
前面讲到,Context Engineering 关心的是:在模型开始工作之前,应该给它准备什么输入。
这一讲把问题再拆细一点。
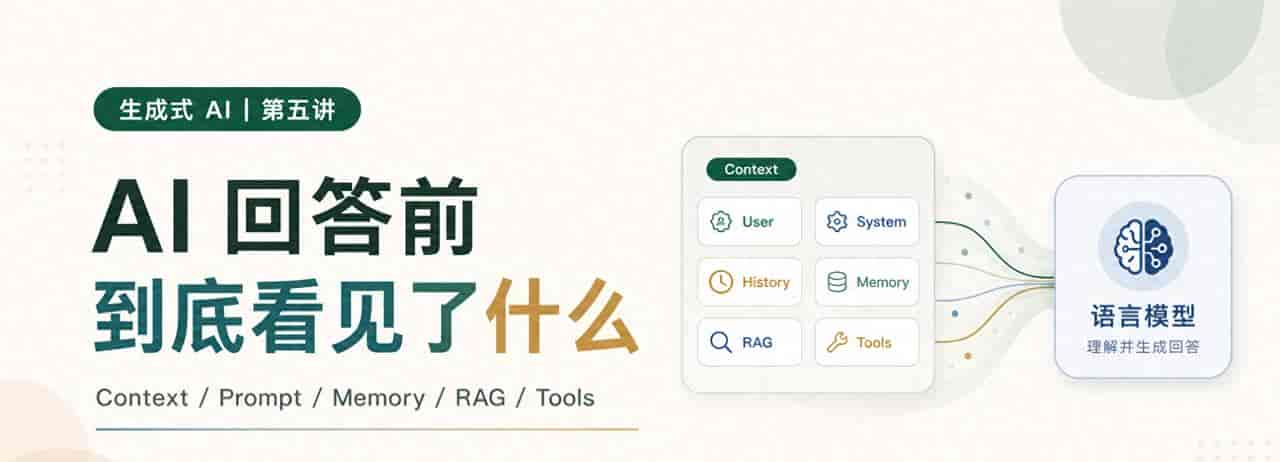
AI 在回答你之前,到底看见了什么?
许多人会以为,它看到的就是你刚刚打进去的那句话。
列如你问:
“帮我写一段产品介绍。”
从使用者视角看,的确 只有这一句话。
但在真实的 AI 产品里,模型看到的往往是一整包东西。
这里面可能有你的问题,也可能有产品写给模型的底层规则、之前聊过的内容、长期保存的偏好、检索出来的资料、工具返回的结果,甚至还有模型自己前面做过的计划和验证。
这些东西合在一起,才是模型这一次真正看到的上下文。
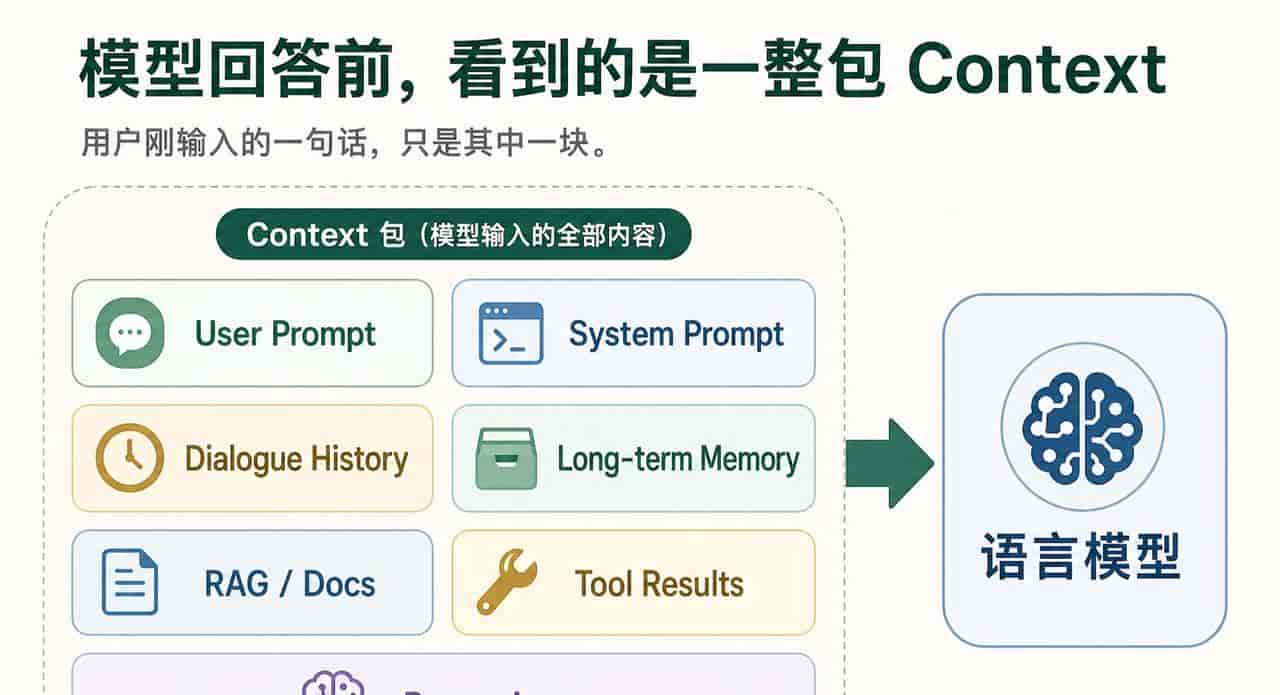
一、User Prompt:你直接交给模型的任务
最容易理解的部分,是 User Prompt。
它就是你作为用户直接输入的内容。
但一个好的 User Prompt,一般不只是一个问题。
它至少可以包含四类信息。
第一,任务是什么。
你希望模型写邮件、总结资料、解释概念、改代码、做计划,还是帮你比较方案。
第二,限制是什么。
字数、语气、读者、格式、不能提到的内容、必须覆盖的重点,都属于限制。
第三,背景是什么。
这件事发生在什么场景里,相关人是谁,之前发生过什么,当前已经有什么材料。
第四,输出应该长什么样。
你要的是短结论、完整文章、表格、清单、代码块,还是可以直接发出去的文案。
模型不会读心。
你没放进上下文里的前提,它只能猜。
猜对的时候,你会觉得它机智。
猜错的时候,你会觉得它不靠谱。
许多时候,模型并没有突然变笨。
它只是没有看到足够清楚的任务条件。
二、System Prompt:产品写给模型的底层规则
除了你输入的内容,模型一般还会看到一段由产品方准备的 System Prompt。
这部分普通用户一般看不见。
它像是产品给模型的一份工作说明书。
