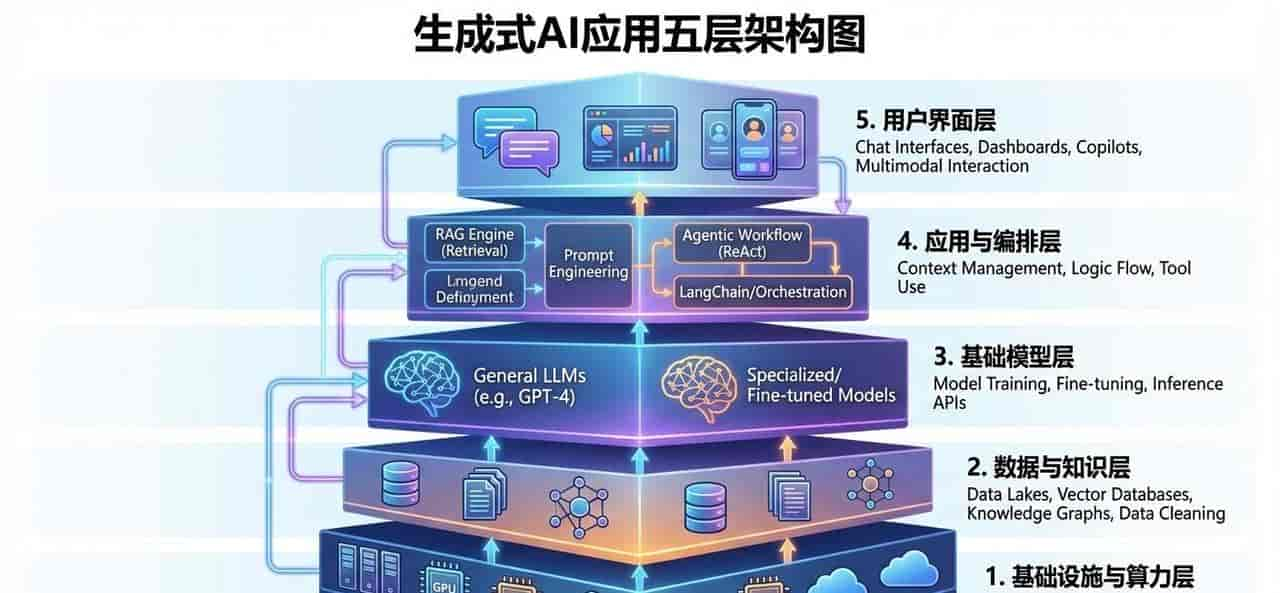
一、五层架构图
介绍当前企业级大模型应用(LLM App)从底层算力到顶层用户体验的完整技术栈和协作流。不仅定义了技术边界,还明确了各个环节的人员分工与核心目标。
以下我将采用自下而上(从基础设施到用户界面)的逻辑,为您详细拆解这五层架构:
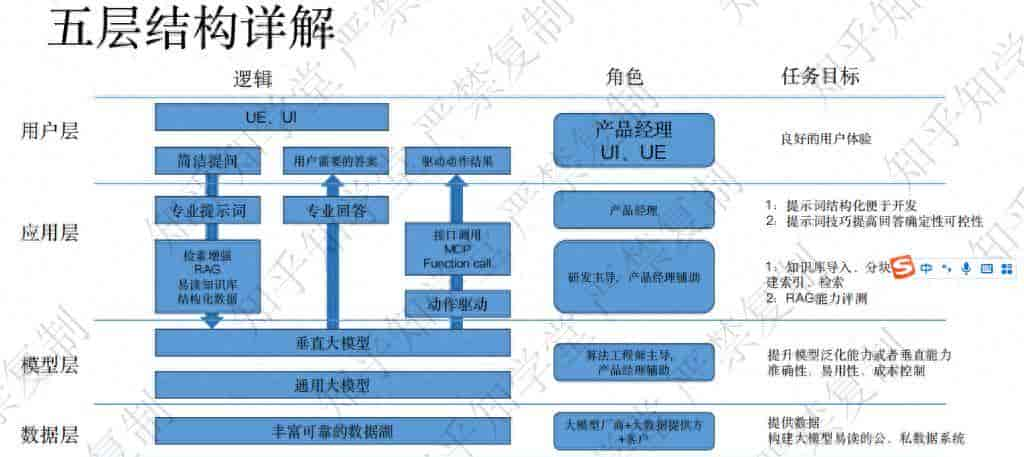
1.1 算法算力层 (Infrastructure Layer)
这是整个AI大厦的地基,决定了系统的上限。
- 核心逻辑:包含基础算法理论的研究与核心算力(GPU/TPU芯片、集群)的供给。
- 关键角色:AI科学家(负责突破算法理论)、芯片厂商(如Nvidia)。
- 任务目标:不断提升物理算力水平和算法效率,为上层提供强劲的计算支撑。
1.2 数据层 (Data Layer)
数据是AI的“燃料”,这一层解决了模型“懂什么”的问题。
- 核心逻辑:构建丰富可靠的数据湖。关键在于不仅仅是存储数据,而是要将企业内部的私有数据、公有数据进行清洗和处理,构建成大模型“易读”的数据系统。
- 关键角色:大模型厂商 + 大数据提供方 + 客户自身的数据团队。
- 任务目标:
- 打破数据孤岛。
- 构建高质量的数据集,区分公有与私有数据,确保数据的安全与合规。
1.3 模型层 (Model Layer)
这是AI的大脑,负责通用的推理和理解能力。
- 核心逻辑:
- 通用大模型:提供基础的语言理解、逻辑推理能力(如GPT-4, Claude, 文心一言等)。
- 垂直大模型:基于通用模型,针对特定行业(如医疗、法律、金融)进行微调(Fine-tuning),以获得更强的领域专业性。
- 关键角色:算法工程师主导,产品经理辅助(定义模型需要具备什么能力)。
- 任务目标:
- 提升模型的泛化能力(举一反三)或垂直能力(专精)。
- 平衡准确性、易用性与成本控制(Token消耗)。
1.4 应用层 (Application Layer)[架构核心]
这是AI架构师最关注的“中台层”,它将笨重的模型能力转化为具体的业务逻辑。图中标注的内容最多,说明这里是业务落地的深水区。
- 核心逻辑:
- 提示词工程 (Prompt Engineering):将用户的“简单提问”转化为模型能理解的“专业提示词”。