里面可能会写模型是谁,应该用什么语气回答,哪些事情不能做,遇到不确定信息该怎么处理,输出格式要遵守什么规则,以及当用户不满意时应该怎样回应。
同样是一个底层模型,放进不同产品里,表现可能会很不一样。
一个产品希望它像客服,回答要短、稳、不能越界。
另一个产品希望它像研究助理,回答要解释依据、保留不确定性、给出来源。
底层模型可能相近,但 System Prompt 会把它引导到不同的行为模式。
这也是为什么同一个问题,在不同 AI 产品里得到的答案会有明显差异。
用户看到的是“模型回答不同”。
底层缘由往往是:模型看到的规则不同。
三、Dialogue History:当前对话里的短期记忆
对话历史也是上下文的一部分。
你在同一个聊天窗口里前面说过的话,模型后面一般还能参考。
列如你先说:
“后来回答我时,尽量用更短的段落。”
接下来你再让它解释一个概念,它就可能继续沿用这个要求。
这不是模型被重新训练了。
它只是把前面的对话内容一起看到了。
所以,同一个问题在新对话里问,和在已经铺垫过许多背景的旧对话里问,结果可能完全不同。
旧对话里,模型知道你前面关心什么,知道你已经理解到哪一步,也知道哪些信息不需要再重复。
这种能力很像短期记忆。
它让模型能在一个连续任务里保持上下文。
但它也有代价。
如果前面的对话里混入了错误信息、无关争论、过时要求,模型后面也可能继续被这些内容影响。
四、Long-term Memory:跨对话保存的信息
有些 AI 产品还会加入长期记忆。
短期记忆只存在于当前对话里。
长期记忆可以跨对话保存。
列如它记住你常用中文写作,偏好短段落,正在做公众号,喜爱教学口吻,不喜爱太夸张的转场。
下次你打开新对话,模型依旧可能参考这些信息。
长期记忆的价值,是减少重复交代。
你不需要每次都从头说明自己的偏好和背景。
但长期记忆也需要管理。
如果记住的是过时偏好,或者把一次性的要求误当成长期规则,后续回答就会被带偏。
所以,记忆不是越多越好。
好的记忆应该稳定、常用、可复用。
临时信息应该留在当前任务里,不应该长期占着位置。
五、RAG:从外部资料里补信息
模型本身不必定知道最新消息,也不必定知道你的私有资料。
如果要让它回答公司内部文档、最新新闻、产品说明书、论文、合同、代码库里的内容,就需要把外部资料放进上下文。
这就是 RAG。
RAG 的全称是 Retrieval-Augmented Generation,可以理解成“先检索,再生成”。
模型先从资料库、网页、文档或搜索结果里找到相关内容,再把这些内容放进上下文,最后基于这些材料回答。
这里有一个很关键的点。
RAG 不是让模型凭空变机智。
它只是让模型在回答前多看见了一些材料。
材料找得准,回答就更扎实。
材料找错了,模型也会沿着错误材料继续生成。
材料太多,模型可能抓不住重点。
所以 RAG 的难点,不只是“能不能搜到东西”。
更难的是:搜到的东西是否相关,是否可信,是否足够精简,是否刚好适合当前任务。
六、Tool Use:工具结果也会进入上下文
目前许多 AI 不只是聊天。
它可以查天气、读日历、搜网页、运行代码、操作浏览器、调用数据库、写文件、发请求。
从模型角度看,工具调用一般也会变成上下文的一部分。
模型先生成一个工具调用指令。
系统真正去执行这个工具。
工具返回结果。
然后结果再被放回上下文里,让模型继续生成最终回答。
列如你问:
“明天下午北京会下雨吗?”
模型自己并不知道实时天气。
它需要调用天气工具。
工具返回降雨概率、温度、风力等信息。
模型再把这些工具结果组织成你能读懂的回答。
真正重大的是,用户往往只看到最后一句自然语言。
中间的工具指令、工具输出和错误重试,一般不会完整展示。
但它们的确 参与了模型的生成过程。
七、Examples:示例会改变模型的接法
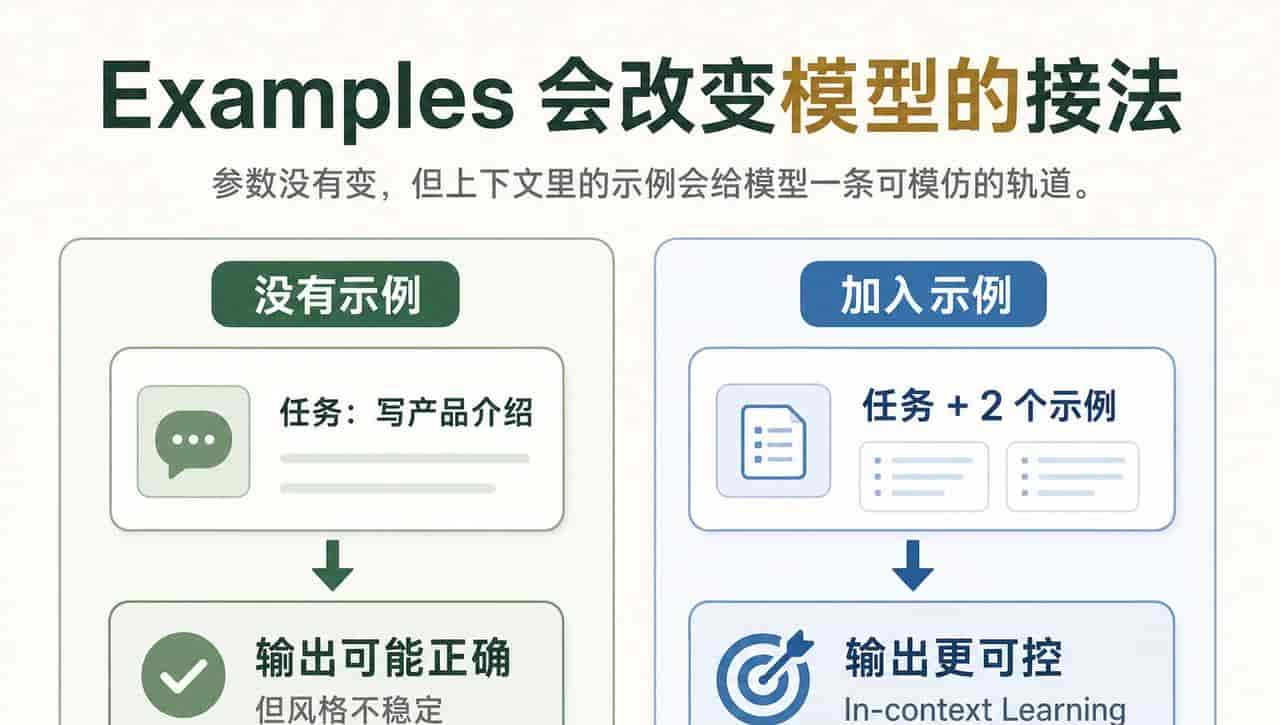
上下文里还有一种超级有用的信息:示例。
你给模型一个例子,它就更容易沿着例子的格式继续生成。
你给两个例子,它就更容易看出规律。