- RAG (检索增强生成):通过引入外部知识库和结构化数据,解决大模型幻觉问题,让回答更专业、可控。 * Agent/Function Call (动作驱动):通过MCP(Model Context Protocol)或接口调用,让AI不仅能“说话”,还能“动手”(如查询数据库、操作软件)。
- 关键角色:
- 产品经理:定义业务流程和提示词策略。
- 研发团队:搭建RAG架构,实现知识库的分块、索引和检索。
- 任务目标:
- 结构化开发:让提示词易于维护。
- 确定性与可控性:确保AI回答准确,不胡说八道。
- 知识库导入:实现企业知识的有效利用。
1.5 用户层 (User Layer)
这是用户直接感知的界面,决定了产品的“手感”。
- 核心逻辑:
- 交互 (UI/UE):提供简洁的聊天或操作界面。
- 意图转化:用户只需进行“简洁提问”,系统负责在后台处理复杂逻辑,最终呈现“用户需要的答案”或直接“驱动动作结果”。
- 关键角色:产品经理、UI/UE设计师。
- 任务目标:极致的用户体验。隐藏背后的技术复杂性,让用户感觉AI既机智又简单。
1.6 总结 (Architect's Insight)
从这张图的流向(箭头)可以看出一个核心的数据价值链:
- 输入流(下行):用户的“模糊需求”经过应用层的Prompt编排和RAG检索,变成了机器可理解的“精准指令”,输入给模型。
- 输出流(上行):模型生成的“原始向量/文本”,经过应用层的格式化和校验,变成了用户能看懂的“优质答案”或实际的“业务操作”。
该架构的亮点在于“应用层”的解耦:它通过RAG和提示词工程,把“不确定的模型”和“确定的业务需求”连接了起来,这是当前AI应用落地的最佳实践模式。
二、RAG(检索增强生成)
在应用层中,RAG(检索增强生成) 是将通用大模型转化为“行业专家”的关键引擎。在设计 RAG 策略时,我们需要在检索精度、系统性能和成本之间寻求平衡。
以下是关于数据切片粒度和向量数据库选择的深度解析:
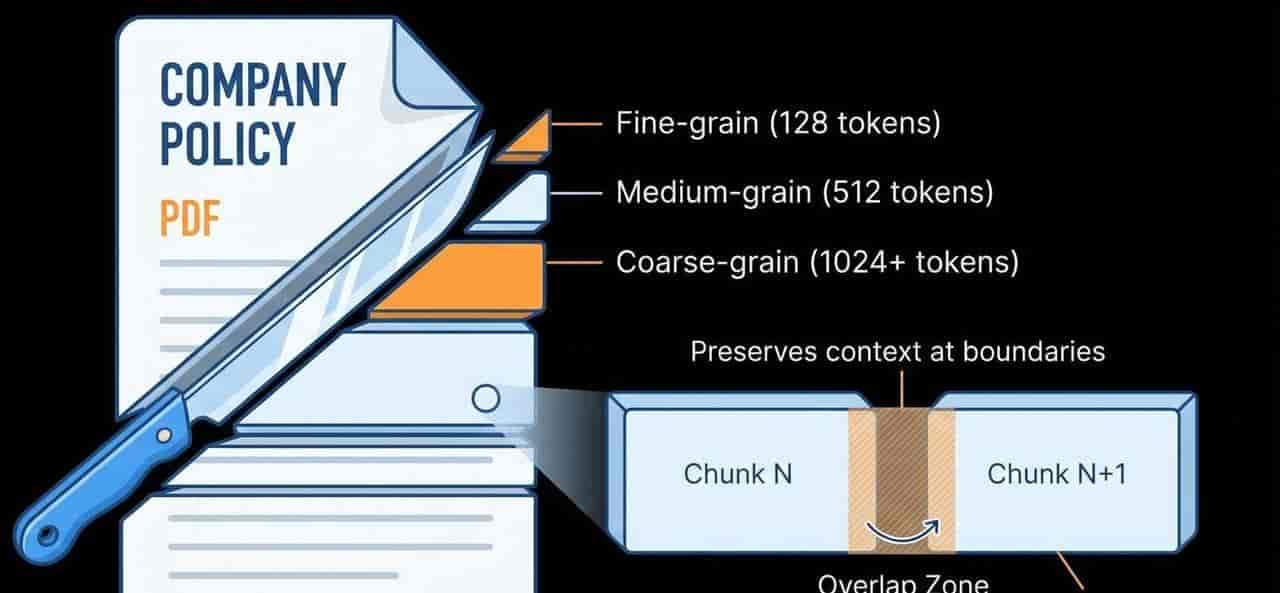
2.1 数据切片粒度 (Chunking Strategy)
切片(Chunking)决定了 AI 检索到的知识“单位”是什么。如果切片太大,回答会混入杂质;如果太小,则会丢失上下文。
- 分块大小 (Chunk Size):
- 细粒度 (128-256 tokens): 适用于实际性问答(如:某产品的保修期是多久?)。优点是匹配精准,缺点是容易丢失句子前后的逻辑因果。
- 中等粒度 (512-1024 tokens): 通用推荐方案。能平衡语义完整性和检索效率,适合大多数技术文档。
- 粗粒度 (>1024 tokens): 适用于总结类任务(如:请概括这一章的核心思想)。
- 重叠度 (Overlap):
- 一般设置 10%-20% 的重叠。
- 目的: 确保当关键信息恰好位于切分点时,不会被截断。重叠部分充当了切片间的“粘合剂”,保持语义连贯。
- 高级切片技术:
- 语义分块 (Semantic Chunking): 不再按字符数切分,而是利用模型检测语义变化点(如段落切换、主题变更),在意思完整的地方动刀。
- 父子索引 (Parent-Document Retrieval): 检索时匹配小的子块(提高精度),但交给 LLM 时提供大父块(提供丰富上下文)。
2.2 向量数据库选择 (Vector Database Selection)
向量数据库是 RAG 的“心脏”,负责存储和快速检索海量的向量化数据。
根据业务场景的不同,我们一般面临三种选择:
|
类型 |
代表产品 |
核心优势 |
适用场景 |
|
原生专用型 |
Milvus / Pinecone |
极致的性能和扩展性,支持亿级向量检索,算法丰富(HNSW, IVF等)。 |
海量数据、高并发、需要复杂检索策略的大型企业。 |
|
传统库扩展型 |
pgvector (PostgreSQL) |
在现有数据库上平替,无需增加新的基础设施。支持向量与关系型数据关联查询。 |
数据量中等、希望降低运维成本、业务逻辑与结构化数据紧密耦合。 |
|
搜索增强型 |
Elasticsearch (ES) |
强劲的全文检索能力,支持混合检索 (Hybrid Search)。 |
需要同时匹配“关键词”和“语义类似度”的场景。 |
2.3 落地提议
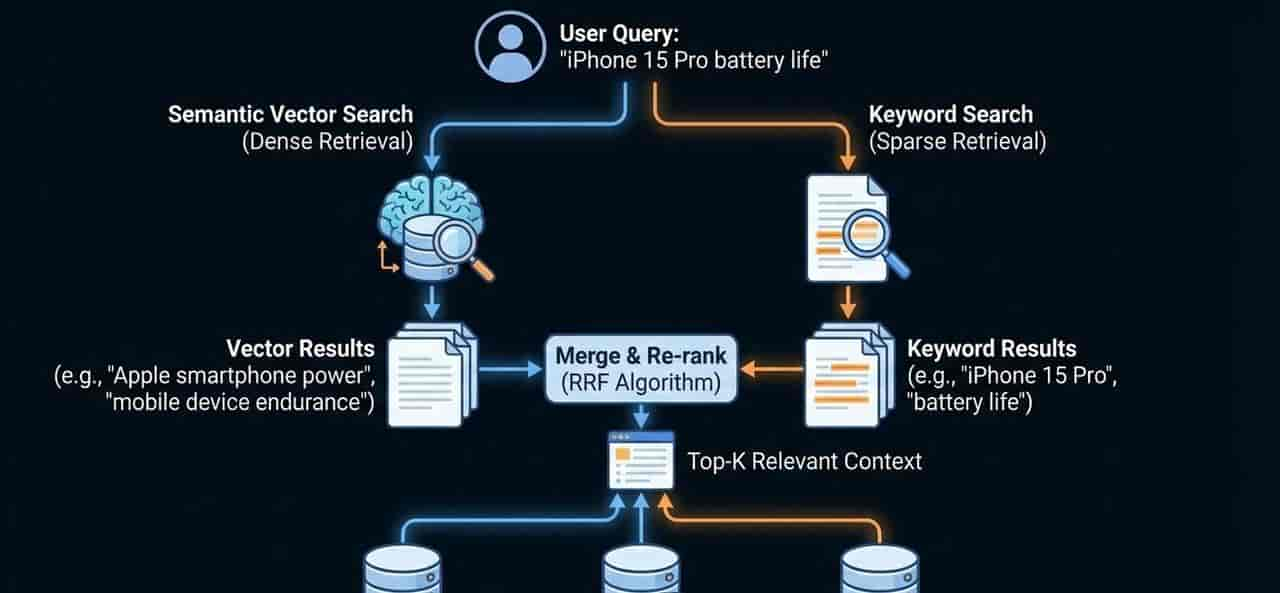