你给一组高质量样例,它甚至能在参数不变的情况下,临时学会一种输出方式。
这就是 In-context Learning。
它不是训练。
模型的参数没有改变。
变化的是上下文。
示例告知模型:
“接下来请按这种方式做。”
这也是为什么许多时候,直接说规则不如给一个例子。
你说“写得高级一点”,模型可能理解得很模糊。
你给它一段你喜爱的样文,它就更容易模仿节奏、密度、词汇和结构。
示例越贴近目标,模型越容易接对。
示例越混乱,模型越容易把混乱也学进去。
八、Reasoning:模型自己的计划和验证
还有一类上下文,和模型自己的思考过程有关。
面对复杂任务时,模型可能会先拆解问题,尝试几条路线,验证中间结果,再决定最终答案。
在许多产品里,用户不必定能看到完整过程。
但从系统设计上看,这些中间步骤可能会影响后面的生成。
它们可以协助模型规划,也可能带来额外成本和风险。
规划得好,模型能把复杂任务拆开做。
规划得差,它会沿着错误路线越走越远。
所以 Reasoning 也属于上下文工程的一部分。
不是只要让模型“多想想”就必定更好。
更重大的是让它在合适的位置计划、验证和停止。
结语
目前可以把“上下文”理解成模型当前看到的世界。
这个世界里,可能有用户问题,有系统规则,有当前对话,有长期记忆,有外部资料,有工具结果,有示例,也有模型自己的中间推理。
模型不能读心。
它只能根据这个世界继续生成。
所以,想让 AI 稳定工作,关键不只是把一句提示词写美丽。
更重大的是判断:
这次任务里,模型应该看到什么。
哪些信息必须放进去。
哪些信息应该删掉。
哪些信息需要从外部检索。
哪些结果需要由工具返回。
哪些例子能让模型更快进入正确轨道。
这就是 Context Engineering 继续往下走时最基本的问题。
下一讲可以继续拆:
为什么一进入 AI Agent 场景,上下文会变得更长、更乱,也更需要被管理。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...