- 首推混合检索 (Hybrid Search): 仅仅靠语义向量是不够的。列如搜索“iPhone 15 Pro”,向量检索可能找到“苹果手机”,但全文搜索能精准锁定型号。将 Vector + Keyword 的结果加权合并(RRF算法),是目前最稳健的做法。
- 动态切片: 针对不同类型的文档(如 PDF 协议、代码库、Excel)采用不同的切片脚本,而不是全公司一套逻辑。
- 多向量存储: 针对同一个切片,可以存储其原文、摘要以及生成的“假设性问题(HyDE)”,这能极大提升检索召回率。
三、Prompt 编排(Prompt Orchestration)
AI 中台架构的应用层中,Prompt 编排(Prompt Orchestration) 是连接“用户意图”与“模型能力”的灵魂。它不再是简单的写一句话,而是一套复杂的软件工程实践。
我将 Prompt 编排模式归纳为以下四个核心维度:
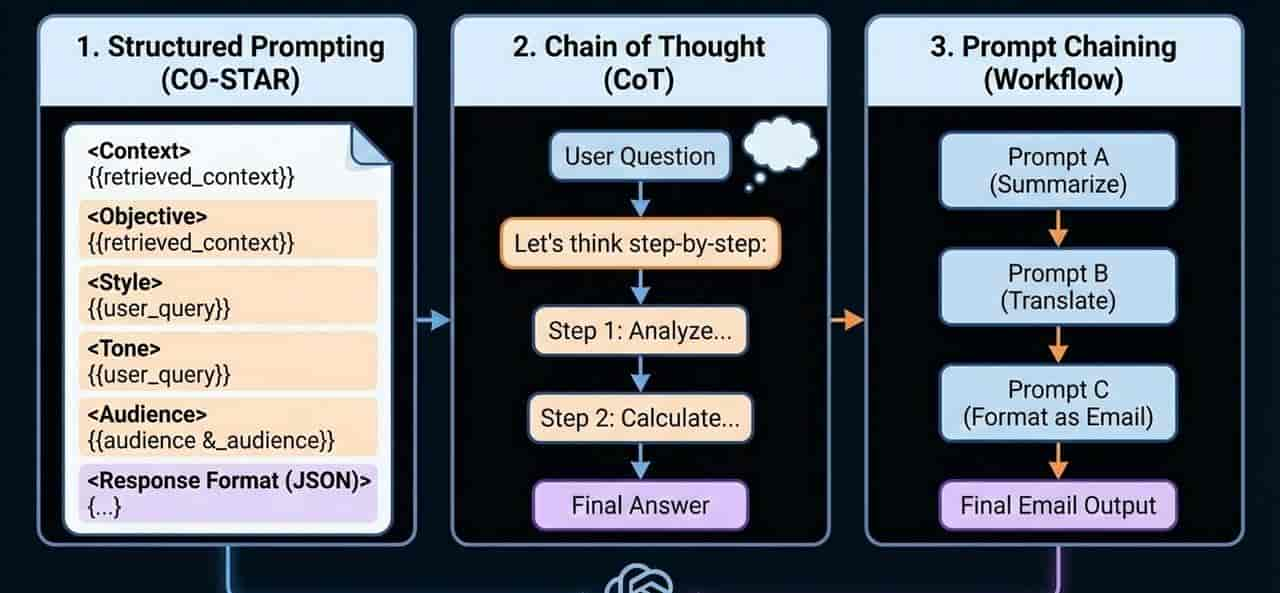
3.1 结构化指令模式 (Structured Prompting)
这是编排的基石。通过将 Prompt 分解为特定的模块,可以显著提高模型输出的稳定性和可预测性。
- CO-STAR 框架:
- Context (背景):提供任务的行业背景。
- Objective (目标):明确要完成的具体任务。
- Style (风格):指定文风(如:专业、幽默)。
- Tone (语调):设定情感基调。
- Audience (受众):针对谁在说话。
- Response (响应):规定输出格式(JSON, Markdown, 表格)。
- XML 标签隔离:在编排时使用 <context>、<rules>、<output_format> 等标签包裹内容。这种做法对 Claude 和 GPT-4 等模型超级有效,能防止模型混淆指令和示例。
3.2 逻辑链编排模式 (Reasoning Patterns)
为了处理复杂逻辑,我们需要引导模型“分步骤”思考。
- CoT (Chain of Thought):要求模型“一步步思考”,展示推理过程,减少逻辑错误。
- Self-Consistency (自一致性):让模型生成多个推理路径,最后通过投票选出最频繁出现的答案。
- ReAct (Reasoning and Acting):这是 Agent 的核心。模型先进行 Reasoning (推理) 决定要做什么,然后执行 Action (行动,如调用 API),最后根据 Observation (观察结果) 进行下一步推理。
3.3 动态上下文编排 (Dynamic Context Injection)
应用层不应向模型发送死板的 Prompt,而应根据实时情况动态拼装。
- 变量占位符:使用 {{user_query}} 或 {{retrieved_context}} 作为模板占位符,在运行时注入 RAG 检索到的知识。
- Few-shot 动态选择:不是固定的给 3 个例子,而是根据用户的提问,通过向量检索从“示例库”中找到最相关的 3 个例子放入 Prompt。这种方式被称为 ICL (In-Context Learning) 的动态增强。
3.4 流程编排与链式调用 (Prompt Chaining)
对于极复杂的任务(如写一篇带图表的行业分析报告),单一的 Prompt 往往效果不佳。我们需要将其拆分为“工作流”。
- 串行链 (Sequential):Prompt A 的输出作为 Prompt B 的输入(例如:先总结文章 -> 再翻译总结)。
- 并行链 (Parallel):同时调用多个 Prompt(例如:同时从正面和反面评价一个观点),最后由一个总结 Prompt 进行汇总。
- 路由分发 (Router):第一层 Prompt 仅用于判断用户意图(是查询、投诉还是闲聊),然后根据判断结果将请求分发给不同专业领域的“子 Prompt”。
3.5 落地提议
- 版本控制:Prompt 就是代码。应将 Prompt 存储在 Git 或专用的 Prompt Management 系统中,记录版本、模型 ID 和参数(Temperature 等)。
- 输入/输出校验 (Guardrails):在 Prompt 编排中加入校验层。例如,强制要求模型输出 JSON,如果输出格式不对,系统应自动拦截并重试,而不是直接展示给用户。
- 单元测试 (Evaluation):为每个 Prompt 建立 Benchmark(基准测试集),每次修改 Prompt 都要跑一遍测试,确保解决旧问题的同时没有引入新问题。
© 版权声明
文章版权归作者所有,未经允许请勿转载。















[db:评论]